introduzir
Há muitas informações valiosas contidas em arquivos PDF e de imagem. Felizmente, temos cérebros poderosos que podem processar esses arquivos para encontrar informações específicas, o que é realmente ótimo.
Mas quantos de nós, no fundo, não gostaríamos que existisse uma ferramenta que pudesse responder a qualquer pergunta sobre um determinado documento?
Fluxo de trabalho geral do projeto
É sempre benéfico ter uma compreensão clara dos principais componentes do sistema que você está construindo. Então vamos começar.
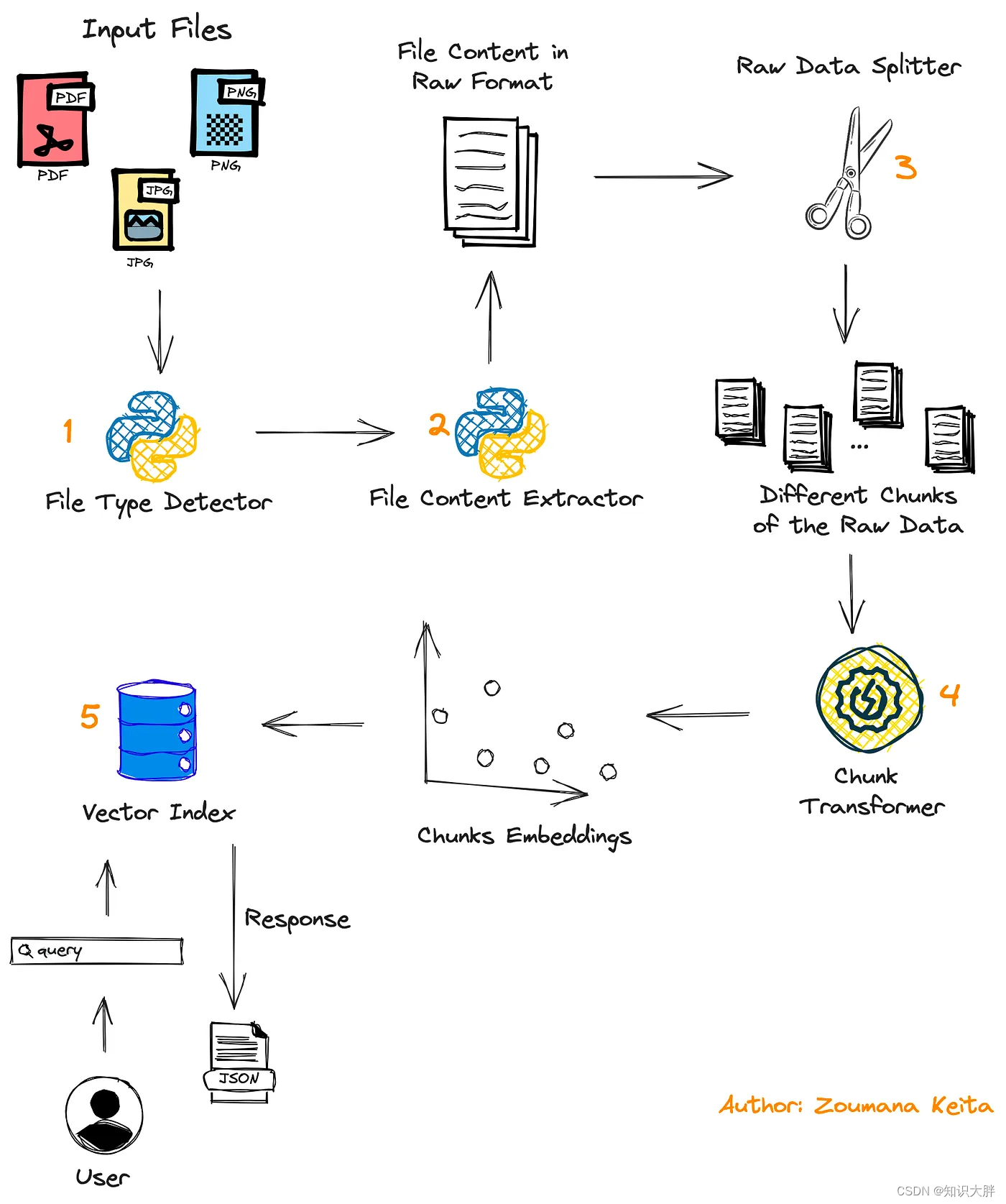
Primeiramente, o usuário envia um documento para processamento, que pode ser em formato PDF ou imagem.
O segundo módulo é usado para detectar o formato do arquivo para aplicar funções relevantes de extração de conteúdo.
O conteúdo do documento é então dividido em partes usando o módulo Data Splitter.
Transformador de pedaços Esses pedaços são finalmente transformados em embeddings antes de serem armazenados em armazenamento vetorial.
Ao final do processo, a consulta do usuário é usada para encontrar blocos relevantes que contenham a resposta à consulta, e os resultados são retornados ao usuário como JSON.
1. Detecte o tipo de documento
Para cada documento de entrada, com base no seu tipo (seja PDF ou imagem.
Isso pode ser alcançado por meio de uma função auxiliar combinada com a função detect_document_type no módulo Python integrado. adivinhar
def detect_document_type(document_path):
guess_file = guess(document_path)
file_type = ""
image_types = ['jpg', 'jpeg', 'png', 'gif']
if(guess_f