「カイカイの機械学習」
目次
1.ロジスティック回帰
1.戻る
線形回帰は、機械学習で最も単純な回帰アルゴリズムであり、ほとんどの人が精通している方程式を記述します。
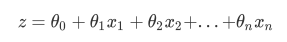
2.バイナリロジスティック回帰
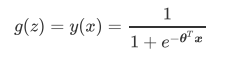
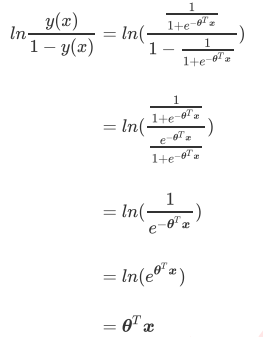
y(x)の対数確率の性質が実際には線形回帰zであることを見つけるのは難しくありません。実際には、線形回帰モデルの予測結果の対数確率を使用して、結果を0と1に無限に近づけています。 。したがって、対応するモデルが「と呼ばれる対数確率リターン私たちです」(ロジスティック回帰)、ロジスティック回帰、この「リターン」と呼ばれるが、の分類に使用される分類器。
前述のように、線形回帰のコアタスクは、解くことによってこの予測関数を構築することであり、予測関数が可能な限りデータに適合できることを期待しているため、ロジスティック回帰のコアタスクは同様です:θ\ thetaを解くθ可能な限りデータを収めることができ、予測機能構成するY(X)Y(X)をy (x )、および特徴行列を予測関数に入力して、対応するラベル値yyを取得します。および。
3.損失機能
「損失関数」評価指標を使用して、パラメータθ\ thetaを測定しますθモデルをトレーニングセットに適合させたときに生成される情報損失のサイズは、パラメーターの長所と短所を測定するために使用されます。パラメータのセットを使用してモデリングした後、モデルがトレーニングセットで良好に機能する場合、モデルフィッティングプロセスでの損失は小さく、損失関数の値は小さく、このパラメータのセットは優れています。

モデルがトレーニングセットで最適に機能するように最小損失関数を追求しているため、別の問題が発生する可能性があります。モデルがトレーニングセットではうまく機能するが、テストセットではうまく機能しない場合、モデルはオーバーフィットします。ロジスティック回帰と線形回帰は本質的にアンダーフィッティングモデルですが、モデルの調整を支援するためにオーバーフィッティングテクノロジーを制御する必要があります。ロジスティック回帰でのオーバーフィッティングの制御は、正規化によって実現されます。
2、sklearnのロジスティック回帰
1.sklearnの回帰
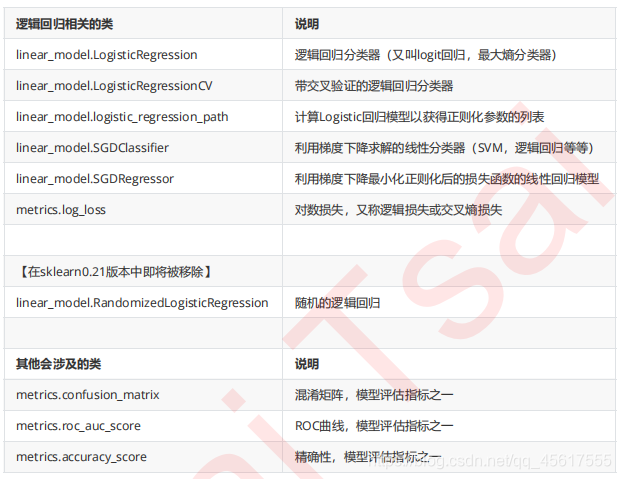
2.linear_model.LogisticRegression
sklearn.linear_model.LogisticRegression (
penalty=’l2’,
dual=False,
tol=0.0001,
C=1.0,
fit_intercept=True,
intercept_scaling=1,
class_weight=None,
random_state=None,
solver=’warn’,
max_iter=100,
multi_class=’warn’,
verbose=0,
warm_start=False,
n_jobs=None)
3.重要なパラメータペナルティ&C
3.1正規化
正規化は、モデルの過剰適合を防ぐために使用されるプロセスです。一般的に使用される2つのオプション、L1正規化とL2正規化があります。これらは、損失関数の後にパラメータベクトルのL1正規形とL2正規形の倍数を追加することによって実装されます。
L1ノルムは、パラメーターベクトル内の各パラメーターの絶対値の合計として表され、L2ノルムは、パラメーターベクトル内の各パラメーターの二乗和の平方根として表されます。
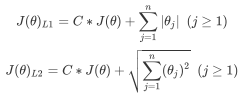

一般的に言って、私たちの主な目的がオーバーフィットを防ぐことである場合、L2正規化を選択することで十分です。ただし、L2の正規化がまだ適切でなく、モデルのパフォーマンスが不明なデータセットで不十分な場合は、L1の正規化を検討できます。
4.コード
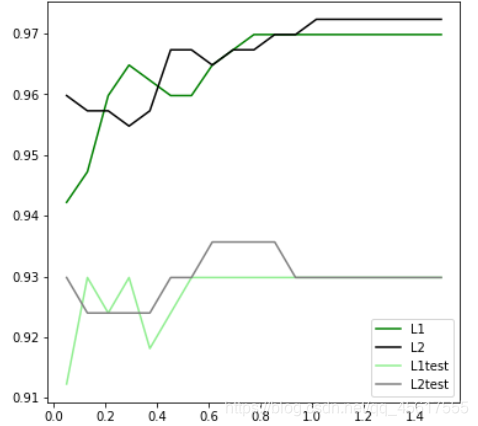
4.1 L1とL2のどちらの効果が優れているかを判断しますか?
l1 = []
l2 = []
l1test = []
l2test = []
Xtrain, Xtest, Ytrain, Ytest = train_test_split(X,y,test_size=0.3,random_state=420)
for i in np.linspace(0.05,1.5,19):
lrl1 = LR(penalty="l1",solver="liblinear",C=i,max_iter=1000)
lrl2 = LR(penalty="l2",solver="liblinear",C=i,max_iter=1000)
lrl1 = lrl1.fit(Xtrain,Ytrain)
l1.append(accuracy_score(lrl1.predict(Xtrain),Ytrain))
l1test.append(accuracy_score(lrl1.predict(Xtest),Ytest))
lrl2 = lrl2.fit(Xtrain,Ytrain)
l2.append(accuracy_score(lrl2.predict(Xtrain),Ytrain))
l2test.append(accuracy_score(lrl2.predict(Xtest),Ytest))
graph = [l1,l2,l1test,l2test]
color = ["green","black","lightgreen","gray"]
label = ["L1","L2","L1test","L2test"]
plt.figure(figsize=(6,6))
for i in range(len(graph)):
plt.plot(np.linspace(0.05,1.5,19),graph[i],color[i],label=label[i])
plt.legend(loc=4) #图例的位置在哪里?4表示,右下角
plt.show()
4.2埋め込み方法
fullx = []
fsx = []
C=np.arange(0.01,10.01,0.5)
for i in C:
LR_ = LR(solver="liblinear",C=i,random_state=420)
fullx.append(cross_val_score(LR_,data.data,data.target,cv=10).mean())
X_embedded = SelectFromModel(LR_,norm_order=1).fit_transform(data.data,data.target)
fsx.append(cross_val_score(LR_,X_embedded,data.target,cv=10).mean())
print(max(fsx),C[fsx.index(max(fsx))])
plt.figure(figsize=(20,5))
plt.plot(C,fullx,label="full")
plt.plot(C,fsx,label="feature selection")
plt.xticks(C)
plt.legend()
plt.show()
