ビッグデータ技術のI.背景
1.コンピュータと情報技術(特に、モバイルインターネット)急速な発展と普及は、アプリケーションシステムは、急速に拡大生成、工業用途(等のFacebook、淘宝、マイクロチャネル、CUP、12306などのユーザおよびアプリケーションシナリオ、数)データは示した爆発的な成長を。
2. PBは簡単に数百あるいはEB(1EB = 1024PB = 1024×達する 1024TB) サイズのデータの遠されている伝統的な超えコンピュータや情報システムの処理能力を。
3.効果的な大規模なデータ処理技術、手法やツールとなっている緊急の需要。
Googleのトロイカは、大規模データの開発のための敷設が非常に重要であるベース。
Googleのトロイカ(非常に重要):3本の論文--->アイデア、原則
1、GFS:Googleのファイルシステム--- > HDFS:Hadoopの分散ファイルシステムは、
ビッグデータを解決するための分散ファイルシステムでありますストレージの問題。
転置インデックスとは何ですか?差し戻しインデックス
転置インデックス:
あなたは、テーブル全体をスキャンし、多くの時間を検索するには、「ビッグデータ」は、前方にのみインデックスならば、それはキーワードを取ることにしたい場合は、レコードキーワード「ビッグデータ」、遅いこのプロセスの場合のデータの膨大な量人々が行われていません、
だから、転置インデックスと、検索エンジンが前方にインデックスを再構築するファイルのIDマッピングのキーワードに該当する転置インデックスは、各キーワードのキーワードマッピングファイルIDに変換された一連の対応このキーワードを浮上している文書、。
人気は言いました:
データを通じて、アドレスを探して
2、MapReduceの計算モデル:問題の原因のPageRank(第1の小コンピューティングタスクを複数に分割し、次いで凝集)
3、BigTableの大きなテーブル---->のNoSQLデータベース:HBaseの(時間と引き換えに犠牲空間)
II。ビッグデータのシナリオ
Baiduの人口移動春祭り、中国の旧正月2014は、Baiduは「Baiduの移行」、ビッグデータ技術の使用、独自の計算解析LBS(位置情報サービス)ビッグデータ、および革新的な「視覚的」プレゼンテーションの使用を開始しました、完全な、動的な、リアルタイムを実現する業界初のは、視覚的に図1-3に示す旧正月大規模な人口移動、前と後の軌道と特性を示します。(クエリURL:HTTP :. //Qianxi.baidu.com/)

分散ファイルシステム(GFS、HDFSなど):データ記憶されているが、(1)
分散コンピューティングモデル(MapReduceは、RDDスパークなど)、(2)データを算出する
算出オフライン:二方向にHadoopのMapReduceの、コアスパーク、 FLINK DataSetの
リアルタイム計算:嵐、スパークストリーミング、FLINKでDataStream
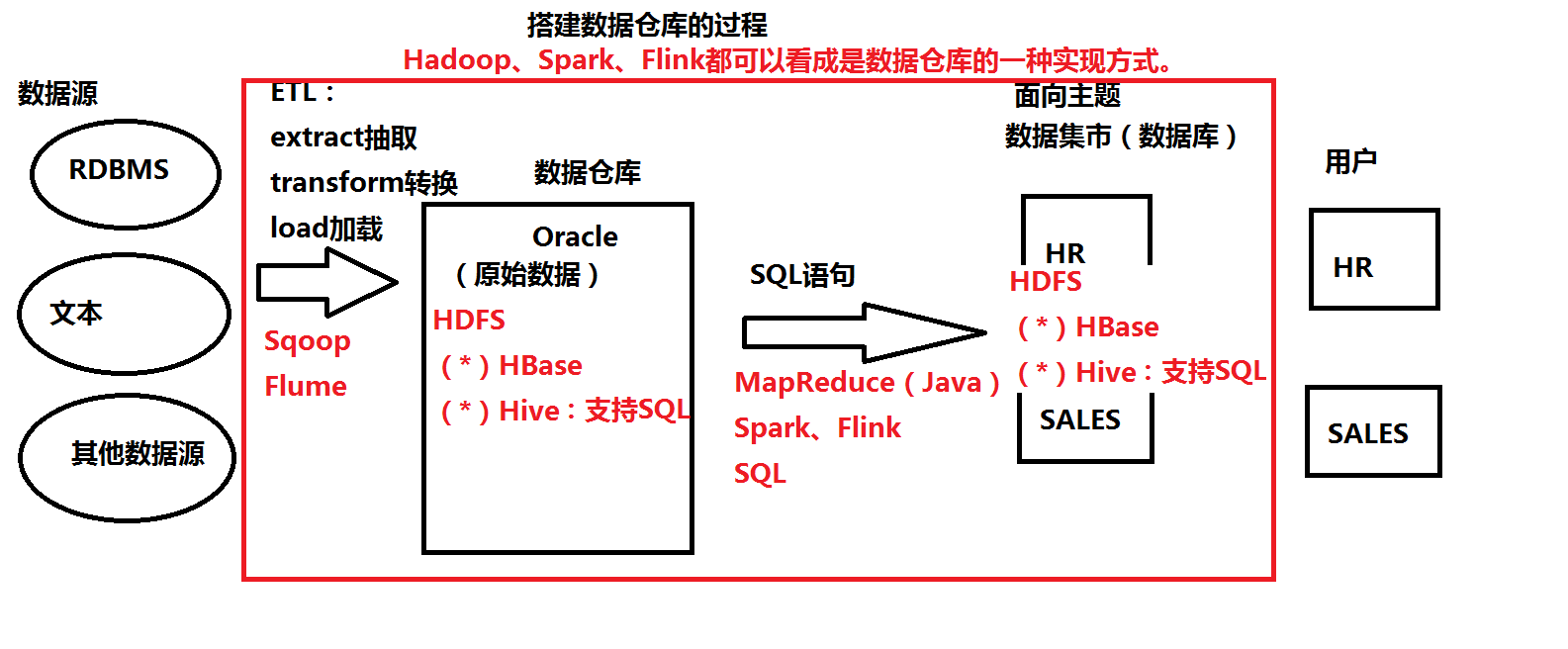
IV。データウェアハウス
従来のデータウェアハウス:オラクル、MySQLの、など
ビッグデータ:Hadoopの、スパーク、FLINKは、データウェアハウスの実装として見ることができます
概念:OLTP与OLAP
数据仓库又是一种OLAP的系统
OLTP:online transaction processing 联机事务处理
insert update delete commit rollback
特点:ACID 原子性、一致性、持久性、隔离性 -----> 关系型数据库
OLAP:online analytic processing 联机分析处理
一般:select
不关心事务
五.Hadoop生态圈的体系机构(Apache 简单版)
