Javaのマルチスレッド(10)
ノンブロッキングキュー
ConcurrentHashMapの
不安のマルチスレッドの条件でのHashMap:
public class MyService {
public HashMap map = new HashMap();
}
public class Thread_1 extends Thread{
private MyService myService;
public Thread_1(MyService myService) {
this.myService = myService;
}
@Override
public void run() {
for (int i = 0; i < 50000; i++) {
myService.map.put("Thread_1 "+(i+1),"Thread_1"+i+1);
System.out.println("Thread_1 "+(i+1));
}
}
}
public class Thread_2 extends Thread{
private MyService myService;
public Thread_2(MyService myService) {
this.myService = myService;
}
@Override
public void run() {
for (int i = 0; i < 50000; i++) {
myService.map.put("Thread_2 "+(i+1),"Thread_2"+i+1);
System.out.println("Thread_2 "+(i+1));
}
}
}
public class Test_2 {
// 多线程操作HashMap
public static void main(String[] args) {
MyService myService = new MyService();
Thread_1 thread_1 = new Thread_1(myService);
Thread_2 thread_2 = new Thread_2(myService);
thread_1.start();
thread_2.start();
}
}
コンストラクタ:
ConcurrentHashMap()
创建一个新的,空的地图与默认的初始表大小(16)
ConcurrentHashMap(int initialCapacity)
创建一个新的空的地图,其初始表格大小适应指定数量的元素,而不需要动态调整大小
ConcurrentHashMap(int initialCapacity, float loadFactor)
根据给定的元素数量( initialCapacity )和初始表密度( loadFactor ),创建一个新的,空的地图,初始的表格大小
ConcurrentHashMap(int initialCapacity, float loadFactor, int concurrencyLevel)
创建具有基于给定数量的元件(初始表大小的新的空映射 initialCapacity ),表密度( loadFactor ),和同时更新线程(数 concurrencyLevel )
ConcurrentHashMap(Map<? extends K,? extends V> m)
创建与给定地图相同的映射的新地图
方法:
void clear()
从这张地图中删除所有的映射
V compute(K key, BiFunction<? super K,? super V,? extends V> remappingFunction)
尝试计算用于指定键和其当前映射的值的映射(或 null如果没有当前映射)
V computeIfAbsent(K key, Function<? super K,? extends V> mappingFunction)
如果指定的键尚未与值相关联,则尝试使用给定的映射函数计算其值,并将其输入到此映射中,除非 null
V computeIfPresent(K key, BiFunction<? super K,? super V,? extends V> remappingFunction)
如果存在指定键的值,则尝试计算给出键的新映射及其当前映射值
boolean contains(Object value)
传统方法测试如果一些键映射到此表中的指定值
boolean containsKey(Object key)
测试此表中的指定对象是否为键
boolean containsValue(Object value)
如果此映射将一个或多个键映射到指定的值,则返回 true
Enumeration<V> elements()
返回此表中值的枚举
Set<Map.Entry<K,V>> entrySet()
返回此地图中包含的映射的Set视图
boolean equals(Object o)
将指定的对象与此映射进行比较以获得相等性
void forEach(BiConsumer<? super K,? super V> action)
对此映射中的每个条目执行给定的操作,直到所有条目都被处理或操作引发异常
void forEach(long parallelismThreshold, BiConsumer<? super K,? super V> action)
对每个(键,值)执行给定的动作
<U> void forEach(long parallelismThreshold, BiFunction<? super K,? super V,? extends U> transformer, Consumer<? super U> action)
对每个(key,value)的每个非空变换执行给定的动作
void forEachEntry(long parallelismThreshold, Consumer<? super Map.Entry<K,V>> action)
对每个条目执行给定的操作
<U> void forEachEntry(long parallelismThreshold, Function<Map.Entry<K,V>,? extends U> transformer, Consumer<? super U> action)
对每个条目的每个非空变换执行给定的操作
void forEachKey(long parallelismThreshold, Consumer<? super K> action)
对每个键执行给定的动作
<U> void forEachKey(long parallelismThreshold, Function<? super K,? extends U> transformer, Consumer<? super U> action)
对每个键的每个非空变换执行给定的动作
void forEachValue(long parallelismThreshold, Consumer<? super V> action)
对每个值执行给定的操作
<U> void forEachValue(long parallelismThreshold, Function<? super V,? extends U> transformer, Consumer<? super U> action)
对每个值的每个非空转换执行给定的动作
V get(Object key)
返回到指定键所映射的值,或 null如果此映射包含该键的映射
V getOrDefault(Object key, V defaultValue)
返回指定键映射到的值,如果此映射不包含该键的映射,则返回给定的默认值
int hashCode()
返回此Map的哈希代码值,即映射中每个键值对的总和,即key.hashCode() ^ value.hashCode()
boolean isEmpty()
如果此地图不包含键值映射,则返回 true
Enumeration<K> keys()
返回此表中键的枚举
ConcurrentHashMap.KeySetView<K,V> keySet()
返回此地图中包含的键的Set视图
ConcurrentHashMap.KeySetView<K,V> keySet(V mappedValue)
返回此地图中键的Set视图,使用给定的公用映射值进行任何添加(即Collection.add(E)和Collection.addAll(Collection) )
long mappingCount()
返回映射数
V merge(K key, V value, BiFunction<? super V,? super V,? extends V> remappingFunction)
如果指定的键尚未与(非空)值相关联,则将其与给定值相关联
static <K> ConcurrentHashMap.KeySetView<K,Boolean> newKeySet()
创建一个新的Set支持的ConcurrentHashMap从给定的类型到Boolean.TRUE
static <K> ConcurrentHashMap.KeySetView<K,Boolean> newKeySet(int initialCapacity)
创建一个新的Set支持的ConcurrentHashMap从给定的类型到Boolean.TRUE
V put(K key, V value)
将指定的键映射到此表中的指定值
void putAll(Map<? extends K,? extends V> m)
将指定地图的所有映射复制到此映射
V putIfAbsent(K key, V value)
如果指定的键尚未与值相关联,请将其与给定值相关联
<U> U reduce(long parallelismThreshold, BiFunction<? super K,? super V,? extends U> transformer, BiFunction<? super U,? super U,? extends U> reducer)
返回使用给定的reducer将所有(key,value)对的给定变换累加到组合值的结果,如果没有则返回null
Map.Entry<K,V> reduceEntries(long parallelismThreshold, BiFunction<Map.Entry<K,V>,Map.Entry<K,V>,? extends Map.Entry<K,V>> reducer)
返回使用给定的reducer累加所有条目的结果,以组合值,如果没有则返回null
<U> U reduceEntries(long parallelismThreshold, Function<Map.Entry<K,V>,? extends U> transformer, BiFunction<? super U,? super U,? extends U> reducer)
返回使用给定的reducer将所有条目的给定变换累加到组合值的结果,否则返回null
double reduceEntriesToDouble(long parallelismThreshold, ToDoubleFunction<Map.Entry<K,V>> transformer, double basis, DoubleBinaryOperator reducer)
返回使用给定的reducer累加给定变换的结果,以组合值,给定基础作为一个标识值
int reduceEntriesToInt(long parallelismThreshold, ToIntFunction<Map.Entry<K,V>> transformer, int basis, IntBinaryOperator reducer)
返回使用给定的reducer累加给定变换的结果,以组合值,给定基础作为一个标识值
long reduceEntriesToLong(long parallelismThreshold, ToLongFunction<Map.Entry<K,V>> transformer, long basis, LongBinaryOperator reducer)
返回使用给定的reducer累加给定变换的结果,以组合值,给定基础作为一个标识值
K reduceKeys(long parallelismThreshold, BiFunction<? super K,? super K,? extends K> reducer)
返回使用给定的reducer累加所有键的结果,以组合值,如果没有则返回null
<U> U reduceKeys(long parallelismThreshold, Function<? super K,? extends U> transformer, BiFunction<? super U,? super U,? extends U> reducer)
返回使用给定的reducer累加所有键的给定变换以组合值的结果,如果没有则返回null
double reduceKeysToDouble(long parallelismThreshold, ToDoubleFunction<? super K> transformer, double basis, DoubleBinaryOperator reducer)
返回使用给定的reducer累加所有键的给定变换的结果,以组合值,给定基础作为标识值
int reduceKeysToInt(long parallelismThreshold, ToIntFunction<? super K> transformer, int basis, IntBinaryOperator reducer)
返回使用给定的reducer累加所有键的给定变换的结果,以组合值,给定基础作为标识值
long reduceKeysToLong(long parallelismThreshold, ToLongFunction<? super K> transformer, long basis, LongBinaryOperator reducer)
返回使用给定的reducer累加所有键的给定变换的结果,以组合值,给定基础作为标识值
double reduceToDouble(long parallelismThreshold, ToDoubleBiFunction<? super K,? super V> transformer, double basis, DoubleBinaryOperator reducer)
返回使用给定的reducer将所有(key,value)对的给定变换累加到结合值的结果,给定的基数作为一个标识值
int reduceToInt(long parallelismThreshold, ToIntBiFunction<? super K,? super V> transformer, int basis, IntBinaryOperator reducer)
返回使用给定的reducer将所有(key,value)对的给定变换累加到结合值的结果,给定的基数作为一个标识值
long reduceToLong(long parallelismThreshold, ToLongBiFunction<? super K,? super V> transformer, long basis, LongBinaryOperator reducer)
返回使用给定的reducer将所有(key,value)对的给定变换累加到结合值的结果,给定的基数作为一个标识值
V reduceValues(long parallelismThreshold, BiFunction<? super V,? super V,? extends V> reducer)
返回使用给定的reducer累加所有值的结果,以组合值,如果没有则返回null
<U> U reduceValues(long parallelismThreshold, Function<? super V,? extends U> transformer, BiFunction<? super U,? super U,? extends U> reducer)
返回使用给定的reducer累加所有值的给定变换以组合值的结果,否则返回null
double reduceValuesToDouble(long parallelismThreshold, ToDoubleFunction<? super V> transformer, double basis, DoubleBinaryOperator reducer)
返回使用给定的reducer累加所有值的给定变换的结果,以组合值,给定基础作为标识值
int reduceValuesToInt(long parallelismThreshold, ToIntFunction<? super V> transformer, int basis, IntBinaryOperator reducer)
返回使用给定的reducer累加所有值的给定变换的结果,以组合值,给定基础作为标识值
long reduceValuesToLong(long parallelismThreshold, ToLongFunction<? super V> transformer, long basis, LongBinaryOperator reducer)
返回使用给定的reducer累加所有值的给定变换的结果,以组合值,给定基础作为标识值
V remove(Object key)
从该地图中删除键(及其对应的值)
boolean remove(Object key, Object value)
仅当当前映射到给定值时才删除密钥的条目
V replace(K key, V value)
仅当当前映射到某个值时才替换该项的条目
boolean replace(K key, V oldValue, V newValue)
仅当当前映射到给定值时才替换密钥的条目
void replaceAll(BiFunction<? super K,? super V,? extends V> function)
将每个条目的值替换为对该条目调用给定函数的结果,直到所有条目都被处理或该函数抛出异常
<U> U search(long parallelismThreshold, BiFunction<? super K,? super V,? extends U> searchFunction)
通过在每个(键,值)上应用给定的搜索函数返回非空结果,如果没有则返回null
<U> U searchEntries(long parallelismThreshold, Function<Map.Entry<K,V>,? extends U> searchFunction)
返回一个非空结果,从每个条目应用给定的搜索函数,如果没有,则返回null
<U> U searchKeys(long parallelismThreshold, Function<? super K,? extends U> searchFunction)
返回一个非空结果,在每个键上应用给定的搜索功能,如果没有,返回null
<U> U searchValues(long parallelismThreshold, Function<? super V,? extends U> searchFunction)
返回一个非空结果,对每个值应用给定的搜索函数,如果没有,返回null
int size()
返回此地图中键值映射的数量
String toString()
返回此地图的字符串表示形式
Collection<V> values()
返回此地图中包含的值的Collection视图
Java8 ConcurrentHashMapの構造
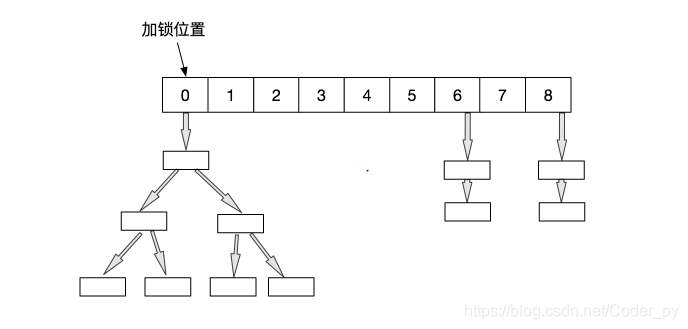
回路図:
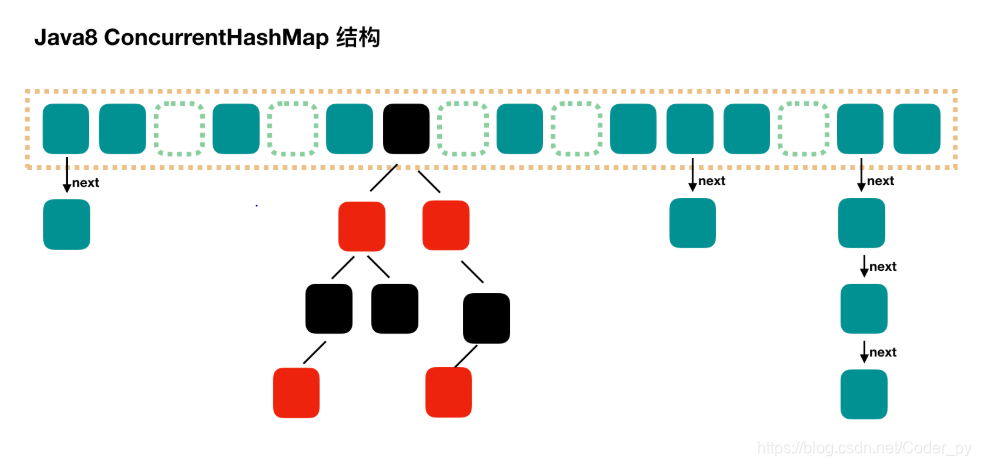
java8では、ときに、リスト満たす特定の条件におけるノードの数は、リストは、赤黒木、検索最大速度となるであろう。
プロパティ
// table为Node数组,加锁时锁住的就是table下标内的node
// 大小始终为2的整数次幂
transient volatile Node<K,V>[] table;
// 只有在扩容时才用得到,用于存储扩容后的数据,因此只有在扩容时nextTable才非空
private transient volatile Node<K,V>[] nextTable;
// baseCount为存储的总node数
private transient volatile long baseCount;
// 控制标识符,不同的值表示不同的意义,默认值为0:
// -1代表数组正在进行初始化
// -N代表有N-1个线程正在进行扩容操作????
// 正数代表下一次需要进行扩容时的阈值,也就是当前容量的0.75(负载因子)倍
private transient volatile int sizeCtl;
// transferIndex不扩容时为0,扩容时代表扩容的边界,扩容从数组最后一个下标倒序开始,transferIndex被赋值为数组长度,根据步长stride(根据核数计算出的,最小值为16)将扩容工作分段,将transferIndex更新transferIndex-stride,假设n为32,stride为16,则扩容任务分为下32-16、16-0两块,可由其他事物线程帮助完成
private transient volatile int transferIndex;
//数组最大大小
private static final int MAXIMUM_CAPACITY = 1 << 30;
//数组默认大小
private static final int DEFAULT_CAPACITY = 16;
/**
* The largest possible (non-power of two) array size.
* Needed by toArray and related methods.
*/
static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
//默认map扩容比例,实际用(n << 1) - (n >>> 1)代替了更高效
private static final float LOAD_FACTOR = 0.75f;
// 链表转树阀值,大于8时
static final int TREEIFY_THRESHOLD = 8;
//树转链表阀值,小于等于6
static final int UNTREEIFY_THRESHOLD = 6;
コンストラクタ
/**
* Creates a new, empty map with the default initial table size (16).
*/
public ConcurrentHashMap() {
}
// 将sizeCtl设置为大于容量的最小的2^n ,并不会初始化table
public ConcurrentHashMap(int initialCapacity) {
if (initialCapacity < 0)
throw new IllegalArgumentException();
int cap = ((initialCapacity >= (MAXIMUM_CAPACITY >>> 1)) ?
MAXIMUM_CAPACITY :
tableSizeFor(initialCapacity + (initialCapacity >>> 1) + 1));
this.sizeCtl = cap;
}
// 返回大于输入参数且最近的2的整数次幂的数。比如10,则返回16
private static final int tableSizeFor(int c) {
int n = c - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
鍵方式
public V put(K key, V value) {
return putVal(key, value, false);
}
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
// 得到 hash 值
int hash = spread(key.hashCode());
// 用于记录相应链表的长度
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
// 如果数组"空",进行数组初始化
if (tab == null || (n = tab.length) == 0)
// 初始化数组,后面会详细介绍
tab = initTable();
// 找该 hash 值对应的数组下标,得到第一个节点 f
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
// 如果数组该位置为空,
// 用一次 CAS 操作将这个新值放入其中即可,这个 put 操作差不多就结束了,可以拉到最后面了
// 如果 CAS 失败,那就是有并发操作,进到下一个循环就好了
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
else if ((fh = f.hash) == MOVED)
// 帮助数据迁移
tab = helpTransfer(tab, f);
else { // 到这里就是说,f 是该位置的头结点,而且不为空
V oldVal = null;
// 获取数组该位置的头结点的监视器锁
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) { // 头结点的 hash 值大于 0,说明是链表
// 用于累加,记录链表的长度
binCount = 1;
// 遍历链表
for (Node<K,V> e = f;; ++binCount) {
K ek;
// 如果发现了"相等"的 key,判断是否要进行值覆盖,然后也就可以 break 了
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
// 到了链表的最末端,将这个新值放到链表的最后面
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
else if (f instanceof TreeBin) { // 红黑树
Node<K,V> p;
binCount = 2;
// 调用红黑树的插值方法插入新节点
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
// binCount != 0 说明上面在做链表操作
if (binCount != 0) {
// 判断是否要将链表转换为红黑树,临界值和 HashMap 一样,也是 8
if (binCount >= TREEIFY_THRESHOLD)
// 这个方法和 HashMap 中稍微有一点点不同,那就是它不是一定会进行红黑树转换,
// 如果当前数组的长度小于 64,那么会选择进行数组扩容,而不是转换为红黑树
// 具体源码我们就不看了,扩容部分后面说
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
//
addCount(1L, binCount);
return null;
}
適切なサイズの配列を初期化し、その後sizeCtlがセット
private final Node<K,V>[] initTable() {
Node<K,V>[] tab; int sc;
while ((tab = table) == null || tab.length == 0) {
// 初始化的"功劳"被其他线程"抢去"了
if ((sc = sizeCtl) < 0)
Thread.yield(); // lost initialization race; just spin
// CAS 一下,将 sizeCtl 设置为 -1,代表抢到了锁
else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
try {
if ((tab = table) == null || tab.length == 0) {
// DEFAULT_CAPACITY 默认初始容量是 16
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
// 初始化数组,长度为 16 或初始化时提供的长度
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
// 将这个数组赋值给 table,table 是 volatile 的
table = tab = nt;
// 如果 n 为 16 的话,那么这里 sc = 12
// 其实就是 0.75 * n
sc = n - (n >>> 2);
}
} finally {
// 设置 sizeCtl 为 sc,我们就当是 12 吧
sizeCtl = sc;
}
break;
}
}
return tab;
}
treeifyBin方法(リスト赤黒木法となります)
private final void treeifyBin(Node<K,V>[] tab, int index) {
Node<K,V> b; int n, sc;
if (tab != null) {
//如果数组长度<64(即链表长度>=8但数组长度<64),不变为红黑树而是扩容
if ((n = tab.length) < MIN_TREEIFY_CAPACITY)
tryPresize(n << 1);
//如果数组长度>=64并且该下标有数据并且为链表
else if ((b = tabAt(tab, index)) != null && b.hash >= 0) {
//锁住该下标第一个node
synchronized (b) {
//变为红黑树
if (tabAt(tab, index) == b) {
TreeNode<K,V> hd = null, tl = null;
for (Node<K,V> e = b; e != null; e = e.next) {
TreeNode<K,V> p =
new TreeNode<K,V>(e.hash, e.key, e.val,
null, null);
if ((p.prev = tl) == null)
hd = p;
else
tl.next = p;
tl = p;
}
setTabAt(tab, index, new TreeBin<K,V>(hd));
}
}
}
}
}
データ移行:移行:新しい配列に元のタブ素子アレイの移行nextTab
private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) {
int n = tab.length, stride;
//根据cpu核数计算出步长,用于分割扩容任务,方便其余线程帮助扩容,最小为16
if ((stride = (NCPU > 1) ? (n >>> 3) / NCPU : n) < MIN_TRANSFER_STRIDE)
stride = MIN_TRANSFER_STRIDE;
//判断nextTab是否为空,nextTab是暂时存储扩容后的node的数组,第一次进入这个方法的线程才会发现nextTab为空
//前文提到的helpTransfer也会调用该方法,当helpTransfer调用该方法时nextTab不为空
if (nextTab == null) {
try {
@SuppressWarnings("unchecked")
//初始化nextTab为table长度的2倍
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n << 1];
nextTab = nt;
} catch (Throwable ex) {
//如果发生了异常,则将sizeCtl设为integer的最大值,因为前文提过数组长度大于1<<30时就不能再扩容了
sizeCtl = Integer.MAX_VALUE;
return;
}
nextTable = nextTab;
//将transferIndex赋值为原数组table的长度
transferIndex = n;
}
int nextn = nextTab.length;
ForwardingNode<K,V> fwd = new ForwardingNode<K,V>(nextTab);
boolean advance = true;
boolean finishing = false;
//这个for循环就是用来扩容最主要的方法了
for (int i = 0, bound = 0;;) {
Node<K,V> f; int fh;
//该while循环的作用有两点 1.将扩容任务根据步长分块 2.确定本次循环要rehash的下标节点(rehash与扩容意义相同)
while (advance) {
int nextIndex, nextBound;
//i为要进行rehash的下标,bound为分块任务的边界,finishing代表扩容完毕
//每个线程在第一次进行该if判断时,bound和i都为0,finishing为false,不进第一个if
//在第一个else if时将transferIndex赋值给nextIndex,不进第一个else if
//在第二个else if,将transferIndex更新为nextIndex-stride
//假设nextIndex为32,stride为16。代表数组长度32,有32个下标要倒序依次rehash,则任务分为两块(32-16,16-0)
//第一个线程会处理32-16的任务。
//第二个线程来的时候发现transferIndex为16,根据步长他会处理16-0的任务
//如果没有其余的线程帮助扩容,则第一个线程会再完成第一块任务后,再获取下一块任务直至都rehash完
if (--i >= bound || finishing)
advance = false;
else if ((nextIndex = transferIndex) <= 0) {
i = -1;
advance = false;
}
else if (U.compareAndSwapInt
(this, TRANSFERINDEX, nextIndex,
nextBound = (nextIndex > stride ?
nextIndex - stride : 0))) {
bound = nextBound;
i = nextIndex - 1;
advance = false;
}
}
//在rehash任务都处理完之前不会进入该if判断,该if方法会进入两次
if (i < 0 || i >= n || i + n >= nextn) {
int sc;
//第一次进入的时候finishing为false
//第二次进入的时候finishing为true,代表扩容已经结束,将新的nextTab赋值给table,并将sizeCtl设置为table长度的0.75倍
if (finishing) {
nextTable = null;
table = nextTab;
sizeCtl = (n << 1) - (n >>> 1);
return;
}
//第一次进入的时候,会将finishing设置为true,并将i重新赋值为原table大小
//假如n=32,则会将最外面的for循环再循环32遍检查各个下标作为是否都已经扩容过了
if (U.compareAndSwapInt(this, SIZECTL, sc = sizeCtl, sc - 1)) {
if ((sc - 2) != resizeStamp(n) << RESIZE_STAMP_SHIFT)
return;
finishing = advance = true;
i = n;
}
}
//如果该下标内没有数据,则将该下标内放入ForwardingNode,代表该下标rehash结束
else if ((f = tabAt(tab, i)) == null)
advance = casTabAt(tab, i, null, fwd);
//如果该下标的hash值为-1(即ForwardingNode的hash值),代表已经rehash结束,继续下一次循环
else if ((fh = f.hash) == MOVED)
advance = true;
else {
//真正的扩容,锁住该下标的第一个node
synchronized (f) {
//再次判断该node有没有变
if (tabAt(tab, i) == f) {
Node<K,V> ln, hn;
//如果该node的hash值>=0, 代表该下标内是链表
if (fh >= 0) {
int runBit = fh & n;
Node<K,V> lastRun = f;
for (Node<K,V> p = f.next; p != null; p = p.next) {
int b = p.hash & n;
if (b != runBit) {
runBit = b;
lastRun = p;
}
}
if (runBit == 0) {
ln = lastRun;
hn = null;
}
else {
hn = lastRun;
ln = null;
}
//遍历链表,将链表内的node重新分配到新nextTab的i位置和i+n位置
//原始的链表会倒序分到两个下标内,越靠后的node在新的map的链表里越靠前
for (Node<K,V> p = f; p != lastRun; p = p.next) {
int ph = p.hash; K pk = p.key; V pv = p.val;
if ((ph & n) == 0)
ln = new Node<K,V>(ph, pk, pv, ln);
else
hn = new Node<K,V>(ph, pk, pv, hn);
}
//更新新的nextTab,并将原table的该下标位置放入ForwardingNode
setTabAt(nextTab, i, ln);
setTabAt(nextTab, i + n, hn);
setTabAt(tab, i, fwd);
advance = true;
}
//该下标内是红黑树
else if (f instanceof TreeBin) {
TreeBin<K,V> t = (ConcurrentHashMap.TreeBin<K,V>)f;
TreeNode<K,V> lo = null, loTail = null;
TreeNode<K,V> hi = null, hiTail = null;
int lc = 0, hc = 0;
//将原树rehash到两个新树里
for (Node<K,V> e = t.first; e != null; e = e.next) {
int h = e.hash;
TreeNode<K,V> p = new TreeNode<K,V>
(h, e.key, e.val, null, null);
if ((h & n) == 0) {
if ((p.prev = loTail) == null)
lo = p;
else
loTail.next = p;
loTail = p;
++lc;
}
else {
if ((p.prev = hiTail) == null)
hi = p;
else
hiTail.next = p;
hiTail = p;
++hc;
}
}
//如果树的node数量<=6,则将红黑树变为链表
ln = (lc <= UNTREEIFY_THRESHOLD) ? untreeify(lo) :
(hc != 0) ? new TreeBin<K,V>(lo) : t;
hn = (hc <= UNTREEIFY_THRESHOLD) ? untreeify(hi) :
(lc != 0) ? new TreeBin<K,V>(hi) : t;
//将新树或链表放到新的table对应的下标里
//并将原table的该下标位置放入ForwardingNode
setTabAt(nextTab, i, ln);
setTabAt(nextTab, i + n, hn);
setTabAt(tab, i, fwd);
advance = true;
}
}
}
}
}
}
参考記事
https://blog.csdn.net/ddxd0406/article/details/81389583
https://blog.csdn.net/sihai12345/article/details/79383766
