Artigo Diretório
1. Princípio de classificação rápida
A ideia básica deste método é:
- 1 Primeiro, pegue um número da sequência numérica como o número de referência.
- 2 No processo de particionamento, todos os números maiores que esse número são colocados no lado direito e todos os números menores ou iguais a ele são colocados no lado esquerdo.
- 3 Repita a segunda etapa para os intervalos esquerdo e direito até que haja apenas um número em cada intervalo.
最本质的总结: A
classificação rápida, para ser franco, é o processo de encontrar a posição de índice correta para os dados de referência.
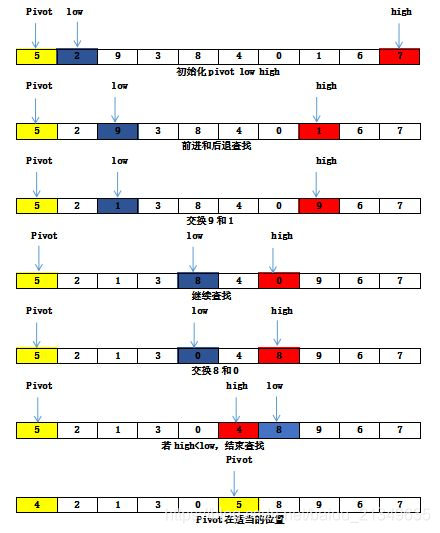
Conforme mostrado na figura abaixo, supondo que os dados de referência iniciais sejam o primeiro elemento 23 da matriz, primeiro use uma variável temporária para armazenar os dados de referência, ou seja, tmp = 23; em seguida, faça a varredura da matriz em ambas as extremidades da matriz e definir dois indicadores: pontos baixos para a posição inicial, pontos altos para o final.

Em primeiro lugar, a partir da segunda metade, se o valor varrido for maior que os dados de referência, deixe alto menos 1. Se houver um elemento que seja menor que o valor dos dados de referência (18 <= tmp na figura acima), atribuir o valor da posição alta à posição baixa, os resultados são os seguintes:
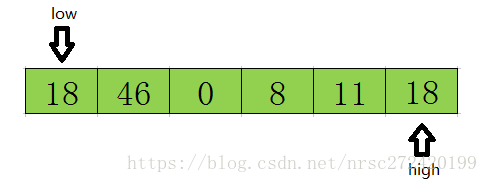
Em seguida, comece a varredura da frente para trás. Se o valor varrido for menor que os dados de referência, adicione 1 a baixo. Se um elemento for considerado maior do que o valor dos dados de referência (conforme mostrado na Figura 46 => tmp), em seguida, atribua o valor da posição inferior à posição alta. O resultado após o ponteiro se mover e a troca de dados é o seguinte:
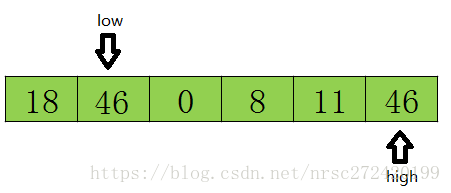
Em seguida, comece a varredura de trás para a frente. O princípio é o mesmo que acima, e verifica-se que a figura acima 11 <= tmp, então o valor da posição alta é atribuído ao valor da posição baixa, e os resultados são do seguinte modo:
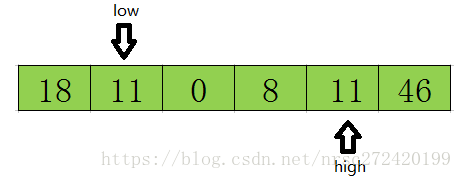
Em seguida, comece a percorrer da frente para trás até que low = high termine o loop, neste momento o subscrito de low ou high é 基准数据23在该数组中的正确索引位置como mostrado na figura abaixo.
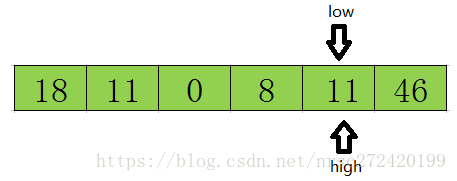
Depois de descer dessa forma, você pode saber claramente que, na verdade 快速排序的本质就是把基准数大的都放在基准数的右边,把比基准数小的放在基准数的左边,这样就找到了该数据在数组中的正确位置.
, a primeira metade e a segunda metade são classificadas separadamente de maneira recursiva no futuro. Quando a metade atual e a segunda metade estiverem em ordem, a matriz será naturalmente ordenada .
2. Idéias de código
Você pode ver no processo acima:
- ① Avance a partir do final da linha e quando baixo <alto, se a [alto]> tmp, então alto -, mas se a [alto] <tmp, então atribua o valor de alto a baixo, ou seja, arr [baixo] = a [alto], ao mesmo tempo, o método de varredura do array precisa ser alterado, ou seja, ele precisa fazer a varredura desde o início da equipe até o final da equipe
- ② Da mesma forma, ao escanear do chefe da equipe até o final da equipe, se um [baixo] <tmp, então baixo ++, mas se um [baixo]> tmp, você precisa atribuir o valor da posição inferior ao posição alta. Ou seja, arr [baixo] = arr [alto] e, ao mesmo tempo, altere o modo de varredura da matriz para varredura do final da linha para o início da linha.
- ③ Continue repetindo ① e ②, sabendo que baixo> = alto (na verdade, baixo = alto), a posição de baixo ou alto é a posição de índice correta dos dados de referência na matriz ...
3. Encontre o índice do número de referência
Aqui está outra foto para aprofundar a impressão de encontrar o índice;
4. Código de referência
import java.util.Arrays;
public class QuickSort {
public static void main(String[] args) {
int[] arr = {
49, 38, 65, 97, 23, 22, 76, 1, 5, 8, 2, 0, -1, 22 };
quickSort(arr, 0, arr.length - 1);
System.out.println("排序后:");
for (int i : arr) {
System.out.print(i + " ");
}
}
private static void quickSort(int[] arr, int low, int high) {
if (low < high) {
// 找寻基准数据的正确索引
int index = getIndex(arr, low, high);
System.out.println("排序后" + Arrays.toString(arr));
// 进行迭代对index之前和之后的数组进行相同的操作使整个数组变成有序
//quickSort(arr, 0, index - 1); 之前的版本,这种姿势有很大的性能问题,谢谢大家的建议
quickSort(arr, low, index - 1);
quickSort(arr, index + 1, high);
}
}
private static int getIndex(int[] arr, int low, int high) {
// 基准数据
int tmp = arr[low];
while (low < high) {
// 当队尾的元素大于等于基准数据时,向前挪动high指针
while (low < high && arr[high] >= tmp) {
high--;
}
// 如果队尾元素小于tmp了,需要将其赋值给low
arr[low] = arr[high];
// 当队首元素小于等于tmp时,向前挪动low指针
while (low < high && arr[low] <= tmp) {
low++;
}
// 当队首元素大于tmp时,需要将其赋值给high
arr[high] = arr[low];
}
// 跳出循环时low和high相等,此时的low或high就是tmp的正确索引位置
// 由原理部分可以很清楚的知道low位置的值并不是tmp,所以需要将tmp赋值给arr[low]
arr[low] = tmp;
return low; // 返回tmp的正确位置
}
}
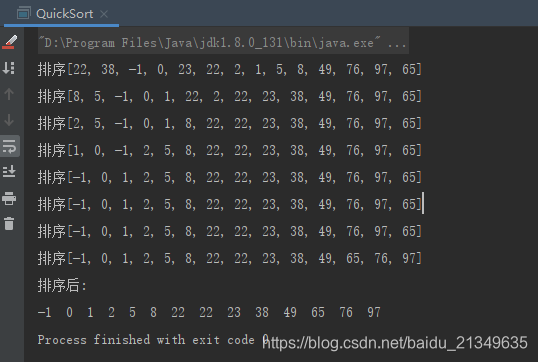
Os efeitos operacionais são os seguintes:
Artigo de referência:
https://blog.csdn.net/nrsc272420199/article/details/82587933
https://github.com/doubleview/data-structure
Terminar