Construção de cluster distribuído Hadoop (foco extremo)
Artigo Diretório
3.1 Construir metas
Devido às limitações do hardware da máquina (aqui, o computador da Cris tem memória de 16G), tive que construir o seguinte ambiente

Na verdade, são necessárias pelo menos seis máquinas virtuais para construir um ambiente completo. Devido às condições limitadas, é difícil fazer até três máquinas virtuais.
Os nomes de componentes específicos e a identidade de cada nó não serão introduzidos aqui. Se você não entende, por favor Google
3.2 Processo de construção
As máquinas nº 101, 102 e 103 têm seus próprios ambientes Java e Hadoop. Aqui, escolhemos o nº 101 como
host para a configuração do ambiente Hadoop. Após a conclusão da configuração, ela pode ser sincronizada diretamente com as máquinas nº 102 e 103.
①, arquivo de configuração principal
Aqui, Cris define as permissões primeiro. Você deve garantir que o proprietário e o grupo de / opt / software e / opt / módulo sejam todos cris

Siga atentamente os dois primeiros capítulos, não existe tal problema, saiba que
modificar o arquivo de configuração principal core-site.xml


Modificar arquivo de configuração HDFS
hadoop-env.sh


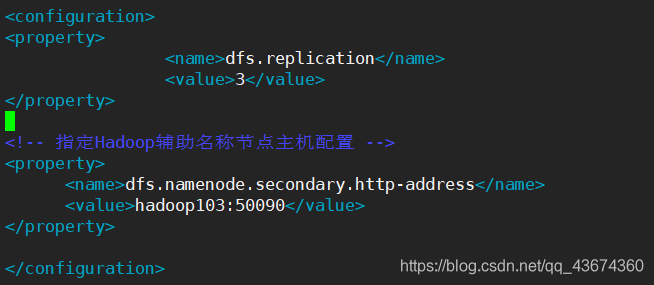
hdfs-site.xml
insira vim hdfs-site.xml e modifique-o da seguinte maneira:
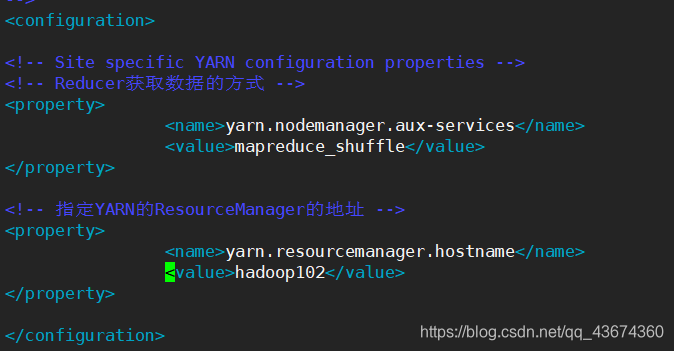
Modifique o arquivo de configuração YARN
yarn-env.sh

yarn-site.xml
Arquivo de configuração MapReduce
mapred-env.sh

mapred-site.xml


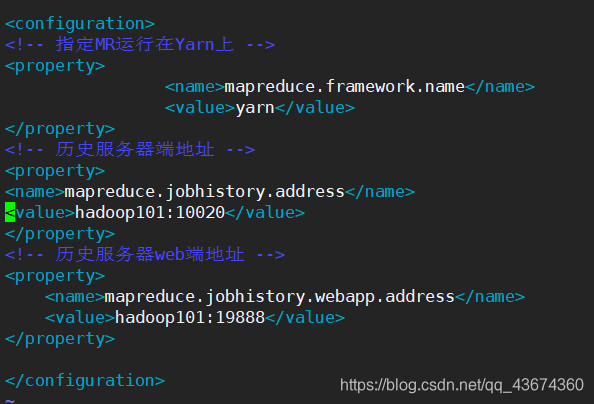
Configure o History Server
Para visualizar a operação histórica do programa, digite vim mapred-site.xml
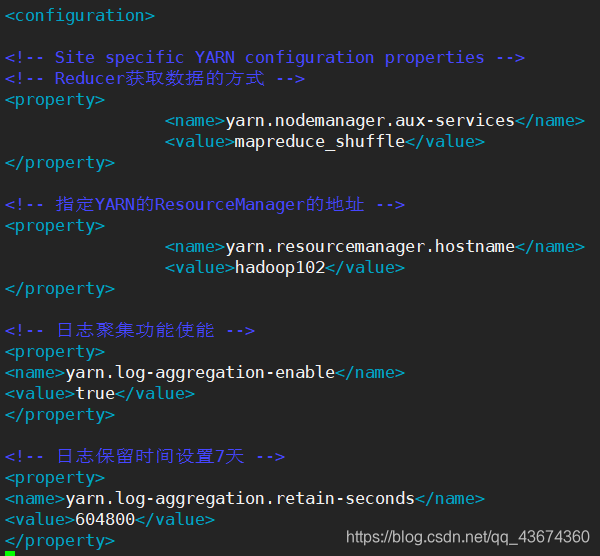
Agregação de log de configuração
Conceito de agregação de log: Depois que o aplicativo é concluído, as informações do log de operação do programa são carregadas para o sistema HDFS. Benefícios da função de agregação de log: você pode facilmente verificar e
ver os detalhes em execução do programa, o que é conveniente para desenvolvimento e depuração.
Digite vim yarn-site.xml
②. Distribuir os arquivos de configuração Hadoop configurados no cluster

Verifique se os arquivos de 102 e 103 foram sincronizados com sucesso
102


103


③, início de ponto único do cluster
formato

Iniciar NameNode em 101

101, 102, 103 iniciar DataNode respectivamente
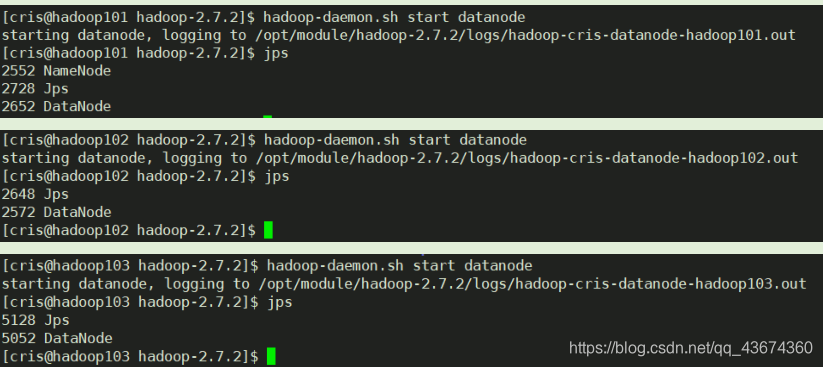
Eu pessoalmente recomendo executar um único nó primeiro após a configuração ser concluída, encontrar e resolver problemas a tempo e, em
seguida, interromper o serviço de ponto único

3.3 Inicie o cluster
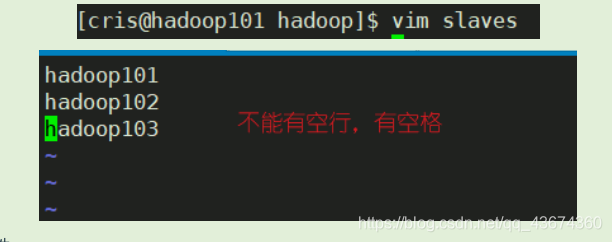
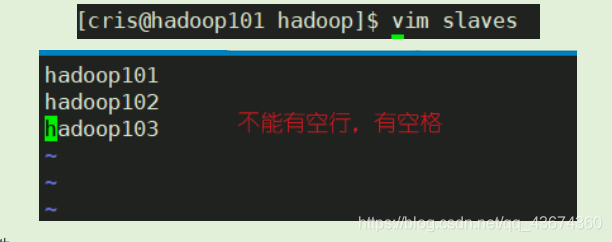
Configurar escravos
Em seguida, sincronize o arquivo
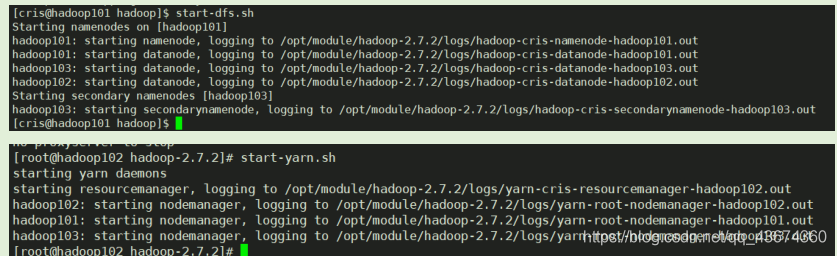
Inicie o cluster e teste
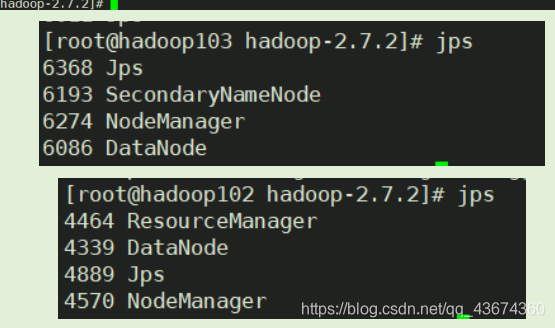
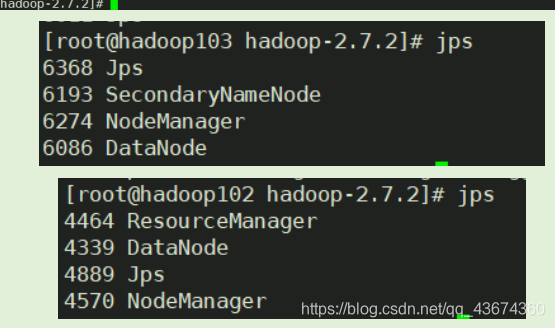
Visite a página da web correspondente
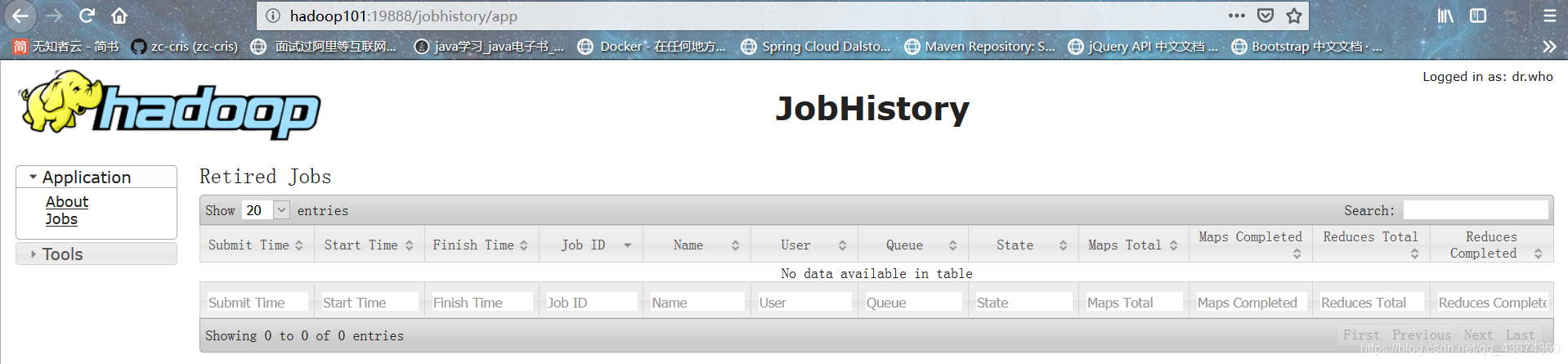
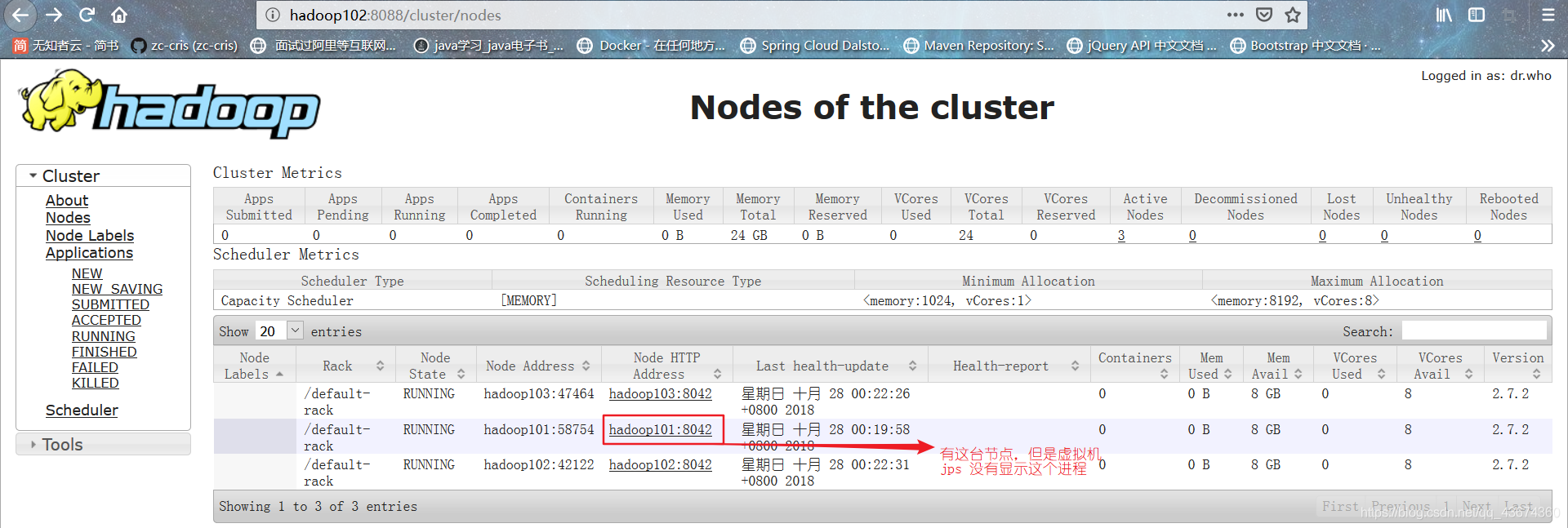
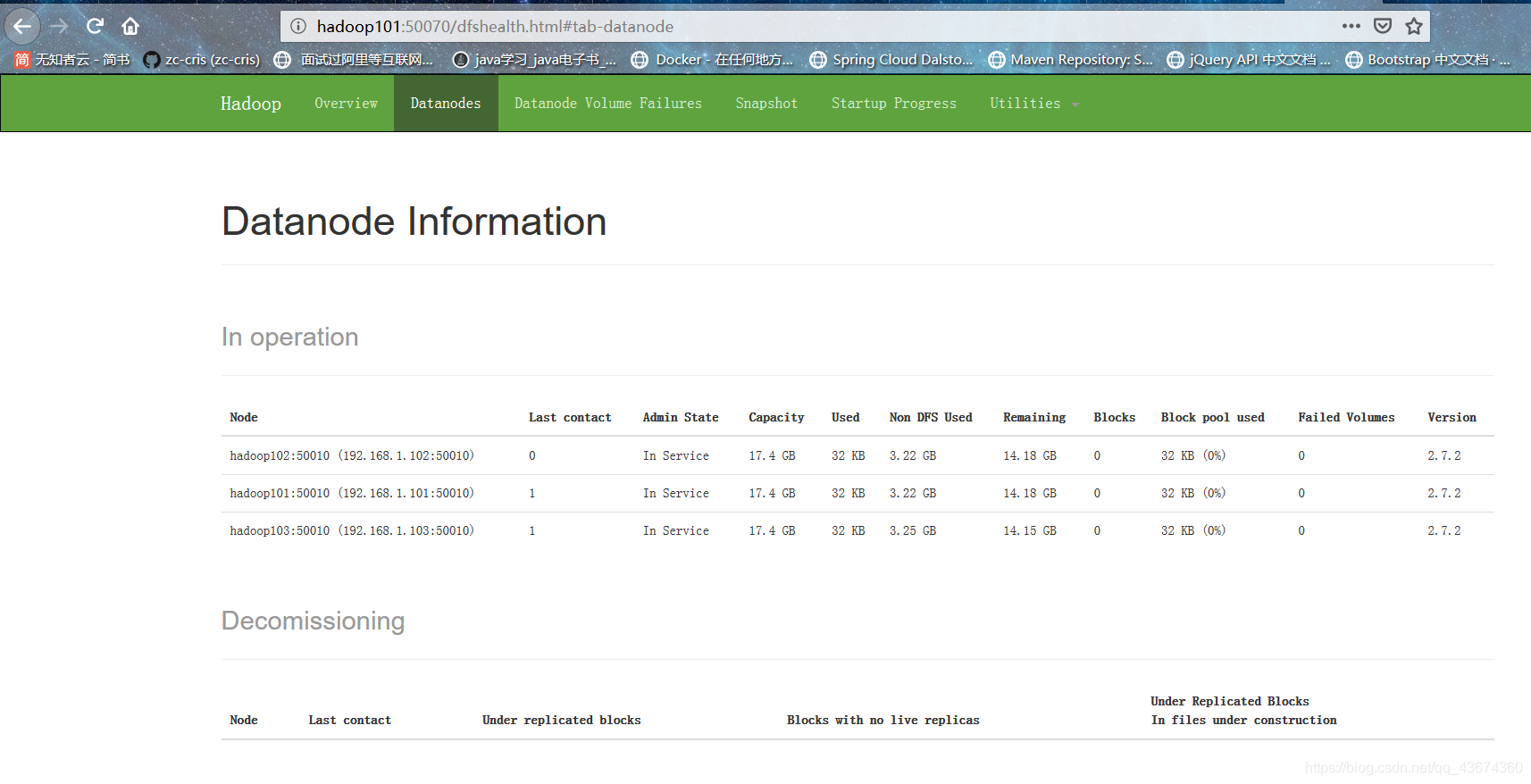 para ver a próxima
para ver a próxima