Prefácio
Isso é principalmente para construir hadoop 2.8.3 sob centos7. Ele registra a compilação do Hadoop com mais detalhes. Ele registra e resolve alguns erros encontrados na Internet e em I. Embora a compilação possa não ser muito difícil, a primeira compilação, eu também encontrou muitos erros, mas demorou uma noite e uma tarde para construir com sucesso. Registre os amigos que esperam ajudar outros parceiros de aprendizagem.
Pronto para trabalhar
Ambiente Java jdk1.8

hadoop2.8.3
Modificar o nome do host
Desligue o firewall

Criar usuário hadoop
Começar
- Modifique a configuração de rede da máquina virtual NAT, defina o segmento de sub-rede da máquina virtual
Método de modificação: pesquisa local -> edição de rede virtual

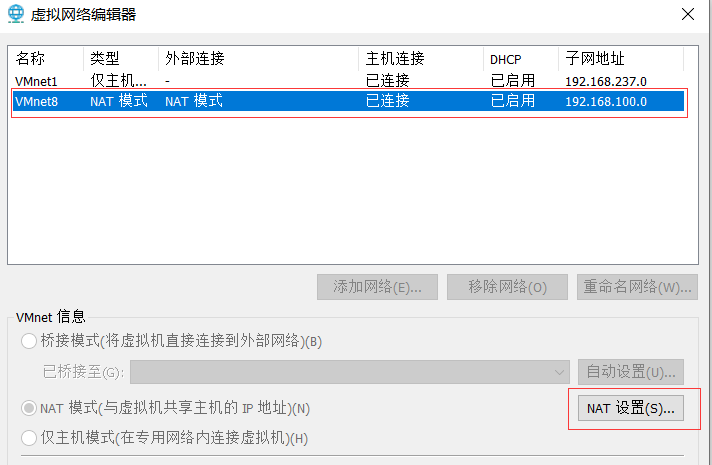
- Aqui, modifique o segmento de sub-rede padrão, que é 192.168.100. Meu segmento de rede anterior é 192.168.85 . Lembre-se do endereço IP do segmento de rede aqui, que é necessário para configuração na máquina virtual abaixo.
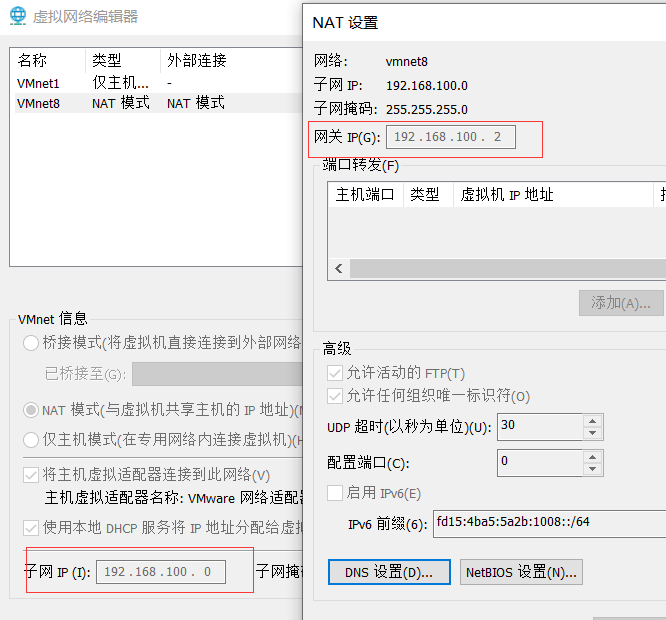
- Após modificar o endereço IP da sub-rede, o IP correspondente configurado na máquina virtual deve estar neste segmento de rede.

- Modificar o nome do host
Existem duas maneiras de modificar o nome do host, uma é a modificação temporária, que se torna inválida após a reinicialização, e a outra é a modificação permanente.
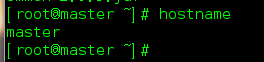
Primeiro verifique o nome do host da máquina:
root@master ~]# hostname
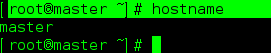
Meu nome de host modificado, você deve ser localhost.localhost antes de modificá-lo
Aqui, sugiro que você use a modificação temporária.
[root@master ~]# hostname master
Para modificações permanentes, consulte: https://www.cnblogs.com/zhangwuji/p/7487856.html
- Desligue o firewall
Para referência, aqui está como fechar centos7: https://blog.csdn.net/ytangdigl/article/details/79796961
- Ao desligar o firewall aqui, ajude o selinux a desligar também. selinux é um mecanismo de sub-segurança do Linux.
vim /etc/sysconfig/selinux
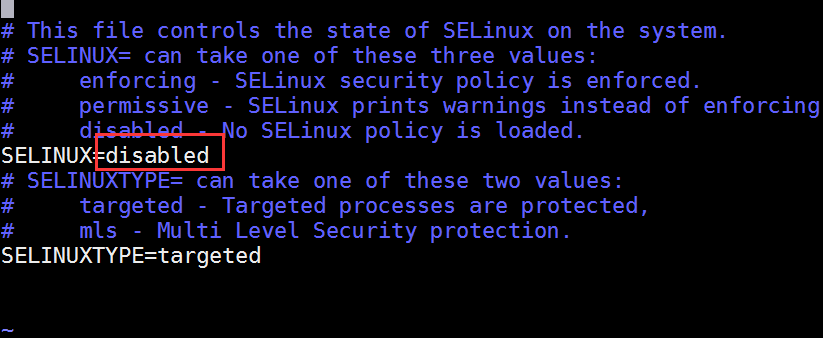
- Crie hadoop de usuário e conceda privilégios de root.
Este é um comando básico do Linux, então você não pode verificar o Baidu, é relativamente simples.
- Como já criei o hadoop, aqui vou criar o hadoop1.
[root@master ~]# useradd hadoop1
[root@master ~]# passwd hadoop1
- Dê ao usuário hadoop1 a permissão sudo. Depois de dar a permissão sudo, precisamos adicionar um sudo antes de executar o comando
[root@master ~]# vim /etc/sudoers
Adicionar extrato
root ALL=(ALL) ALL
hadoop1 ALL=(root) NOPASSWD:ALL

- Ver usuário atual
[root@master ~]# cat /etc/passwd

- Teste o usuário: su

- Instale o jdk
- Instalar o jdk é relativamente simples, não vou introduzir muito aqui, aqui devemos lembrar o caminho de instalação do jdk.
- Desinstalar jdk existente
- Consulte se deseja instalar o software Java:
rpm -qa | grep java
- Se a versão instalada for inferior a 1.7, desinstale o JDK:
sudo rpm -e 软件包
- Coloque o pacote de instalação jdk na máquina virtual e descompacte-o. Aqui criamos um diretório para salvar o software.
mkdir -p /opt/modulel
将解压后的Jdk放到这个目录下,防止忘记Java的安装位置。
- Configurar variáveis de ambiente JDK
打开/etc/profile文件
sudo vi /etc/profile
在profile文件末尾添加JDK路径
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_144
export PATH=$PATH:$JAVA_HOME/bin
- Deixe o arquivo modificado entrar em vigor
source /etc/profile
- Teste se o JDK foi instalado com sucesso
Java -version

- Instalar hadoop
Antes de instalar o hadoop, certifique-se de que a instalação do jdk está correta. Caso contrário, o hadoop não funcionará normalmente.
- baixar
https://archive.apache.org/dist/hadoop/common/hadoop-2.7.2/
- Descompacte ou descompacte hadoop para / opt / module acima.
- Abra o arquivo / etc / profile
sudo vi /etc/profile
在profile文件末尾添加JDK路径:(shitf+g)
##HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-2.7.2(这个改成你的hadoop版本)
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
- Sair depois de salvar
- Deixe o arquivo modificado entrar em vigor
source /etc/profile
- Teste se a instalação foi bem sucedida
hadoop version (注意没有-)

hadoop run
- Os modos operacionais do Hadoop incluem: modo local, modo pseudo-distribuído e modo totalmente distribuído
- O modo local e o modo pseudo-distribuído são usados principalmente aqui.
Modo **** de operação local
- Caso oficial Grep
- Crie uma pasta wcinput sob o arquivo hadoop2.8.3
mkdir wcinput
- Crie um arquivo wc.input no arquivo wcinput
cd wcinput
touch wc.input
- Edite o arquivo wc.input
hadoop yarn
hadoop mapreduce
atguigu
atguigu
- Volte para o diretório do Hadoop /opt/module/hadoop-2.8.2
- executar programa
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount wcinput wcoutput
Explique a consciência desta frase: Este é um programa hadoop. Este pacote jar é um arquivo que vem com o hadoop. No caso do wordcount, wcinput é a pasta de entrada seguida pela saída para essa pasta.
- Ver resultados
cat wcoutput/part-r-00000
atguigu 2
hadoop 2
mapreduce 1
yarn 1
Executado localmente com sucesso
Modo operacional pseudo-distribuído
- degrau
- Configure o cluster
- Inicie, teste a adição, exclusão e verificação do cluster
- Implementação do caso WordCount
- Configure o cluster
Configuração: hadoop-env.sh add JAVA_HOME Road King
export JAVA_HOME=/opt/module/jdk1.8.0_144
- Posicionamento: core-site.xml
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://master(你的主机名):9000</value>
</property>
<!-- 指定Hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-2.7.2/data/tmp</value>(这个是用来存放hadoop执行生成的数据文件夹)
</property>
- Configuração: hdfs-site.xml
<!-- 指定HDFS副本的数量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property
- Inicie o cluster
- Formate o NameNode (formate-o na primeira inicialização e não o formate o tempo todo). Preste atenção a isso. Não formate-o com frequência. A formatação frequente pode facilmente levar a erros na correspondência de nó subsequente.
- Inicie o NameNode
sbin/hadoop-daemon.sh start namenode
- Iniciar DataNode
sbin/hadoop-daemon.sh start datanode
- Iniciar SecondaryNameNode
sbin/hadoop-daemon.sh start secondarynamenode
- Comando JPS para verificar se foi iniciado com sucesso, se houver um resultado, o início foi bem sucedido
输入jps出现
3034 NameNode
3233 Jps
3193 SecondaryNameNode
3110 DataNode
表示成功
- Depois que a inicialização for bem-sucedida, você pode verificar se ela foi bem-sucedida na web
http: // hadoop101: 50070 / dfshealth.html # tab-overview
Observação: se você não conseguir visualizá-lo, consulte a seguinte postagem para processamento: http://www.cnblogs.com/zlslch/p/6604189.html
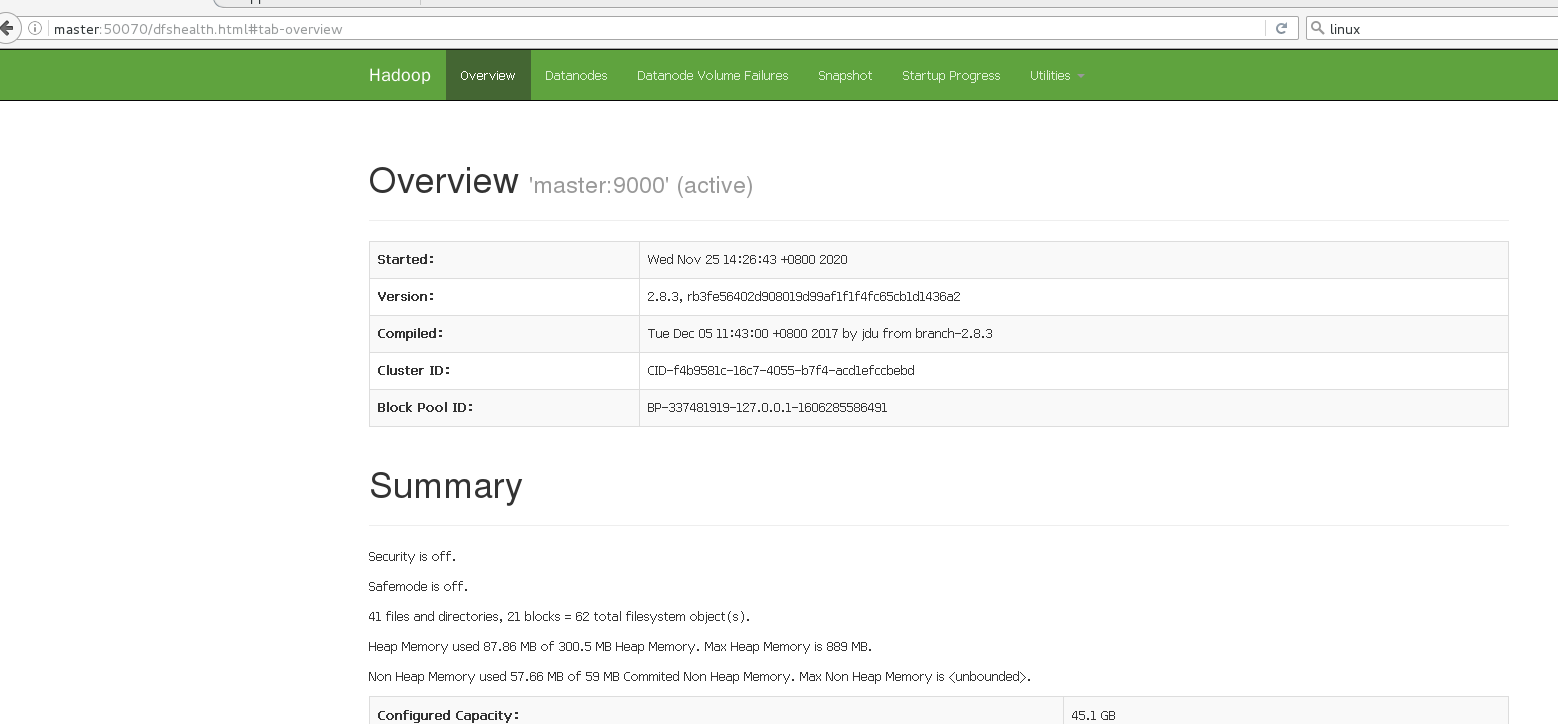
Cluster de operação (HDFS)
- Crie uma pasta de entrada no sistema de arquivos HDFS
bin/hdfs dfs -mkdir -p /user/atguigu/input
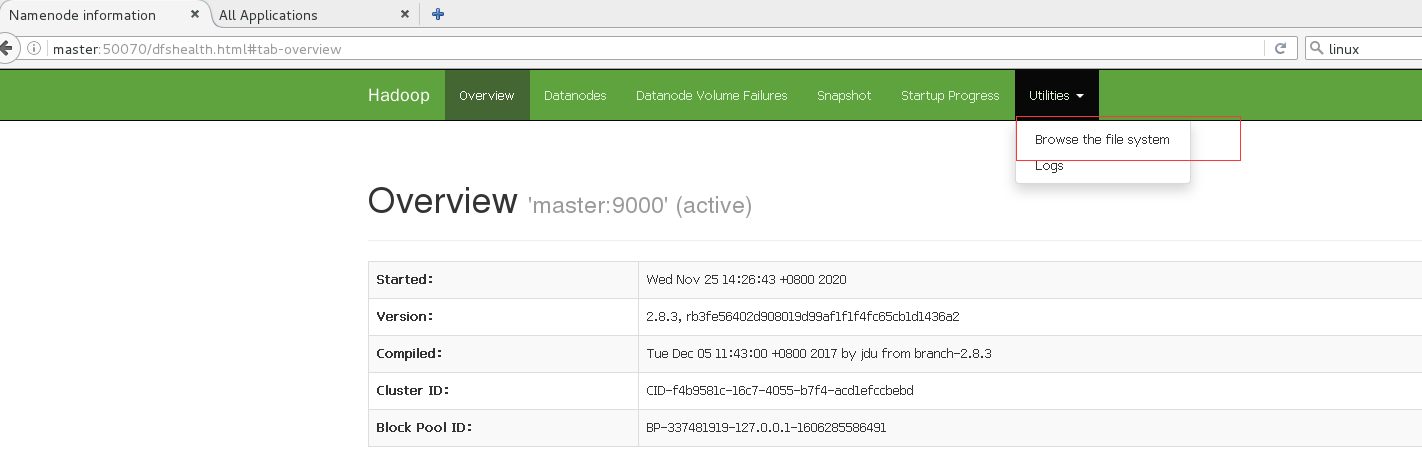
- Carregue o conteúdo do arquivo de teste para o sistema de arquivos, aqui carregamos a pasta wc.input que criamos anteriormente
bin/hdfs dfs -mkdir -p /user/atguigu/input

- Execute o programa MapReduce
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.3.jar wordcount /user/atguigu/input/ /user/atguigu/output
Depois que a operação for bem-sucedida, dois arquivos aparecerão no diretório de saída, indicando que a execução foi bem-sucedida.

- Exclua o resultado de saída, porque enviaremos o arquivo para a saída mais tarde. Se esta pasta existir, pode haver conflito, portanto, exclua-a primeiro.
hdfs dfs -rm -r /user/atguigu/output
Inicie o YARN e execute o programa MapReduce
- degrau
- Configure o cluster para executar MR no YARN
- Inicie, teste a adição, exclusão e verificação do cluster
- Executando o caso WordCount no YARN
- Configure o cluster, configure yarn-env.sh, adicione uma instrução no final do arquivo
export JAVA_HOME=/opt/module/jdk1.8.0_144(这里的jdk改为你的版本)
- Canal yarn-site.xml
<!-- Reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
- Configuração: mapred-env.sh, adicione também java_home
export JAVA_HOME=/opt/module/jdk1.8.0_144
- Configuração: (Renomear mapred-site.xml.template para) mapred-site.xml
mv mapred-site.xml.template mapred-site.xml
vi mapred-site.xml
添加
<!-- 指定MR运行在YARN上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
- Inicie o cluster
- Antes de começar, você deve garantir que o NameNode e DataNode foram iniciados, use jps para verificar se eles foram iniciados
- Inicie o ResourceManager que foi iniciado antes, não se preocupe com isso
- Iniciar NodeManager
sbin/yarn-daemon.sh start nodemanager
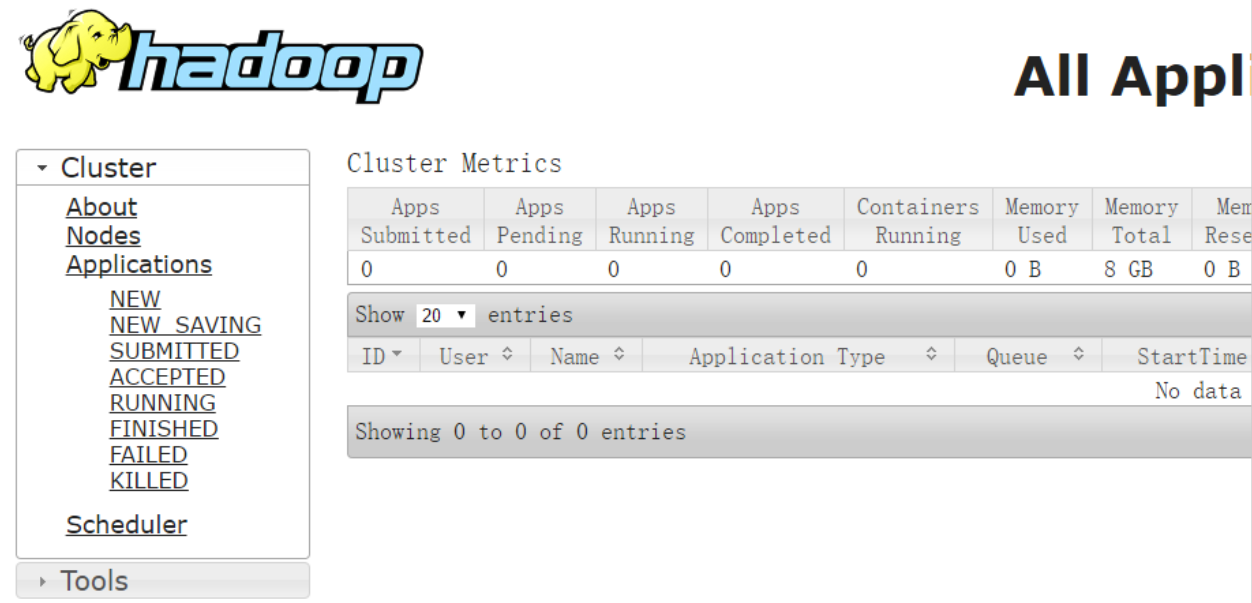
- Visualização da página do navegador YARN http: // master: 8088 / cluster
- Execute o programa MapReduce e exclua o diretório de saída antes para evitar conflito com isso, mas você pode modificar o nome da pasta de saída, por exemplo, output1.
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.3.jar wordcount /user/atguigu/input /user/atguigu/output
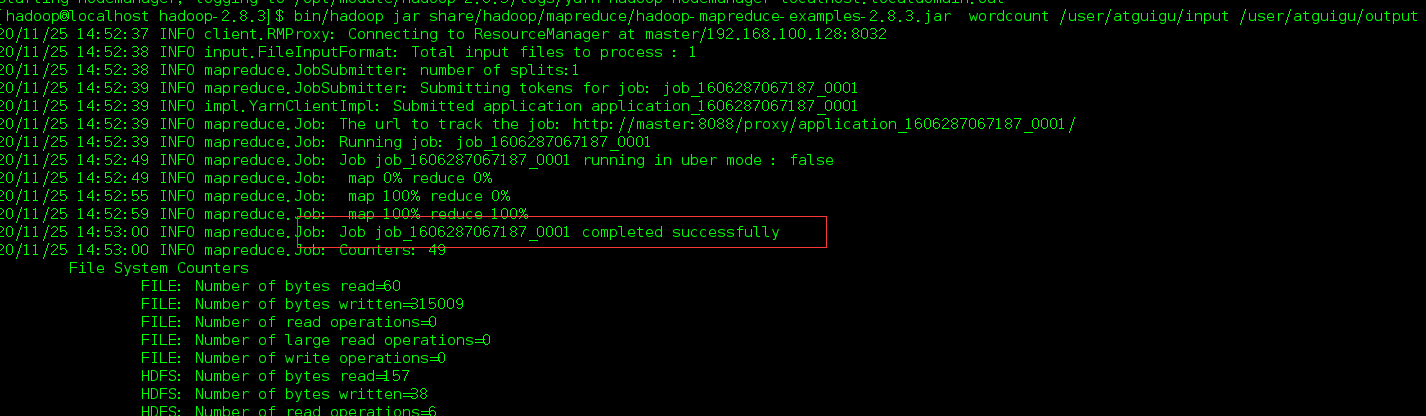
Isso indica sucesso, verifique no lado da web.
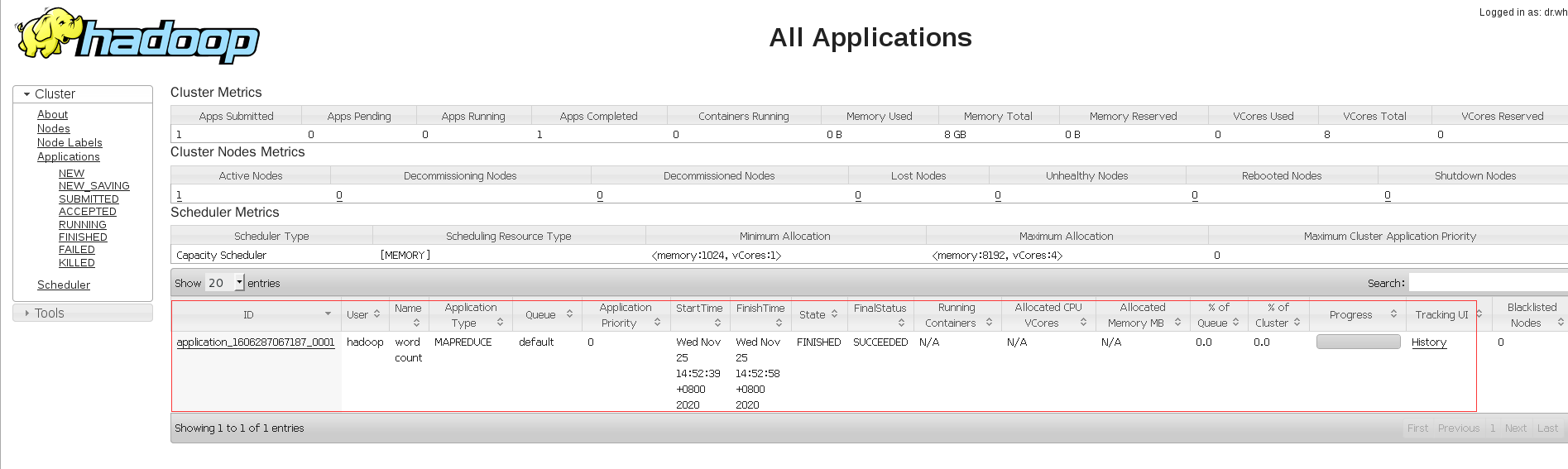
sucesso.
problema
- Aqui eu explico principalmente os erros encontrados por alguns hadoops grandes.O maior problema é o problema que me fez construir várias vezes e outra vez, ou seja, a última etapa está travada.
Resolvi isso fazendo referência a: https://blog.csdn.net/wjw498279281/article/details/80317424
- Além disso, o upload falhou quando o arquivo foi carregado por HDFS no final. Esse problema era principalmente porque o firewall não estava desligado. Na verdade, ele não foi desligado porque eu o desliguei no root e finalmente mudei para hadoop, mas o upload falhou.
A solução para isso: https://blog.csdn.net/qq_44702847/article/details/105403388
3 - Existem alguns outros erros, mas o primeiro problema me mantém preso na última etapa.
Conclusão
Esta é a primeira vez que construo hadoop, por favor, grave-o. Após a configuração, pode-se considerar um pequeno entendimento da construção do hadoop.