1, necessita de um ambiente
de três diferentes máquinas (não apenas o mesmo processo) que namenode e secondaryNode não na mesma máquina e ResourceManager também precisam de ser colocado numa máquina separada
2, a configuração da máquina-relacionada virtuais
precisamos de três máquinas virtuais primeira clonagem de uma máquina virtual a partir da base da máquina (mais primitivo sistema de máquina) e, em seguida, nesta máquina virtual para fazer toda a configuração básica e, em seguida, através desta máquina virtual dois ainda clonados.
Configuração básica:
* Alterar a senha de root
* ssh instalado
privilégios * ssh root para abrir -> cluster deve ser aberto quando
* Modificar hostname
* Modificar anfitriões
* instalar o JDK e software Hadoop
* para configurar um IP estático -> Este é o primeiro passo após a clonagem não terminar as restantes duas máquinas virtuais para fazer (porque os padrões de máquina virtual para DHCP para atribuir IP de modo cada vez que você iniciar a máquina virtual não pode ser a mesma conexão IP também são muito problemáticas é necessário definir um IP estático para que IP depois de tudo não muda)
Aqui tiros operações relacionadas são os seguintes:
Alterar a senha de root: Use o sudo passwd rootcomando para modificar a senha de root
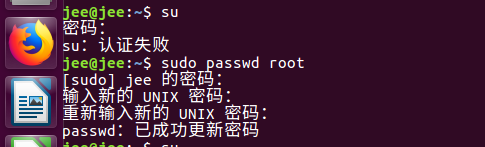
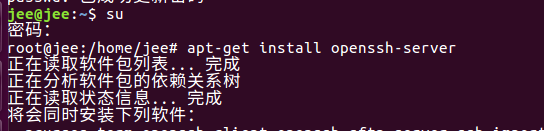
para instalar ssh: apt-get install openssh-servera imagem sué comutada para o usuário root, se você quiser mudar para usuários comuns su - 用户名
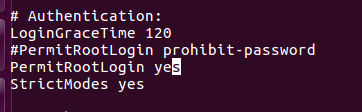
abertas privilégios ssh raiz: para deixar de ir ao usuário root por isso precisamos de mudar para o usuário root é o último passo do sucomando e no arquivo ssh_config / etc / ssh para edição

e, em seguida, na proibição originais modificar este permissões de arquivo para sim (o comentário original para fora esta linha para inserir um novo line)
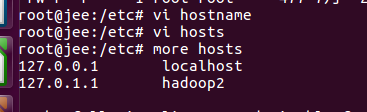
modificar o nome do host e o arquivo hosts: digite / etc editar los hostname arquivos e arquivo hosts o nome do host está definido para hadoop2
instalar o JDK e software Hadoop:
nesta pasta de arquivo / home / username (isto é, pasta do usuário) criar uma pasta para armazenar software JDK nosso software e Hadoop mkdir software
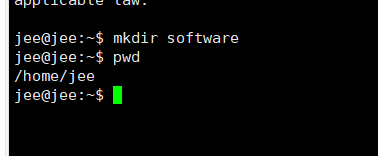
usar ferramentas para Xftp jdk e software hHadoop carregado para esta máquina virtual 
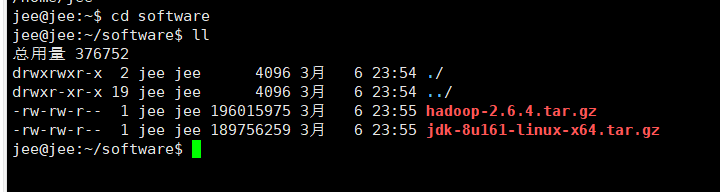
pode ver que temos passou com êxito o jdk e software Hadoop para criar nossa própria pasta de arquivo
-
depois de passar o arquivo dois compactado de extração o próximo passo é que eles vão descompactá-los para o /usr/localdiretório tar -zxvf jdk-8u161-linux-x64.tar.gz -C /usr/local tar -zxvf hadoop-2.6.4.tar.gz -C /usr/local


Em / usr / local para ver se descompactados com êxito a este diretório

, tem sido um sucesso, mas jdk descompactado e nomes Hadoop são muito longos por trás deles será usado para que uma simples mudança de comando é renomeado mv jdk1.8.0_161/ java mv hadoop-2.6.4/ hadoopeles foram alterados para java e Hadoop, fácil de usar

Então precisamos modificar seus usuários e grupos chown -R jee:jee hadoop chown -R jee:jee javaNota jee aqui: jee é meu nome de usuário: nome do grupo
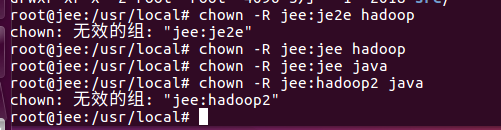
para que o nosso Hadoop e jdk ser instalado o também armazenado no local que especificar o próximo passo que precisamos para configure jdk e hadoop ambiente variável prestar atenção às variáveis ambientais, mas que não deve ser associado a uma configuração de usuário no usuário root necessidades para mudar para nossos usuários atuais su - jee
para configurar o nosso jdk precisamos editar o arquivo ~/.bashrcé adicionado no início deste documento
export JAVA_HOME=/usr/local/java
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib
export PATH=$PATH:$JAVA_HOME/bin
Para hadoop configure também precisamos editar o arquivo ~/.bashrcpara juntar-se neste arquivo
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
export PATH=$PATH:$HADOOP_HOME/bin


Após a conclusão do ambiente de configuração variáveis precisa usar o source ~/.bashrccomando para fazer o arquivo de configuração para ter efeito e depois vamos ver nossa versão jdk Hadoop e ver se já está disponível

pelo gráfico podemos aprender em nosso jdk e hadoop ambiente foi configurado, portanto, o nosso a primeira configuração da máquina foi concluída , então podemos clonar esta máquina virtual!

As três máquinas virtuais foram iniciados até ver o seu endereço IP ifconfige, em seguida, usar Xshell (usado aqui é SecureCRT) ferramenta para conectar este três máquinas virtuais
alguma configuração Em seguida, precisamos modificar as máquinas do cluster:
* Configuração de três IP estático máquinas virtuais precisa configurar um IP estático
* hostname e arquivo de hosts modificações porque três máquinas virtuais exigem nome de máquina diferente

pode ser visto aqui, embora três máquinas virtuais diferentes, mas eles são o mesmo nome da máquina é o nosso primeiro hadoop2 uma máquina virtual criada (porque os dois estão de volta a partir do primeiro clone de modo que o nome da máquina é o mesmo)
* de login sem senha de configuração do ssh do (importante) por que é importante diria o seguinte
nos em primeiro lugar modificar cada máquina o nome da máquina para nos ajudar a distinguir estes três máquinas virtuais cada um são hadoop2 outro modo evitar práticas confusão e acima mudanças hostname e abordagem consistente anfitrião vi hostname vi hosts


para que o nosso nome nos três máquinas são bem configurado chamado hadoop2 hadoop3 hadoop4 (hadoop1 no meu teste foi nomeado para o teste quando a máquina)

Em seguida, precisamos modificar o IP estático para cada máquina virtual (que eu agora usar o endereço IP do modo de três ponte não é muito bom no futuro ele será substituído pelo modo NAT Aqui está operando em modo bridge, se tiver tempo eu vou mudar modo de NAT novamente modificada)
Primeiro Network Services Fechar service network-manager stop
Então precisamos ir para o /etc/networkdiretório, modificar o interior das interfaces de arquivo vi interfaces

, precisamos adicionar alguns de nossos próprios parâmetros de configuração neste final do arquivo
auto ens33
iface ens33 inet static //static表示静态的 全局访问
address 192.168.124.21 //这里的address表示我们给这台主机设置的静态IP 三台分别设置21 22 23.
netmask 255.255.255.0 //子网掩码 默认都是255.255.255.0
gateway 192.168.124.1 //网关
dns-nameservers 192.168.124.1 //DNS名称服务器 和网关一致即可
Estes parâmetros estamos aqui não só com o talento que precisa ver o endereço IP da máquina está configurado corretamente, é preciso configurar um endereço IP estático e nosso gateway IP local também deve ser consistente em uma rede de comunicação ( Modo NAT ponte práticas inconsistentes )


para reiniciar os nossos serviços de rede /etc/init.d/networking restart, em seguida, podemos olhar para o endereço IP dessa máquina virtual não está configurado como nós, como se re-testar se a rede foi ligada ao uso ping www.baidu.com

que você pode ver que nós configurou com êxito estático IP e rede além de dois dias sem máquina virtual problema é a mesma abordagem, mas apenas o mesmo IP estático
O próximo passo, temos de configurar o ssh sem senha de login
为什么我们要配置这个ssh无密码登录呢
ssh无密码登录 说直白点就是ssh协议连接机器时不需要密码
NameNode-->管理DataNode NameNode存了元数据 需要去访问DataNode
ResourceManager-->YARN的大管家 需要去访问NodeManager
他们之间的访问 是通过ssh协议完成的 在正常的运行中 ssh协议是需要密码的 我们现在配置的是完全集群模式 我们不可能还去手动输入密码
所以我们设置ssh无密码登录 不配置的话 集群是有问题的
我们应该怎么样来配置ssh无密码登录呢
我们是将NameNode存放在hadoop2中 SecondaryNode存放在hadoop4中 将ResourceManager存放在hadoop3中
NameNode和SecondaryNode不要部署在一台服务器上 因为在实际的部署环境中 需要Secondary去做NameNode的HA(高可用)
ResourceManager需要的内存比较大 所以它也需要单独部署在一台服务器上
hadoop2中有 : NameNode + +DataNode + NodeManager
hadoop3中有 : DataNode + ResourceManager + NodeManager
hadoop4中有 : DataNode + NodeManager + SecondaryNode
NameNode需要去访问DataNode 所以存放NameNode的虚拟机访问存放了DataNode的虚拟机是不需要密码的
所以hadoop2 ssh-->hadoop2、 hadoop3、hadoop4 需要配置无密码登录
ResourceManager 需要访问 NodeManager 所以存放ResourceManager的虚拟机访问存放了NodeManager的虚拟机不需要密码
所以hadoop3 ssh--> hadoop3、hadoop2、hadoop4 需要配置无密码登录
* Etapa
(1) 生成ssh访问的密钥
(2) 拷贝密钥到其他机器上面,就实现了无密码登录(如果其他机器中有本机的ssh密钥 那么本机访问其他机器 就可以不用密码登录了)
要想生成本机的密钥 我们需要进入本机的 /home/用户名/.ssh 这个目录下, 新的虚拟机没有.ssh这个目录 这是因为我们没有使用ssh连过本机 如果没有的话 我们需要 ssh localhost 使用ssh连接一下本机
这样就会生成一个.ssh目录了 我们再进入这个目录下 使用ssh-keygen -t rsa命令 生成密钥
Nota: A chave para o usuário associado com a necessidade de mudança para o usuário comum ao invés de usar o usuário root para gerar diferente chave de usuário ssh não é o mesmo que precisamos mudar para nossos usuários regulares
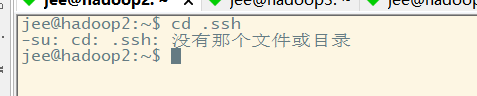
pode ver que nós não, então temos de diretório .ssh ssh localhostdeixá-lo visitar na máquina gera um diretório .ssh

seguinte, entrar em nossas chaves SSH obtidos em .ssh diretório ssh-keygen -t rsa

pode ver os dois arquivos gerou uma chave privada uma chave pública que copiar a chave pública para outras máquinas pode ssh-copy-id 目标机器的IP地址como ssh-copy-id 192.168.124.22

você vê o seguinte e, em seguida, fomos 192.168.124.22 se a máquina já é público
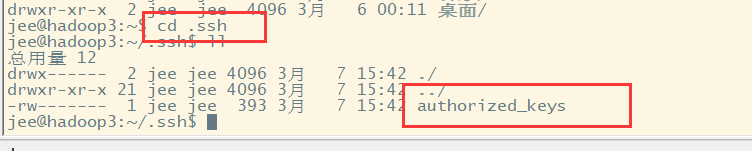
em nome da nossa cópia do arquivo authorized_keys chave pública existe quando as outras necessidades da chave pública do sucesso da máquina é a mesma abordagem ssh conexões são configurados sem senhas .
不要忘记给本机也要复制一个公钥 本机通过ssh访问本机 也是需要ssh公钥的!!!
Nós nenhuma conexão ssh depois que ele terminou precisamos mudar a senha antes de modificar o arquivo hosts, não só porque o nome completo mudou , também precisa mudar seu endereço IP e IP as outras duas máquinas virtuais em conjunto para permitir-lhe para encontrar os outros dois endereço IP da estação (três têm de fazer)


e reinicie nossos três máquinas virtuais podem ser encontrados em nosso uso pinge sshcomando de três máquinas conectadas a este hostname pode ser com sucesso esta mostra o nome do arquivo e nosso arquivo hosts hostname arquivo de configuração e IP a entrada em vigor


pode ser visto usando a conexão ssh que não precisa digitar a senha
我们做上述的这些操作 就是为了可以使用 ssh hostname--->直接登录集群的机器
arquivo de configuração do Hadoop:

Em seguida, precisamos configurar um cluster:
* (1) Configuração está agora completa em uma máquina
* (2) todas as configurações na máquina distribuída para outras máquinas
De acordo com os requisitos desta figura, podemos obtê-los para modificar a configuração desses arquivos
modificados core-site.xml entrar no /usr/local/hadoop/etc/hadoopdiretório em que a modificação core-site.xml

da core-site.xmladicionar a seguinte informação
<configuration>
<!--配置Hadoop中NameNode存放元数据信息的目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/data</value>
</property>
<!--配置Hadoop NameNode节点 value中写的是存放NameNode节点的机器名 hadoop2-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop2:9000</value>
</property>
</configuration>

Configuração hadoop-env.sh, como será mostrado abaixo JAVA_HOME modificado

configuração hdfs-site.xmlé inserida neste documentovi hdfs-site.xml
<configuration>
<property>
<!--设置副本的个数 因为我们使用了三台虚拟机 所以设为3-->
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<!--设置SecondaryNode的位置 因为我们将SecondaryNode存放在第三台虚拟机中 所以value中写的是第三台主机的hostname hadoop4-->
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop4:50090</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/data/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/data/dfs/data</value>
</property>
</configuration>

Modificar o slavesnome do arquivo de nossos três máquinas virtuais adicionado à lista ( o que significa que o nosso DataNode que é executado em vários nós ) vi slaves
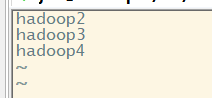
para o yarn-env.sh-> Configuração Modificar JAVA_HOME

modificações yarn-site.xml vi yarn-site.xmlinserir o seguinte conteúdo
<!--reducer获取数据的方式-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--指定yarn的ResourceManager的地址 我们将ResourceManager存放在第二台虚拟机 所以value为第二台虚拟机的hostname hadoop3-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop3</value>
</property>

Configuração mapred-env.sh-> Modificar JAVA_HOME configurado

para mapred-site.xml.templatemodificar mapred-site.xml mv mapred-site.xml.template mapred-site.xml, e então o seguinte são inseridos mapred-site.xml
<configuration>
<!--指定mr运行在yarn上-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
Até agora, temos concluído a configuração acima desta máquina, em seguida, só precisamos distribuir até mais duas máquinas configuradas nestas máquinas, que utilizam este comando
rsync -rvl /usr/local/hadoop/etc/hadoop/* jee@hadoop3:/usr/local/hadoop/etc/hadoop
其中/usr/local/hadoop/etc/hadoop/* 表示这个目录中的所有文件
jee@hadoop3 中 jee是指当前的用户名hadoop3是值虚拟机的名字

Este sucesso é todas as configurações neste catálogo distribuído para as outras duas máquinas virtuais pode ir para as outras duas máquinas virtuais para ver se o arquivo está associado com uma boa distribuição
Neste ponto, todos nós temos sido configurado aglomerado feito! ! !
O próximo passo é executá-lo para ver se há problemas neste cluster
我们创建了三台虚拟机 hadoop2、hadoop3、hadoop4
hadoop2中有NameNode+DataNode+NodeManager
hadoop3中有DataNode+ResourceManager+NodeManager
hadoop4中有SecondaryNode+DataNode+NodeManager
我们配置了HDFS和YARN 所以 要启动这个集群 我们只需要启动HDFS和YARN即可
启动HDFS : 在NameNode这个节点执行启动命令即可(在启动之前需要格式化我们的NameNode!!!)
启动YARN : 在ResourceManager这个节点执行启动命令即可
Vamos teste: primeiro iniciar a formatação nosso NameNode no /usr/local/hadoop/bindiretório seguinte ./hdfs namenode -format


após a formatação NameNode completar podemos iniciar o HDFS Inception HDFS, em seguida, iniciar Fios. HDFS começar na /usr/local/hadoop/sbinpróxima diretório ./start-dfs.sh

e, em seguida, iniciar o serviço em nosso nó FIO ResourceManager /usr/local/hadoop/sbinpara o próximo diretório./start-yarn.sh

Assim que nosso cluster irá iniciar podemos usar em cada máquina virtual no jpsfim de visualizar o processo nesta máquina virtual
如果正常启动 那么
第一台机器上的进程:NameNode+DataNode+NodeManager
第二台机器上的进程:ResourceManager+DataNode+NodeManage
第三台机器上的进程:SecondaryNode+DataNode+NodeManage
Primeiro máquina:
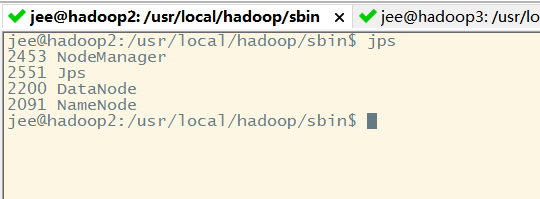
segunda máquina:
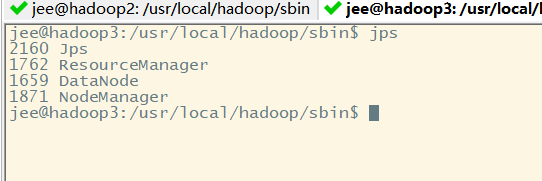
uma terceira máquina:
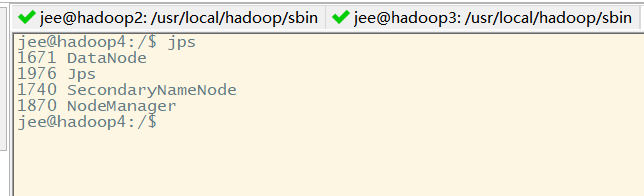
Deste ponto de vista, temos três máquinas de processar o processo não é errado
查看web页面:http://nameNode机器的IP:50070/

如果我们想停集群
先停Yarn,再停Hdfs.
停Yarn:sbin/stop-yarn.sh
停Hdfs:sbin/stop-dfs.sh
Estes são todos os passos para construir um modo completo cluster do Hadoop!
! ! ! ! Note-se que o caminho acima para construir clusters de fato, há um bug é realmente acaba de lançar um DataNode

原因分析:
配置hosts中localhost为本机Ip。datanode连接到namenode上识别到localhost,又回头重连自己。
解决办法:
删除hosts配置的localhost(集群中的每台机器都需要做)

Então nós poderíamos olhar para um número Nó página Web

Se a máquina virtual para acessar o nome de domínio no hadoop2 / hadoop3 / hadoop4 nativa, jornal não é reconhecido:
解决办法:
C:\Windows\System32\drivers\etc 下的hosts文件
添加下面信息:
192.168.1.17 hadoop102
192.168.1.18 hadoop103
192.168.1.19 hadoop104
