1, tipo inserção
Ordenação por inserção é um algoritmo de classificação simples. Ele funciona através da construção de uma seqüência ordenada, para dados não classificado, a digitalização na seqüência ordenada de trás para frente, e encontrar as posições de inserção correspondentes.
public static void insertSort(int[] array){
for(int i = 1;i < array.length;i++){
int temp = array[i];
int j = i - 1;
for(;j >=0 && array[j] > temp;j--){
array[j+1] = array[j];
}
array[j+1] = temp;
}
}
2, a classificação do monte
Hill, também conhecido como incrementos tipo escolha descendente algoritmo é um tipo de inserção mais eficaz de uma versão melhorada. Colina de classificação algoritmo de classificação não-estacionária.
Colina triagem método melhorado é apresentada com base nos seguintes dois pontos propriedades inserção tipo:
Quando a operação de inserção de dados tipo quase classificados, de alta eficiência, isto é, a eficiência da ordenação linear pode ser alcançada
, mas é geralmente ineficiente inserção tipo, tipo de inserção de dados, porque só pode ser movido um
public static void shellSort(int[] array) {
int i,j,temp,gap = 1;
int len = array.length;
while(gap < len / 3){gap = gap * 3 + 1;}
for(;gap > 0;gap /= 3){
for(i = gap;i < len;i++){
temp = array[i];
for(j = i - gap;j >= 0&& array[j] > temp;j -= gap){
array[j+gap] = array[j];
}
array[j+gap] = temp;
}
}
}
3. Selecione o tipo
Em primeiro lugar, encontrar a menor sequência de não triados (grande) elemento, a posição de partida é armazenado na sequência ordenada, e, em seguida, continuar a encontrar o elemento mínimo (grande) a partir dos restantes elementos não triados e classificados no final da sequência. E assim por diante, até que todos os elementos estão ordenados.
public static void selectSort(int[] array){
int position = 0;
for(int i = 0;i < array.length;i++){
int j = i + 1;
position = i;
int temp = array[i];
for(;j < array.length;j++){
if(array[j] < temp){
temp = array[j];
position = j;
}
}
array[position] = array[i];
array[i] = temp;
}
}
4, heapsort
Ele refere-se a uma tal estrutura de dados de triagem algoritmo concebido para uso montão. Uma pilha está quase completa estrutura de árvore binária, enquanto atende as propriedades de volume: isto é, o nó de chave ou índice de criança é sempre menor do que (ou superior a) seu nó pai.
https://www.cnblogs.com/lanhaicode/p/10546257.html
public static void heapSort(int[] array) {
/*
* 第一步:将数组堆化
* beginIndex = 第一个非叶子节点。
* 从第一个非叶子节点开始即可。无需从最后一个叶子节点开始。
* 叶子节点可以看作已符合堆要求的节点,根节点就是它自己且自己以下值为最大。
*/
int len = array.length - 1;
int beginIndex = (len - 1) >> 1;
for (int i = beginIndex; i >= 0; i--) {
maxHeapify(i, len, array);
}
/*
* 第二步:对堆化数据排序
* 每次都是移出最顶层的根节点A[0],与最尾部节点位置调换,同时遍历长度 - 1。
* 然后从新整理被换到根节点的末尾元素,使其符合堆的特性。
* 直至未排序的堆长度为 0。
*/
for (int i = len; i > 0; i--) {
swap(0, i, array);
maxHeapify(0, i - 1, array);
}
System.out.println(Arrays.toString(array) + " heapSort");
}
private static void swap(int i, int j, int[] arr) {
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
/**
* 调整索引为 index 处的数据,使其符合堆的特性。
*
* @param index 需要堆化处理的数据的索引
* @param len 未排序的堆(数组)的长度
*/
private static void maxHeapify(int index, int len, int[] arr) {
int li = (index << 1) + 1; // 左子节点索引
int ri = li + 1; // 右子节点索引
int cMax = li; // 子节点值最大索引,默认左子节点。
if (li > len) {
return; // 左子节点索引超出计算范围,直接返回。
}
if (ri <= len && arr[ri] > arr[li]) // 先判断左右子节点,哪个较大。
{ cMax = ri; }
if (arr[cMax] > arr[index]) {
swap(cMax, index, arr); // 如果父节点被子节点调换,
maxHeapify(cMax, len, arr); // 则需要继续判断换下后的父节点是否符合堆的特性。
}
}
5, bubble sort
public static void bubbleSort(int[] array) {
int size = array.length;
for(int i = 0;i < size - 1;i++) {
for(int j = i + 1;j < size;j++) {
if(array[j] > array[i]) {
int temp = array[j];
array[j] = array[i];
array[i] = temp;
}
}
}
}
6, Quick Sort
Sob condições médias, para ordenar n itens 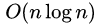 (O notação Big) comparando vezes. Na pior situação que você precisa para
(O notação Big) comparando vezes. Na pior situação que você precisa para 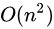 comparações, mas esta situação não é incomum. Na verdade, rápido tipo geralmente é significativamente mais rápido do que outros algoritmos, porque o seu ciclo interior (circuito interno) pode ser alcançado de forma muito eficiente na maioria das arquiteturas.
comparações, mas esta situação não é incomum. Na verdade, rápido tipo geralmente é significativamente mais rápido do que outros algoritmos, porque o seu ciclo interior (circuito interno) pode ser alcançado de forma muito eficiente na maioria das arquiteturas.
public static void quickSort(int[] array,int left,int right){
if(left > right)
return;
int base = array[left];
int i = left, j = right;
while(i!=j) {
while(array[j]>=base && i < j) {
j--;
}
while(array[i]<=base && i < j) {
i++;
}
if(i < j) {
int temp = array[i];
array[i] = array[j];
array[j] = temp;
}
}
array[left] = array[i];
array[i] = base;
quickSort(array,left,i-1);
quickSort(array,i+1,right);
}
7, merge sort
eficiência 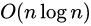
https://www.jianshu.com/p/33cffa1ce613
public static void mergeSort(int[] arr) {
sort(arr, 0, arr.length - 1);
}
public static void sort(int[] arr, int L, int R) {
if(L == R) {
return;
}
int mid = L + ((R - L) >> 1);
sort(arr, L, mid);
sort(arr, mid + 1, R);
merge(arr, L, mid, R);
}
public static void merge(int[] arr, int L, int mid, int R) {
int[] temp = new int[R - L + 1];
int i = 0;
int p1 = L;
int p2 = mid + 1;
// 比较左右两部分的元素,哪个小,把那个元素填入temp中
while(p1 <= mid && p2 <= R) {
temp[i++] = arr[p1] < arr[p2] ? arr[p1++] : arr[p2++];
}
// 上面的循环退出后,把剩余的元素依次填入到temp中
// 以下两个while只有一个会执行
while(p1 <= mid) {
temp[i++] = arr[p1++];
}
while(p2 <= R) {
temp[i++] = arr[p2++];
}
// 把最终的排序的结果复制给原数组
for(i = 0; i < temp.length; i++) {
arr[L + i] = temp[i];
}
}
8, radix sort
Tipo de comparação é um não inteiro algoritmo de classificação, o princípio é o número inteiro de bits é cortada por diferentes números, então o número de bits para cada um foram comparados. Uma vez que o inteiro pode ser expressas cadeias de vírgula flutuante (por exemplo, nome ou data) e um formato específico, a espécie radix não é utilizado apenas para o número inteiro.
//实现基数排序 LSD-从最低位开始排 MSD-从最高位开始排
public void radixSort(int[] data) {
int maxBin = maxBin(data);
List<List<Integer>> list = new ArrayList<List<Integer>>();
for(int i = 0; i < 10; i ++) {
list.add(new ArrayList<Integer>());
}
for(int i = 0, factor = 1; i < maxBin; factor *= 10, i ++) {
for(int j = 0; j < data.length; j ++) {
list.get((data[j]/factor)%10).add(data[j]);
}
for(int j = 0, k = 0; j < list.size(); j ++) {
while(!list.get(j).isEmpty()) {
data[k] = list.get(j).get(0);
list.get(j).remove(0);
k ++;
}
}
}
}
//计算数组里元素的最大位数
public int maxBin(int[] data) {
int maxLen = 0;
for(int i = 0; i < data.length; i ++) {
int size = Integer.toString(data[i]).length();
maxLen = size > maxLen ? size : maxLen;
}
return maxLen;
}
