Matriz shell e algoritmo de classificação
Variedade
Um, defina a matriz
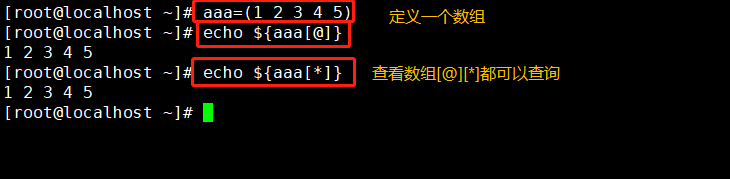
Método 1:
nome da matriz = (valor0 valor1 valor2…)
Método 2:
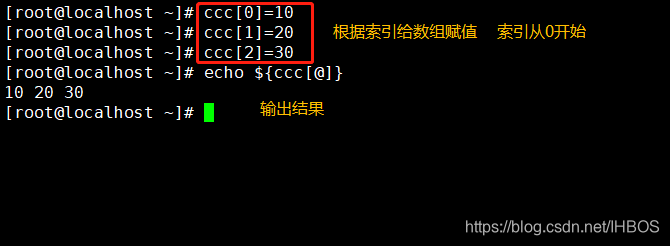
nome da matriz = ([0] = valor [1] = valor [2] = valor ...)

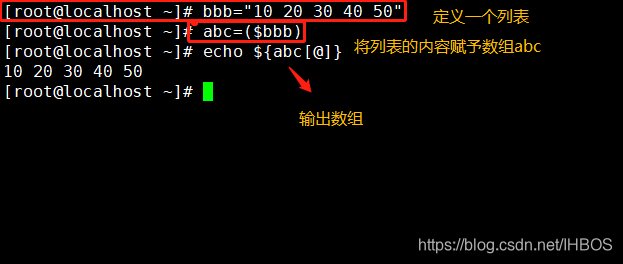
Método 3:
List name = "value0 value1 value2…"
Array name = ($ list name)
Método 4:
Nome da matriz [0] = "valor"
Nome da matriz [1] = "valor"
Nome da matriz [2] = "valor"
1. Tipos de dados incluídos na matriz
● 数值类型
● 字符类型(字符串)
使用" "或''定义
2. Obtenha o comprimento da matriz
abc=(10 20 30 40 50 60)
echo $(#abc[*])
echo $(#abc[@]) #获取数组长度

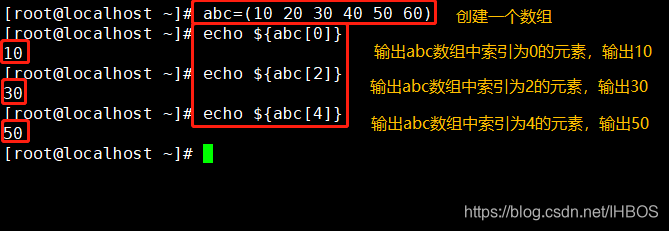
3. Leia uma tarefa subscrita
abc=(10 20 30 40 50 60)
echo ${
abc[0]}
echo ${
abc[2]}
echo ${
abc[4]
Dois, travessia de matriz
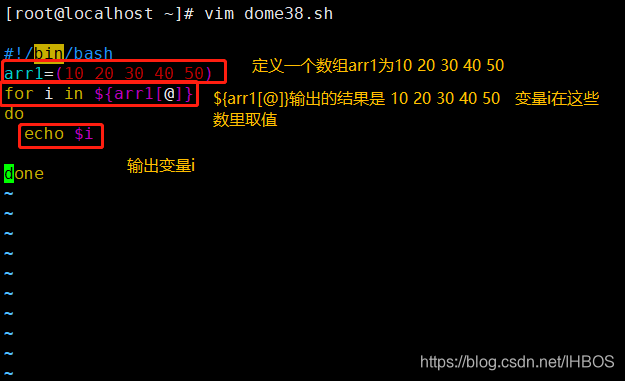
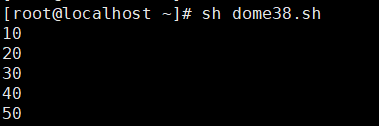
[root@localhost ~]# vim dome38.sh
#!/bin/bash
arr1=(10 20 30 40 50)
for i in ${
arr1[@]}
do
echo $i
done
Três, corte de matriz
arr2=(1 2 3 4 5 6)
echo ${
arr2[*]}
echo ${
arr2[@]:0:2} #获取 ${
数组名[@或*]:起始位置:长度} 的值
echo ${
arr2[@]:1:3}
echo ${
arr2[@]:3:4}

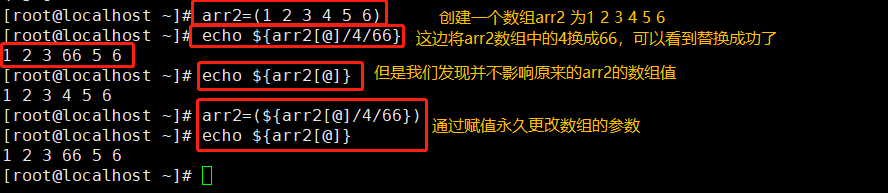
Quatro, substituição de matriz
arr2=(1 2 3 4 5 6)
echo ${
arr2[@]/4/66} # ${
数组名[@或*]/查找字符/替换字符}
echo ${
arr2[@]} #并不会替换数组原有内容
arr2=(${
arr2[@]/4/66}) #要实现改变原有数组,可通过重新赋值实现
echo ${
arr2[@]}
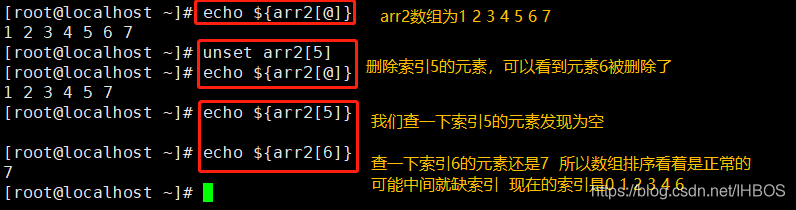
Cinco, exclusão de array
echo ${
arr2[@]}
unset arr2
echo ${
arr2[@]}

arr2=(1 2 3 4 5 6 7)
echo ${
arr[*]}
unset arr[5] #删除数组中选择索引对应的元素
echo ${
arr[*]}
echo ${
arr[6]}
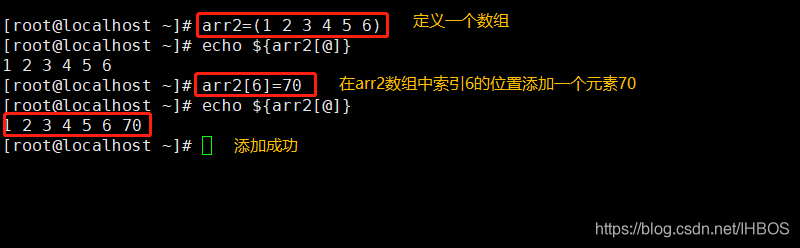
Seis, adicione elementos ao array
方法一:根据索引单个添加元素
array_name[index]=value
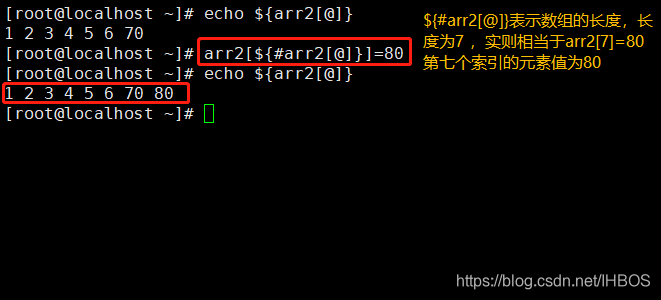
方法二:
array_name[${
#array_name[@]}]=value
方法三:
array_name=("${#array_name[@]}" value1 value2 ... valueN)
双引号不能省略,否则数组中存在包含空格的元素时会按空格将元素拆分成多个
不能将“@”替换为“*”,如果替换为“*”,不加双引号时与“@”的表现一致,加双引号时,会将数组array_name中的所有元素作为一个元素添加到数组中
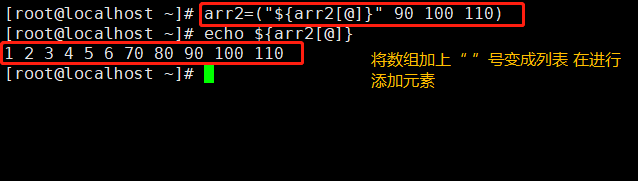
方法四:
array_name+=(value1 value2 ... valueN)
注:待添加元素必须用“()”包围起来,并且多个元素用空格分隔

Sete, passe parâmetros de array para a função
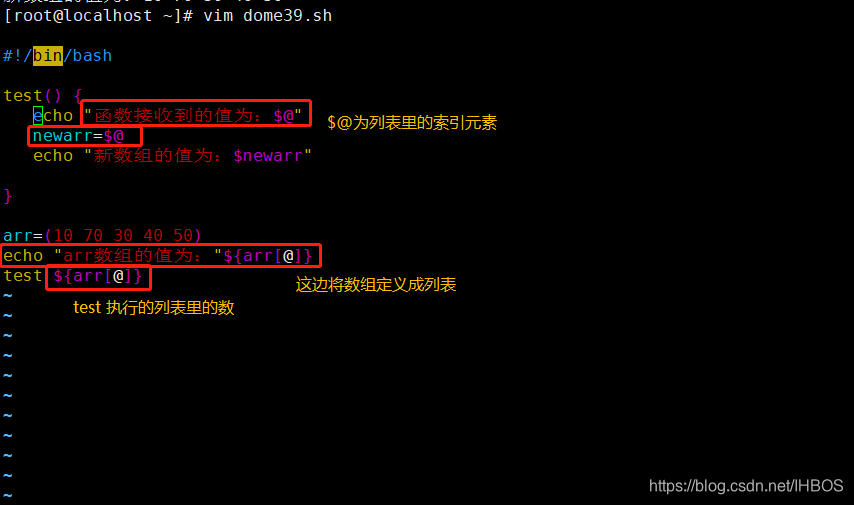

Oito, algoritmo de classificação
1. Algoritmo de classificação de bolhas
Semelhante ao surgimento de bolhas, os dados continuarão a avançar na matriz, de pequenos a grandes ou de grandes a pequenos.
-
Ideia básica:
a ideia básica da classificação por bolha é comparar os valores de dois elementos adjacentes. Se as condições forem atendidas, os valores dos elementos são trocados, o elemento menor é movido para a frente da matriz e o elemento maior é movido para a parte de trás da matriz (ou seja, troque duas posições de cada elemento), de modo que o elemento menor suba de baixo para cima como uma bolha. -
Ideia do algoritmo: o
algoritmo de bolha é implementado por um loop de camada dupla, onde o loop externo é usado para controlar o número de rodadas de classificação. Geralmente, o comprimento da matriz a ser classificada é reduzida em 1, porque há apenas uma matriz elemento deixado no último loop e nenhuma comparação é necessária. A classificação foi concluída. O loop interno é usado principalmente para comparar o tamanho de cada elemento adjacente na matriz para determinar se deve-se trocar as posições.O número de comparações e trocas diminui com o número de rodadas de classificação.
#!/bin/bash
arr=(5 1 9 3 6 4)
echo "原数组的排序:${arr[@]}"
length=${
#arr[@]}
#定义比较轮数,比较轮数为数组长度减1,从1开始
for ((i=1; i<$length; i++))
do
#确定比较元素的位置,比较相邻两个元素,较大的数往后放,比较次数随着比较轮数而减少
for ((a=0; a<$length-i; a++))
do
#定义第一个元素的值
first=${
arr[$a]}
#定义第二个元素的值
second=${
arr[$a+1]}
#如果第一个元素比第二个元素大就互换
if [ $first -gt $second ]
then
#把第一个元素值保存到一个临时变量中
temp=$first
#把第二个元素值赋给第一个元素
arr[$a]=$second
#把临时变量(也就是第一个元素的原值)赋给第二个元素
arr[$a+1]=$temp
fi
done
done
echo "排序后的数组为:${arr[@]} "


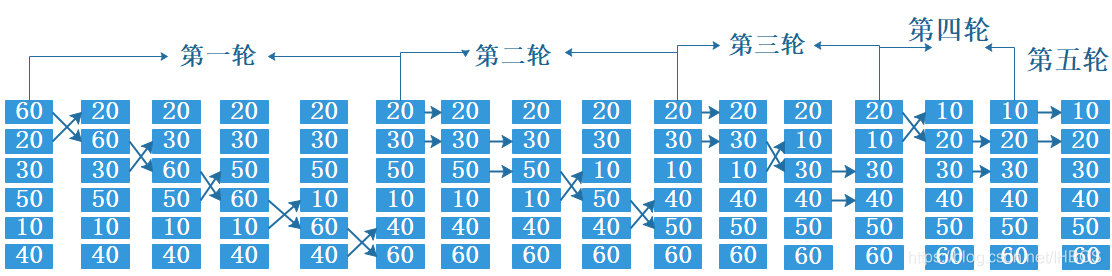
2. Selecione diretamente a classificação
-
Em comparação com a classificação por bolha, a classificação por seleção direta tem menos trocas, por isso é mais rápida.
-
A ideia básica:
comparar a posição de classificação especificada com outros elementos da matriz separadamente. Se a condição for atendida, o valor do elemento será trocado. Observe que a diferença entre a classificação por bolha não é trocar elementos adjacentes, mas trocar os elementos que atendem a com a posição de classificação especificada (como Classificar a partir do último elemento), de modo que a posição de classificação se expanda gradualmente e, finalmente, toda a matriz se torna o formato classificado.
#!/bin/bash
arr=(60 20 30 50 10 40)
echo "原数组元素顺序为:${arr[@]}"
length=${
#arr[@]}
#定义排序轮数
for ((i=1; i<$length; i++))
do
#假设索引为0的元素是最大的
index=0
#定义和第一个元素比较的索引,来确定最大的元素索引
for ((a=1; a<=$length-$i ;a++))
do
#定义最大的元素的值
max=${
arr[$index]}
#定义从索引1开始比较的元素值
yuansu=${
arr[$a]}
#判断如果从索引1开始比较的元素大于当前最大元素的值,就记录最大值的索引到index
if [ $yuansu -gt $max ]
then
index=$a
fi
done
#定义每一轮比较的最后一个元素的索引
last=$[$length-$i]
#把当前轮次的最后一个元素的值赋给临时变量temp
temp=${
arr[$last]}
#把最大的值赋给当前轮次的最后一个元素
arr[$last]=${
arr[$index]}
#把temp里的原来最后一个元素的值赋给原最大值所在索引的元素
arr[$index]=$temp
done


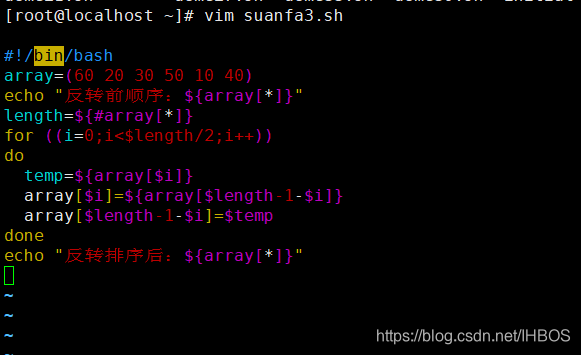
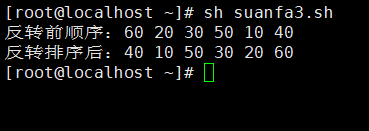
3. Inverta a classificação
-
Reordene o conteúdo da matriz original na ordem inversa
-
A ideia básica:
substitua o último elemento do array pelo primeiro elemento. O penúltimo elemento é substituído pelo segundo elemento, e assim por diante, até que todos os elementos da matriz sejam revertidos e substituídos
#!/bin/bash
array=(60 20 30 50 10 40)
echo "反转前顺序:${array[*]}"
length=${
#array[*]}
for ((i=0;i<$length/2;i++))
do
temp=${
array[$i]}
array[$i]=${
array[$length-1-$i]}
array[$length-1-$i]=$temp
done
echo "反转排序后:${array[*]}"