計算フレームワークを統一流バッチとしてFLINK、1.10に関連する機能強化および改善の大きなバッチの完了。1.10は、機能・性能の大幅な改善があり、それはデータセット弱いの前に押し流され、最初の成熟生産FLINKバッチSQLのバージョンが利用可能であると言うことができる、私は三つの側面が手の込んだアーキテクチャ、外部システム、練習から次を統合しました。
アーキテクチャ
スタック

スタックではまず見て、私たちとDataSetに絶対に何も意味しないも変容に設定したバッチ、内の新しいブリンクプランナー、:
- 我々は可能な限り再利用可能なコンポーネントをストリーミング、コードの再利用など、行動の同じセットを持つことができます。
- あなたは表/ SQLはTODATASETまたはFROMDATASETある場合は、まったく問題外だろう。可能な限り、表レベルでそれに対処します。
- 私たちは、バッチ機能をもたらすためにでDataStream、でDataStream上BoundedStreamのフォローアップを構築検討しています。
ネットワークモデル
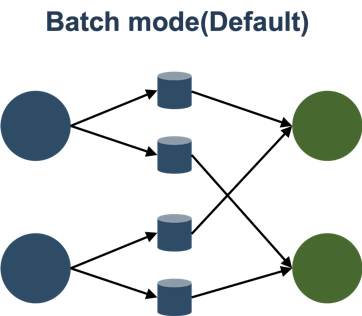
バッチモードでは、中間結果、ディスクから外れて、このパターンの典型的なバッチ処理は、MapReduceの/スパーク/ TEZように、同じです。
また、バッチおよびパイプラインに分かれFLINK以前のネットワークモデルは2ですが、バッチモードは、唯一の共通の同時上流と下流を満たすことができない資源の量である下流のパーティションの実行、サポートされています。しかし、良いお尻ではありませんフェールオーバ別のキーポイントは、1.9と1.10は、フェイルオーバーの単一のポイントをサポートし、この点で改善されました。
ときバッチ開くことをお勧めします:
jobmanager.execution.failover戦略=地域
忙しすぎJobMaster再起動頻繁な原因を避けるために、あなたは、再起動間隔を向上させることができます。
再起動-strategy.fixed-delay.delay = 30秒
メリットのバッチモードは以下のとおりです。
- トレラントフォールト、および回復のシングルポイントすることができ
- スケジューリング良い、実行することができますどのように多くのリソースに関係なく
- 性能差,中间数据需要落盘,强烈建议开启压缩
taskmanager.network.blocking-shuffle.compression.enabled = true
Batch模式比较稳,适合传统Batch作业,大作业。

Pipeline模式是Flink的传统模式,它完全和Streaming作业用的是同一套代码,其实社区里Impala和Presto也是类似的模式,纯走网络,需要处理反压,不落盘,它主要的优缺点是:
- 容错差,只能全局重来
- 调度差,你得保证有足够的资源
- 性能好,Pipeline执行,完全复用Stream,复用流控反压等功能。
有条件可以考虑开启Pipeline模式。
调度模型
Flink on Yarn支持两种模式,Session模式和Per job模式,现在已经在调度层次高度统一了。
- Session模式没有最大进程限制,当有Job需要资源时,它就会去Yarn申请新资源,当Session有空闲资源时,它就会给Job复用,所以它的模型和PerJob是基本一样的。
- 唯一的不同只是:Session模式可以跨作业复用进程。
另外,如果想要更好的复用进程,可以考虑加大TaskManager的超时释放:
resourcemanager.taskmanager-timeout = 900000
资源模型
先说说并发:
- 对Source来说:目前Hive的table是根据InputSplit来定需要多少并发的,它之后能Chain起来的Operators自然都是和source相同的并发。
- 对下游网络传输过后的Operators(Tasks)来说:除了一定需要单并发的Task来说,其它Task全部统一并发,由table.exec.resource.default-parallelism统一控制。
我们在Blink内部实现了基于统计信息来推断并发的功能,但是其实以上的策略在大部分场景就够用了。
Manage内存
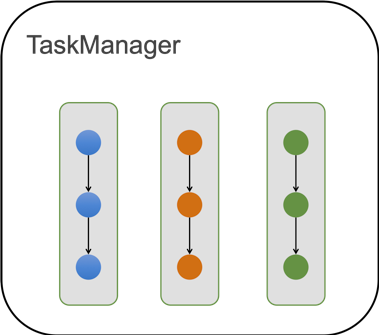
目前一个TaskManager里面含有多个Slot,在Batch作业中,一个Slot里只能运行一个Task (关闭SlotShare)。
对内存来说,单个TM会把Manage内存切分成Slot粒度,如果1个TM中有n个Slot,也就是Task能拿到1/n的manage内存。
我们在1.10做了重大的一个改进就是:Task中chain起来的各个operators按照比例来瓜分内存,所以现在配置的算子内存都是一个比例值,实际拿到的还要根据Slot的内存来瓜分。
这样做的一个重要好处是:
- 不管当前Slot有多少内存,作业能都run起来,这大大提高了开箱即用。
- 不管当前Slot有多少内存,Operators都会把内存瓜分干净,不会存在浪费的可能。
当然,为了运行的效率,我们一般建议单个Slot的manage内存应该大于500MB。
另一个事情,在1.10后,我们去除了OnHeap的manage内存,所以只有off-heap的manage内存。
外部系统集成
Hive
强烈推荐Hive Catalog + Hive,这也是目前批处理最成熟的架构。在1.10中,除了对以前功能的完善以外,其它做了几件事:
- 多版本支持,支持Hive 1.X 2.X 3.X
- 完善了分区的支持,包括分区读,动态/静态分区写,分区统计信息的支持。
- 集成Hive内置函数,可以通过以下方式来load:
a)TableEnvironment.loadModule("hiveModule",new HiveModule("hiveVersion")) - 优化了ORC的性能读,使用向量化的读取方式,但是目前只支持Hive 2+版本,且要求列没有复杂类型。有没有进行过优化差距在5倍量级。
兼容Streaming Connectors
得益于流批统一的架构,目前的流Connectors也能在batch上使用,比如HBase的Lookup和Sink、JDBC的Lookup和Sink、Elasticsearch的Sink,都可以在Batch无缝对接使用起来。
实践
SQL-CLI
在1.10中,SQL-CLI也做了大量的改动,比如把SQL-CLI做了stateful,里面也支持了DDL,还支持了大量的DDL命令,给SQL-CLI暴露了很多TableEnvironment的能力,这让用户可以方便得多。后续,我们也需要对接JDBC的客户端,让用户可以更好的对接外部工具。但是SQL-CLI仍然待继续改进,比如目前仍然只支持Session模式,不支持Per Job模式。
编程方式

老的BatchTableEnv因为绑定了Dataset,而且区分Java和Scala,是不干净的设计方式,所以Blink planner只支持新的TableEnv。
TableEnv注册的source, sink, connector, functions,都是temporary的,重启之后即失效了。如果需要持久化的object,考虑使用HiveCatalog。

可以通过tEnv.sqlQuery来执行DML,这样可以获得一个Table,我们也通过collect来获得小量的数据:

可以通过tEnv.sqlUpdate来执行DDL,但是目前并不支持创建hive的table,只能创建Flink类型的table:

可以通过tEnv.sqlUpdate来执行insert语句,Insert到临时表或者Catalog表中,比如insert到上面创建的临时JDBC表中:

当结果表是Hive表时,可以使用Overwrite语法,也可以使用静态Partition的语法,这需要打开Hive的方言:

结语
目前Flink batch SQL仍然在高速发展中,但是1.10已经是一个可用的版本了,它在功能上、性能上都有很大的提升,后续还有很多有意思的features,等待着大家一起去挖掘。
本文作者:李劲松(之信)
本文为阿里云内容,未经允许不得转载。