分析の最初に、目的
ジョブのデータ分析動員および成長見通しを理解します。
第二に、分析寸法
分析目的によると、主に以下の分析では、3次元を提示します:
1、仕事の地理的分布
主地域グループ、各領域内のジョブの数の分布を分析しました。
2、賃金
最小の給料は最低賃金の全体的な分布の分析、モニタリングにより記載されています。
3、必要な実務経験
グループワークの経験を通じて、仕事の需要はいくつかのセグメント、サービスの長さと賃金への影響は彼らの将来のキャリアプランニングを支援するために分析された年数で主に観察されました。
4、スキル要件
業界への主要なアクセスが必要なスキルを理解する必要があります。
5、学術的な要件
位置に学歴の最小要件を理解します。
6、会社の利益
ほとんどの企業は、共通はいの主要なメリットの分析を与えます。
第三に、分析ツール
ここでは主に私は、Pythonに精通しになりたいので、メインパンダパイソンバッグの使用、およびmatplotlibの。
第四に、データクレンジング
図1に示すように、データセットが記載されています
データセット名:プルフック募集ネットワークデータ解析
データセット出典:プルフックネットワークデータ解析ジョブデータを通じてクロールタコ(Pythonの爬虫類のためには精通していません)
データセットの量:9 431 *
2、列を追加
2.1、最も高い賃金(high_salary)カラム及び最低賃金(low_salary)カラムを追加します。
最低賃金を分析する必要があるため、テーブル内のデータが範囲(図A)によって与えられる、最高解像度の範囲の給与(high_salary)及び最低賃金(low_salary)(図B)を払う必要があります。
2.2場所(場所)列を追加
表領域のデータが各領域(図A)の詳細によって与えられ、私はそれを除去するエリア情報の詳細する必要があり、全体の領域を分析する必要があり、位置列(図のB)を加えました。

図A

図B
カラム内の余分な文字の生活作業」を3、工程
経験「(パネルA「)で働いて生活」を除去する(図B)。
4、欠損値を扱います
欠損値をチェックした後は表示されません。
図5に示すように、プロセスの重複
繰り返し記録が表示されません。
第五に、データ解析
1、分析のための位置の地域分布:

杭州、広州、深センに続いて、データ分析の仕事の需要北京、上海、および領域上の特別な要件場合、北京や上海、開発の他のエリアに移動することをお勧めします。これは、上記の分析から見ることができます。
2、賃金の分析
データへのアクセスは最大賃金の最小間隔であるので、唯一の最低賃金に関する記事を分析した通りであり;
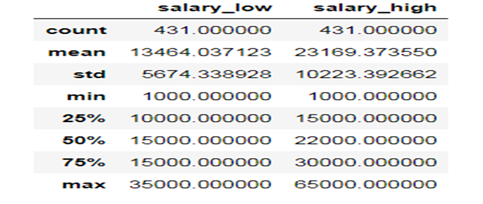
専門職の給与の状況は依然として非常に実質的であるように、あなたは、最も高い給与が65,000で、最低賃金は1000(インターン)で、テーブルから13K-22Kの平均賃金を見ることができます。
3、必要な実務経験
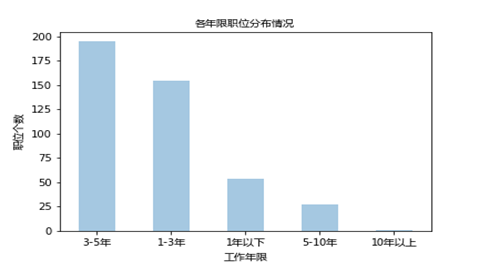
これは、分析を通して見ることができます:投稿のための会社の仕事の経験の要件を主に1--5年、3 - 需要の5歳まで、一年未満の実務経験要件のため、実務経験の1--3年に続きます5年間の需要よりも少しは基本的には減少傾向を示しており、基本的には実務経験10年以上で、従業員は必要ありません。仕事上の経験を積む、自分のキャリアの計画に参加するために必要としています。
また、によりデータの取得作業の年数と給与の変化の分析は、これだけ最低賃金を分析し、最大賃金の最小の範囲であり、次のように:
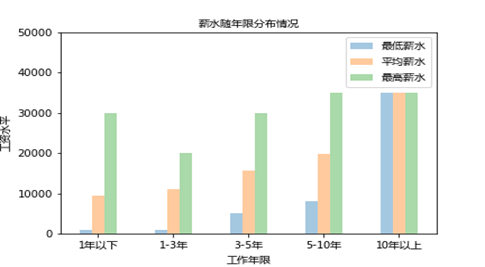
これは、ことを示している:10年で、いずれかの賃金の増加に伴って賃金最低賃金、最大賃金またはビューの平均賃金、から上昇している一方で、ワークの年数、および大きさが大幅に増加;見、作業経験が計画を行うには、そのため、重要であり、少なくとも10年以内に、経験を蓄積するための努力は、リターンは非常に印象的です。
4、スキル要件
ワードアートは、ワープロを使用して行う以下のように、単語の雲が発生しました:

業界を入力するには、ワードクラウドからわかるように、主に共通して、スキルを学ぶためにたくさん持っている統計情報を持っている必要があり、エクセル、パイソン/ Rは、MySQL(SQL)及びその他の知識は、当然のことながら、これらは単なるツールで、最も重要であり、それは考えていると、データ分析と組み合わせたビジネス知識は、これらの仕事に訓練を継続する必要があります。
5、学術的な要件
この部分は資格がこの位置には、次のチャートでより人気があるかを分析したいと思います。
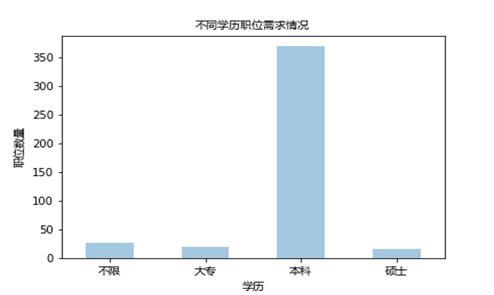
もちろん、ほとんどの企業が大学の学位を必要とし、教育を受けた大学は、小型、唯一のマップビューを要求するために限定されるものではないが、一部の企業は、高い学位を必要と残っています、それを見ることができ、専門的な資格のために、しきい値は比較的低いです。
6、会社の利益
この部分はまだ有益組成物を表示するワードクラウドの方法を使用している、ワードクラウドは次のとおりです。

図から分かるように、企業が共通しているのは、基本的に5保険料で年次有給休暇、土曜日というように、実際には、現在の視点から、すべての産業は、5回の保険の支払額は、二重見つけるために、基本的にありますが、ハードまだそう、少なくとも上記の分析から、人々は週末にもっと傾いている場合は、業界や間違っを入力することを選択し、ビューの福祉の観点から、土曜日を言うためにヒューの仕事、多くの作業。
結論
上記の局面を分析することにより、一般的に我々は、以下の点を描くことができます。
(1)産業の発展の見通しのデータ分析は、比較的高い賃金非常に良いです。
(2)現在の視点の地域分布の点では、領域は、比較的広い北もう少し開発の機会です。
(3)参入障壁から、企業のほとんどは、大学レベルの教育を必要とします。
;(4)いくつかのハードスキルの要件を除いて、仕事の経験が特に重要であり、ビューの企業の観点から必要な
(5)の観点から、各企業の利益は、それぞれの会社の利益は似ています。
最後に、説明:このデータは非常にインターネット業界のほとんどのため、プルフックネットから来ているので、解析は非常に包括的ではありません。また、ので、私はPythonの知識に精通取るので、パイソンを分析するために、その知識を使用したいです、しかし、少量のデータは、Excelを使用して分析することができ、そのようなpyecharts、タブローExcelおよび関連ツールのような他の描画ツールを使用することが好ましい外観のようなチャートが示されています。
途中であきらめてはいけない、ああ、彼らの信頼を強化するために、自分の友人を含め、友人を、切り替えたいがあります!
輸入PDとしてパンダ から matplotlibの輸入PLTとしてpyplot から matplotlibの輸入font_manager DF = pd.read_excel(' C:/ユーザー/管理者/デスクトップ/プルフック募集ネットワークデータ解析(最新)の.xlsx ' ) salary_low = [] salary_high = [] のための I における範囲(0、LEN(DF))。 DF1 = df.iloc [I] [ ' 給与' ] .split(' - ' ) salary_low .append(DF1 [0]) salary_high.append(DF1 [ 1 ]) #1 プリント(salary_low) #1 プリント(salary_high) [DF ' salary_low ' ] = salary_low DF [ ' salary_high ' ] = salary_high #賃金'000'に見て、int型に変換することができる DF [ ' salary_low ' ] = DF [ ' salary_low ' ] .str.replace(' K '、' 000 ' ) DF [ ' salary_high ' ] = DF [ ' salary_high ' ] .str.replace(' K '、' 000 ' ) #intに給与列を変換 #DF [ 'salary_lowを']。asType(np.int16) #1 印刷(DF [ 'salary_high']) #DF [ 'salary_high']。asType(np.int64)メソッド#1 DF [ ' salary_low ' ] = DF [ ' salary_low ' ] .astype(' I8 ')#1 方法2 DF [ ' salary_high '] = DFの[ 'salary_high ' ] .astype(' I8 " ) DF ""」 #職場を分割、唯一の都市・グループ #位置= [] 範囲内のjについて#(0、LEN(DF)): #位置1 = df.iloc [J] [ '職場'] .split( '・') #location.append(LOCATION1 [0]) #1 df.insert(2 '位置'、場所) DF #ここで体験すると最近の卒業生は、1年以下に限定されるものではありません #Dfの[ '寿命'] =のDF [ '寿命'] .str.replace( '体験'、 '') #DF [ '寿命'] =のDF [ '寿命'] .str.replace( 'どれ'、 '1年') #Dfの[ '寿命'] =のDF [ '寿命'] .str.replace( '卒業生'、 '1年') #プロフィール df.info() #繰り返すかどうかをチェックします df.duplicated() #重複した値を削除します。 df.drop_duplicates() df.shape #は、地域グループであるために group_by_location = df.groupby( '位置')[ '职位名称'] .count()。sort_values(昇順=偽) my_font = font_manager.FontProperties(FNAME = 'C:/Windows/Fonts/msyh.ttf',size = 10) group_by_location.plot(種類= 'バー'、タイトル= '位置分布'、ラベル= '番号'、アルファ= 0.4、腐敗= 45) plt.title( 'ジョブの地域分布'、fontproperties = my_font) plt.legend(プロプ= my_font、LOC = '右上') plt.xticks(fontproperties = my_font) plt.xlabel( 'エリア名'、fontproperties = my_font) plt.savefig( './ picture1.png') plt.show() 給与下の状況について#表示 df.describe() <CODE> #職歴要件 df.groupby( '寿命')[ '名称'] .count()。sort_values(昇順=偽).PLOT(種類= 'バー'、アルファ= 0.4、腐敗= 0) 中国のラベル処理の# plt.xlabel( '寿命'、fontproperties = my_font) plt.ylabel( 'ポスト番号'、fontproperties = my_font) plt.xticks(fontproperties = my_font) plt.title( '各年齢の位置分布'、fontproperties = my_font) plt.savefig(」./写真2' ) plt.show() 最低賃金と仕事の経験#との相関関係 Y1 = df.groupby( '寿命')[ 'salary_low'] AGG([( '最小給与'、 '分')、 ( '平均給与'、 '平均')、 ( '最大給与'、 '最大')])。Sort_values(= '平均給与' によります) y1.plot.bar(アルファ= 0.4、腐敗= 0) plt.xticks(fontproperties = my_font) plt.xlabel( '寿命'、fontproperties = my_font) plt.ylabel( '給与'、fontproperties = my_font) plt.title( '年齢と給与の分布'、fontproperties = my_font) plt.legend(LOC = '右上'、プロプ= my_font) #縦スケール調整範囲 plt.ylim(YMAX = 50000) plt.savefig(」./しゃし' ) plt.show() df.groupby( 'アカデミック要件')[ '名称'] .count()。plot.bar(アルファ= 0.4、腐敗= 0) plt.xticks(fontproperties = my_font) plt.xlabel( '度'、fontproperties = my_font) plt.ylabel( 'ジョブの数'、fontproperties = my_font) plt.title( '異なる教育ポジションの需要'、fontproperties = my_font) plt.savefig(」./ picture5' ) plt.show()