ロジスティック回帰アルゴリズムを達成するために、そしてMNISTデータにおける学習者の影響を一元ビュー:目的。
Ministデータセット データタイプ: 手書きのデジタルデータセット、0 10〜9カテゴリ。 各画像は$ 28times28times1 $グレースケール画像です。
規模データセット: 60,000サンプルのトレーニングセット10,000サンプルのテストセット。
10個のクラスがあるので、マルチソート処理OVR使用することができる、符号化EOCO MVMを行うために使用することができます。
ロジスティック回帰は達成します ロジスティック回帰モデル
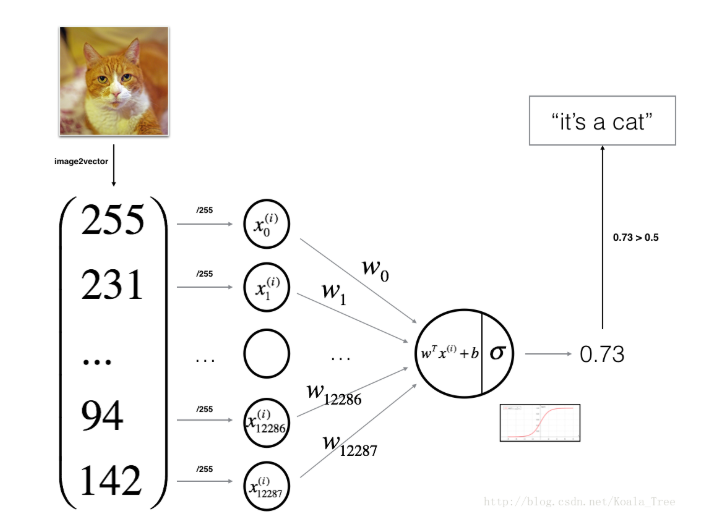
ニューラルネットワーク要素のシグモイド活性化関数とみなすロジスティック回帰を使用して。
サンプルの$ boldsymbol {X} _iの$のための:
直線部分と活性化関数:私たちのモデルは、2つの部分から構成されます。
肯定の場合に比べ$帽子なら{Y} _i> 0.5 $、;もし$帽子{Y} _ileq0.5の$、比較反例。
$ハットサンプルがクラスに属する{Y} $可視化陽性確率。
損失関数 単一変数$ boldsymbol {X} _iの$損失関数(対数尤度)。
$ Y_I = 0 $、$ LNのような対数損失に属する即ち$のboldsymbol {X} _iの$(1ハット{Y } _i)$、 $ Y_I = 1 $、すなわち$のboldsymbol {X }クラスに属する_iする$ N、{Y} _iの$ lnhat $の損失の数。
すべての学習サンプルに対する損失関数の場合
今、私たちは満足して$(boldsymbol {W} ^ {*}、B ^ {*})$をパラメータ欲しいです
勾配降下 オブジェクト:我々は目的関数の$ J $を最小化する最適なパラメータの$ boldsymbol {W} ^ {*} $ aとb ^ {*} $ $を、見つけるために。
初期化の$ boldsymbol {W} $ゼロB、 対数関数が凸関数であり、任意の値は、勾配降下によって最適解を見つけるために初期化することができます。
1 2 w = np.zeros((X_train.shape[0 ], 1 )) b = 0
进行num_iterations次梯度下降:
用当前的$boldsymbol{w}$和$b$计算$hat{boldsymbol{y}}$
1 2 y_hat = sigmoid(np.dot(w.T, X_train) + b)
1 2 3 cost = -1.0 / m_train * np.sum(Y_train * np.log(y_hat) + (1 - Y_train) * np.log(1 - y_hat)) cost = np.squeeze(cost)
1 2 3 dw = 1.0 / m_train * np.dot(X_train, (y_hat - Y_train).T) db = 1.0 / m_train * np.sum(y_hat - Y_train)
1 2 3 w = w - learning_rate * dw b = b - learning_rate * db
经过num_iterations次梯度下降就得到我们最后的$boldsymbol{w}^{*}$和$b^{*}$了。
1 2 3 4 y_hat_train = sigmoid(np.dot(w.T, X_train) + b) y_hat_test = sigmoid(np.dot(w.T, X_test) + b)
$hat{boldsymbol{y}}$算是属于正类的概率。
1 2 3 4 y_prediction_train = np.zeros((1 , m_train)) y_prediction_train[y_hat_train > 0.5 ] = 1 y_prediction_test = np.zeros((1 , m_test)) y_prediction_test[y_hat_test > 0.5 ] = 1
总的模型函数如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 def (X_train, Y_train, X_test, Y_test, num_iterations=2000 , learning_rate=0.5 , print_cost=False) : """ 逻辑回归模型 参数: X_train -- np数组(num_px * num_px, m_train) Y_train -- np数组(1, m_train) X_test -- np数组(num_px * num_px, m_test) Y_test -- np数组(1, m_test) num_iterations -- 超参数 迭代次数 learning_rate -- 超参数 学习率 print_cost -- Set to true to print the cost every 100 iterations """ m_train = X_train.shape[1 ] m_test = X_test.shape[1 ] w = np.zeros((X_train.shape[0 ], 1 )) b = 0 costs = [] for i in range(num_iterations): A = sigmoid(np.dot(w.T, X_train) + b) cost = -1.0 / m_train * np.sum(Y_train * np.log(A) + (1 - Y_train) * np.log(1 - A)) cost = np.squeeze(cost) dw = 1.0 / m_train * np.dot(X_train, (A - Y_train).T) db = 1.0 / m_train * np.sum(A - Y_train) w = w - learning_rate * dw b = b - learning_rate * db if i % 100 == 0 : costs.append(cost) if print_cost and i % 100 == 0 : print("Cost after iteration %i: %f" % (i, cost)) w = w.reshape(-1 , 1 ) y_hat_train = sigmoid(np.dot(w.T, X_train) + b) y_hat_test = sigmoid(np.dot(w.T, X_test) + b) y_prediction_train = np.zeros((1 , m_train)) y_prediction_train[y_hat_train > 0.5 ] = 1 y_prediction_test = np.zeros((1 , m_test)) y_prediction_test[y_hat_test > 0.5 ] = 1 D = { "コスト" :コスト、 "Y_prediction_test" :y_prediction_test、 "Y_prediction_train" :y_prediction_train、 "Y_hat_test" :y_hat_test、 "Y_hat_train" :y_hat_train、 "W" 、W: "B" :B、 "learning_rate" :learning_rate 、 "num_iterations" :num_iterations} リターン D
MNISTデータセットをインポートした後、トレーニングOVM 10分類のアイデアを使用して。 それを分類します。
各分類器は、負正の場合、追加の9つのカテゴリのカテゴリです。 従って$ N実施例:実施例トランス= 1:9 $、正例の数は反例の数よりもはるかに小さく、この比が実質的に生成された実際の配信データの比率であるように、不平衡カテゴリの問題を生じないが。
完全なコードを参照してください ここに
オリジナル: ビッグボックス MNISTデータセットのロジスティック回帰