Há algo de errado, por favor me corrijam
bubble Sort
A idéia central
Se o número n dispostos em ordem crescente, de trás para a frente ascendente tamanho comparação par a par adjacente (acho que é melhor entendido), se o primeiro do que o último sobre uma grande imediatamente transposição Talia colocar, posição direta troca, o primeiro passo para baixo a maior no último, após o último sem comparação, pela segunda vez, a segunda maior em segundo lugar. . . . . . Comparação da primeira passagem do n-1 vezes, permutado vezes incerto, compara o segundo tempo n-2 vezes. . . . .
void bubble_sort(int a[],int n)
{
int tem=0;
for(int i=n-1;i>0;--i)
{
for(int j=0;j<i;++j)
{
if(a[j]>a[j+1])
{
tem=a[j];
a[j]=a[j+1];
a[j+1]=tem;
}
}
}
}
seleção Classificar
A idéia central
Os métodos específicos são:
Atravessando uma gravação da localização dos elementos mais valiosos, o fim do percurso, o valor deste elemento é ajustado para a posição mais apropriada de
primeira passagem, comparar vezes n-1, apenas uma troca, será a colocação correcta do valor da mais
void sort(int a[],int n){
for(int i=0;i<n;i++)//外层循环
{
int min=a[i];//每次循环把a[i]假设当前最小的数
int index=i;//相当一个索引,始终指向最小的
for(int j=i+1;j<n;j++)//内层循环,从剩下的数中找有没有更小的
{
if(a[j]<min)
{
min=a[j];
index=j;//跟新索引
}
}
int temp=a[index];//交换
a[index]=a[i];
a[i]=temp;
}
}
改进
void select_sort(int a[],int n)
{
int k,temp;
for(int i=0;i<n-1;i++)
{
k=i;//假设最小为a[i],用k标记
for(int j=i+1;j<n;j++)//内层循环,从剩下的数中找有没有更小的
{
if(a[j]<a[k])
{
k=j;//找到新的最小的,跟新k的值
}
}
if(i!=k)//比较i和k的值,判断是否交换
{
temp=a[i];
a[i]=a[k];
a[k]=temp;
}
}
}
A diferença no
caso em que os mesmos dados, o número de ciclos dos dois algoritmos é a mesma, o mesmo número de comparações, mas de selecção de ordenação apenas 0-1 vezes o câmbio, e troca de tipo bolha apenas 0 a n vezes.
A parte principal do algoritmo afetar o nosso desempenho é a circulação eo intercâmbio, obviamente, mais o número, pior o desempenho. É complexidade de O (N * N). Mas a eficiência de diferente
espécie de bolha:
quando os dados no caso inverso, o mesmo número de ciclos como a troca (a troca será determinada em cada ciclo),
uma complexidade em O (N * N). Quando os dados são positivos, não haverá troca. A complexidade é S (0). Desordem num estado intermédio. É por esta razão, são geralmente algoritmo para comparar o número de ciclos.
tipo de selecção:
Como cada circuito externo gera apenas uma troca (apenas um mínimo). Portanto, f (n) <= n
temos f (n) = O (n ). Então, mais caos nos dados, pode reduzir o número de vezes que uma determinada troca.
Classificação rápida
A idéia central:
inserção Sort
A idéia central:
ordenação por inserção que cada passo será uma linha de dados a ser inserido no tamanho adequado de acordo com sua posição já classificadas dados até que todos cued.
1, começando a partir do primeiro elemento que um [0] pode ser considerado como tendo sido classificados.
2, vai buscar o próximo elemento da sequência de elementos foi ordenada na digitalizada da parte de trás
3, se o elemento a [0] (ordenadas), um novo elemento é maior do que a [1], em seguida, os elementos de uma [0] mudança para a próxima posição
4, 3 repetido até encontrar a localização é menos do que ou igual a elementos ordenados de novo o elemento
5, o novo elemento é inserido na posição
6 foi repetido 2
método de inserção Classificar para classificar e dividir diretamente na inserção binário tipo são dois, aqui apenas inserção direta classificar, inserção binário espécie Veja outro artigo http://blog.csdn.net/qq_29232943/article/details/52939374
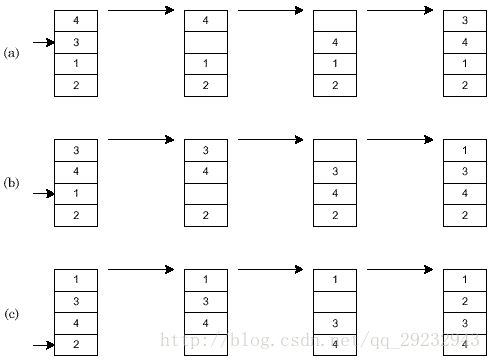
1 cartas de apresentação os quatro elementos do processo directamente para a espécie, de um total de (a), (b), (c) interpolação cúbico.
#include <iostream>
using namespace std;
void insert_sort(int a[],int n);
int main()
{
int a[]={3,41,369,1,2,4,5,9};
int n=8;
insert_sort(a,n);
for(int i=0;i<n;i++)
{
cout<<a[i]<<" ";
}
return 0;
}
void insert_sort(int a[],int n)
{
for (int i=1;i<n;i++)
{
for(int j=i;(j>0)&&(a[j]<a[j-1]);j--)
{
int tem=a[j];
a[j]=a[j-1];
a[j-1]=tem;
}
}
}
O melhor caso, as já ascendente, apenas n-1 comparações, o pior caso, é descendente, de n (n-1) / comparações
complexidade média de O (n2)
