estruturas cluster de HA pode ser construído numa base totalmente distribuído
objectivo:
Reduzir a incidência de pontos únicos de falha
diagrama configuração planeamento
| NN1 | NN2 | DN | ZK | ZKFC | JNN | RM | |
|---|---|---|---|---|---|---|---|
| hadoop100 | * | * | * | * | * | * | |
| hadoop101 | * | * | * | * | * | * | |
| hadoop102 | * | * | * |
A Fig. NN, ND, ZK, ZKFC, JNN, RM é daqui em diante referido como
NN: NameNode
o DN: DataNodes
ZK: o Zookeeper
ZKFC: o cliente Zookeeper
JNN: Journalnode
RM: resourceManager
preparativos:
1, servidor de sincronização de tempo de configuração (opcional)
Todos os nós executar
yum -y install ntp
ntpdate ntp1.aliyun.com
2, configure o mapeamento de cada host (não sei para resolver seus próprios Baidu)
3, evitar fechar Entrar
Todos os nós executar
ssh-keygen-t rsa //生成密钥 中途停下询问的一直按回车到执行成功为止
ssh-copy-id hadoop101 //发送公钥到其他节点上
4, desligar as configurações de firewall
systemctl stop firewalld.service //暂时关闭
systemctl disable firewalld.service //永久关闭
Começou a construir um cluster Hadoop alta disponibilidade
instalação do JDK (se for uma instalação mínima Centos jdk padrão não é instalado diretamente extrair o bem, a instalação gráfica requer desinstalar o JDK original para instalar)
Extraindo instalação do pacote hadoop
tar xf hadoop2.7.7... -C /module/ha/
arquivo de configuração do Hadoop para o diretório
cd /module/ha/hadoop/etc/hadoop
Três (Hadoop, fios, mapred) arquivo -env.sh, encontrar o conjunto JAVA_HOME jdk caminho de instalação
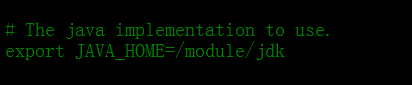
Colocado núcleo-site.xml
vi core-site.xml
<!-- 设置hdfs的nameservice服务 名称自定义 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<!-- 设置hadoop的元数据存放路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/moudle/ha/hadoop/data</value>
</property>
<!-- 指定zookeeper地址 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop100:2181,hadoop101:2181,hadoop102:2181</value>
</property>
vi hdfs-site.xml
<!-- 完全分布式集群名称 -->
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<!-- 集群中NameNode节点都有哪些 -->
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>hadoop100:9000</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>hadoop101:9000</value>
</property>
<!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>hadoop100:50070</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>hadoop101:50070</value>
</property>
<!-- 指定NameNode元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop100:8485;hadoop101:8485;hadoop102:8485/mycluster</value>
</property>
<!-- 配置隔离机制,即同一时刻只能有一台服务器对外响应 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- 使用隔离机制时需要ssh无秘钥登录-->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!-- 声明journalnode服务器存储目录-->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/module/ha/hadoop/data/jn</value>
</property>
<!-- 关闭权限检查-->
<property>
<name>dfs.permissions.enable</name>
<value>false</value>
</property>
<!-- 访问代理类:client,mycluster,active配置失败自动切换实现方式-->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!--设置开启HA故障自动转移-->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
Colocado mapred-site.xml
vi mapred-site.xml
Adicionar a seguinte configuração
<!-- 指定mr框架为yarn方式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
Configuração fio-site.xml (opcional)
vi yarn-site.xml
Adicionar a seguinte configuração
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--启用resourcemanager ha-->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!--声明两台resourcemanager的地址-->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>cluster-yarn1</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>hadoop100</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>hadoop101</value>
</property>
<!--指定zookeeper集群的地址-->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>hadoop100:2181,hadoop101:2181,hadoop102:2181</value>
</property>
<!--启用自动恢复-->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!--指定resourcemanager的状态信息存储在zookeeper集群-->
<property>
<name>yarn.resourcemanager.store.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
escravos de configuração
vi slaves
hadoop100
hadoop101
hadoop102
Configuração terminou distribuídos para todos os nós
scp –r -p /usr/local/hadoop/ root@master2:/usr/local/
instalação Zookeeper
Descompacte o arquivo
tar xf 文件名 -C 存放路径
Boa auto-configuração variável de ambiente
zoo_sample.cfg sob o diretório conf modificado
mv zoo_sample.cfg zoo.cfg
vi zoo.cfg
Armazenar os metadados armazenados no zk definição do caminho
dataDir=/module/zookeeper/zk
Na parte inferior do arquivo adicionar os seguintes dados
Server.1=hadoop100:2888:3888
Server.2=hadoop101:2888:3888
Server.3=hadoop102:2888:3888
Gerando a localização toras de modificar tratadornão pode ser modificado
vi bin/zkEnv.sh

modificaçãoapontando segunda flecha para o caminhoPara colocar seu próprio deseja armazenar
Criando um metadados do arquivo armazenado no caminho de armazenamento de zk
mkdir /module/zookeeper/zk
Distribuir zookeeper arquivos de configuração zookeeper a todos os nós
escritos em diferentes nós correspondentes a id
echo 1 > /module/zookeeper/zk/myid # hadoop100节点上:
ZooKeeper em cada nó do cluster, execute os serviços ZooKeeper de script de inicialização
zkServer.sh start
detalhes de implantação
1, você deve começar journalnode
hadoop-daemons.sh start journalnode
2, em que a selecção é configurado para executar um formato de tabela em hadoop nó NN
bin/hdfs namenode –format
3. Selecione um namenode início NN
sbin/hadoop-daemon.sh start namenode
4, a sincronização dos dados é executada em outro nó NN
bin/hdfs namenode -bootstrapStandby
5, sobre um NN em que a formatação zkfc realizada
bin/hdfs zkfc –formatZK
Em que o NN iniciar aglomerado hadoop
sbin/start-dfs.sh
Use jps comando para vistacadaExiste um nó seguinte nó
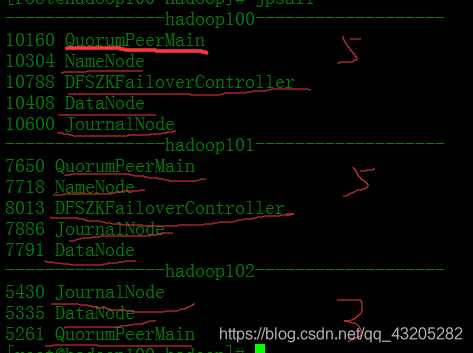
ponto do cluster completa hadoop HA! ! ! !
RM é aberta está disposta sobre o HA desempenha nó RM
sbin/start-yarn.sh
Numa outra configuração também é realizada na RM nó
sbin/yarn-daemon.sh start resourcemanager
Veja todos os nós têm o seguinte nó da RM configuração de cluster HA até agora com sucesso! ! ! ! ! !
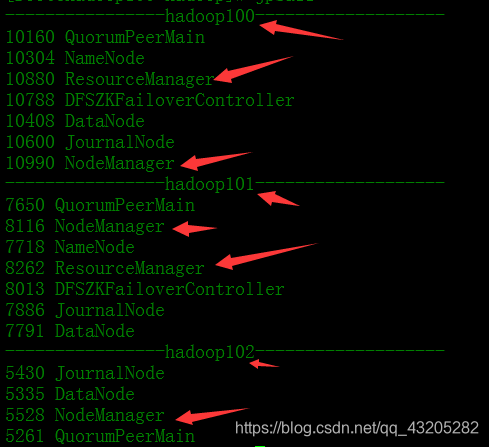
Comandos frequentemente utilizados NameNode processo começa: hadoop-daemon.sh Iniciar os NameNode
processo DataNode começa: hadoop-daemon.sh DataNode inícioHA ambiente de alta disponibilidade, você precisa para começar o processo: zookeeper: zkServer.sh início zkServer.sh parada start
estado zkServer.sh para exibir o status de follwer lídercomando de cluster journalnode journalnode início hadoop-daemon.sh começar hadoop-daemon.sh
PARAR Pára journalnodeZKFC Formato: hdfs zkfc -formatZK começar zkfc processo: hadoop-daemon.sh início zkfc
processo de parada zkfc: zkfc parada hadoop-daemon.shNameNode nome sincronização de dados: hdfs namenode -bootstrapStandby
Inicie o processo de fios:
yarn-daemon.sh começar ResourceManager
Analógico Detector de estado automaticamente failover em espera NN
- Use jps id Ver processo namenode
jps
- processo namenode parada
kill -9 namenode的进程id
Então veja se a página web dois namenode para ver o estado de comutação
3. processo namenode Restart:
hadoop-daemon.sh start namenode
