distribuído
Toda a aplicação pode ser formada pela colaboração de processos (programas) distribuídos em diferentes hosts.
Navegador/servidor web: programa thin client.
Características de big data 4V
1. Volume: grande em tamanho
2. Velocidade: rápido
3. Variedade: muitos estilos
4. Valor: densidade de baixo valor
Hadoop
Software de código aberto para computação distribuída confiável, escalável.
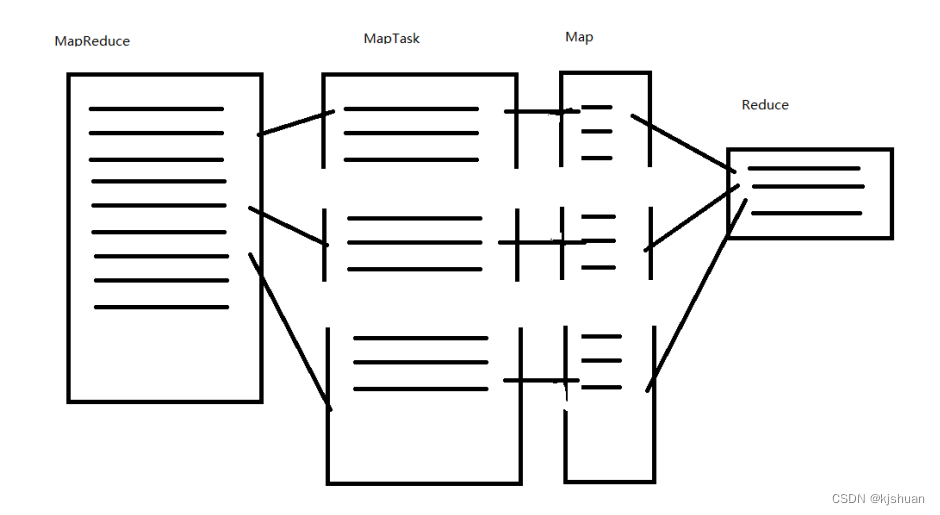
É um framework que permite o processamento de grandes conjuntos de dados em clusters de computadores, utilizando um modelo de programação simples (MapReduce).
Escalável de um único servidor para milhares de hosts, cada nó fornece funções de computação e armazenamento. em vez de depender de máquinas altamente disponíveis
Depende da implementação no nível do aplicativo,
Módulo Hadoop
1.hadoop biblioteca de classes públicas comuns
2. Sistema de arquivos distribuídos hadoop HDFS
3. Estrutura de agendamento de trabalho e gerenciamento de recursos do Hadoop Yarn
4.Hadoop MapReduce tecnologia de processamento paralelo de grande conjunto de dados baseada no sistema de fios
Como funciona o MapReduce
Instalação do Hadoop
- Jdk (recomendado usar JDK 1.8.11)
Pré-requisitos: Preparar o ambiente Linux
base de dados grande
1 sistema de arquivos
linux Exts XFS windons HTFS hbase instale o HDFS primeiro
2.Ícone
hbase baleia assassina colmeia elefante cabeça abelha cauda hadoop elefante
3 ecossistema de big data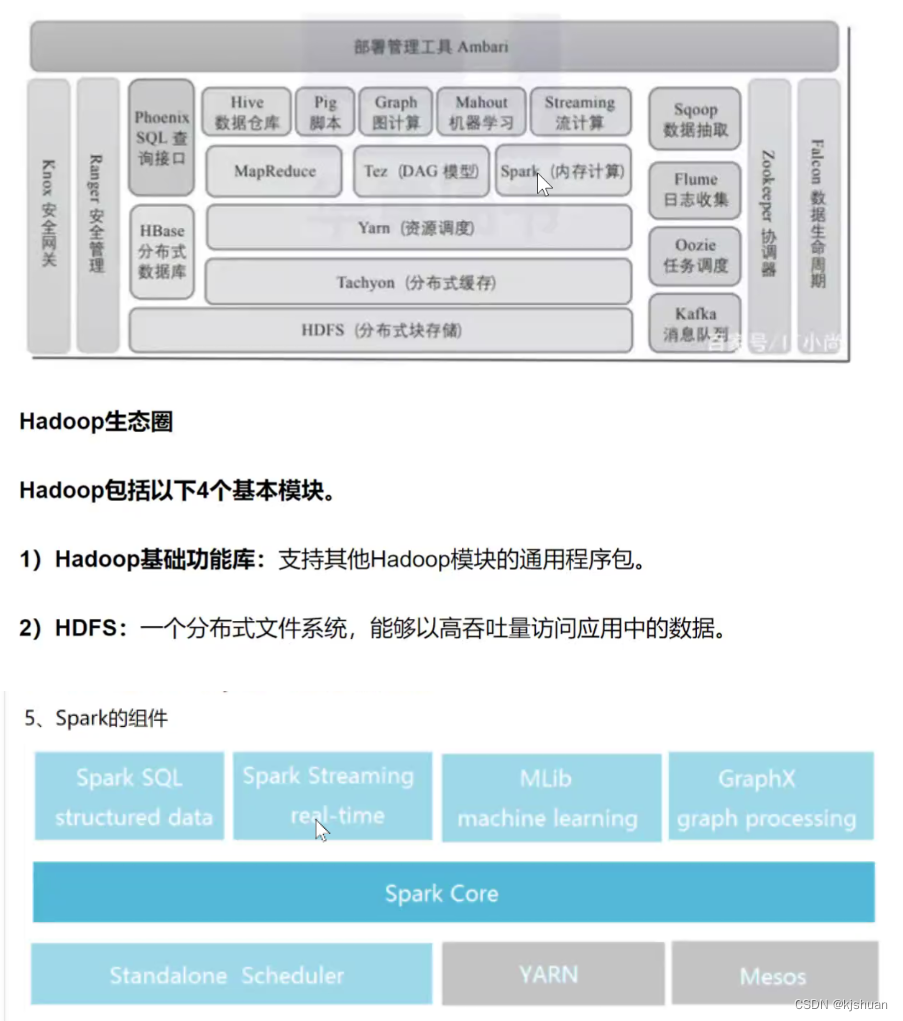
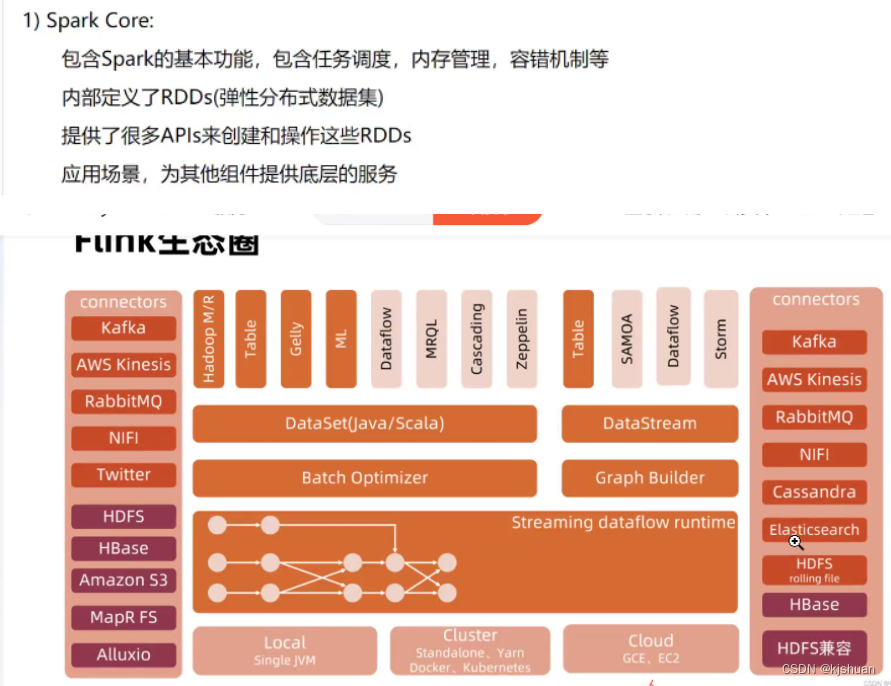
Linguagem do mecanismo de pesquisa Elasticsearch (Java/Scala )
Versões do Hadoop 3 1 Versão da comunidade Apache Hadoop (recursos gratuitos não são bons) 2 Versão de distribuição CDH (usada atualmente) 3 Versão de distribuição HDP (recursos pagos são fantásticos)
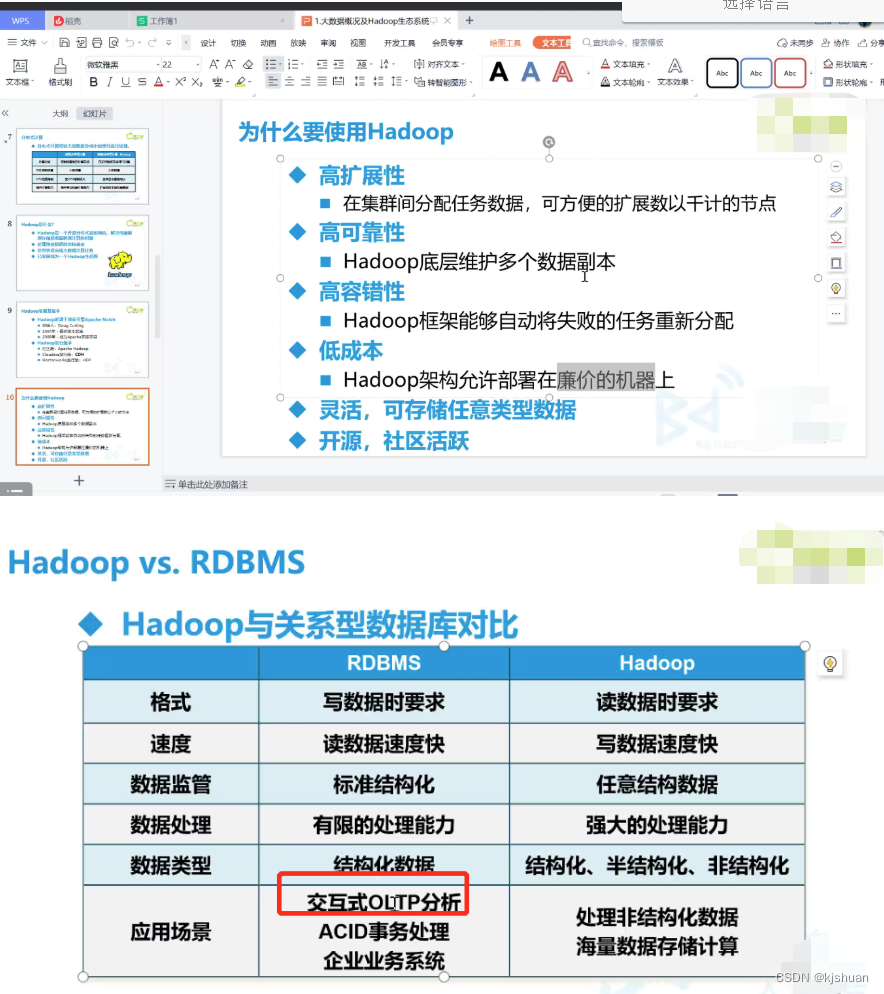
Banco de dados OLAP Big data OLTA
HDFS MapReduce YARN
Construção de ambiente operacional Hadoop independente
1Copiar base para hadoop01
hostnamectl set-nome do host hadoop01vim /etc/systemconfig/network-scripts/ifcfg-ens33
vim /etc/hosts
拖入hadoop相关jar包到 /opt
cd /opt
tar -zxf hadoop-2.6.0-cdh5.14.2.tar.gz
mv hadoop soft/hadoop260
cd soft/hadoop260
cd etc/hadoop
pwd
vim hadoop-env.sh
1= ===========================
exportar JAVA_HOME=/opt/soft/jdk180
:wq
1========== ===================
vim
core-site.xml
2======================== =====
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.64.210:9000</value>
</property>
<property>
<name>hadoop.tmp .dir</name>
<value>/opt/soft/hadoop260/tmp</value>
</property>
</configuration>
:wq
2===========================
vim
hdfs-site.xml
3======= =====================
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
< /configuração>
:wq
3============================
cp
mapred-site.xml.template mapred-site.xml
vim mapred -site.xml
4============================
<configuração
> <propriedade>
<nome>mapreduce.framework.nome</name>
<value>fio</value>
</property>
</configuration>
:wq
4===========================
vim fio-site.xml
5============== ==============
<configuration>
<property>
<name>yarn.resourcemanager.localhost</name>
<value>localhost</value>
</property>
<property>
<name> yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
:wq
5===========================
#Configurar
variáveis de ambiente hadoop. Por favor, use seu próprio hadoop260
vim /etc/profile
6== = ========================
# Hadoop ENV
export HADOOP_HOME=/opt/soft/hadoop260
export HADOOP_MAPRED_HOME=$HADOOP_HOME
exportar HADOOP_COMMON_HOME=$HADOOP_HOME
exportar HADOOP_HDFS_HOME=$HADOOP_HOME
exportar YARN_HOME=$HADOOP_HOME
exportar HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
exportar PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
exportar HADOOP_INSTALL=$HADOOP_HOME
:
wq
6======= =====================
#Ative a
fonte de configuração acima /etc/profile
#Faça login sem senha
ssh-keygen -t rsa -P ''
cd /root/ .ssh/
ls
ssh-copy-id -i ~/.ssh/id_rsa.pub [email protected]
sim
ok
ls
ll
ssh 192.168.64.210
exit
#Faça login remotamente no hadoop210 como seu próprio nome de host/ect/hosts ou systemctl sethostname hadoop210#
ssh hadoop210
sim
sair
#Faça login diretamente sem senha
ssh hadoop210
sair
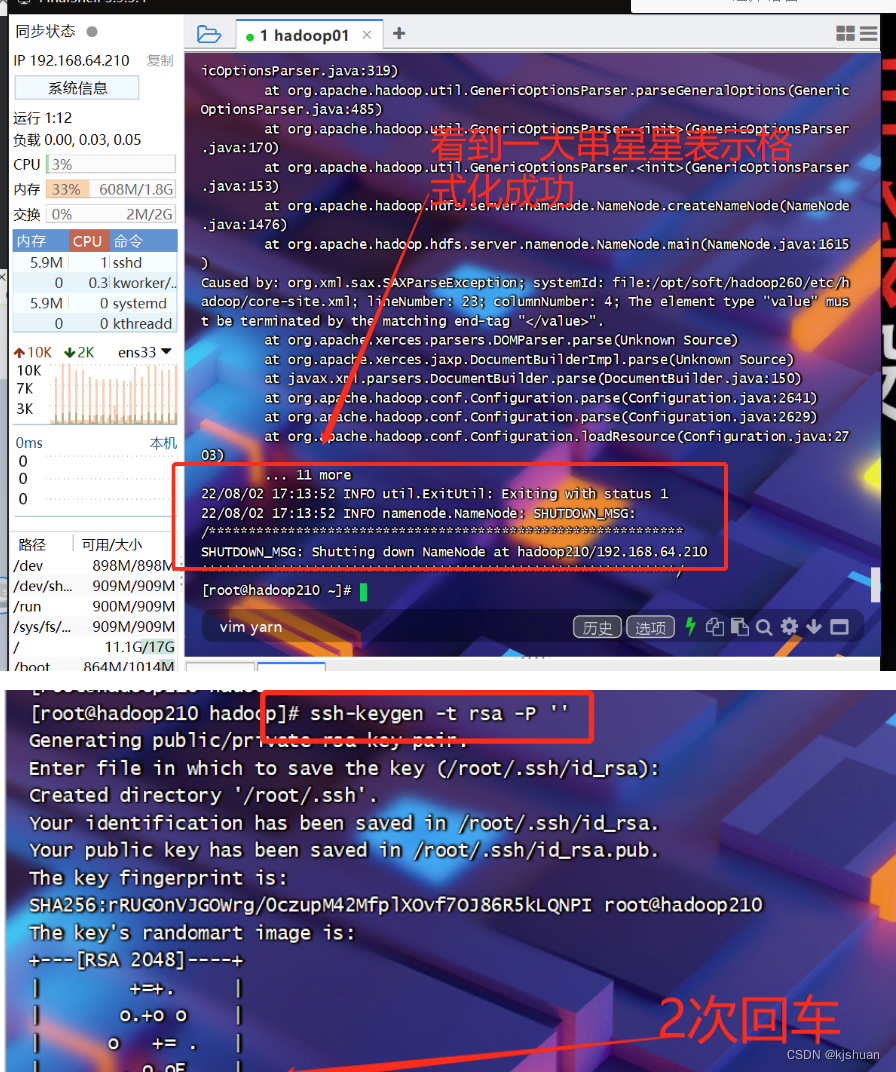
#Format NameNode
hdfs namenode
-format
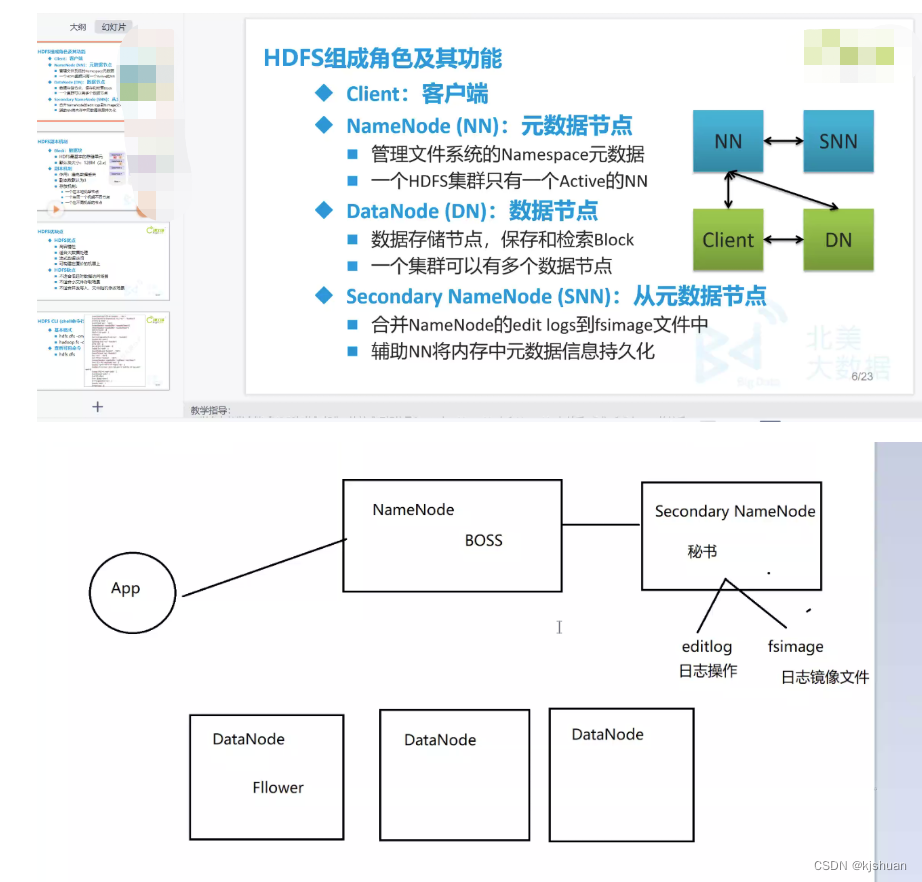
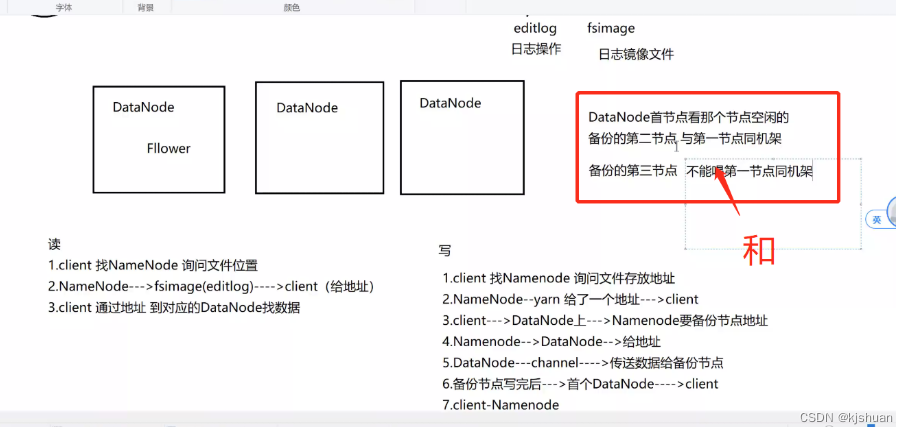
ler
1 cliente procura o NameNode e pede a localização do arquivo 2 NameNode--->fsimage(editlog)--->client (forneça o endereço) 3 cliente usa o endereço para encontrar os dados no DataNode correspondente
Escrever
1 cliente procura NameNode e pede o endereço de armazenamento do arquivo 2 NameNode--yarn fornece um endereço--->cliente 3 cliente--->DataNode--->NameNode deseja fazer backup do endereço do nó 4 NameNode---> DataNode -> fornece o endereço 5 DataNode -- canal -> Transmitir dados para o nó de backup 6 Após o nó de backup concluir a gravação ---> Primeiro DataNode ---> cliente 7 client-NameNode
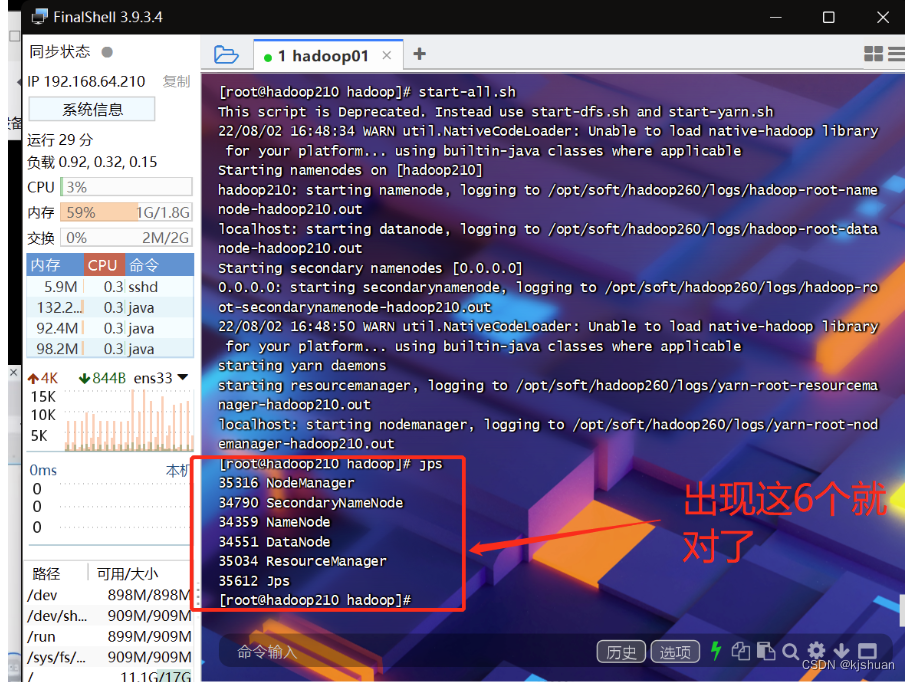
2Inicie o hadoop01
start-all.sh sim sim jps #Navegador para visualizar a construção do cluster de máquina única hadoop concluída 192.168.64.210:50070
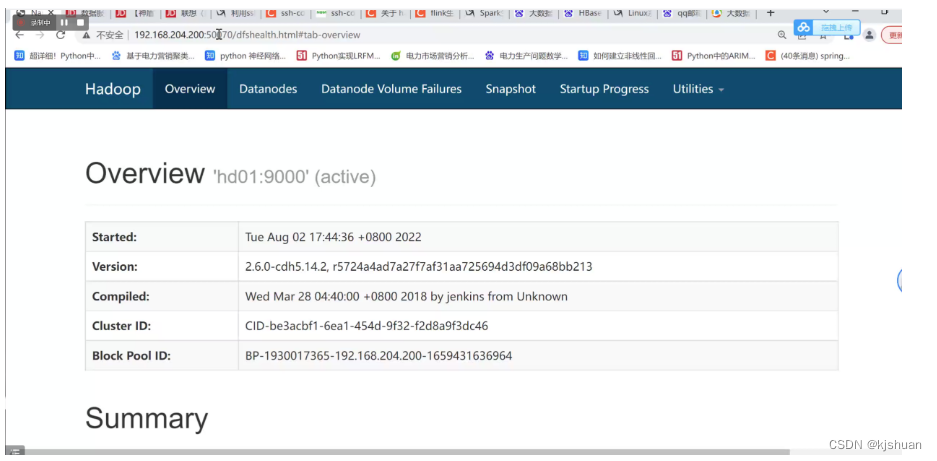
3. Desligue o sistema
pare tudo.sh