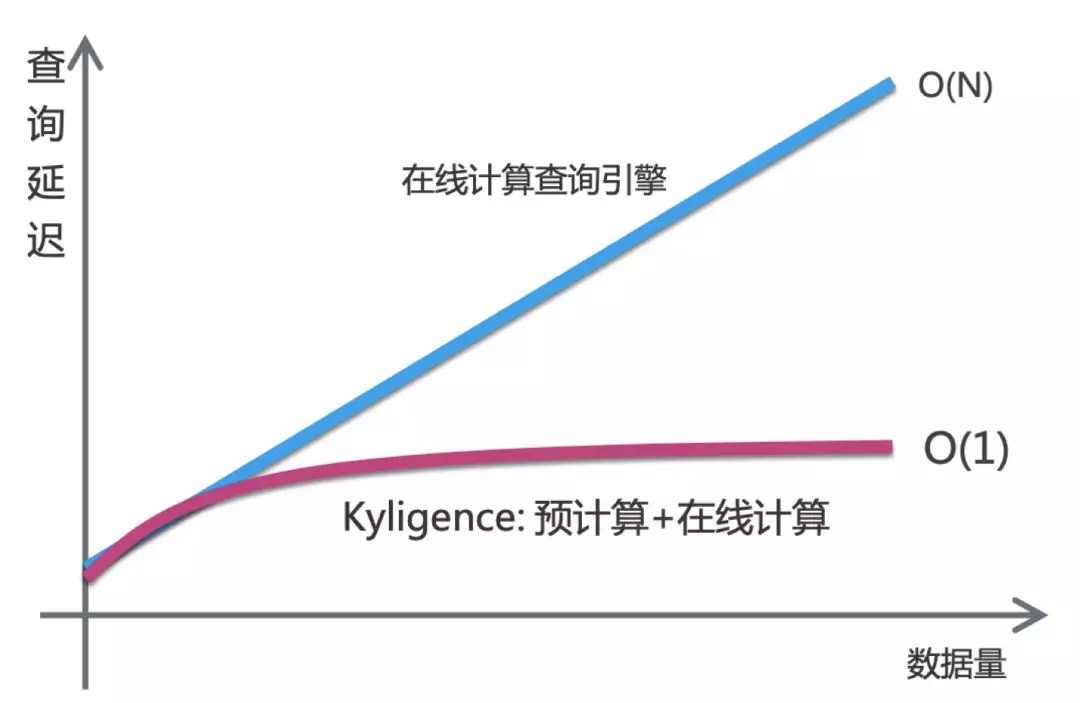
今日の新興様々なグローバルビッグデータ技術は、競争上の優位性を獲得するために、大量のデータをフルに活用するために、企業は、信頼性とタイムリーな分析は、膨大な量のデータへの洞察を提供し、高性能なデータ分析プラットフォームを必要としています。データ駆動型企業の場合は、大量のデータのインタラクティブな分析の能力は、1つの非常に重要な機能です。このテストは、大規模なデータセット上のスパークSQLクエリ応答とKyligence製品の性能の違いと特性を比較し、多次元シーン解析に焦点を当てています。
テスト製品
SQLは、本質的にするためにスパークMPP DAGに基づいて、論理プログラム、物理的実行、および分散実行にSQLクエリ要求により、SQLまたはSQLクエリ・インターフェースを提供します。クエリの実行中に、完全なメモリの完全な使用は、低いレイテンシを達成するために並列クエリに基づいて算出される(典型的には秒分遅いデータ照会応答の、より多量)。
Kyligence Enterpriseは、エンタープライズクラスのインテリジェントビッグデータOLAPで、基本的な考え方は、元のデータのクエリの速度にアクセスせずに到達したインデックスをスキャンし、多次元インデックスのデータです。製品の完全な使用が技術をカウントすることが予想されるので、Kyligence Enterpriseは、サブ秒の応答の多次元分析を専門としています。データの量が指数関数的に成長しているとき、具体的には、クエリのパフォーマンスは、まだ非常に重要な利点があります。
 試験製品はKyligenceエンタープライズ4.0、ビッグデータ分析エンジンのスパークSQL 2.4.1の制御です。
試験製品はKyligenceエンタープライズ4.0、ビッグデータ分析エンジンのスパークSQL 2.4.1の制御です。
ベンチマークを決定します
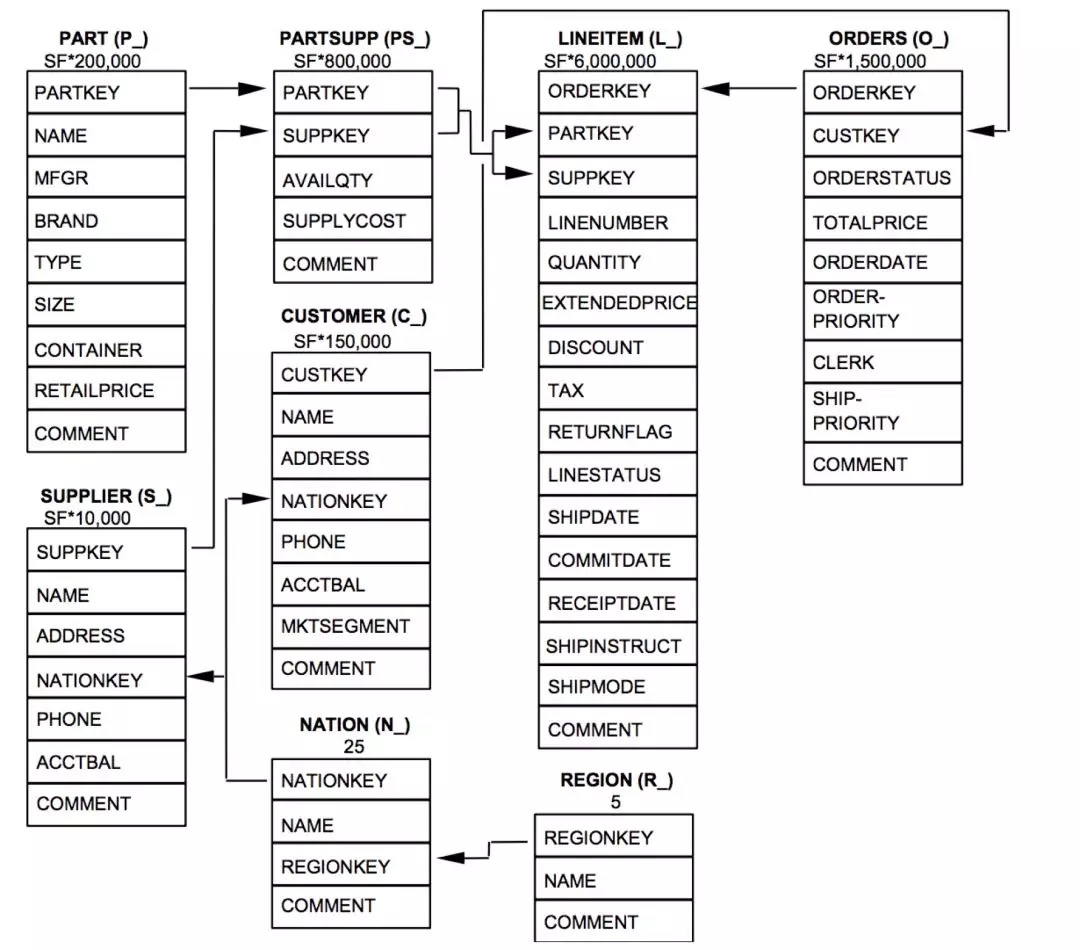
選択したベンチマークでは、我々は分析し、クエリが実際のユーザー、TPC-Hベンチマークに従って試験最終決定の場面を特徴と考えます。TPC-Hは、意思決定支援システムは、8つのテーブル、22個のクエリを定義するベンチマーク商品販売のシナリオを、抽象化です。テストクエリは、一般的に、より複雑で、うまくなどの価格設定やプロモーション分析、供給および販売チャネルトラフィック分析、収益および収益性分析、顧客満足度の分析、市場シェア分析、などのビジネスシナリオ、最も一般的なテーマの分析、の広い範囲を表します。
- 查询集中的Query 1,总结了已经开票的、寄出的、退回的业务交易量。

- 查询Query 3,分析了具有最高价值的n个未发货交易单。

- 查询Query 4,确定了订单排序系统的工作情况,并评估了客户满意度。

更多查询和数据集的信息,可以了解TCP-HBenchmark标准。
准备测试数据和环境
我们使用TPC-H数据工具生成了不同规模的测试数据集,在20台物理机中使用一个资源队列进行测试。
测试查询前,KyligenceEnterprise产品通过预计算生成了不同大小的 TPC-H 数据文件,以 parquet 格式存储在安装节点的 HDFS 上供查询测试使用。每条查询都执行了多次,最终取其平均值作为实验结果。整个测试过程中,关闭了KyligenceEnterprise 4.0 的查询缓存机制。
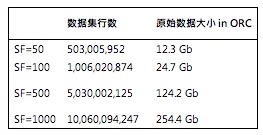
数据集
以下为每个测试数据集中,各个表的行数。

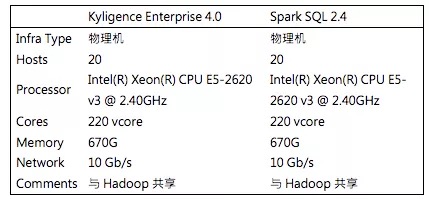
硬件环境
测试集群的硬件配置。
测试结果和解读
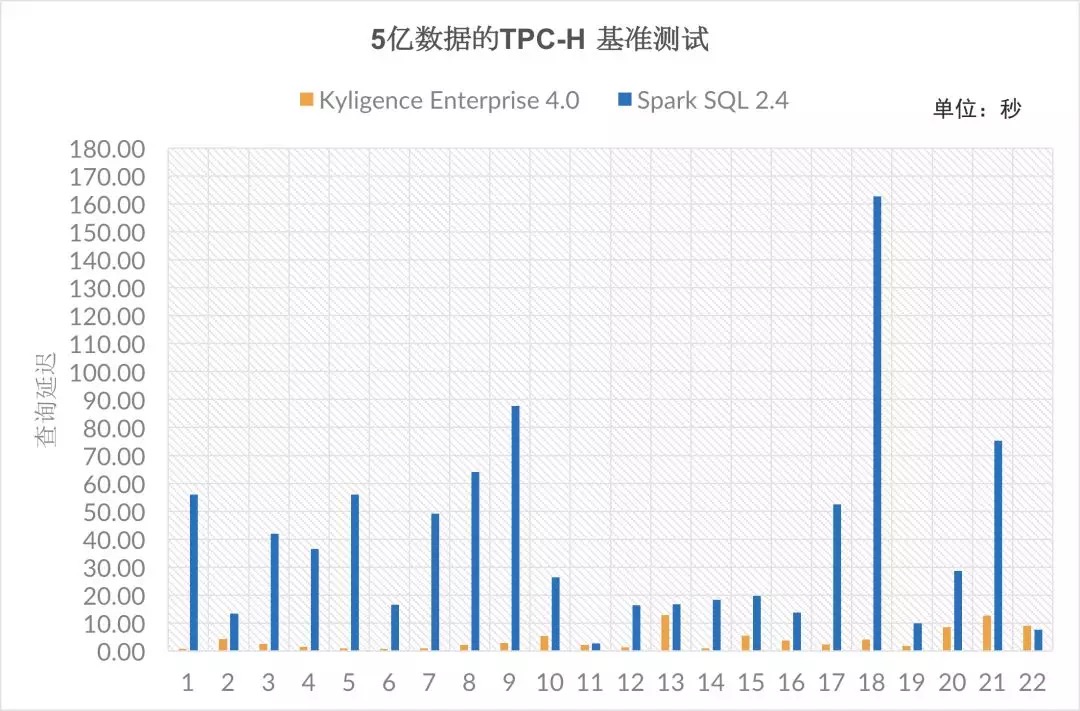
在5亿数据的TPC-H 数据集上,Kyligence Enterprise 4.0的查询性能普遍优于Spark SQL 2.4。22条测试查询中,Kyligence 产品支持60% 查询在3秒以内返回结果,90% 查询可以在10秒以内返回结果,最大查询延迟也只有12.81秒。这些数据反映了,在亿级大数据上, Kyligence产品能够支持秒级的的交互式分析场景。
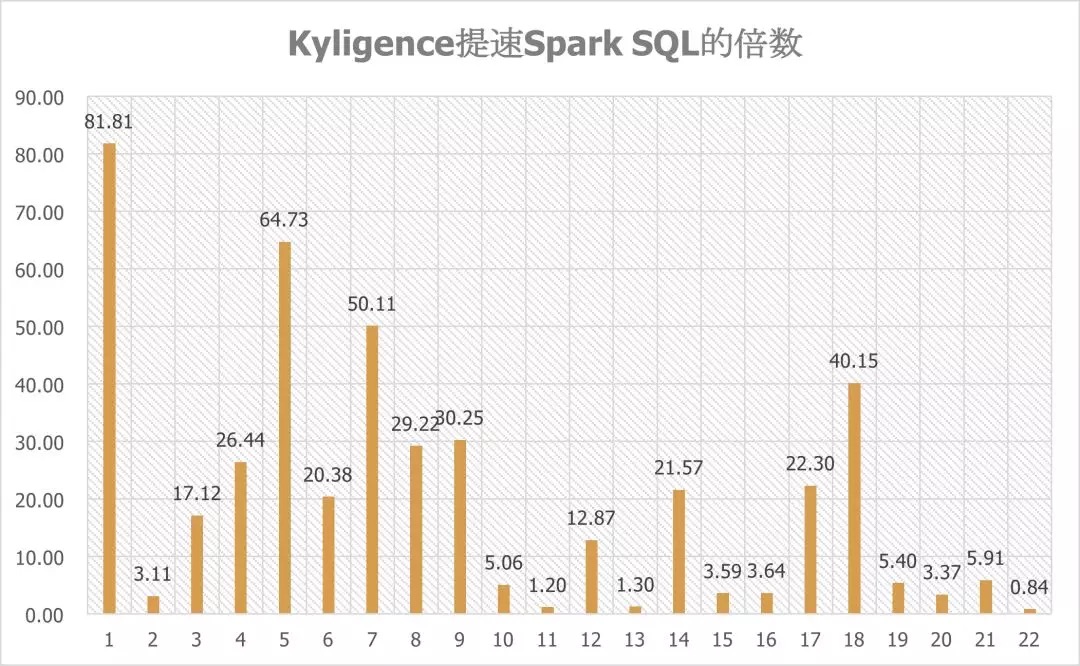
对比来看,Kyligence Enterprise 4.0 的查询性能明显优于 Spark SQL 2.4,其中有55% 的查询提升在10倍以上,96% 查询有提升 (query 22稍慢于Spark SQL 2.4,但性能相差不足1秒),性能优势非常明显,单条查询的性能最大提升81.81倍(query 1);单条查询时间最多缩短150秒(query 18)。
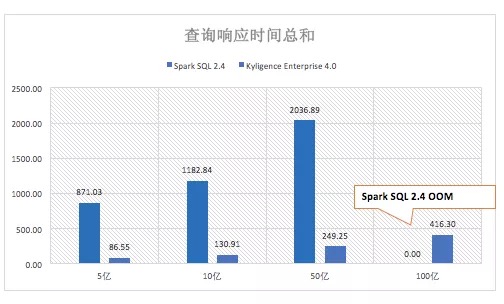
当数据集继续增加到 10亿、50亿、100亿时,即使集群资源不扩充,Kyligence Enterprise 4.0的查询延迟的总时间相对平稳。面对数据量倍数增长到100亿时,Spark SQL 作为在内存中完成数据中间处理过程的分析引擎,需要的资源也需要相应增长,否则就如图展现出由于内存资源不足导致查询报错。
结论和展望
通过本次TPC-H 查询性能的基准测试,我们可以得出Kyligence产品在多维分析场景下更有性能优势:
- 在5亿数据集上, Kyligence Enterprise4.0的查询性能远远优于Spark SQL 2.4。测试的22条查询中,60% 查询可以在3秒以内返回结果,90%查询可以在10秒以内返回结果,平均查询性能为Spark SQL2.4的24.47倍。
- 当数据集继续增加到 10亿、50亿、100亿时,即使集群资源不扩充,KyligenceEnterprise 4.0的查询总延迟时间相对平稳,平均每条查询的延迟时间保持在秒级。
根据上述结论,我们容易看出 Kyligence 产品非常擅长满足海量数据上的多维分析的场景,并且具有交互式和高性价比的特点。当企业的信息生态系统中数据持续增长时,选择 Kyligence 产品更是确保了技术投入的持续可用,不会因为数据量增长而导致 TCO 不断增长。SparkSQL作为 Spark 的一个处理结构化数据的程序模块,更适合抽取部分数据、周期性的转换数据,对部分数据进行灵活的简单分析。
转载自:https://kyligence.io/zh/blog/kyligence-vs-spark-sql/