まず、データマイニング---中国語の単語
•文字通り、だけでなく、どのようにセグメント化し、理解する上でテキストだけではない何か。
•例:
-フライドアサンホテル:
-牙山(アサン)/チャーハン/ショップアサン/ /ホテル揚げ
ので、より多くの英語よりも分よりも、中国の検索エンジンを、達成するために、中国語の単語の間にスペースを入れずに、英語と異なる•
ワードタスク。
•だろう何の中国語の単語が存在しない場合:
-のための「手の届くところには、」関連する「ジダンは」メッセージが表示されます
•中国の単語分割精度の問題を解決するために、一般的な単語のプログラムの無料版を提供することができますか?
-自然言語処理ワードの分野でこのような問題、完全に完全に解決することは困難である
-それぞれ異なる業界やビジネスに焦点を当て、セグメンテーションツールのデザイン戦略は同じではありません
第二に、セグメント化方式

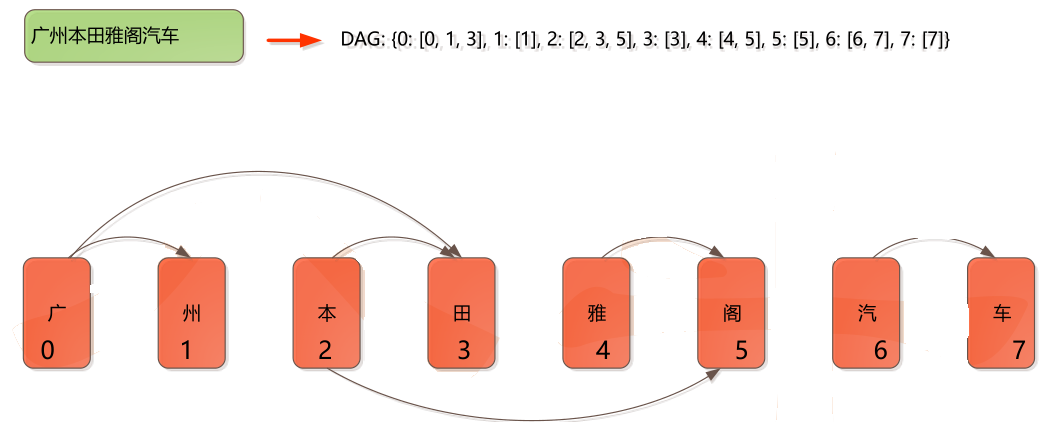
、そうでない場合は対応するビットが0である、ビット•カットが1で対応した位置を開始して示すために、「はい/ご意見/発散、」ビット容量がある:11010
あなたはまた、例えば、セグメント化方式を表現するために、ノードの単語列を使用することができます、「そこ/コメント/差、「単語ノードのシーケンスは、{0,1,3,5}
第三に、最も一般的な方法
•最も一般的な方法は、単語辞書の一致に基づいている
-最大長は見つけること(前方を探し、後方に見て)
•データ構造
-検索効率を向上させるために、ではない辞書に単語を照合することにより、1
-時間の時間可能なセグメントの合計割合の約3分の1を見つけるために辞書は、セグメンテーションの速度を確保するために、あなたは良い選択する必要があり
、ルックアップ辞書法を
-トライ木は、多くの場合、言葉の問題を見つけるために辞書をスピードアップするために使用します
四、トライ木

単語分割マップ
第五に、言語モデルの確率
•あなたがワードコーパスや語彙が存在しているうち分割したいと仮定し、最も簡単な方法は、言葉で確率を計算することで
はないワードカウント確率で。
•ビュー思考の統計的観点から、問題の入力単語列がC = C1、C2 ...... CNは、出力
ワードシーケンス...... WMのW2、S = W1を M <= N、。特定文字列Cのために、複数の切断有する
プログラムに対応する点Sを、単語分割タスクはSでプログラムを見つけることで、S、Pよう|の値(S C)
最高。
•P(S | C)は、最も可能性の高い解析入力文字列である文字列CによるセグメンテーションSを生成する確率は、ある
単語のシーケンスを
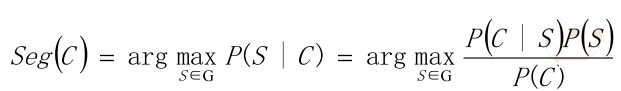
例:
•例:入力列Cは、「南京長江大橋、」二分割をすることができる次の
- S1:南京/長江/ブリッジ
- S2:南京/市長/大橋
•両方のセグメンテーションそれぞれS1およびS2と呼ばれます。そしてP |条件付き確率P(C S1)を算出する(S2 | C)を、その後に応じて
選択された値を決定するために、P S1又はS2 | |の(C S2)(C S1)及びP.
•P(C)は、コーパス内の文字列の出現確率です。例えば、一つはその10 000コーパス文、ある
「南京長江大橋、」次に、P(C)= P(「南京長江大橋」)=百万分の一であるが。
•ので、P(C∩S)= P(S | C)* P(C)= P(C | S)* P(S)、そう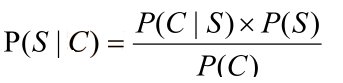
•ベイズ式に:

•のみ正規の固定値のP(C)
•また:確率は(C | S)Pので、唯一の方法がある文字の文字列に単語列から回復= 1。
•だから、:P(S1 | C)と比較し、P(S2 | C)のサイズは比較的P(S1)及びP(S2)サイズになります
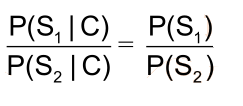
•P(S1)= P(南京、長江、橋)=ので、P(南京)* P(揚子江)* P(ブリッジ) > P(S2)= P(南京市、
ロング江橋)、そうセグメント化方式S1を選択
例3:
•実装を容易にするために、我々はその後、各単語間の確率が文脈自由であることを前提としています。

•場合は、P(w)は単語がコーパスに出現する確率です。Xが増加すると、関数y =ログ(X)ので
Yが増大され、単調増加関数です。Αは、シンボルに比例しています。単語の確率が1未満であるので、そう取る
ログが負です。
•最後のカウントのlogP(ワット)。少数、例えばあればログは、アンダーフローを防止するために取られる0.000000000000000000000000000001ダウンオーバーフローしてもよいです。
事前の値がカウントアウトされている場合•、結果はさらによりもむしろ乗算添加することによって直接得ることができるより速い方法スピード。
第六に、解決のための動的計画法---
•文字列Xは、長さがm、初めの数です。
•文字列Y、長さnの、先頭からの番号。
•X I = <X 1、......、XI>すなわち前のi番目の文字列X(1 <= l <= M)(iはXの接頭文字列」としてカウントされるX I「)
•Y I = <Y 1、...、YI>すなわち、i番目の文字列Yの前に(1 <= jの<= N)(Y jが "文字列Y jのプレフィックス" としてカウントされます)
•LCS(X、Y)はXの文字列であり、Yは、最長共通サブシーケンスである、すなわち、Z = <Z 1、......、ZK>
•XM = YN(最後の文字と同じ)、次いで:?最長共通最後の文字シーケンスZ kはX及びY nは必ずしも場合XM(=アルキニル)
•XM Zkを=乃至Yn =
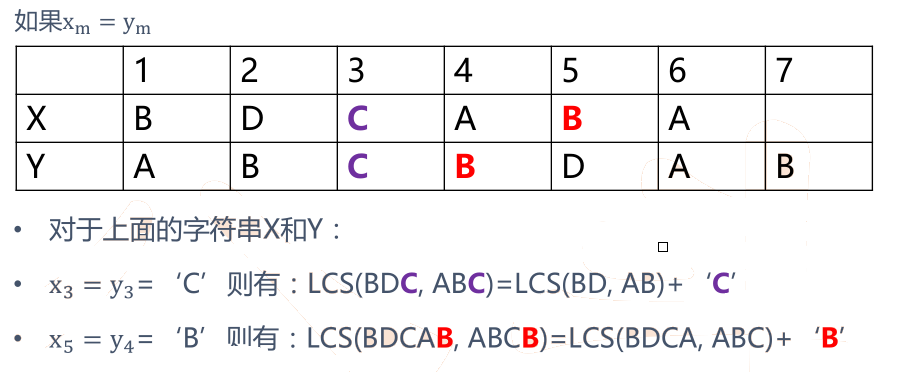
七、LCSの概要分析
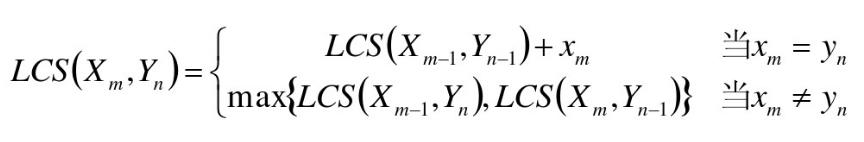
•動的なプログラミングの問題です!
八、二次元配列----
•二次元配列C [M、N - ]
•C [I、J]最長共通サブシーケンスの記録シーケンスXの長さのiおよびY jの
- I = 0又はJ = 0、X iは空虚であり、そして最長共通サブシーケンスY jのため、C [I、J] = 0
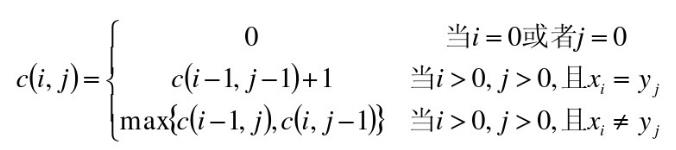
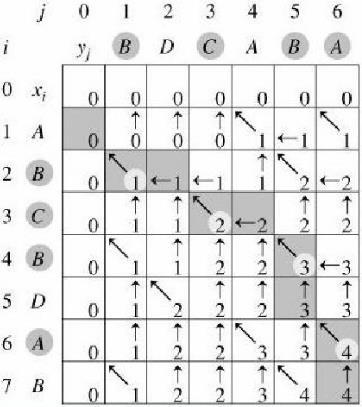
例:
•X = <A、B、C、B、D、A、B>
•Y = <B、D、C、A、B、A>
mr_lcsのMapReduceの
## map.py
# - * -コーディング:UTF-8 - * -
!#は/ usr / binに/ Pythonの
インポートSYS
DEF cal_lcs_sim(first_str、second_str):
len_vv = [0] * 50] * 50
first_str =ユニコード( first_str、 "UTF-8"、エラー= '無視' ) second_str =ユニコード(second_str、 "UTF-8"、エラー= '無視' )
len_1 = LEN(first_str.strip())len_2 = LEN(second_str.strip( ))#for first_strで:#word = a.encode( 'UTF-8')は、iの範囲は(1、len_1 + 1 )の範囲内のJ(1、len_2 + 1 ):first_strなら[I - 1] == second_str [J - 1 ]:len_vv [I] [J] = 1 + len_vv [I - 1] [J - 1 ]他:len_vv [I] [J] = MAX(len_vv [I - 1] [J]、len_vv [I] [J - 1])戻りフロート(フロート(len_vv [len_1] [len_2] * 2)/フロート(len_1 + len_2)のラインのため)sys.stdinを:SS = line.strip()スプリット( '\ tの' )lenの場合( SS)= 2! :継続first_str = SS [0] .strip()second_str = SS [1 ] .strip()sim_score = cal_lcs_sim(first_str、second_str)印刷「\ t'.join([first_str、second_str、STR( sim_score)])
#run.sh
HADOOP_CMD = "は/ usr / local / srcに/ Hadoopの-1.2.1 / binに/ Hadoopの"
STREAM_JAR_PATH = "は/ usr / local / srcに/ Hadoopの-1.2.1 / contribの/ストリーミング/ Hadoopのストリーミング-1.2。 1.jar "
INPUT_FILE_PATH_1 = "/ lcs_input.data" OUTPUT_PATH = "/ lcs_output"
$ HADOOP_CMD FS -rmr - skipTrash $ OUTPUT_PATH#ステップ1. $ HADOOP_CMDジャーの$ STREAM_JAR_PATH \ - 入力$ INPUT_FILE_PATH_1 \ - 出力の$ OUTPUT_PATHの\の-mapper" 「Pythonのmap.py = 0 mapred.reduce.tasks \ -jobconf "" \ -jobconf "mapred.job.name = mr_lcs" \ -file ./map.py
mr_tfidfのMapReduceの
## red.py
ます。#/ usr / bin / Pythonの!
輸入sysは
インポート数学
current_word = なし
count_pool = [] の和= 0
docs_cnt = 508
でラインのsys.stdinを:SS = line.strip()スプリット( '\トン" )(SS)lenの場合= 2! :継続単語、ヴァル= current_word場合はSSを== なし:current_word = !単語current_word場合は= 単語:のカウントのためのcount_pool:合計+ = カウントidf_score = math.log(フロート(docs_cnt )/(フロート(和)+ 1 ))プリント"%sの\ T%S" %(current_word、idf_score)current_word = ワードcount_pool = []和=数の0 count_pool.append(INT(ヴァル))count_pool:合計+ = カウントidf_score = math.log(フロート(docs_cnt)/(フロート(和)+ 1 ))プリント"%sの\ T%S" %( current_word、idf_score)
## run.sh
HADOOP_CMD = "は/ usr / local / srcに/ Hadoopの-1.2.1 / binに/ Hadoopの"
STREAM_JAR_PATH = "は/ usr / local / srcに/ Hadoopの-1.2.1に/ contrib /ストリーミング/ Hadoopのストリーミング-1.2 .1.jar」
INPUT_FILE_PATH_1 = "/ tfidf_input.data" OUTPUT_PATH = "/ tfidf_output"
$ HADOOP_CMD FS -rmr - skipTrash $ OUTPUT_PATH#ステップ1. $ HADOOP_CMDジャーの$ STREAM_JAR_PATH \ - 入力$ INPUT_FILE_PATH_1 \ - 出力$ OUTPUT_PATH \ -mapper "Pythonのmap.py" \ -reducer "Pythonのred.py" \ -file ./ map.py \ -file ./red.py