Resumo: Visando os problemas a serem resolvidos pela recuperação vetorial, este artigo classifica as tecnologias relacionadas à recuperação vetorial dominante e analisa uma tendência atual da recuperação vetorial.
O que é recuperação vetorial
Em primeiro lugar, entendemos o que é um vetor.O chamado vetor é uma matriz composta por n números (um vetor binário consiste em n bits), que chamamos de vetor n-dimensional. A recuperação vetorial é para recuperar K vetores (K-vizinho mais próximo, KNN) que são semelhantes ao vetor de consulta em um determinado conjunto de dados vetoriais de acordo com uma determinada medida. No entanto, devido à grande quantidade de cálculos KNN, geralmente nos concentramos apenas em aproximações Problema do vizinho mais próximo (vizinho mais próximo aproximado, ANN).
Métrica vetorial
Existem quatro métricas de vetor comuns: distância euclidiana, cosseno, produto interno, distância de Hamming
Métodos de medição diferentes correspondem a cenas diferentes. Normalmente, a distância euclidiana é usada para recuperação de imagem, o cosseno é usado para reconhecimento de rosto, o produto interno é usado principalmente para recomendação e a distância de Hamming é geralmente usada para cenas de recuperação de vídeo em grande escala devido ao pequeno vetor.
Com a métrica, geralmente usamos a taxa de rechamada (geralmente chamada de precisão) para avaliar o efeito da recuperação vetorial. Para um determinado vetor q, seus K vizinhos mais próximos no conjunto de dados são N, recuperando os K conjuntos de vizinhos mais próximos recuperados É M então

Quanto mais próximo o recall estiver de 100%, melhor será o efeito de indexação.
Problemas resolvidos por recuperação vetorial
Em essência, a recuperação vetorial não tem diferença entre sua estrutura de pensamento e os métodos tradicionais de recuperação. Mais tarde, quando explicarmos a estrutura do índice da recuperação vetorial, teremos uma experiência mais profunda.
1. Reduza o conjunto de vetores candidatos
Semelhante à recuperação de texto tradicional, a recuperação de vetor também requer uma certa estrutura de índice para evitar a correspondência na quantidade total de dados. A recuperação de texto tradicional usa indexação invertida para filtrar documentos irrelevantes, enquanto a recuperação de vetor usa uma estrutura de índice para vetores. Contornando vetores irrelevantes, este artigo enfoca a estrutura de índice vetorial relevante.
2. Reduza a complexidade do cálculo de vetor único
A recuperação de texto tradicional geralmente usa o modelo de funil ao classificar. O cálculo de nível superior é relativamente leve, e quanto mais baixo o cálculo, mais refinado, mas conforme a filtragem avança, o número de documentos que precisam ser calculados também diminui gradualmente. Para vetores de alta dimensão, um único A quantidade de cálculo vetorial ainda é relativamente pesada, geralmente o vetor é quantizado, o vetor é aproximado e, finalmente, o vetor original é classificado em um pequeno conjunto de dados.
Vamos nos concentrar nessas duas questões para discutir a recuperação vetorial.
Estrutura do índice de pesquisa vetorial
Estabelecer uma estrutura de índice eficiente para vetores é o problema número um enfrentado pela recuperação de vetores. Antes de começar, vamos dar uma olhada em um projeto Benchmark . Este projeto compara os indicadores de desempenho de recall de estruturas de índice relacionadas em vários conjuntos de dados vetoriais públicos, para que possamos rapidamente Tenha uma compreensão intuitiva do desempenho de várias estruturas de índice.
Cálculo de força bruta
O cálculo da força bruta é a forma mais simples, mas mais complexa. Ao calcular a recuperação, o resultado do cálculo da força bruta são os dados de referência como a resposta. Em cenários de reconhecimento de rosto, geralmente é necessária uma taxa de recuperação de 100%. Neste caso Cálculo de força bruta geralmente direto.
Abordagem baseada em árvore
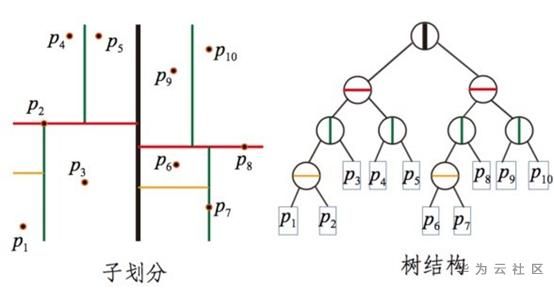
Existem muitos métodos baseados em árvore, os mais típicos são KDTree, BallTree e VPTree, que são análogos às árvores binárias tradicionais. A estrutura da árvore nada mais é do que a decisão de expandir para a esquerda ou para a direita ao construir a árvore. Diferentes índices de árvore vetorial são baseados no padrão a seguir. Na tomada de decisão, KDTree (conforme mostrado na figura abaixo) irá selecionar uma dimensão com a maior variância no vetor e tomar o valor mediano como critério, ou seja, dividir o espaço com um hiperplano, enquanto BallTree divide o espaço com uma superfície esférica, e VPTree primeiro seleciona um ponto alto , E então calcule a distância entre cada ponto e o ponto de vista, e use a distância mediana como critério. Normalmente, esses métodos usam desigualdades triangulares para eliminar a exploração desnecessária durante a pesquisa.
Existem muitos outros tipos de métodos baseados em árvore, mas são sempre os mesmos. Eles nada mais são do que dividir o espaço vetorial de acordo com um determinado critério. No entanto, não importa como a divisão seja feita, o desempenho do método baseado em árvore é determinado pela necessidade de retrocesso. É um pouco inferior.
Método Hash
O hash é familiar para todos. Os vetores também podem ser hash para acelerar a pesquisa. O hash de que estamos falando aqui se refere ao hash sensível à localidade (LSH), que é diferente do hash tradicional sem colisão. Hashes sensíveis dependem de colisões para encontrar vizinhos.
A função hash que atende às duas condições a seguir é chamada de (d1, d2, p1, p2) -sensível:
1. Se d (x, y) <= d1, então a probabilidade de h (x) = h (y) é pelo menos p1;
2. Se d (x, y)> = d2, então a probabilidade de h (x) = h (y) é pelo menos p2;
A expressão acima é em termos humanos: se dois pontos no espaço de alta dimensão estão muito próximos, então projete uma função hash para calcular o valor hash dos dois pontos, de modo que seus valores hash tenham uma grande probabilidade de serem os mesmos Sim, se a distância entre dois pontos for grande, a probabilidade de que seus valores de hash sejam iguais será muito pequena. Diferentes medidas de distância têm diferentes funções de hash, e nem todas as medidas de distância (como produto interno) podem encontrar o hash localmente sensível correspondente
Baseado no método invertido
O índice invertido tradicional é baseado no documento que contém uma determinada palavra e, em seguida, coloca o documento atual na palavra alterada índice invertido para construir a estrutura do índice.Como o vetor constrói o índice invertido? Por meio do agrupamento, todo o espaço vetorial é dividido em K regiões, e cada região é substituída por um ponto central C. Desta forma, cada vetor é comparado com todos os pontos centrais e é classificado na linha invertida correspondente ao ponto central mais próximo de si mesmo. A estrutura do índice é estabelecida
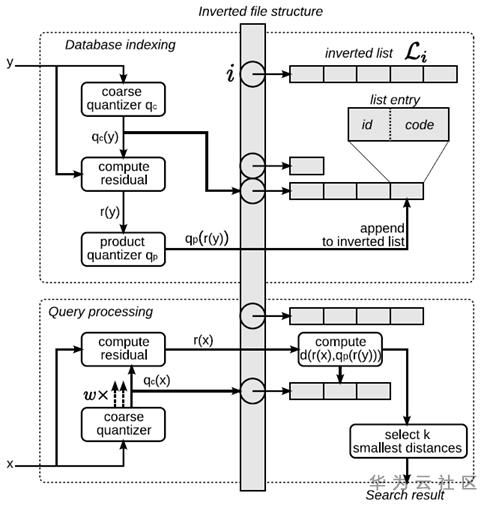
Outro índice baseado na linha invertida é o BOW. O princípio é praticamente o mesmo. Por exemplo, uma imagem extrairá centenas de características locais e todas as características são agrupadas primeiro para formar os pontos centrais. Esses pontos centrais são usados como base para as linhas invertidas estabelecerem Ao indexar, classifique cada característica local da imagem em seu ponto central mais próximo, estabeleça uma linha invertida e filtre os resultados de acordo com o número de ocorrências durante a recuperação.
Abordagem baseada em gráficos
A estrutura de índice apresentada acima pode ser classificada como um método baseado na divisão do espaço. Cada vetor pertencerá apenas a uma determinada área dividida. O maior problema desses métodos é que, para melhorar a recordação, uma grande área do vetor precisa ser examinada, resultando em A quantidade de cálculos está aumentando. Existe uma maneira melhor de resolver esse problema? O método baseado em gráfico pode atingir melhor esse objetivo. A ideia mais simples do método gráfico é que os vizinhos dos vizinhos também podem ser vizinhos. Dessa forma, a pesquisa do vizinho mais próximo é transformada na travessia do gráfico. Devido à sua conectividade, pode ser direcionada Parte do vetor é inspecionado em vez de por região, então o escopo do vetor pode ser bastante reduzido.
Nos últimos anos, o método de gráfico tem sido um tópico importante na pesquisa de recuperação de vetor. Um lote de métodos de índice de gráfico, como KGraph, NSG, HNSW, NGT, etc., apareceu, mas, na verdade, a principal diferença entre esses métodos de gráfico está no processo de construção, e diferentes métodos de gráfico usam métodos diferentes. Para melhorar a qualidade do gráfico, mas as etapas de recuperação do gráfico são basicamente as mesmas: a. Selecione o ponto de entrada; b. Percorra o gráfico; c. Convergir. Na prática contínua, observamos algumas características para julgar a qualidade do índice de gráfico e nos orientar na direção da melhoria do método de gráfico:
1. O ponto vizinho está perto de K vizinho mais próximo
2. O número de pontos vizinhos é o menor possível, ou seja, reduz o grau de saída
3. Garanta a conectividade do gráfico tanto quanto possível e aumente o grau
Vamos tomar o HNSW como exemplo para apresentar o princípio do método gráfico. A razão pela qual escolhemos o HNSW é que o método é fácil de entender e é mais fácil construir e atualizar o índice de streaming, que é a personificação perfeita do método tradicional no vetor.
Por trás do HNSW está, na verdade, a aplicação de tabelas de salto no gráfico. Como uma estrutura de índice simples e eficiente, as tabelas de salto são amplamente utilizadas no Redis, LevelDB e outros sistemas, conforme mostrado na figura a seguir:
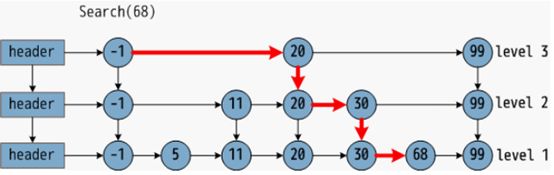
Há uma quantidade total de dados na primeira camada. A camada superior é determinada pela inserção aleatória de moedas. Quanto maior o investimento, menor a probabilidade. Há um registro do nó que é investido na camada superior, que é usada como uma rodovia para recuperação.
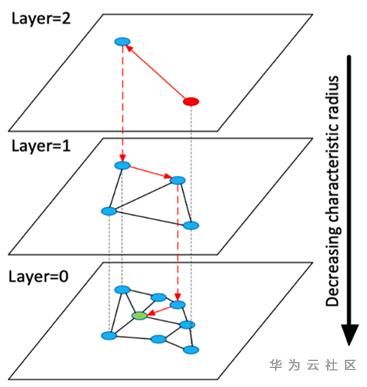
O princípio do HNSW também é semelhante. Ao contrário das tabelas de salto tradicionais que usam listas vinculadas para conectar os nós em cada camada, o HNSW é um NSW (Navigable Small World Graph) em cada camada, organizado pela estrutura de dados do gráfico, e os nós de nível superior também são determinados pela inserção de moeda. Uma camada, e todos são registrados no gráfico da camada inferior. O gráfico da camada superior pode ser considerado um microcosmo do gráfico da camada inferior. Ao pesquisar, de cima para baixo, o processo de recuperação é continuamente orientado para se aproximar gradualmente do espaço vetorial que você deseja explorar. Além disso, no processo de composição, o HNSW garante a conectividade do gráfico através do recorte de arestas. Aliás, em muitos artigos sobre o método de grafos, todos os métodos de recorte de arestas são descritos a partir de suas próprias perspectivas, mas independentemente dos vários métodos de recorte Como a descrição é legal, os métodos são exatamente os mesmos, mas a perspectiva é diferente.
Quantização vetorial
A tecnologia de índice de recuperação vetorial principal é basicamente descrita acima. Depois que o vetor sob investigação é cortado pela estrutura do índice, o valor de cálculo único ainda é muito grande para vetores de dimensões elevadas. Existe uma maneira de reduzir a quantidade de cálculo? ? A quantificação é baseada precisamente nesta tecnologia de propósito. A chamada quantificação se refere à quantificação de um espaço de grande valor para uma faixa de valor menor. Para um exemplo simples, existem mais de 6 bilhões de pessoas no mundo, ou seja, a representação de pessoas na Terra tem 60 Podemos quantificar as pessoas em dois tipos, homens e mulheres, para que possamos quantificar um espaço de mais de 6 bilhões em um intervalo de apenas dois valores.
A quantização comumente usada geralmente inclui PQ (e seu OPQ, LOPQ otimizado) e dois valores.
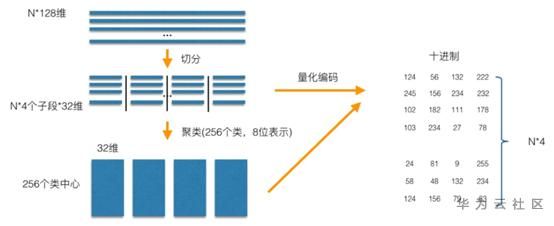
O princípio de PQ é mostrado na figura .O P em PQ significa produto, então como surge um produto? Na figura abaixo, um espaço vetorial de 128 dimensões é processado por PQ. O espaço vetorial é dividido em 4 segmentos e cada segmento é quantificado por 256 pontos centrais. Portanto, o espaço original de 128 dimensões agora pode usar os pontos centrais em cada segmento. Combinação, ou seja, 256 * 256 * 256 * 256 combinações para expressar, este é o chamado produto.
Para vetores binários, como as CPUs modernas fornecem instruções especiais, o cálculo da distância de Hamming é muito rápido. Na recuperação de vetores massivos, os vetores binários são geralmente gerados diretamente. Os métodos comuns para gerar vetores binários incluem ITQ (Quantização Iterativa), Métodos como DeepHash.
Outras tecnologias
Clustering
O agrupamento de vetores refere-se principalmente à série de métodos K-means, como o clássico K-means, K-means ++, K-means #, One pass K-means, YinYang k-means, etc. Na prática, também usamos a estratificação Método para obter pontos centrais massivos.
Conversão de produto interno
Anteriormente no capítulo hash, vimos que não há como encontrar a função hash localmente sensível correspondente para o produto interno, e o produto interno não satisfaz a desigualdade do triângulo, portanto, muitas estruturas de índice não podem usar diretamente o produto interno como uma métrica. O vetor é normalizado e então recuperado, mas a normalização irá transformar a distribuição do espaço vetorial. Pesquisadores descobriram um método por meio de uma observação matemática. Por meio de uma certa transformação de regra, o produto interno e euclidiano podem ser correlacionados negativamente, conforme mostrado na figura a seguir:

Depois de converter o vetor, ele pode ser recuperado diretamente usando o método de medição de distância euclidiana.
A tendência de desenvolvimento da recuperação vetorial
No início deste artigo, mencionamos que a estrutura de pensamento da recuperação vetorial não é diferente da recuperação tradicional.Até agora, os dividendos dos métodos tradicionais aplicados à recuperação vetorial foram basicamente consumidos. Uma tendência de desenvolvimento nos últimos dois anos é a combinação de vários métodos. Ao absorver as vantagens de vários métodos, pode-se obter melhor desempenho e vetores em maior escala.
Mapa de quantização
A partir do benchmark, podemos ver claramente que o método dominante é basicamente dominado pelo método do gráfico. Ao mesmo tempo, sabemos que a quantização pode reduzir a quantidade de cálculo de um único vetor. Portanto, uma ideia natural é deixar os dois trabalharem juntos. O cálculo quantitativo é usado para acelerar o processo de travessia do gráfico. Este método tem vantagens óbvias em métodos de alta dimensão, e a taxa de aceleração pode chegar a mais de três vezes.
Imagem + invertida
Embora o desempenho do mapa seja excelente, as deficiências também são muito óbvias. Para garantir o efeito de recuperação, a economia no mapa consome muito espaço de armazenamento
Especialmente em um vetor binário onde o próprio vetor é muito pequeno, esta é uma carga insuportável.Além disso, os vizinhos do gráfico são aleatórios por natureza, o que também é muito desfavorável para vetores de processamento de hardware. O método invertido é exatamente o oposto. A estrutura do índice basicamente não consome muito espaço, mas a desvantagem é que o método da divisão do espaço é fácil de causar a taxa de recall não é alta, mas temos alguma inspiração da observação da computação violenta. Existem duas perspectivas para a computação violenta da perspectiva da divisão do espaço. : O cálculo da força bruta pode ser considerado como agrupamento de todos os vetores em um; o cálculo da força bruta também pode ser considerado como agrupamento em centros N (N é o tamanho do conjunto de dados vetoriais) e cada ponto central é o próprio vetor. Esses dois métodos podem ser 100% recuperados, mas um deles é porque há muitos vetores sob o ponto central, e o outro é porque há muitos pontos centrais no cluster, o que torna a quantidade de cálculo inaceitável. Podemos encontrar um equilíbrio? É o número apropriado de pontos centrais para alcançar um melhor equilíbrio entre recall e desempenho? O método gráfico + arranjo invertido surgiu, usando pontos centrais massivos para dividir o espaço vetorial, e o método gráfico para organizar os pontos centrais massivos.
Prática de recuperação vetorial de nuvem Huawei
A aplicação de recuperação vetorial tem visto uma prosperidade sem precedentes. O Huawei Cloud Search Service (CSS) agora abriu os recursos de recuperação vetorial para o mundo externo. Oferecemos soluções para cenários de dados massivos e de alto desempenho.
Na implementação, nos baseamos principalmente no método de gráfico e fizemos muitos aprimoramentos na otimização de corte, aprimoramento de conectividade, aceleração de instrução e processamento multi-thread. No teste comparativo, nossa taxa de recall é muito maior do que Faiss, e a lacuna em dados de alta dimensão é ainda mais óbvia. Sob o mesmo recall, nosso desempenho é 2,3 vezes maior que o de Faiss em conjuntos de dados públicos como SIFT e GIST. O teste de comparação usa a mesma máquina e o mesmo algoritmo.
Resumindo:
Tendo em vista os problemas a serem resolvidos pela recuperação vetorial, este artigo classifica as tecnologias relacionadas à recuperação vetorial convencional e analisa uma tendência atual da recuperação vetorial. No processo de desenvolvimento da recuperação vetorial, ainda existem muitos métodos relacionados que não foram incluídos, mas são sempre os mesmos.Estes métodos são a expansão dos métodos tradicionais ou a otimização da aplicação da desigualdade triangular ou a aplicação de métodos hierárquicos. Espero que este artigo possa ajudar a esclarecer o contexto da recuperação vetorial.
referências:
1. JL Bentley. Árvores de pesquisa binárias multidimensionais usadas para pesquisa associativa. Communications of the ACM, 18: 509-517,1975
2. PN Yianilos. Estruturas de dados e algoritmos para pesquisa de vizinho mais próximo em espaços métricos gerais. Em Proc. do 4º Simpósio ACM-SIAM anual de Algoritmos Discretos, páginas 311-321, 1993
3. Liu, T .; Moore, A. & Gray, A. (2006). Novos algoritmos para classificação não paramétrica de alta dimensão eficiente . Journal of Machine Learning Research. 7 : 1135–1158.
4. P. Indyk e R. Motwani. Vizinhos mais próximos aproximados: Para remover a maldição da dimensionalidade. Em STOC, páginas 604-613, Dallas, TX, 1998.
5. W. Dong, C. Moses e K. Li. Construção eficiente de gráfico de k-vizinho mais próximo para medidas de similaridade genéricas. Em Proceedings of the 20th international conference on World Wide Web, páginas 577-586. ACM, 2011.
6. YA Malkov e DA Yashunin. Pesquisa de vizinho mais próximo eficiente e robusta usando gráficos hierárquicos de pequeno mundo navegáveis. CoRR, abs / 1603.09320, 2016.
7. https://arxiv.org/abs/1707.00143
8. https://yongyuan.name/blog/vector-ann-search.html
9. A. Shrivastava e P. Li. Um esquema melhorado para lsh assimétrico. Relatório técnico, arXiv: 1410.5410, 2014.
10. H. Jegou, M. Douze e C. Schmid. Quantização do produto para pesquisa do vizinho mais próximo. Transações IEEE em análise de padrões e inteligência de máquina, 33 (1): 117 {128, 2011.
11.https: //arxiv.org/abs/1810.07355
Observação: alguns exemplos da estrutura do índice neste artigo são de https://yongyuan.name/blog/vector-ann-search.html
Clique para seguir e aprender sobre a nova tecnologia da Huawei Cloud pela primeira vez ~