modo de operação Capítulo VI Hadoop
modos de operação do Hadoop incluem:
- modo local, de modo distribuído-pseudo e modo distribuído completo.
- Hadoop site oficial:
http://hadoop.apache.org/
6.1 modo de operação local
6.1.1 Caso oficial Grep
- Criar Criar uma pasta no arquivo de entrada hadoop-3.1.2 abaixo
[zpark@hadoop104 hadoop-3.1.2]$ mkdir input
- Cópia Hadoop arquivo de configuração XML para entrada
[zpark@hadoop104 hadoop-3.1.2]$ cp etc/hadoop/*.xml input
- procedimentos de execução MapReduce sob o diretório share
[zpark@hadoop104 hadoop-3.1.2]$ bin/hadoop jar
share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.2.jar grep input output 'dfs[a-z.]+'
- Ver saída
[zpark@hadoop104 hadoop-3.1.2]$ cat output/*
6.1.2 Caso oficial WordCount
- Criar Criar uma pasta no wcinput hadoop-3.1.2 arquivo abaixo
[zpark@hadoop104 hadoop-3.1.2]$ mkdir wcinput
- Wc.input criar um arquivo no wcinput arquivo
[zpark@hadoop104 hadoop-3.1.2]$ cd wcinput
[zpark@hadoop104 wcinput]$ touch wc.input
- Editar arquivo wc.input
[zpark@hadoop104 wcinput]$ vi wc.input
Digite o seguinte no arquivo
hadoop yarn
hadoop mapreduce
zhangyong
zhangyong
WQ Guardar e sair ::
4. Voltar para o Hadoop diretório /opt/module/hadoop-3.1.2
execução 5. programa
[zpark@hadoop104 hadoop-3.1.2]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.2.jar wordcount wcinput wcoutput
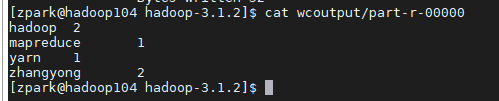
- Ver resultados
[zpark@hadoop104 hadoop-3.1.2]$ cat wcoutput/part-r-00000
zhangyong 2
hadoop 2
mapreduce 1
yarn 1
6.2 modo distribuído-pseudo de operação
6.2.1 programas HDFS e MapReduce executar
- Análise
(1) configure um cluster
(2) começar, teste add cluster, de exclusão, de verificação
(3) a implementação de WordCount caso - Passo
(1) a configuração de cluster
(a) Configuração: hadoop-env.sh
o sistema Linux para instalação caminho JDK:
[zpark@hadoop104 ~]# echo $JAVA_HOME
/opt/module/jdk1.8.0_181
Modificar caminho JAVA_HOME:
export JAVA_HOME=/opt/module/jdk1.8.0_181
(B) lugar: Núcleo-site.xml
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop104:9000</value>
</property>
<!-- 指定Hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.1.2/data/tmp</value>
</property>
(C) Configuração: hdfs-site.xml
<!-- 指定HDFS副本的数量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
(2) Inicie o cluster
(a) Formato NameNode (A primeira vez que iniciar a formatação, nem sempre após a formatação)
[zpark@hadoop104 hadoop-3.1.2]$ bin/hdfs namenode -format
(B) NameNode início
[zpark@hadoop104 hadoop-3.1.2]$ sbin/hadoop-daemon.sh start namenode
(C) iniciar DataNode
[zpark@hadoop104 hadoop-3.1.2]$ sbin/hadoop-daemon.sh start datanode
(3) Ver Cluster
(a) para ver se um início bem sucedido
[zpark@hadoop104 hadoop-3.1.2]$ jps
13586 NameNode
13668 DataNode
13786 Jps
Nota: JPS no comando JDK, não um comando Linux. JDK não está instalado não pode usar os JPS
(b) um fim de arquivo Web vista HDFS sistema
http://hadoop104:50070/dfshealth.html#tab-overview
Nota: Se você não pode ver, consulte o seguinte pós-processamento
http://www.cnblogs.com/zlslch/p/6604189.html
Log Log (c) gerado vista
Descrição: Bug encontrados na empresa, muitas vezes com base na mensagem de log para analisar e resolver Bug.
diretório atual:
/opt/module/hadoop-3.1.2/logs
[zpark@hadoop104 logs]$ ls
hadoop-zhangyong-datanode-hadoop.zhangyong.com.log
hadoop-zhangyong-datanode-hadoop.zhangyong.com.out
hadoop-zhangyong-namenode-hadoop.zhangyong.com.log
hadoop-zhangyong-namenode-hadoop.zhangyong.com.out
SecurityAuth-root.audit
[zpark@hadoop104 logs]# cat hadoop-zhangyong-datanode-hadoop104.log
(D) pensando: Por que não foi formatado NameNode, formatação NameNode, prestar atenção ao que?
Nota: A formatação NameNode, irá gerar novo ID de cluster, resultando em NameNode e DataNode id cluster é inconsistente, o cluster não pode encontrar dados do passado. Portanto, quando os formatos NameNode, os dados devem primeiro excluir os dados de log e o log, em seguida, formate NameNode.
(4) Operação do conjunto
de entrada (a) para criar uma pasta no sistema de arquivo HDFS
[zpark@hadoop104 hadoop-3.1.2]$ bin/hdfs dfs -mkdir -p /user/zhangyong/input
(B) o teor de upload de arquivos de teste para o sistema de arquivos
[zpark@hadoop104 hadoop-3.1.2]$bin/hdfs dfs -put wcinput/wc.input
/user/zhangyong/input/
(C) se a visão correta arquivos enviados
[zpark@hadoop104 hadoop-3.1.2]$ bin/hdfs dfs -ls /user/zhangyong/input/
[zpark@hadoop104 hadoop-3.1.2]$ bin/hdfs dfs -cat /user/zhangyong/ input/wc.input
(D) rodando em MapReduce
[zpark@hadoop104 hadoop-3.1.2]$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.2.jar wordcount /user/zhangyong/input/ /user/zhangyong/output
(E) ver a saída
de comando Vista:
[zpark@hadoop104 hadoop-3.1.2]$ bin/hdfs dfs -cat /user/zhangyong/output/*
Browser para ver

(f) o conteúdo do arquivo baixado para o teste local
[zpark@hadoop104 hadoop-3.1.2]$ hdfs dfs -get /user/zhangyong/output/part-r-00000 ./wcoutput/
(G) de saída suprimido
[zpark@hadoop104 hadoop-3.1.2]$ hdfs dfs -rm -r /user/zhangyong/output
6.2.2 Iniciar e programas MapReduce funcionam FIO
- Análise
(1) configurar o cluster para ser executado no FIO MR
(2) aumento início, o cluster de teste, de exclusão, de verificação
(3) no caso de execução WordCount FIO - Realize os passos de
(1) para configurar um cluster
(a) Configuração yarn-env.sh
configure o JAVA_HOME olhar
export JAVA_HOME=/opt/module/jdk1.8.0_181
(B) colocado fio-site.xml
<!-- Reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop104</value>
</property>
(C) Configuração: mapred-env.sh
configure o JAVA_HOME olhar
export JAVA_HOME=/opt/module/jdk1.8.0_181
(D) de configuração: (p-mapred site.xml.template renomeado) mapred-site.xml
[zpark@hadoop104 hadoop]$ mv mapred-site.xml.template mapred-site.xml
[zpark@hadoop104 hadoop]$ vi mapred-site.xml
<!-- 指定MR运行在YARN上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
(2) Inicie o cluster
(a) antes foi lançado o início deve garantir NameNode e DataNode
(b) iniciar ResourceManager
[zpark@hadoop104 hadoop-3.1.2]$ sbin/yarn-daemon.sh start resourcemanager
(C) iniciar NodeManager
[zpark@hadoop104 hadoop-3.1.2]$ sbin/yarn-daemon.sh start nodemanager
(3) as operações de cluster
(a) os fios navegador página de visualização, como
http://hadoop104:8088/cluster
Figura página do browser 2-35 FIO do
arquivo de saída no (b) para excluir o sistema de arquivos
[zpark@hadoop104 hadoop-3.1.2]$ bin/hdfs dfs -rm -R /user/zhangyong/output
(C) implementação de programas de MapReduce
[zpark@hadoop104 hadoop-3.1.2]$ bin/hadoop jar
share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.2.jar wordcount /user/zhangyong/input /user/zhangyong/output
(D) Ver o resultado da operação, como mostrado
[zpark@hadoop104 hadoop-3.1.2]$ bin/hdfs dfs -cat /user/zhangyong/output/*

6.2.3 história configuração do servidor
Para visualizar o histórico do funcionamento do programa, é necessário configurar a história servidor. O procedimento de configuração é a seguinte:
- Colocado mapred-site.xml
[zpark@hadoop104 hadoop]$ vi mapred-site.xml
Aumento segue dentro do arquivo.
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop104:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop104:19888</value>
</property>
- Comece a história servidor
[zpark@hadoop104 hadoop-3.1.2]$ sbin/mr-jobhistory-daemon.sh start historyserver
- servidor Ver histórico é iniciado
[zpark@hadoop104 hadoop-3.1.2]$ jps
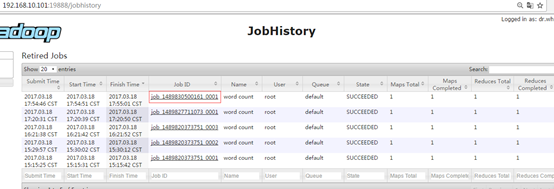
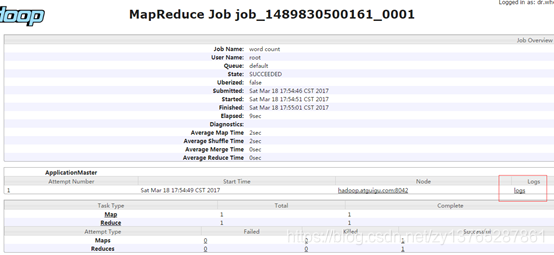
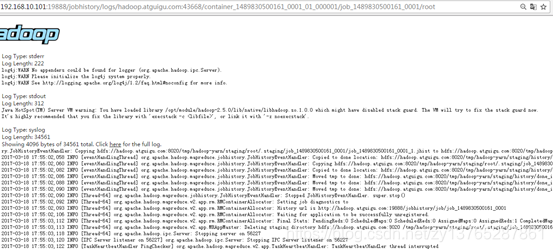
- Ver JobHistory
http://hadoop104:19888/jobhistory
6.2.4 reunir log de configuração
Log agregação conceito: Após a conclusão da aplicação está em execução, o programa será executado em informações log HDFS é carregado para o sistema.
benefícios de agregação de log: você pode facilmente visualizar os detalhes do programa para ser executado, fácil desenvolvimento e depuração.
Nota: Ativar a função de agregação de log, você precisa reiniciar NodeManager, ResourceManager e HistoryManager.
Ativar a agregação log os seguintes passos:
- Localizado fio-site.xml
[zpark@hadoop101 hadoop]$ vi yarn-site.xml
Aumento segue dentro do arquivo.
<!-- 日志聚集功能使能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 日志保留时间设置7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
- Fechar NodeManager, ResourceManager e HistoryServer
[zpark@hadoop101 hadoop-2.7.2]$ sbin/yarn-daemon.sh stop resourcemanager
[zpark@hadoop101 hadoop-2.7.2]$ sbin/yarn-daemon.sh stop nodemanager
[zpark@hadoop101 hadoop-2.7.2]$ sbin/mr-jobhistory-daemon.sh stop historyserver
- Iniciar NodeManager, ResourceManager e HistoryServer
[zpark@hadoop101 hadoop-2.7.2]$ sbin/yarn-daemon.sh start resourcemanager
[zpark@hadoop101 hadoop-2.7.2]$ sbin/yarn-daemon.sh start nodemanager
[zpark@hadoop101 hadoop-2.7.2]$ sbin/mr-jobhistory-daemon.sh start historyserver
- Excluir o arquivo de saída já existe no HDFS
[zpark@hadoop101 hadoop-2.7.2]$ bin/hdfs dfs -rm -R /user/zpark/output
- a execução do programa WordCount
[zpark@hadoop101 hadoop-2.7.2]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /user/zpark/input /user/zpark/output
6.2.5 Descrição do Perfil
arquivo de configuração do Hadoop divididos em duas categorias: o padrão arquivos de configuração e arquivos de configuração personalizada, apenas a um usuário quiser modificar os valores de configuração padrão, só precisa modificar o arquivo de configuração personalizada, altere os valores dos atributos apropriados.
(1) o arquivo de configuração padrão:
| Para obter o arquivo padrão | arquivo Hadoop armazenado em um frasco na posição |
|---|---|
| [Núcleo-default.xml] | hadoop-comum-2.7.2.jar / núcleo-default.xml |
| [Hdfs-default.xml] | hadoop-hdfs-2.7.2.jar / hdfs-default.xml |
| [Fio-default.xml] | hadoop-fios comum-2.7.2.jar / fio-default.xml |
| [Mapred-default.xml] | hadoop-mapreduce-client-core-2.7.2.jar / mapred-default.xml |
arquivo de configuração (2) personalizado:
core-site.xml
hdfs-site.xml
yarn-site.xml
mapred-site.xml
arquivos de configuração quatro em $ HADOOP_HOME / etc / Hadoop este caminho, o usuário pode voltar a modificar a configuração de acordo com os requisitos do projeto.
