**hadoop搭建集群**1. Desligue o firewall
1) Verifique o status do
firewall firewall-cmd --state
2) Pare o firewall
systemctl e firewalld.service
3) Desative a inicialização do firewall
systemctl desativar firewalld.service
2.
Entrada da linha de comando de sincronização de tempo : yum install ntp Faça o download do plugin ntp,
Após a conclusão do download, digite a linha de comando: ntpdate -u ntp1.aliyun.com
e, em seguida, digite a linha de comando: date
Se as seguintes condições aparecerem, a configuração será bem-sucedida: 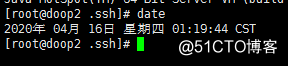
3. Configure o servidor (aqui, como exemplo 4)
1 nó principal: doop1 ( 192.168.0.103), 2 nós filhos (escravos), doop2 (192.168.0.104), doop3 (192.168.0.105), doop4 (192.168.0.106)
2. Configure o nome do nó principal (192.168.0.103)
na linha de comandos e digite: vi / etc / sysconfig / network
adiciona conteúdo:
NETWORKING = yes
HOSTNAME = doop1
configura três nomes de nós filhos (192.168.0.104), (192.168.0.105), (192.168.0.106):
vi / etc / sysconfig / network
adiciona conteúdo:
NETWORKING = sim
HOSTNAME = doop2
vi / etc / sysconfig / network
adiciona conteúdo:
NETWORKING = yes
HOSTNAME = doop3
vi / etc / sysconfig / network
adiciona conteúdo:
NETWORKING = yes
HOSTNAME = doop4
4. Configure hosts para
abrir o arquivo de hosts do nó principal Comente duas linhas (comente as informações do host atual) e adicione todas as informações do host do cluster hadoop no arquivo.
Digite na linha de comando: vi / etc / hosts
adicione as informações do nome do nó de 3 servidores
192.168.0.103 doop1
192.168.0.104 doop2
192.168.0.105 doop3
192.168.0.106 doop4
save, copie os hosts do nó principal para os outros dois
comandos de subnó Digite as seguintes linhas:
scp / etc / hosts [email protected]: / etc /
scp / etc / hosts [email protected]: / etc /
scp / etc / hosts [email protected]: / etc /
e execute ( (Reinicie o servidor sem executar a seguinte instrução): / bin / hostname hostname
5, configure o acesso ssh sem senha para
gerar um par de chaves públicas
Execute em cada nó separadamente:
Entrada da linha de comandos: ssh-keygen -t rsa e
pressione Enter até que a geração seja concluída Após a conclusão da
execução, dois arquivos id_rsa e id_rsa são gerados no diretório /root/.ssh/ em cada nó. pub
A primeira é a chave privada e a segunda é a chave pública
executada no nó principal:
root scp /root/.ssh/id_rsa.pub @ doop2: /root/.ssh/
scp /root/.ssh/id_rsa.pub root @ doop3: /root/.ssh/
scp /root/.ssh/id_rsa.pub root @ doop4: /root/.ssh/ Insira
o seguinte comando em todas as sessões da janela xshell : 
cd /root/.ssh/
cp id_rsa.pub author_keys
Por fim, teste se a configuração foi bem-sucedida.
Execute
ssh doop2 em doop1 e
ssh doop3
pode pular para a interface de operação dos dois nós filhos corretamente. Da mesma forma, é possível efetuar login no nó mestre e outros nós filhos da mesma maneira em cada nó filho sem senha. Isso significa que a configuração foi bem-sucedida.
6. Instale o jdk (todas as quatro máquinas devem estar instaladas)
Instalado no mesmo local /usl/local/jdk1.8.0_191
Faça o download do JDK: https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads- 2133151.html
Descompacte o JDK: tar -zxvf /usr/local/jdk-8u73-linux-x64.gz
Configure variáveis de ambiente, edite o arquivo de perfil:
vi / etc / profile
Adicione o seguinte código no final do arquivo de perfil:
export JAVA_HOME = / usr / local / jdk1 .8.0_191
export PATH = $ JAVA_HOME / bin: $ PATH
export CLASSPATH = $ JAVA_HOME / lib: $ JAVA_HOME / jre / lib para
salvar o arquivo que você acabou de editar: source / etc / profile para
testar se a instalação foi bem-sucedida: versão-java
7. Instale o hadoop O
local da instalação é personalizado, por exemplo, instale-o no diretório / usr / local para
fazer o download do pacote hadoop:
https://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-2.7.7/hadoop- 2.7.7.tar.gz é
colocado no diretório / usr / local, extrai o hadoop
tar -zxvf hadoop-2.7.7.tar.gz
para gerar o diretório hadoop-2.7.7 em usr.
Configure as variáveis de ambiente:
vi / etc / profile
em Adicione no final:
exportar HADOOP_HOME = / usr / local / hadoop-2.7.7
exportar PATH = $ PATH: $ HADOOP_HOME / bin: $ HADOOP_HOME / sbin
Salve o perfil recém-editado para entrar em vigor:
source / etc / profile
8. Configurar a
configuração do hadoop
Arquivo de configuração do hadoop O local do arquivo a ser configurado é / usr / local / hadoop -2.7.7 / etc / hadoop, os seguintes arquivos precisam ser modificados:
hadoop-env.sh
yarn-env.sh
core-site.xml
hdfs-site.xml
mapred-site.xml
yarn-site.xml masters de
escravos No hadoop-env.sh e no yarn-env.sh, adicione a variável de ambiente jdk hadoop-env.sh e adicione o seguinte código: exporte JAVA_HOME = / usr / local / jdk1.8.0_191 para o seguinte local: yarn-env. Adicione o seguinte código em sh : exporte JAVA_HOME = / usr / local / jdk1.8.0_191 para o seguinte local: adicione o seguinte código em core-site.xml : <configuração> <! - Porta de transmissão de dados- > <propriedade>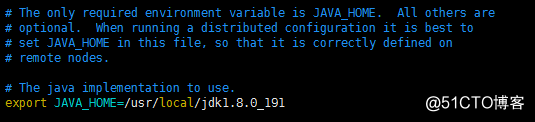
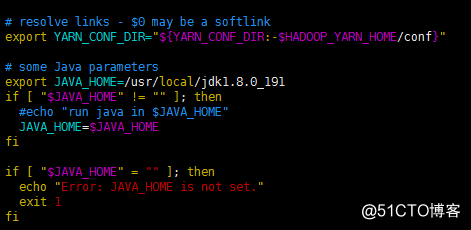
<name> fs.defaultFS </name>
<value> hdfs: // doop1: 9000 </value>
</property>
<property>
<name> io.file.buffer.size </name>
<value> 131072 < / value>
</property>
<! - arquivo hadoop fsimage ->
<property>
<name> hadoop.tmp.dir </name>
<value> arquivo: / usr / temp </value>
</property>
<property>
<name> hadoop.proxyuser.root.hosts </name>
<value> </value>
</property>
<property>
<name> hadoop.proxyuser. root.groups </name>
<value> </value>
</property>
</ configuration>
Nota: A pasta temp sob o caminho após o arquivo no código acima precisa ser criada por ele
mesmo.Adicione
o seguinte código ao hdfs-site.xml :
<configuração>
<! - nó de nome secundário 配置 ->
<propriedade>
<name> dfs.namenode.secondary.http-address </name>
<value> doop4: 50090 </value>
</property>
<property>
<name> dfs .namenode.secondary.https-address </name>
<value> doop4: 50091 </value>
</property>
<property>
<name> dfs.namenode.name.dir </name>
<value> arquivo: / usr / dfs / name </value>
</property>
<property>
<name> dfs.datanode.data.dir </name>
<value> arquivo: / usr / dfs / data </value>
</property>
<propriedade >
<name> dfs.replication </name>
<value> 2 </value>
</property>
<property>
<name> dfs.webhdfs.enabled </name>
<value> verdadeiro </value>
</property>
<propriedade>
<nome> dfs.permissions </ nome>
<valor> falso </ valor>
</ propriedade>
<propriedade>
<nome> dfs.web.ugi </ nome
> supergrupo <valor>
</ valor> </ property>
</ configuration> A
configuração do nome do host DataNode nos escravos é
modificada para:
doop2
doop3
doop4
masters A configuração do nome do host SecondaryNameNode é
modificada para:
doop4 em
mapred-site.xml
(observe que mapred-site.xml.template deve ser renomeado para .xml O arquivo mv mapred-site.xml.template mapred-site.xml)
inclui o seguinte código:
<configuração>
<propriedade>
<nome> mapreduce.framework.name </ nome>
<valor> fio </ value>
</ property>
<propriedade>
<name> mapreduce.jobhistory.address </name>
<valor> doop1: 10020 </value>
</property>
<property>
<name> mapreduce.jobhistory.webapp.address </name>
<value> doop1: 19888 </value>
</property>
</configuration>
fio -site.xml :
添加 如下 代码:
<configuração>
<propriedade>
<name> yarn.nodemanager.aux-services </name>
<value> mapreduce_shuffle </value>
</property>
<property>
<name> yarn.nodemanager .aux-services.mapreduce.shuffle.class </name>
<value> org.apache.hadoop.mapred.ShuffleHandler </value>
</property>
<property>
<name> yarn.resourcemanager.address </name>
<valor> doop1: 8032 </value>
</property>
<property>
<name> yarn.resourcemanager.scheduler.address </name>
<value> doop1: 8030 </value>
</property>
<property>
<name> yarn.resourcemanager.resource-tracker.address </name>
<value> doop1: 8031 </value>
</property>
<property>
<name> yarn.resourcemanager.admin.address </name>
<value> doop1: 8033 </value>
</property>
<property>
<name> fio. resourcemanager.webapp.address </name>
<value> doop1: 8088 </value>
</property>
</configuration>
e hadoop 安装 到 子 节点
节点 l ::
rm -rf /usr/local/hadoop-2.7 .7 / share / doc /
scp -r /usr/local/hadoop-2.7.7 root @ doop2: / usr / local /
scp -r /usr/local/hadoop-2.7.7 root @ doop3: / usr / local /
scp -r /usr/local/hadoop-2.7.7 root @ doop4: / usr / local /
Copie o perfil para o
nó principal do nó filho e execute:
scp / etc / profile root @ doop2: / etc /
scp / etc / profile root @ doop3: / etc /
scp / etc / profile root @ doop4: / etc /
valida o novo perfil nos três nós filhos:
source / etc / profile
Configure a variável de ambiente Hadoop
vi ~ / .bash_profile
no final e inclua:
export HADOOP_HOME = / usr / local / hadoop-2.7.7
export PATH = $ PATH: $ HADOOP_HOME / bin: $ HADOOP_HOME / sbin
scp ~ / .bash_profile root @ doop2: / root /
scp ~ / .bash_profile root @ doop3: / root /
scp ~ / .bash_profile root @ doop4: / root /
加载
fonte ~ / .bash_profile
Formate o namenode do masternode
, digite o diretório hadoop no masternode e execute:
hdfs namenode -format
Dica: Formatado com sucesso indica uma formatação bem-sucedida
Inicie o
nó principal do Hadoop e execute-o no diretório Hadoop:
start-all.sh
stop Hadoop
stop-all.sh
No nó principal JPS processar como se segue:
a NameNode
o ResourceManager
processo JPS em cada criança, como se segue:
DataNode
o NodeManager
DOOP haver vários processos
SecondaryNameNode
se isso representa uma configuração de cluster hadoop com sucesso
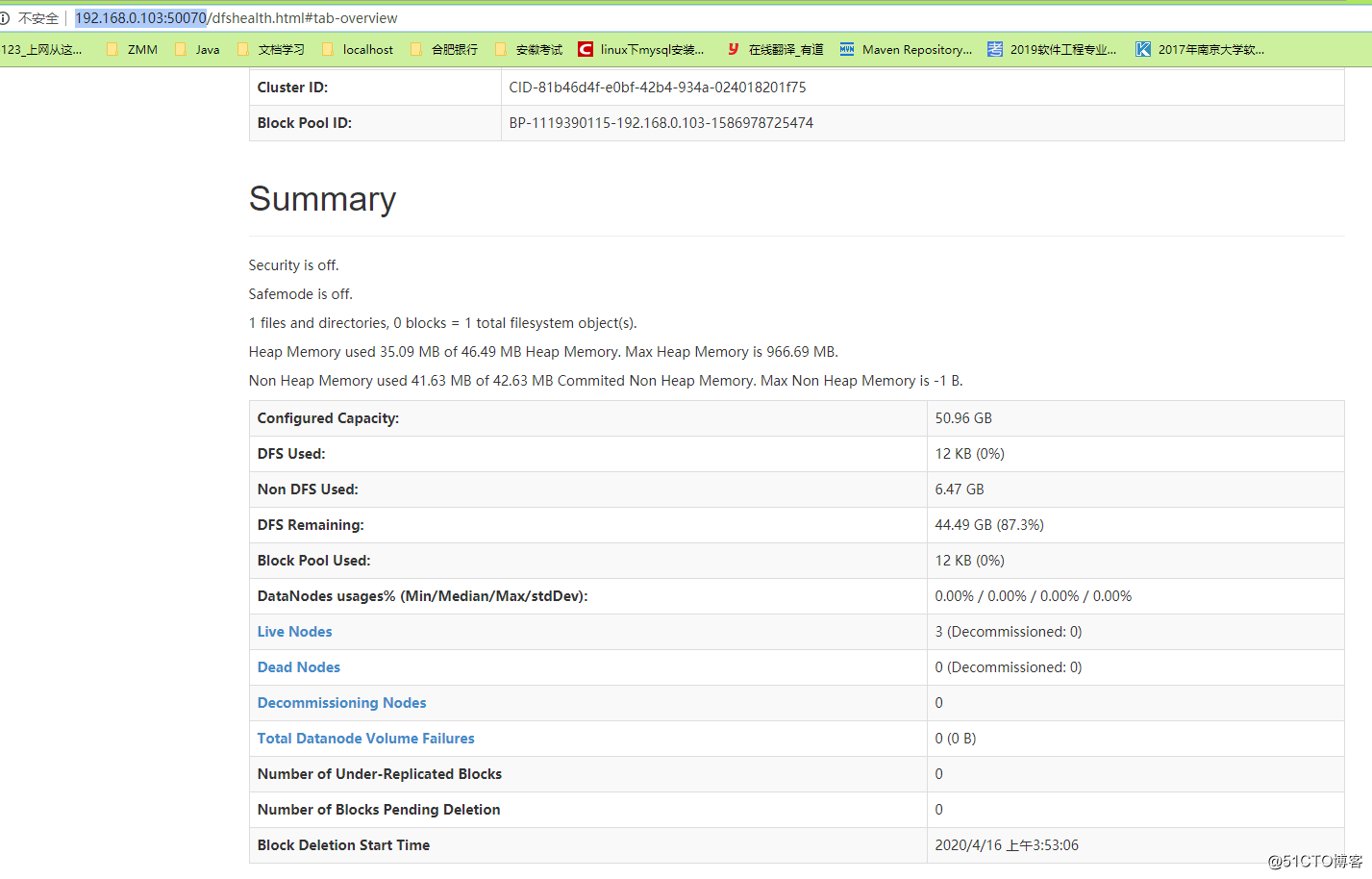
Endereço de acesso http://192.168.0.103:50070/
Se você quiser acessar pelo nome do host, precisará configurar o arquivo host do Windows
e, em seguida, consulte a página