The author of this article is Hong Dongdong, software development engineer of the big data team of China Mobile Cloud Competence Center. The article mainly introduces the principle of Apache Kyuubi's high availability based on Apache ZooKeeper, and the use of existing components and technologies to achieve cloud-native load in cloud-native scenarios. Balanced and client-side high concurrency.
background
Apache Kyuubi is a distributed, multi-tenant gateway for serving Serverless SQL on Lakehouse. Kyuubi was originally a large-scale data processing and analysis tool compatible with the HiveServer2 protocol built on Apache Spark, and currently supports engines such as Flink/Trino/Hive/Doris. Kyuubi is committed to being an out-of-the-box data warehouse and data lake tool that allows anyone to use various computing engines easily and efficiently, and can process big data like ordinary data on the basis of understanding SQL. In the Kyuubi architecture, there are three main features:
1. Multi-tenancy, Kyuubi provides end-to-end multi-tenancy support for resource acquisition and data/metadata access through a unified authentication authorization layer. 2. High availability, Kyuubi provides load balancing through ZooKeeper, which provides enterprise-level high availability and unlimited client high concurrency. 3. Multiple workloads, Kyuubi can easily support multiple different workloads with one platform, one data copy and one SQL interface.
In a cloud-native scenario, additional deployment and maintenance of ZooKeeper is expensive. Do we have a cloud-native solution to replace it?
High Availability Implementation Based on ZooKeeper
The DiscoveryClient interface under the Kyuubi-ha module contains all the interfaces (based on the master branch) that need to be implemented for service registration and discovery, roughly including: client creation and shutdown, node creation and deletion, node existence, registration and deregistration services, obtain distributed locks, obtain engine addresses, etc. The diagram below briefly shows the steps involved in interacting with discovery as a tenant connects to Kyuubi.

When we start the Kyuubi server or start the engine, ServiceDiscovery will register relevant information in ZooKeeper. After the tenant obtains the list of available servers, the tenant selects the server to open the session according to the policy. During the process of opening the session, the Kyuubi server will be based on the user connection The engine sharing strategy of ZooKeeper looks for an available engine in ZooKeeper, and if not, pulls up a new engine and connects.
In the whole process, two core functions of ZooKeeper are mainly used: service registration and distributed lock.
service registration
ZooKeeper provides 4 ways to create nodes:
1. PERSISTENT (persistence) even if the client is disconnected from ZooKeeper, the node still exists, as long as the node is not manually deleted, it will exist forever; 2. PERSISTENT_SEQUENTIAL (persistent sequence numbering directory node) is based on the persistent directory node , ZooKeeper sequentially numbers the node name; 3.EPHEMERAL (temporary directory node) After the client disconnects from ZooKeeper, the node will be deleted; 4.EPHEMERAL_SEQUENTIAL (temporary sequence numbering directory node) is based on the temporary directory node ZooKeeper numbers the node name sequentially
The service registration of server and engine in Kyuubi is implemented based on EPHEMERAL_SEQUENTIAL. A temporary node is created when the service starts, and the link is disconnected when it exits, and ZooKeeper automatically deletes the corresponding node. At the same time, when the service is started, a temporary node of the watcher monitoring registration will be created. When the node is deleted, the service will be stopped gracefully.
Distributed lock
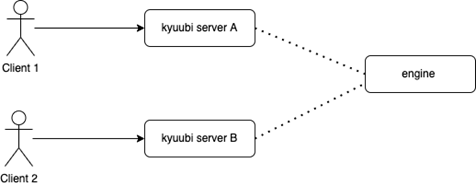
As shown in the figure above, when two clients request the same engine at the same time, if the engine does not exist, in the unlocked state, we will start the two engines. When there is a new connection in the future, it will always connect to the engine registered later. The first registered engine will be idle for a long time. Therefore, when creating a new engine, by adding a distributed lock to the corresponding node, the client that acquires the lock first creates the engine, and the client that acquires the lock directly uses the started engine.
High-availability cloud-native implementation based on ETCD
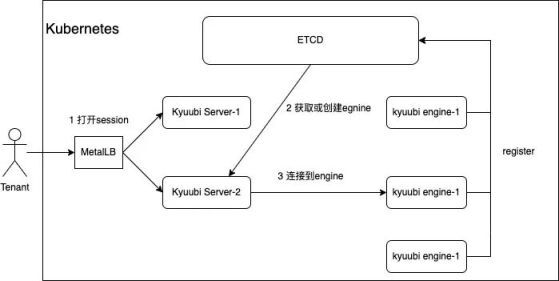
The figure above shows the process of tenants connecting to Kyuubi in a cloud-native scenario, which involves key components in cloud-native applications, ETCD and MetalLB. Among them, ETCD is responsible for engine service registration and discovery, and MetalLB provides load balancing capabilities for Kyuubi server.
Since ETCD supports engine registration and discovery, why doesn't it support high availability of Server at the same time as ZooKeeper?
We mainly consider this from the perspective of customer use. The beeline and jdbc drivers we usually use support ZooKeeper-based service discovery, but do not support ETCD. If the server is registered in ETCD, we have no way to be compatible with existing clients, and we need to provide additional drivers for tenants. At the same time, we also know that in cloud-native scenarios, MetalLB can provide load balancing for the following pods (deployments) through a single IP. After consideration, we finally choose the ETCD+MetalLB method.
About ETCD
ETCD is a distributed and consistent KV storage system for shared configuration and service discovery. It is an open source project initiated by CoreOS, and its licensing protocol is Apache. ETCD has many usage scenarios, including: configuration management, service registration and discovery, leader election, application scheduling, distributed queues, distributed locks, etc. Among them, many application scenarios are service discovery. Service discovery (Service Discovery) is to solve one of the most common problems in distributed systems, that is, how can processes or services in the same distributed cluster find each other and establish connect. ETCD is the primary data store for Kubernetes and the de facto standard system for container orchestration. Using ETCD, cloud-native applications can maintain a more consistent uptime and function in the event of individual server failures. Applications read data from and write to ETCD; providing redundancy and resiliency for node configuration by decentralizing configuration data.
A simple comparison of ETCD and ZooKeeper is as follows:
| ETCD | ZooKeeper | |
| Conformance Protocol | Raft | Ps |
| API | HTTP+JSON, gRPC | client |
| safely control | HTTPS | Kerberos |
| Operation and maintenance | Simple | difficulty |
About MetalLB
Kubernetes does not provide a load balancer implementation by default. MetalLB provides a network load balancer implementation for Kubernetes through MetalLB hooks. Simply put, it allows to create LoadBalancer type services in private Kubernetes. MetalLB has two main functions:
1. Address allocation: When applying for LB in the platform, an IP will be automatically allocated. Therefore, MetalLB also needs to manage the allocation of IP addresses. 2. IP external declaration: When MetalLB obtains an external address, it needs to declare the IP to be used in Kubernetes. , and can communicate normally.
implementation details
When the underlying engine of Kyuubi starts, the corresponding Key will be created in ETCD. The tenants use is to directly connect to the address provided by MetalLB, and the underlying LoadBalancer is responsible for load balancing. After connecting to the corresponding Kyuubi server, the server will look for an available engine in ETCD, and create it if not. It mainly involves the following three points:
1. Use the native component MetalLB+Deployment in Kubernetes to achieve high availability of Kyuubi server 2. Simulate the EPHEMERAL_SEQUENTIAL node in ETCD. There is no concept of temporary key in ETCD, and the corresponding key information cannot be automatically deleted when the service stops. However, the KeepAlive function is provided in the client: an expiration time is attached to a specific Key, and the expiration time is automatically refreshed when the client is not closed or timed out. At the same time, when the engine is registered, it obtains the distributed lock of the corresponding node and calculates the number to realize the self-increase of the node number. 3. Distributed locks. The distributed locks of ETCD are basically the same as ZooKeeper in terms of use, but they are slightly different in terms of lock holding time. The locks in ETCD have a lease time. If the lock is not actively released after the time, it will be automatically released. , and ZooKeeper will not release if it is not actively released.
Summarize
First, let's briefly compare the cloud-native architecture with the existing architecture:
| Server+ZooKeeper | Kurbernetes+ETCD | |
| package management | none | Helm3 |
| Server high availability | ZooKeeper | LoadBalancer |
| Engine registration | ZooKeeper | ETCD |
| Deployment and maintenance costs | high | Low |
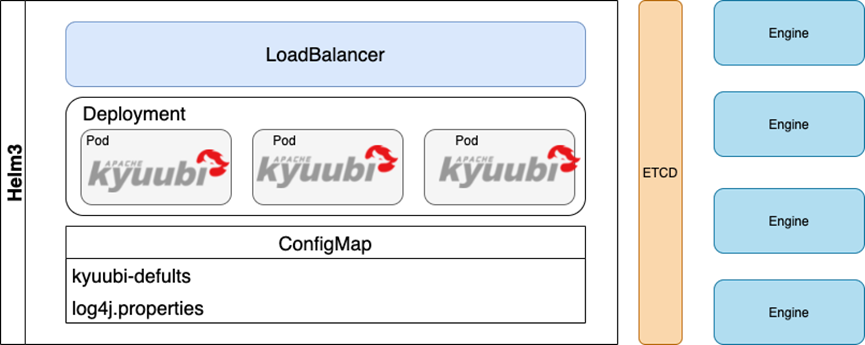
The introduction of the cloud native architecture of Kyuubi greatly reduces the cost of deployment and operation and maintenance, and based on deployment, we can realize the dynamic expansion of the Kyuubi server, and realize the unified configuration management of the server based on the comfigmap. At present, we mainly refer to the implementation of ZooKeeper for the service registration and discovery logic of ETCD, and the subsequent work will further optimize the calling logic.
Finally, our current overall architecture diagram of Kyuubi is as follows, for your reference.