1.の.textファイル形式の.textファイル形式に.xmlファイルは、行が物品であります
gensim.corpora インポートWikiCorpus input_file_name = ' /Users/admin/A_NLP/data/zhwiki-20190720-pages-articles-multistream.xml.bz2 ' output_file_nameに = ' wiki.cn.txt ' INPUT_FILE = WikiCorpus(input_file_name、lemmatize =偽、辞書= {}) のoutput_file =オープン(output_file_nameに、' W '、符号化= " UTF-8 " ) カウント = 0の ためのテキストに(input_file.get_texts): output_file.write(' '.join(テキスト)+ ' \ N- ' ) COUNT = COUNTの+ 1。 IF COUNT%で10000 == 0: 印刷(' %dは、現在処理されたデータ'%COUNT)
input_file.close() output_file.close()
2.コーパスの行は、複雑で、単純な、きれいな、単語を回します
インポート再 インポートopencc インポートjiebaの CC = opencc.OpenCC(' T2S ' ) FRオープン(= ' wiki.cn.txt '、' R ' ) FW =オープン(' wiki.sen.txt '、' + ' ) のためのラインFR: simple_format = cc.convert(ライン)#繁转简 zh_list = re.findall(U " [\ u4e00- \ u9fa5] + "、simple_format) #中国の非洗浄したデータ 文= [] のための short_sentence でzh_list: 文 + = リスト(jieba.cut(cc.convert(short_sentence))) fw.write(' ' .join(文)+ ' \ N- ' ) FR。クローズ使用() ()をfw.close
ファイル処理されたビューの最初のラインアウト3.印刷
フィート(=オープン「wiki.sen.txt 」、「R 」) のためのラインでフィート: プリント(行) ブレーク

4.訓練ベクトルワードとモデルを保存
インポートマルチ から gensim.modelsはインポートWord2Vecを から gensim.models.word2vec インポートLineSentence input_file_name = ' wiki.sen1k.txt ' model_file_name = ' wiki_min_count500.model ' モデル = Word2Vec(LineSentence(input_file_name)、 サイズ = 100、 #1 词向量长度 ウィンドウ= 5 、 min_count = 500 、 労働 = multiprocessing.cpu_count()) model.save(model_file_name)
5.テストいくつかの単語、最も類似した単語を見つけるために10
gensim.models インポートWord2Vec wiki_model = Word2Vec.load(' wiki_min_count500.model ' ) テスト = [ ' 文学'、' 雨'、' 車'、' モンスター'、' 幾何学'、' 故宮' ] のための単語でテスト: RES = wiki_model.most_similar(ワード) を印刷(ワード) を印刷(RES)

6.複数のベクトルを参照してください。
wiki_model.wv['文学']

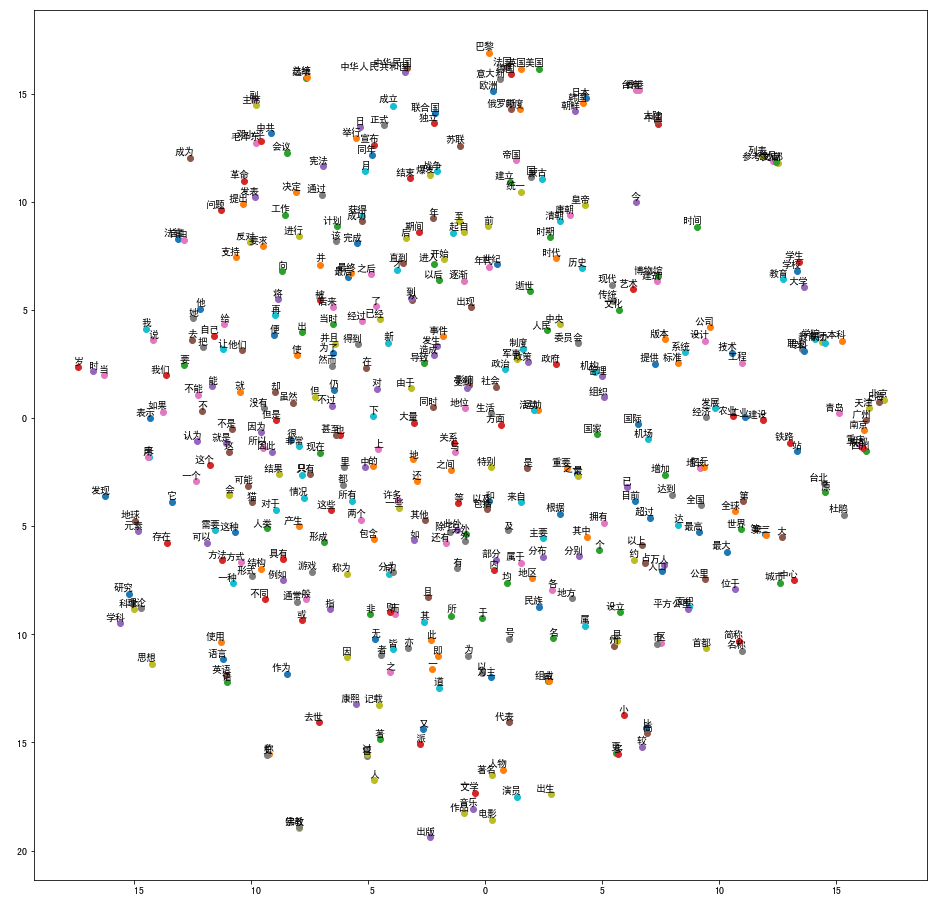
7.向量可视化,利用TSNE工具,将词向量降维,降维的原理是使得原本距离相近的向量降维后距离尽可能近,原本距离较远的向量降维后距离尽可能远
from sklearn.manifold import TSNE import matplotlib.pyplot as plt %matplotlib inline def tsne_plot(model): "Creates and TSNE model and plots it" labels = [] tokens = [] for word in model.wv.vocab: tokens.append(model[word]) labels.append(word) tsne_model = TSNE(perplexity=40, n_components=2, init='pca', n_iter=2500, random_state=23) new_values = tsne_model.fit_transform(tokens) x = [] y = [] for value in new_values: x.append(value[0]) y.append(value[1]) plt.figure(figsize=(16, 16)) for i in range(len(x)): plt.scatter(x[i],y[i]) plt.annotate(labels[i], xy=(x[i], y[i]), xytext=(5, 2), textcoords='offset points', ha='right', va='bottom') plt.show()
wiki_model = Word2Vec.load('wiki_min_count500.model') tsne_plot(wiki_model)
第一张图是用所有语料训练处的模型,包含的词语较多,因此成了一个大墨团;由于simhei.ttf文件没有替换,该有的中文文字没有显示出来

第二张图使用了前1w行数据作为语料库训练,在相应位置替换掉了simhei.ttf文件,是以下效果:

为了看的更清晰一点,第三章图使用的是前1000行数据作训练,效果如下: