オリジナルリンク:https://blog.csdn.net/weixin_39175124/article/details/79463993
第1のデータ処理は、データがある場合には、多くの場合、標準化を伴います。関係によって、既存のデータは、空間にマッピングされました。一般に平均値を減算し、標準的な方法を用い、その差は、標準的な空間で0に平均値にマッピングされます。データを復元することができるように、システムは、各入力パラメータの平均値と標準差を記録します。
線形回帰RBFカーネルSVM、L1およびL2のカノニカル:アルゴリズムの入力パラメータの平均は、MLは、例えば、0であるとの順序の同じ分散を持つ訓練の多くを必要と
sklearn.preprocessing.StandardScaleの Rは容易上記の機能を実現することができます。
呼ばれるよう、次のとおりです。
まず、オブジェクトの定義:
SS = sklearn.preprocessing.StandardScaler(コピー=真、真= with_mean、with_std = TRUE)
ここでは、
コピー; with_mean; with_std
既定値はTrueです。
コピー 偽、それは正規化された値を元の値を交換する場合は、データが正規化np.arrayない場合またはCSRマトリックスをscipy.sparse、データの元のコピーが置き換えられないであろう
with_mean スパースCSRまたはCSCの行列に対処するには、それ以外の場合はFalseを設定しなければならないだろうスーパーメモリ
属性を照会するには:
scale_: スケーリングするだけでなく、標準偏差
mean_:各機能の平均値
var_:各機能の分散
n_sample_seen_:サンプル数はpatial_fitによって増加させることができます
例えば:
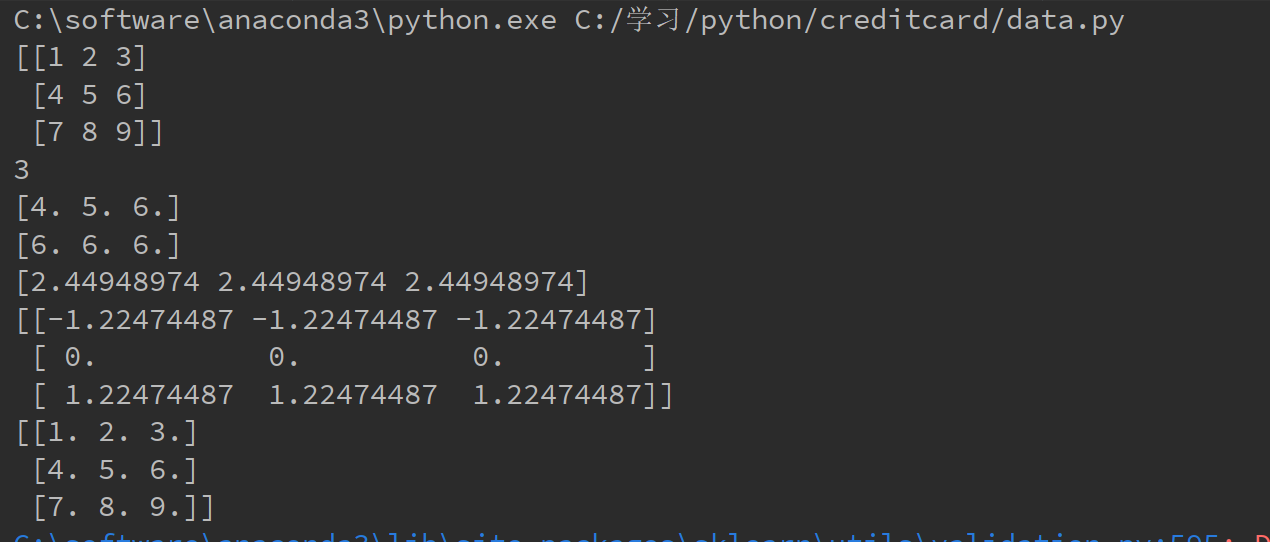
インポートのNPとしてnumpyの インポートPLTのようmatplotlib.pyplot インポートPDとしてパンダ から sklearn.preprocessing インポートStandardScaler #1 データ= pd.read_csv( "C:/学习/python/creditcard/creditcard.csv") X = np.arrayを([1 、2、3、4、5、6、7、8、9])。((3、3整形)) SS = StandardScaler() プリント(X) ss.fit(X = x)は プリント(ss.n_samples_seen_) プリント(ss.mean_) プリント(ss.var_) プリント(ss.scale_) Y = ss.fit_transform(X) の印刷(Y) Z= ss.inverse_transform(Y) の印刷(Z)
業績は次のとおりです。
これは、メソッド呼び出すことができます。
フィット(X、Y =なし):あなたは(transofrmを呼び出すことができるので、データに応じて)、入力データの各特徴の後に平均値、標準偏差、およびスケーリング係数を計算
X:トレーニングセット
Yの着信と互換性のあるパイプラインそのために
fit_transform(X、Yなし= ** fit_paramsを): 調整データの後fit_params Xによって、調整Xを取得するyは、ゼロ平均及び分散を有する各データ配信することを特徴1。
配列Xは、である:トレーニングセット
yとラベルは、
Xの変更後に返します
get_params(深い=真): 、設定されたパラメータStandardScalerオブジェクトを返します。
inverse_transform(X-、コピー=なし):名前が示すように、逆方向電流データのスケーリング則に基づいて復元されます
変換(X、Y =「非推奨 」、コピー=なし): オブジェクトの既存のルールに基づいて、新しいパラメータの正規化
fit_transform(考えることができる)フィット()と()フィット感を変換です。