Primeiro conhecimento do tipo de inserção
A classificação por inserção também é um algoritmo de classificação relativamente simples. A ideia é pegar o primeiro elemento da matriz como uma sequência que foi classificada e, em seguida, pegar os elementos restantes na matriz da esquerda para a direita, um elemento por vez, e inseri-los na sequência ordenada à esquerda Continue para expandir o comprimento da sequência ordenada à esquerda até que toda a matriz seja ordenada.
O diagrama é o seguinte
Suponha que você vai inserir o seguinte array

Primeiro adicione o primeiro elemento à sequência ordenada

Em seguida, pegue o primeiro elemento da parte não classificada e insira o elemento na posição apropriada na sequência ordenada à esquerda

O primeiro elemento da parte não classificada é 3, e verifica-se que 3 deve ser inserido antes de 9
Então, os resultados da primeira rodada de inserção são os seguintes

Continue para a próxima rodada, pegue o primeiro elemento da parte não classificada , 6

Insira 6 na posição apropriada na sequência ordenada à esquerda, ou seja, entre 3 e 9

Continue para a próxima rodada, pegue o primeiro elemento 1 da parte não classificada da matriz e descubra que 1 deve ser inserido à esquerda de 3

Continue para a próxima rodada, 4 é inserido entre 3 e 6

Na próxima rodada, 2 é inserido entre 1 e 3

… Por fim, todo o array está ordenado

Observação: insira um número em uma posição apropriada na sequência ordenada. Este processo pode ser implementado de várias maneiras. O mais simples é usar um processo semelhante ao borbulhamento, comparando e trocando constantemente dois números adjacentes, e sempre trocando os elementos a serem inseridos na posição adequada. De acordo com essa ideia, o código para classificação por inserção é o seguinte
public void insertSort(int[] array) {
/*不断地将数字插入到合适的位置,扩大有序序列的边界 */
for (int sortedSize = 1; sortedSize < array.length; sortedSize++) {
for (int i = sortedSize - 1; i >= 0 ; i--) {
if (array[i + 1] < array[i]) {
swap(array, i + 1, i);
} else {
break;
}
}
}
}
Ideias de otimização
Ideia Um
Alterar comparação e troca para atribuição unilateral
A classificação de inserção acima realmente tem espaço para otimização. Porque em cada rodada de classificação, você só precisa encontrar uma posição adequada. Na implementação acima, o processo de encontrar uma posição de inserção adequada é realizado por meio da troca constante de elementos. Cada vez que dois números são trocados, três operações de atribuição são necessárias . Em outras palavras, podemos realmente colocar os elementos a serem inseridos do zero e, em seguida, ser inseridos nos elementos e elementos em uma sequência ordenada da direita para a esquerda para comparação, desde que a sequência ordenada de elementos do que os elementos a serem inserido no grande Se for, mova sua posição na sequência ordenada para a direita um bit, de modo que toda vez que o lugar que precisa ser trocado for alterado para atribuição unilateral , apenas uma operação de atribuição seja necessária. Finalmente, depois de encontrar uma posição adequada, atribua diretamente o elemento armazenado temporariamente a ser inserido. O diagrama é o seguinte
Suponha que o estado da matriz em um determinado momento durante o processo de classificação por inserção seja o seguinte

O próximo elemento a ser inserido é 5, armazene-o temporariamente e, em seguida, começando do elemento mais à direita na sequência ordenada, compare-o com 5 por sua vez e descubra que 9 é maior que 5, em seguida, atribua 9 unidirecionalmente à direita, sobrescrevendo 5. Logicamente falando, a posição original do 9 é realmente inútil, porque o 9 foi movido um lugar para a direita e, como armazenamos temporariamente o 5, não há necessidade de se preocupar em perdê-lo. Elementos inúteis são marcados em roxo na imagem abaixo

Em seguida, vá para a esquerda e olhe para o próximo elemento na sequência ordenada, 8

Compare 8 e 5, descubra que 8 é maior que 5, então 8 também é atribuído à direita, cobrindo o 9 roxo

Continue para a esquerda,
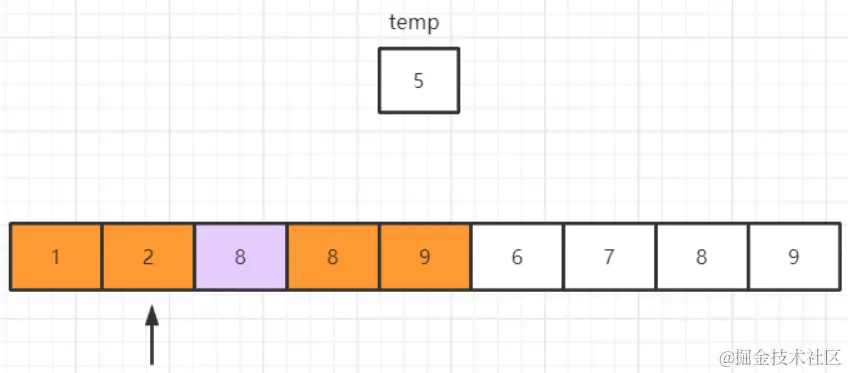
Comparando 2 e 5, verifica-se que 2 é menor que 5, indicando que uma posição de inserção adequada foi encontrada, e o 5 previamente armazenado temporariamente é atribuído à posição do elemento roxo em uma direção

Isso conclui esta rodada de classificação por inserção
Logicamente, equivale a mover os elementos maiores na sequência ordenada uma posição por vez para a direita, deixando um espaço para o elemento a ser inserido. Por ser uma atribuição unilateral, é menor que a troca de comparação anterior Muitas operações de atribuição foram realizadas, portanto, o desempenho irá melhorar. Mas é necessário um espaço extra para armazenar temporariamente os elementos a serem inseridos. De acordo com essa ideia, o código é escrito da seguinte maneira
public void insertSortV1(int[] array) {
for (int sortedSize = 1; sortedSize < array.length; sortedSize++) {
int temp = array[sortedSize];
int i = sortedSize;
while (i > 0 && array[i - 1] > temp) {
array[i] = array[i - 1];
i--;
}
array[i] = temp;
}
}
Ideia dois
Alterar pesquisa linear para pesquisa binária
Por causa de cada rodada de classificação de inserção, a chave é encontrar a posição de inserção apropriada , que na verdade é um processo de pesquisa. A implementação acima usa pesquisa linear, ou seja, a partir da extremidade direita da sequência ordenada e, em seguida, compara à esquerda até que uma posição adequada seja encontrada. A complexidade de tempo dessa busca é linear, ou seja, O (n). Podemos otimizar este processo de pesquisa substituindo a pesquisa linear pela pesquisa binária . A pesquisa binária é uma pesquisa de salto. Cada vez que a posição intermediária da sequência a ser pesquisada é tomada e comparada com o valor alvo. Se for menor que o valor alvo, continue em Pesquisar na metade direita, se for maior do que o valor de destino, continue a pesquisar na metade esquerda. A pesquisa binária pode reduzir o espaço de pesquisa pela metade a cada vez, e sua complexidade de tempo é O (log (n))
O código otimizado usando pesquisa binária é o seguinte
/**
* 二分查找
* @param left 左边界(inclusive)
* @param right 有边界(inclusive)
* */
private int binarySearch(int[] array, int left, int right, int target) {
while (left <= right) {
/* 取中间位置 */
int mid = (left + right) >> 1;
/*
* 临界情况有2种
* 1. 待查找区间还剩2个数 -> 此时 right = left + 1 , mid = left
* 1.1 若判断 arr[mid] > target, 则该查找左半部分,此时应该插入的位置是mid,也就是left
* 1.2 若判断 arr[mid] < target, 则该查找右半部分,此时应该插入的位置是mid + 1,也就是更新后的left
* 2. 待查找区间还剩3个数 -> 此时 right = left + 2 , mid = left + 1
* 2.1 若判断 arr[mid] > target, 则查找左半部分,回到情况1
* 2.2 若判断 arr[mid] < target,则查找右半部分,更新完后下一轮循环 left = right = mid,
* 若arr[mid] > target,则应插入的位置是left,若arr[mid] < target,则更新完后的left是应插入的位置
* */
if (array[mid] > target) {
/* 往左半边查找 */
right = mid - 1;
} else if (array[mid] < target) {
/* 往右半边查找 */
left = mid + 1;
} else {
/* 相等了,返回待插入位置为 mid + 1 */
return mid + 1;
}
}
return left;
}
@Override
public void insertSortBinarySearch(int[] array) {
for (int sortedSize = 1; sortedSize < array.length; sortedSize++) {
int temp = array[sortedSize];
/* 获得待插入的位置 */
int insertPos = binarySearch(array, 0, sortedSize - 1, temp);
/* 将待插入位置之后的有序序列,全部往后移一位 */
for (int i = sortedSize; i > insertPos ; i--) {
array[i] = array[i - 1];
}
array[insertPos] = temp;
}
}
Idéia 3
Tipo de colina
Hill sort é uma variante da ordenação por inserção. Sua ideia central é introduzir o conceito de tamanho do passo . Hill sort usa o tamanho do passo para dividir o array em muitos pequenos arrays, usa a classificação por inserção em cada pequeno array e, em seguida, reduz gradualmente o passo. Longo , o último passo é reduzido a um, e a classificação Hill com um passo de um é o tipo de inserção simples acima. Em comparação com a classificação por inserção simples, a vantagem da classificação Hill é que os elementos podem ser movidos em várias posições, enquanto a classificação por inserção simples original deve ser comparada um a um para encontrar uma posição de inserção adequada.
O diagrama de classificação de Hill é o seguinte, o tamanho do passo inicial é geralmente definido para metade do comprimento da matriz
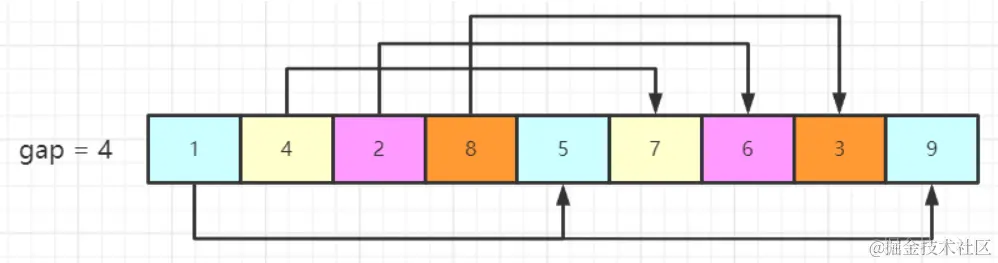
A matriz acima é dividida em 4 grupos de elementos de acordo com gap = 4. Os elementos cujo intervalo de posição é igual à lacuna são divididos no mesmo grupo. O primeiro grupo é [1,5,9], (5 e 1 são separados por 4 posições, 9 e 5 são separados por 4 posições ...) são marcados em azul claro, e o segundo grupo é [4,7] , É marcado como amarelo claro, o terceiro grupo é [2,6], que é marcado como roxo claro, e o quarto grupo é [8,3], que é marcado como laranja. Para cada grupo de elementos, uma classificação de inserção simples é executada e, em seguida, o valor da lacuna é reduzido e a classificação de inserção é continuada para cada grupo até que a lacuna seja reduzida a 1. A última rodada é equivalente a uma classificação de inserção simples. Como a classificação por inserção pode atingir alta eficiência quando a matriz é basicamente ordenada, a classificação Hill introduz o conceito de tamanho do degrau, que permite que os elementos sejam inseridos em várias posições sem ter que operar um por um. Após cada rodada de classificação Hill, toda a matriz se torna mais ordenada como um todo (pode-se entender que, após uma rodada de classificação Hill, os elementos na posição frontal de toda a matriz são os menores elementos em cada grupo, e as linhas Os seguintes elementos são os elementos maiores em cada grupo)
Após a primeira rodada de classificação Hill, o status da matriz é o seguinte (apenas as posições de 3 e 8 são trocadas)

Na segunda rodada de classificação Hill, a diferença é reduzida pela metade para 2

Insira e classifique os 2 grupos de elementos respectivamente, e os resultados são os seguintes (o primeiro grupo, marcado em azul claro, sem qualquer alteração; o segundo grupo, marcado em laranja, apenas as posições de 3 e 4 são trocadas)

Finalmente, gap = 1, execute a última rodada de classificação Hill (isso é equivalente a uma classificação por inserção simples)
A olho nu, podemos ver que a última rodada só precisa trocar 2 e 3, 6 e 7. Duas trocas, ou seja, classificação completa

A matriz acima é classificada por Hill, e a classificação é concluída após um total de 4 operações de troca serem realizadas, o que é muito eficiente. Se a classificação por inserção simples for usada, o número de operações de troca será maior que 4. Isso mostra o poder da classificação Hill. Com base no conteúdo acima, também podemos entender melhor o significado da classificação Hill, que também é chamada de classificação incremental reduzida . Tamanho do passo, incremento e intervalo são todos a mesma coisa. A escolha da sequência de incremento também afetará a eficiência da classificação de Hill.Normalmente, o incremento inicial é a metade do comprimento da matriz e, em seguida, a sequência de incremento é reduzida à metade a cada vez.
A implementação do código de classificação de Hill é a seguinte
public void shellSort(int[] array) {
for (int gap = array.length / 2; gap > 0; gap /= 2) {
for (int i = gap; i < array.length; i++) {
int j = i;
int temp = array[i];
/* 这里没有采用二分查找,直接使用的线性查找 */
while (j - gap >= 0 && array[j - gap] > temp) {
array[j] = array[j - gap];
j -= gap;
}
array[j] = temp;
}
}
}
Observe que, na implementação do código, deve-se atravessar diretamente da posição após a lacuna até o último elemento da matriz e, para cada elemento, a lacuna é incrementada e a classificação por inserção direta é executada para a frente. Isso é um pouco diferente da descrição da classificação por inserção para cada grupo de elementos no diagrama. A vantagem de escrever dessa maneira é que todo o código de classificação de Hill precisa de apenas 3 camadas de loops e é mais fácil de entender. De acordo com a descrição do diagrama, cada vez que o tipo de inserção de um grupo de elementos é usado como um loop, o código escrito requer 4 camadas de loops, o que não é fácil de entender. Os leitores interessados podem consultar o seguinte código
public void shellSort(int[] array) {
int gap = array.length / 2;
while (gap >= 1) {
for (int i = 0; i < gap; i++) {
/* 这一层循环就是对每一组元素进行插入排序 */
for (int j = i; j + gap < array.length; j += gap) {
int pos = j + gap;
while (pos - gap >= 0) {
if (array[pos] < array[pos - gap]) {
swap(array, pos, pos - gap);
pos -= gap;
} else {
break;
}
}
}
}
gap /= 2;
}
}
Teste de performance
Usando matrizes aleatórias que variam de 10.000 a 500.000, o teste de desempenho de cada algoritmo de classificação de inserção é realizado e o gráfico de linha é desenhado da seguinte maneira

Pode-se ver que o desempenho da classificação de Hill explodiu em outras versões. A segunda é otimizada por busca binária e a segunda é otimizada por atribuição unilateral. O desempenho não otimizado é o pior.