目的のファイルやディレクトリを見つける1.find
フォーマット:見つける[パス] [-option] [-exec |グレップ| xargsの-ok -print | ...] [コマンド{} \;]
パラメータ:
入力する型の検索
Fファイル
Dディレクトリ
-nameファイル名を探します
サイズに応じ頼む価格を見つけるために、-size。例えば:見つける/データ-size 5M
ファイルのパーミッションに基づいて-perm下さい。例えば:/データ-perm 755を見つけます
-maxdepth層の最大数は、n表示します。(このパラメータは、通常、そうでなければ、警告が存在するであろう、最初に配置されています)。例えば:見つける/データ/ -maxdepth 2型D
-execコマンド{} \;与えられたパラメータを実行するためのコマンド・ファイルを一致させます。フォームコマンド{} \。
-execと同じ効果を-OK。違いは、コマンドプロンプトを実行する前に、ユーザーが実行するかどうかを確認することができます、ということです。
-mtime -n / + N対応するファイルの更新時刻を見つけるために従いました。N + N日前指し; -nは、n日以内を意味します。プラスまたはマイナス記号を持たなければならない日数の前では、そうしないと、検索結果はありません。
例:-typeのF -name "* .logの" -mtime +7を見つける| xargsのLSと-l或のls -l $(-type F -name "* .logの" -mtime 7を見つける。)或型F -name見つけます"* .logの" -mtime 7つの-exec LS -l {} \。
!否定。注意:シンボルの前と後の少なくとも1つのスペースを。例えば:見つける/データは、2型Dの-nameを-maxdepth! ""
-----(サブディレクトリ内のサブディレクトリとファイルを含む)、現在のディレクトリ内のすべてのファイルを表示するには引数を見つけていません
2.grepフィルタ。あなたがファイルに欲しいものを見つけます
フォーマット:ファイル名にキーの文字を見つけるために使用grepのパラメータ
パラメータ:
-v除外。例:ファイル内のgrep -v「NUM」test.txtというtest.txtのは、numが非文字含まれている 行 表示を
マッチが現れると行N列以下時間を示す-An文字行。例えば:grepのA15「NUM」テキスト内のtest.txt test.txtという、num個のライン表示マッチした文字、およびライン15下の行を表示します
配置されている文字、および行番号の内容に合わせて、-n表示行。
ディスプレイ、即ち、一致コンテンツのそれぞれの-o grepの実行。定期的に必要とする、そして、定期的には、コンテンツへの各マッチです。
egrepのは、高度な定期的にサポートしています。grepの-Eに相当
ラインを取る3.sed。交換のために使用します。デフォルトでは、ファイルの内容全体を表示します。また、コンテンツを見つけるために使用することができます(つまり、あまり使用します)
フォーマット:ファイル名、行/検索/置換文字にマッチするsedのパラメータ
パラメータ:
デフォルトの出力をキャンセル-n。ことは、デフォルトの廃止は、全体の内容を表示し、一般的にPを使用して。
-rは、拡張正規への支持を表明しました。
-iファイルの内容を変更します
例えば:
行フェッチ: '20 -Nセッド、30〜20 Test.txtファイル行の30P「test.txtのライン表示内容。
sedの-n '20P' 表示内容test.txtというファイルのtest.txtという行20。
SED -N '3、$ pを' 最後の行にあるtest.txt第3の表示ラインを。
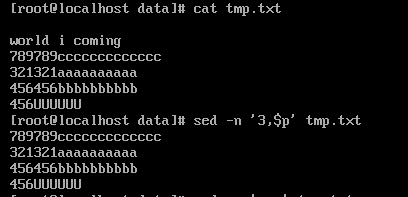
注意:どのように多くの行の前または表示する行数の後に、あなたが頭や尾のコマンドを使用することができます。SEDは、特定の行または行の範囲で示しています。ディスプレイ上の表示ラインが完全にケリすることができます。
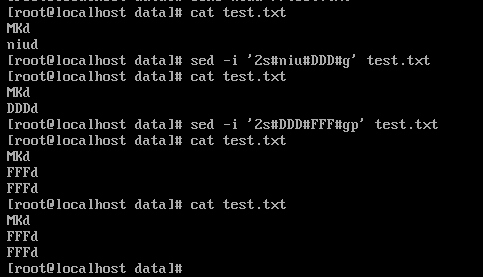
また: SED -i ':SEDが'なぜ#1 S#また#G' test.txtの例えば-i S#NM#DDD#G' test.txtの紙test.txtのすべてのDDD NMを交換します
注:SG真ん中の3つのシンボルを交換する場合は何もすることができますが、一般的に使用されるまたは#@、すなわちS @@@グラムまたはsの###グラム
複数のファイルの内容との代替を探します:
/データ/ -type fが-name "* .SH" を見つける| xargsがsedの-iの#abcの#のKPLの#g 'は、すべてのファイルにABCを置き換え、終了.SH内のすべてのファイルの/ dataフォルダを見つけますKPL。
二行目のtest.txt '2S#ABC#123#GP' ABC 2を123に置き換えられ-n sedは、表示されています。追加した場合、その後、ここで-iは、ファイル全体の内容のような、加工ラインの結果によって置き換えられる:test.txtの-i「2S#ABC#123#GP -N」セッド、それは2行目の全てのABCであろう123の後に置き換え、空のファイル、第2の書き込みラインの内容は、以下の通り:
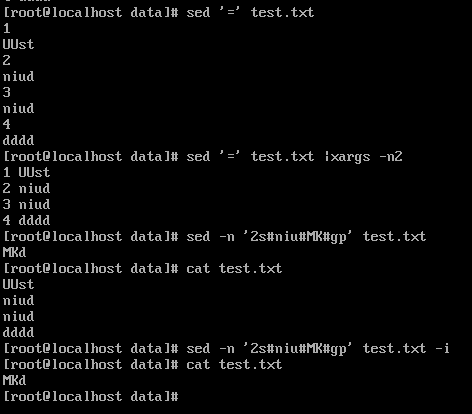 「=」の各行の行番号を示しプラス
「=」の各行の行番号を示しプラス
それ以外の場合は間違って行くだろう、あなたは限りすることができますように-i、パラメータpを追加することはできません、行の特定のコンテンツを交換し、それが複数の行になります。ここでは、まだ我々は、調査研究が必要になります。
SED -i '2S#1のABC#123#のG' のtest.txtはないパラメータpは、法線123を交換するように2 ABCです。
。sedのようなパラメータがpであるtest.txtという-i「2S位ABC#123#GP」は、交換するラインにおいてそれ以上で、かつ一貫性のあるコンテンツ行図2ます。
検索: sedの-n '/ ABC / P'紙の表示を含むABC test.txtの行。
行のsed「/ ABC / D」test.txtの文書におけるABCの文字が表示されます(プラス-n場合は、ここで、それは何も示していない)は含まれません。-----一般的に使用するので、不便のsed、grepを持つ行を見つけるために、文字に基づいて、だけでなく、少ないと。

4.awk列を取ります。行してください。計算。
フォーマット:AWKパラメータは、ファイル名、行/列見つける/取り文字を取得
awkのない{} 'ファイル例:第2のコンテンツファイルtest.txtというの最初の3行を取るのtest.txt awkのNR == 2 {$ 3印刷}'
パラメータ:
(セパレータとして指定されていない、デフォルトのスペース)区切り文字を指定-F。例えば:AWK -F "" '{$ 3印刷}' test.txtのカンマ区切り、表示部3として、
-F "[、]" 複数の区切り文字を指定します。例えば:AWK -F "[、]" test.txtのカンマまたはスペース区切りとして、3〜5のディスプレイ '{$ 5、$ 3を印刷}'
-F "[、] +" 複数の区切り文字を指定します。ここでは、セパレータとしての連続したスペースやカンマで+記号。
$ N n列
$ 0行全体の内容を表します
NRは、行番号を示します
{印刷}
列を取ります:
awkは3ページを表示あるtest.txt '{] $ 3印刷します'
awkの列6、2ページを表示あるtest.txt '{$ 2、$ 6を印刷}'
awkは'{ "$ 2を印刷 tets.txt AA" $ 4}' 2ページ、4欄を表示します。中括弧、二重引用符は出力内容がそのままます。
取行:
awkのNRの== 20、NRの== 30 'test.txtの表示ライン20、ライン30へ
test.txtのは、ライン20に示されているawkのNRの== 20 '
検索:
文書内の文字の123本の表示ラインを備えるのawk「/ 123 /」test.txtの
awkは「!/ 123 /」test.txtの表示行123は、文書中の文字が含まれていません