言語モデル
同時確率関数Pを目的とした言語モデルは、Wiはi番目の文の単語を表し声明(W1、...、WT)のモデリング、です。ターゲット言語モデルは、私はモデルが意味のある文章の高い確率を与えることを願って、無意味なの文章は小さな確率を与えられました。このようなモデルは、このような機械翻訳、音声認識、情報検索、音声タグ付け、手書き認識など多くの分野に適用することができ、彼らは連続配列の確率を得るために期待しています。
ターゲット言語モデル確率P(W1、...、WT)は 、 テキスト内の各単語が独立していると仮定すると、文全体の同時確率、すなわち、で条件付き確率のすべての単語の積として表すことができます。
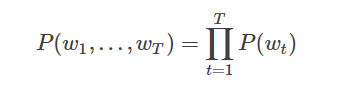
しかし、我々は密接に関連し、すべての条項の前に現れる文中の各単語の確率があることを知っているので、実際には通常、条件付き確率言語モデルを表明しました:
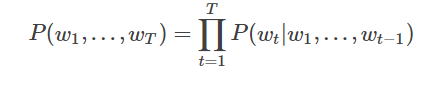
N-gramの神経モデル
nグラムには、テキストは、n個の連続したエントリを表す、テキストの重要な表現です。特定のアプリケーションシナリオに基づいて、それらの各々は文字、単語又は音節であってもよいです。nグラムモデルは、一般に、Nワードの内容を予測するために単語の履歴とN-1のnグラムの各々からなるnグラム言語モデルの訓練を受けた統計的言語モデルの重要な方法です。
私たちは、最初の単語の確率と単語tのT-1関連文の単語の前、つまり、上記では条件付き確率でモデリング言語モデルについて話しています。実際には、実際にははるかに多くの単語に小さい単語の影響、あなたはnグラム、唯一の前のn-1の単語によって影響を受ける各単語を考えると、あります。
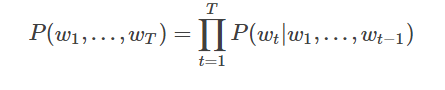
本物の材料の与えられた数、これらのコーパスが意味の文章で、Nグラムモデルの最適化の目的は、目的関数を最大化することである:
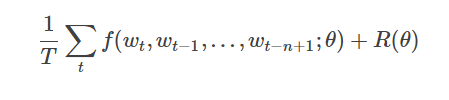
F(WT、WT-1、ここ ...、WT-N + 1)はn-1個の単語履歴に応じた電流を表します単語の重量条件付き確率、R(θ)正則化項を表すパラメータ

。図2は、下から見上げ、Nグラムニューラルネットワークモデルを示しているが、モデルは、以下のセクションに分割される: -各サンプル、モデル入力のための重量N + 1、... WT-1 、辞書の単語tの内の最初の文の出力|言葉の確率分布| V.
各入力ワードWT-N + 1、...重量 -1 最初のワードベクトルC(WT-N + 1)にマッピング行列によってマッピングされ 、... C(WT-1)。
- 単語ベクトルのすべての単語が、その後大きなベクター中にスプライシング、および中間層の非線形マッピングの後の言葉の歴史を取得するには、言いました:
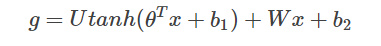
式中、Xは、歴史は、そのテキストの特徴を示す大ベクター中にスプライシングワード内のすべての単語のベクトルであり、θ、U、B1、B2及びWが接続されている中間層の層の単語ベクトルのパラメータです。Gは正規化せずに、すべての出力ワード確率を表し、GIは、i番目の辞書単語の正規化せずに出力確率を表します。
- GIを正規化することにより、ソフトマックス定義することにより、ターゲット単語重量を生成する確率は、次のとおり
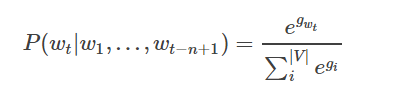
- ネットワーク(コスト)のための全体的な損失値として製剤、クロスエントロピーの多クラス分類である
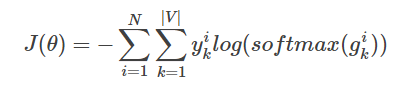
YIKを表し、I k番目のクラス実際のラベルのサンプル番目(0または1)、ソフトマックス(GIK)はk番目のクラスのI番目のサンプルを示しソフトマックス確率出力

N-Gram是基于一个假设:第n个词出现与前n-1个词相关,而与其他任何词不相关。(这也是隐马尔可夫当中的假设。)整个句子出现的概率就等于各个词出现的概率乘积。各个词的概率可以通过语料中统计计算得到。假设句子T是有词序列w1,w2,w3…wn组成,用公式表示N-Gram语言模型如下:
P(T)=P(w1)*p(w2)*p(w3)***p(wn)=p(w1)*p(w2|w1)*p(w3|w1w2)***p(wn|w1w2w3…)
一般常用的N-Gram模型是Bi-Gram和Tri-Gram。分别用公式表示如下:
Bi-Gram: P(T)=p(w1|begin)*p(w2|w1)*p(w3|w2)***p(wn|wn-1)
Tri-Gram: P(T)=p(w1|begin1,begin2)*p(w2|w1,begin1)*p(w3|w2w1)***p(wn|wn-1,wn-2)
注意上面概率的计算方法:P(w1|begin)=以w1为开头的所有句子/句子总数;p(w2|w1)=w1,w2同时出现的次数/w1出现的次数。以此类推。(这里需要进行平滑)
二、N-Gram的应用
根据上面的分析,N-Gram(有时也称为N元模型)是自然语言处理中一个非常重要的概念,通常在NLP中,它主要有两个重要应用场景:
(1)、人们基于一定的语料库,可以利用N-Gram来预计或者评估一个句子是否合理。
(2)、另外一方面,N-Gram的另外一个作用是用来评估两个字符串之间的差异程度。这是模糊匹配中常用的一种手段。
1、N-gram在两个字符串的模糊匹配中的应用
首先需要介绍一个比较重要的概念:N-Gram距离。
(1)N-gram距离
它是表示,两个字符串s,t分别利用N-Gram语言模型来表示时,则对应N-gram子串中公共部分的长度就称之为N-Gram距离。例如:假设有字符串s,那么按照N-Gram方法得到N个分词组成的子字符串,其中相同的子字符串个数作为N-Gram距离计算的方式。具体如下所示:
字符串:s=“ABC”,对字符串进行分词,考虑字符串首尾的字符begin和end,得到begin,A,B,C,end。这里采用二元语言模型,则有:(begin,A)、(A,B)、(B,C)、(C,end)。
字符串:t=“AB”,对字符串进行分词,考虑字符串首尾的字符begin和end,得到begin,A,B,end。这里采用二元语言模型,则有:(begin,A)、(A,B)、(B,end)。
此时,若求字符串t与字符串s之间的距离可以用M-(N-Gram距离)=0。
然而,上面的N—gram距离表示的并不是很合理,他并没有考虑两个字符串的长度,所以在此基础上,有人提出非重复的N-gram距离,公式如下所示:
上面的字符串距离重新计算为:
4+3-2*3=1
2、N-Gram在判断句子有效性上的应用
假设有一个字符串s=“ABC”,则对应的BI-Gram的结果如下:(begin,A)、(A,B)、(B,C)、(C,end)。则对应的出现字符串s的概率为:
P(ABC)=P(A|begin)*P(B|A)*P(C|B)*P(end|C)。
3、N-Gram在特征工程中的应用
在处理文本特征的时候,通常一个关键词作为一个特征。这也许在一些场景下可能不够,需要进一步提取更多的特征,这个时候可以考虑N-Gram,思路如下:
以Bi-Gram为例,在原始文本中,以每个关键词作为一个特征,通过将关键词两两组合,得到一个Bi-Gram组合,再根据N-Gram语言模型,计算各个Bi-Gram组合的概率,作为新的特征。
数据平滑:
N-gram的N NN越大,模型 Perplexity 越小,表示模型效果越好。这在直观意义上是说得通的,毕竟依赖的词越多,我们获得的信息量越多,对未来的预测就越准确。然而,语言是有极强的创造性的(Creative),当N NN变大时,更容易出现这样的状况:某些n-gram从未出现过,这就是稀疏问题。
n-gram最大的问题就是稀疏问题(Sparsity)。例如,在bi-gram中,若词库中有20k个词,那么两两组合(C220k C_{20k}^2C 20k2)就有近2亿个组合。其中的很多组合在语料库中都没有出现,根据极大似然估计得到的组合概率将会是0,从而整个句子的概率就会为0。最后的结果是,我们的模型只能计算零星的几个句子的概率,而大部分的句子算得的概率是0,这显然是不合理的。
因此,我们要进行数据平滑(data Smoothing),数据平滑的目的有两个:一个是使所有的N-gram概率之和为1,使所有的n-gram概率都不为0。它的本质,是重新分配整个概率空间,使已经出现过的n-gram的概率降低,补充给未曾出现过的n-gram。
N-gram的进化版:NNLM
NNLM 即 Neural Network based Language Model,由Bengio在2003年提出,它是一个很简单的模型,由四层组成,输入层、嵌入层、隐层和输出层。模型接收的输入是长度为n nn的词序列,输出是下一个词的类别。首先,输入是单词序列的index序列,例如单词 I 在字典(大小为∣V∣ |V|∣V∣)中的index是10,单词 am 的 index 是23, Bengio 的 index 是65,则句子“I am Bengio”的index序列就是 10, 23, 65。嵌入层(Embedding)是一个大小为∣V∣×K |V|\times K∣V∣×K的矩阵,从中取出第10、23、65行向量拼成3×K 3\times K3×K的矩阵就是Embedding层的输出了。隐层接受拼接后的Embedding层输出作为输入,以tanh为激活函数,最后送入带softmax的输出层,输出概率。
NNLM最大的缺点就是参数多,训练慢。另外,NNLM要求输入是定长n nn,定长输入这一点本身就很不灵活,同时不能利用完整的历史信息。

Word2Vec
Word2Vec解决的问题已经和上面讲到的N-gram、NNLM等不一样了,它要做的事情是:学习一个从高维稀疏离散向量到低维稠密连续向量的映射。该映射的特点是,近义词向量的欧氏距离比较小,词向量之间的加减法有实际物理意义。Word2Vec由两部分组成:CBoW和Skip-Gram。其中CBoW的结构很简单,在NNLM的基础上去掉隐层,Embedding层直接连接到Softmax,CBoW的输入是某个Word的上下文(例如前两个词和后两个词),Softmax的输出是关于当前词的某个概率,即CBoW是从上下文到当前词的某种映射或者预测。Skip-Gram则是反过来,从当前词预测上下文,至于为什么叫Skip-Gram这个名字,原因是在处理过程中会对词做采样。
袋連続-のワードモデル(CBOW)
(Nワードの各々に対する)単語モデル予測現在の単語の文脈をCBOW。n = 2の場合、以下に示すようなモデルは:

より具体的には、コンテキスト語入力シーケンスを考慮することなく、CBOWワードは、現在の単語の文脈における予測単語の平均ベクトルです。すなわち:
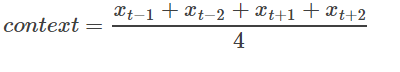
最初の単語、分類スコア(スコア)ベクトルz = U *コンテキスト、ソフトマックスY、多クラス分類のクロスエントロピーを用いた損失関数を用いて、最終的な分類のための単語ベクトルXTここで、T。
スキップ-gramモデル
CBOWの利点は、ノイズが除去された単語ベクトル平滑化中の単語の文脈で配布されるので、小さなデータセットに有効です。スキップグラム法、ワード内のそのコンテキストの予測を、現在のワードのコンテキストのサンプル数を得るために、より大きなデータセットで有用。

上記のように、特定のアプローチは、スキップグラムモデル、ソフトマックスによって得られた2Nその次にワードベクトルワードのワードベクトル2Nにマッピングワード(2N前と現在の入力ワードの各々の後にn個の単語を表す)は、あります分類値と言葉を失います。