記事ディレクトリ
導入
言語モデルは、一連のテキスト内の次の単語または文字の確率分布を予測するために使用されるモデルです。文法、文構造、文脈情報など、言語構造の特定の側面をキャプチャできます。従来の言語モデルは通常、N グラム手法または隠れマルコフ モデルを使用しますが、これらのモデルは長距離の依存関係や複雑な意味情報をキャプチャできないことがよくあります。
1. 言語モデルとは何ですか
平たく言えば、
言語モデルは文が「合理的」か「人間的」かを評価します。
数学的には、
P (今日の天気は良い) > P (今日の悪天候)
言語モデルがテキストの計算に使用されます。文の確率
2. 言語モデルの主な目的
2.1 言語モデル - 音声認識
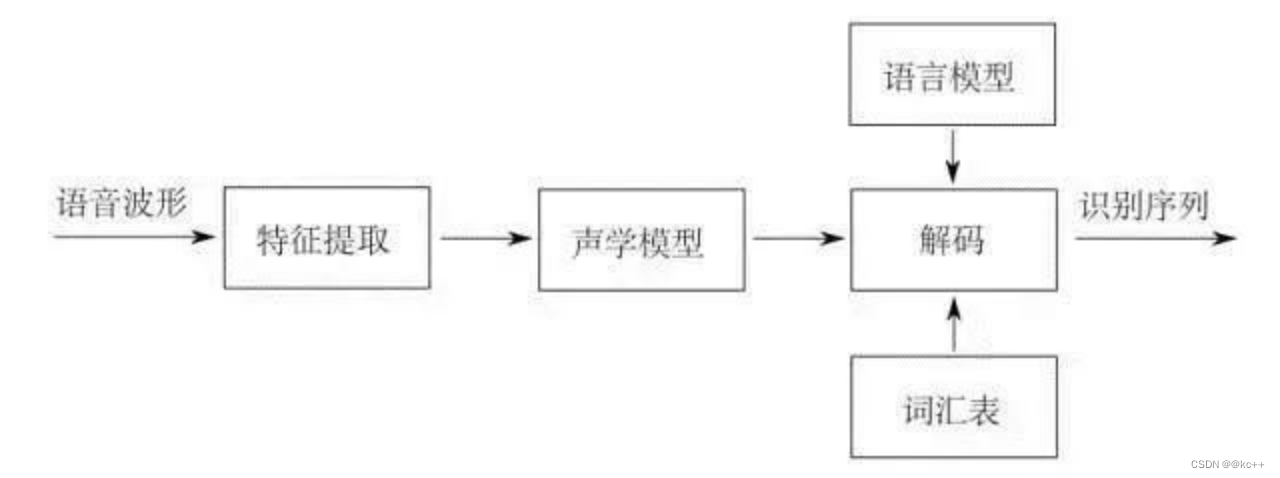
- 音声認識: サウンド -> テキスト
- 音は波です
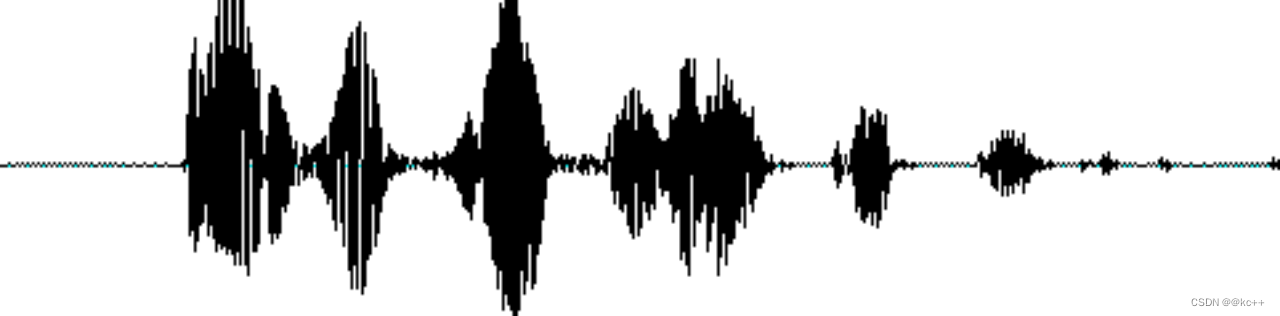
- 波形を時間周期に応じて多数のフレーム(25ms など)に分割します。
- 次に、音響特徴抽出を実行し、各フレームをベクトルに変換します。
- 音響特徴抽出後のベクトルを入力とし、音響モデルを用いて音素を予測する
- 音素はピンインに似ていますが、声調を考慮する必要があります
- 音素シーケンスは複数のテキストシーケンスに対応し、言語モデルは文を形成する確率が最も高いシーケンスを選択します。
- ビームサーチまたはビタビを使用してデコードする
- 音声認識図
2.2 言語モデル - 手書き認識

- 認識モデルは、画像内のテキストを候補漢字に変換し(一般に、位置決めと認識の 2 つのステップに分かれます)、その後、言語モデルが文を形成する確率が最も高いシーケンスを選択します。
2.3 言語モデル - 入力方法
- 入力はピンイン配列であり、各ピンインには当然複数の候補漢字があり、言語モデルに従って確率の高い配列が選択されます。
- 入力方法は非常に詳細な作業であり、言語モデルの基本アルゴリズムに基づいて、よくあるタイプミス、よくある発音の間違い、ピンインの略語、中国語と英語の混合、出力記号、ユーザーの習慣などを考慮する必要があります。
- 手書き入力方式、音声入力方式は同じです
3. 言語モデルの分類
- 統計的言語モデルに基づく
- コーパスの単語頻度、単語順序、および単語の共起の統計
- 言語モデルを取得するための関連確率を計算します。
- 代表者:N-gram言語モデル
- ニューラルネットワークに基づく言語モデル
- 設定されたネットワーク構造に従ってコーパスを使用してモデルをトレーニングします
- 代表的なもの:LSTM言語モデル、BERTなど
- 自動回帰言語モデル
- トレーニング時にコンテキストからコンテキストを予測 (またはその逆)
- 一方向モデル。片側配列情報のみを使用します。
- 代表者:エヌグラム、エルモ
- 自動エンコード言語モデル
- トレーニング時にシーケンス内の任意の場所の文字を予測します
- コンテキスト情報を吸収する双方向モデル
- 代表者:バート
4. N-gram言語モデル
N グラム言語モデルは、最初の N-1 個の単語または文字に基づいて、次の単語または文字の確率を予測するために使用される基本的な言語モデルです。このモデルは、テキストを単語または文字の順序付けされたシーケンスとして認識し、n 番目の単語が最初の N-1 単語にのみ関連していると想定します。
たとえば、バイグラム (2 グラム) モデルでは、各単語の出現はその前の単語にのみ依存します。たとえば、「私は食べます」の後に「リンゴ」が続く確率は、P(リンゴ | 私は食べます) と表すことができます。
アドバンテージ:
- 簡単な計算: 単語の頻度と条件付き単語の頻度をカウントするだけです。
- 実装が簡単: 複雑なアルゴリズムは必要ありません。
欠点:
- スパース性の問題: N が増加すると、モデルに必要な記憶領域が急激に増加し、ほとんどの N グラムの組み合わせが実際のデータに存在しない可能性があります。
- コンテキスト制限: N-1 単語のコンテキスト情報のみをキャプチャできます。
これらの制限にもかかわらず、N グラム モデルは、そのシンプルさと効率性により、スペル チェック、音声認識、機械翻訳など、多くのアプリケーション シナリオで依然として広く使用されています。
文の確率を計算するにはどうすればよいですか?
- 文には S を使用し、個々の単語またはフレーズには w を使用します
- S = w1w2w3w4w5…wn
- P(S) = P(w1,w2,w3,w4,w5…wn)
- 文章確率 → 単語 W1 ~ Wn が連続して出現する確率
- P(w1,w2,w3,…,wn) = P(w1)P(w2|w1)P(w3|w1,w2)…P(wn|w1,…,wn-1)
言葉で
- P(今日の天気は良いです) = P(今日)*P(今日|今日) *P(今日|今日) *P(ガス|今日の日) *P(違う|今日の天気) *P(間違っています|今日の天気はですない)
言葉で
- P(今日の天気は良い) = P(今日)*P(天気|今日) *P(いい|今日の天気)
P(今日)を計算するにはどうすればよいですか?
- P(today) = Count(today) / Count_total コーパス内の単語の総数
- P(天気|今日) = カウント(今日の天気) / カウント(今日)
- P(良い|今日の天気) = カウント(今日の天気は良い) / カウント(今日の天気)
- 2 タプル: 今日の天気 2 グラム
- 三つ子:今日は天気がいいです 3グラム
難易度: 文章が多すぎます!
- どの言語でも、N グラムの数は多すぎてすべてを網羅できないため、簡略化する必要があります。
マルコフ仮説
- P(wn|w1,…,wn-1) ≈ P(wn|wn-3,wn-2,wn-1)
- n 番目の単語が出現する確率は、その前の限られた単語によってのみ影響されると仮定します。
- P(今日の天気は良い) = P(今日)*P(日|今日) *P(日|今日) *P(ガス|毎日) *P(いいえ|天気) *P(間違っ|いいえ)
マルコフ仮定の欠陥:
- n 番目の単語に影響を与える要因は、はるか先の
長距離依存症に現れる可能性があります例: マルコフの生涯についての本を読みました
マルコフの生涯についての映画を観ました
マルコフの生涯についての話を聞きました
- n 番目の単語に影響を与える要素がその後に現れる場合があります
- n 番目の単語に影響を与える要素はテキストに含まれていない可能性があります
ただし、マルコフ仮定の下でも非常に効率的なモデルを取得できます。
コーパス:
今日の天気は良いです P(今日) = 3 / 12 = 1/4
明日の天気は良いです P(天気 | 今日) = 2 / 3
今日の天気は良くありません P (いい | 今日の天気) = 1 / 2
今日は晴れです P (良い天気|天気) = 2/3
3 グラムモデル
P(今日の良い天気) = P(今日)*P(天気|今日)*P(良い|今日の天気) = 1/12 2 グラムモデル
P
(今日はいい天気) = P(今日)*P(天気|今日)*P(いい|天気) = 1 / 9
コーパス:
今日の天気は良いです P(今日) = 3 / 12 = 1/4
明日の天気は良いです P(天気 | 今日) = 2 / 3
今日の天気は良くありません P (いい | 今日の天気) = 1 / 2
今日は晴れです P (良い |天気) = 2/3
質問: コーパスに出現していない単語または ngram の確率を与えるにはどうすればよいですか?
P(今日の悪天候) = P(今日)*P(天気|今日)*P(悪|天気)
- 平滑化問題(平滑化)
- 理論的には、単語の任意の組み合わせによって文が形成される確率はゼロではないはずです。
- 目に見えない単語や ngram に確率を割り当てる方法は平滑化の問題です
- 割引問題 (ディスカウント) とも呼ばれます。
4.1 N-gram言語モデル - スムージング法
- 後退する
三重項 abc が存在しない場合、bc バイナリ群の確率を探します。
P(c | ab) = P(c | b) * Bow(ab)
Bow(ab) は、バイナリ群 ab のフォールバック確率と呼ばれます
。フォールバック確率を計算するにはさまざまな方法があり、定数として設定することもできます
。フォールバックは、シーケンス abcd
P(d | abc) = P(d | bc) * Bow(abc)
Pのように反復的に実行できます。 (d | bc) = P( d | c) * ボウ(bc)
P(d | c ) = P(d) * ボウ©
P(単語)が存在しない場合の対処方法
1 を加算するスムーズな加算
1 グラムの確率 P(単語) = Count(word)+1/Count(total_word)+V
V は語彙サイズ
高い場合も可能-順序確率
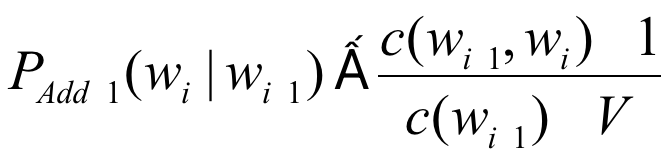
低頻度の単語を
予測で出現した未確認の単語に置き換え、さらにそれらを
1 つの単語に置き換えて prophecy -> 1 つの単語を
P に (|1 つの単語を)
これは、nlp が未登録の単語 (OOV) を処理する一般的な方法です。
補間 バック
オフ平滑化をヒントに、高次の ngram 確率を計算する際、低次の ngram 確率値も同時に考慮され、最終結果は補間によって与えられます。
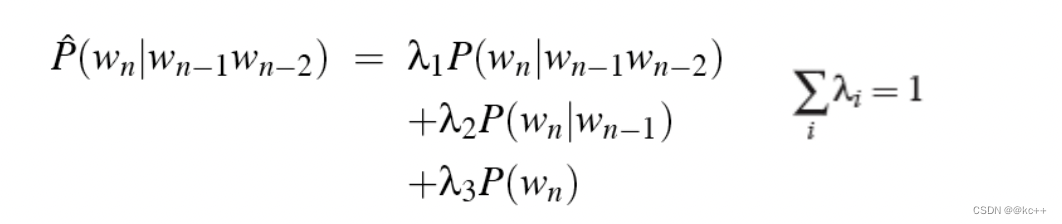
実践により、この方法の効果を改善できることが証明されました。
検証セットのパラメータを調整することで λ を決定できます。
4.2 ngramコード
import math
from collections import defaultdict
class NgramLanguageModel:
def __init__(self, corpus=None, n=3):
self.n = n
self.sep = "_" # 用来分割两个词,没有实际含义,只要是字典里不存在的符号都可以
self.sos = "<sos>" #start of sentence,句子开始的标识符
self.eos = "<eos>" #end of sentence,句子结束的标识符
self.unk_prob = 1e-5 #给unk分配一个比较小的概率值,避免集外词概率为0
self.fix_backoff_prob = 0.4 #使用固定的回退概率
self.ngram_count_dict = dict((x + 1, defaultdict(int)) for x in range(n))
self.ngram_count_prob_dict = dict((x + 1, defaultdict(int)) for x in range(n))
self.ngram_count(corpus)
self.calc_ngram_prob()
#将文本切分成词或字或token
def sentence_segment(self, sentence):
return sentence.split()
#return jieba.lcut(sentence)
#统计ngram的数量
def ngram_count(self, corpus):
for sentence in corpus:
word_lists = self.sentence_segment(sentence)
word_lists = [self.sos] + word_lists + [self.eos] #前后补充开始符和结尾符
for window_size in range(1, self.n + 1): #按不同窗长扫描文本
for index, word in enumerate(word_lists):
#取到末尾时窗口长度会小于指定的gram,跳过那几个
if len(word_lists[index:index + window_size]) != window_size:
continue
#用分隔符连接word形成一个ngram用于存储
ngram = self.sep.join(word_lists[index:index + window_size])
self.ngram_count_dict[window_size][ngram] += 1
#计算总词数,后续用于计算一阶ngram概率
self.ngram_count_dict[0] = sum(self.ngram_count_dict[1].values())
return
#计算ngram概率
def calc_ngram_prob(self):
for window_size in range(1, self.n + 1):
for ngram, count in self.ngram_count_dict[window_size].items():
if window_size > 1:
ngram_splits = ngram.split(self.sep) #ngram :a b c
ngram_prefix = self.sep.join(ngram_splits[:-1]) #ngram_prefix :a b
ngram_prefix_count = self.ngram_count_dict[window_size - 1][ngram_prefix] #Count(a,b)
else:
ngram_prefix_count = self.ngram_count_dict[0] #count(total word)
# word = ngram_splits[-1]
# self.ngram_count_prob_dict[word + "|" + ngram_prefix] = count / ngram_prefix_count
self.ngram_count_prob_dict[window_size][ngram] = count / ngram_prefix_count
return
#获取ngram概率,其中用到了回退平滑,回退概率采取固定值
def get_ngram_prob(self, ngram):
n = len(ngram.split(self.sep))
if ngram in self.ngram_count_prob_dict[n]:
#尝试直接取出概率
return self.ngram_count_prob_dict[n][ngram]
elif n == 1:
#一阶gram查找不到,说明是集外词,不做回退
return self.unk_prob
else:
#高于一阶的可以回退
ngram = self.sep.join(ngram.split(self.sep)[1:])
return self.fix_backoff_prob * self.get_ngram_prob(ngram)
#回退法预测句子概率
def calc_sentence_ppl(self, sentence):
word_list = self.sentence_segment(sentence)
word_list = [self.sos] + word_list + [self.eos]
sentence_prob = 0
for index, word in enumerate(word_list):
ngram = self.sep.join(word_list[max(0, index - self.n + 1):index + 1])
prob = self.get_ngram_prob(ngram)
# print(ngram, prob)
sentence_prob += math.log(prob)
return 2 ** (sentence_prob * (-1 / len(word_list)))
if __name__ == "__main__":
corpus = open("sample.txt", encoding="utf8").readlines()
lm = NgramLanguageModel(corpus, 3)
print("词总数:", lm.ngram_count_dict[0])
print(lm.ngram_count_prob_dict)
print(lm.calc_sentence_ppl("e f g b d"))
4.3 言語モデルの評価指標
- 困惑
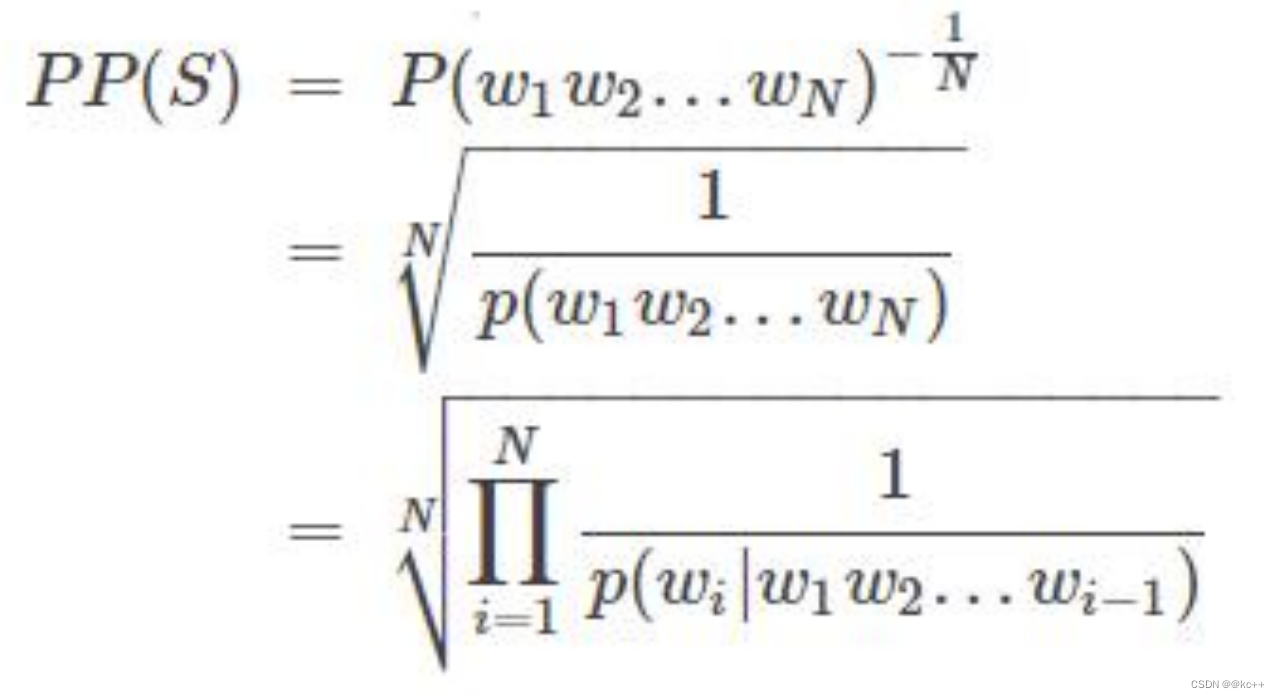
- PPL値は文確率に反比例する
一般に、PPL の計算には合理的な対象テキストが使用されますが、PPL 値が低い場合は、文を構成する確率が高いことを意味し、言語モデルによって文の合理性が判断されます。これは優れた言語モデルです。
- 分数積の代わりに対数合計を使用した別の PPL
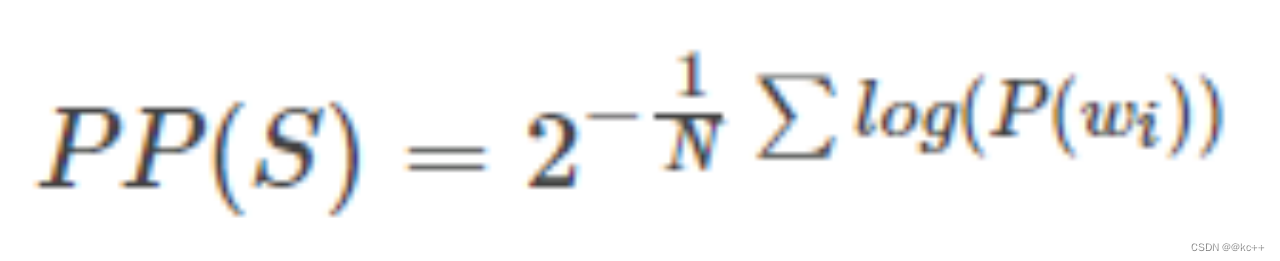
- 本質は同じで文確率に反比例する
- 考察: PPL が小さいほど、言語モデルの効果は高くなります。この結論は正しいでしょうか?
- 文の確率は相対値です!
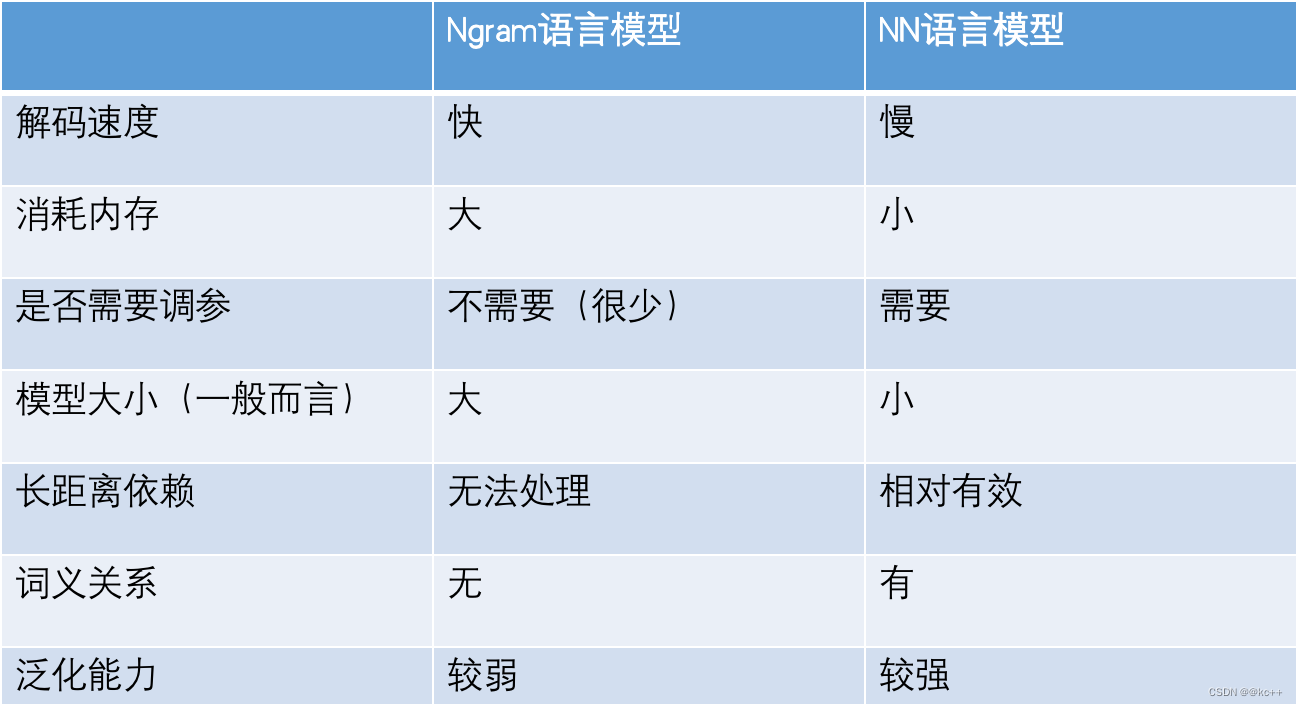
4.4 2 種類の言語モデルの比較
5. ニューラルネットワーク言語モデル
- ベンジオら。2003年
- ngram モデルと同様に、最初の n 単語を使用して次の単語を予測します
- 単語リストの確率分布を出力します。
- 単語ベクトルの副産物を取得します
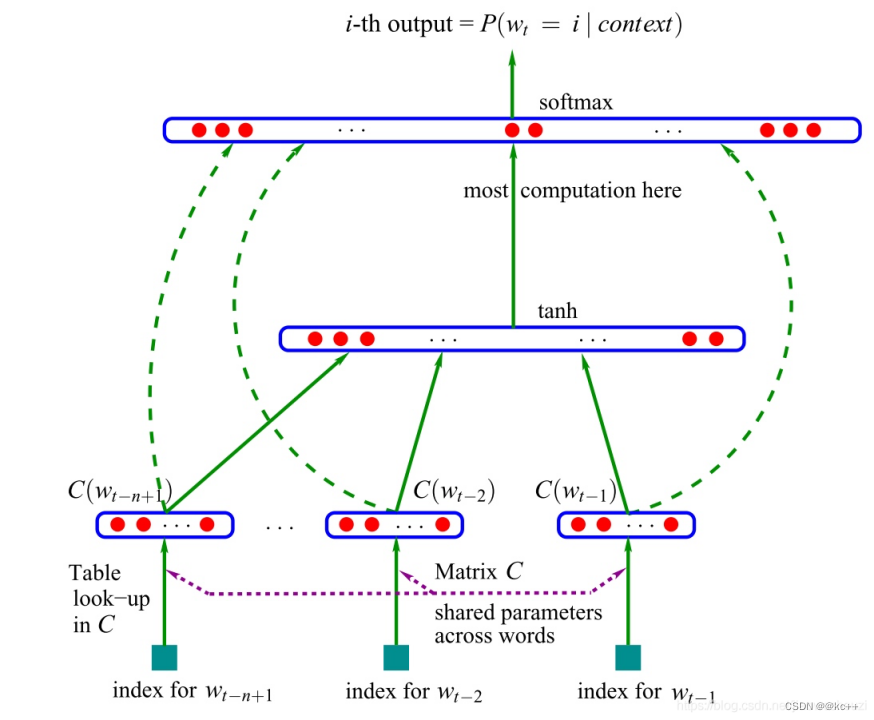
- 関連研究の発展に伴い、隠れ層モデル構造の複雑さは増加し続けています。
- DNN -> CNN/RNN -> LSTM/GRU -> トランス
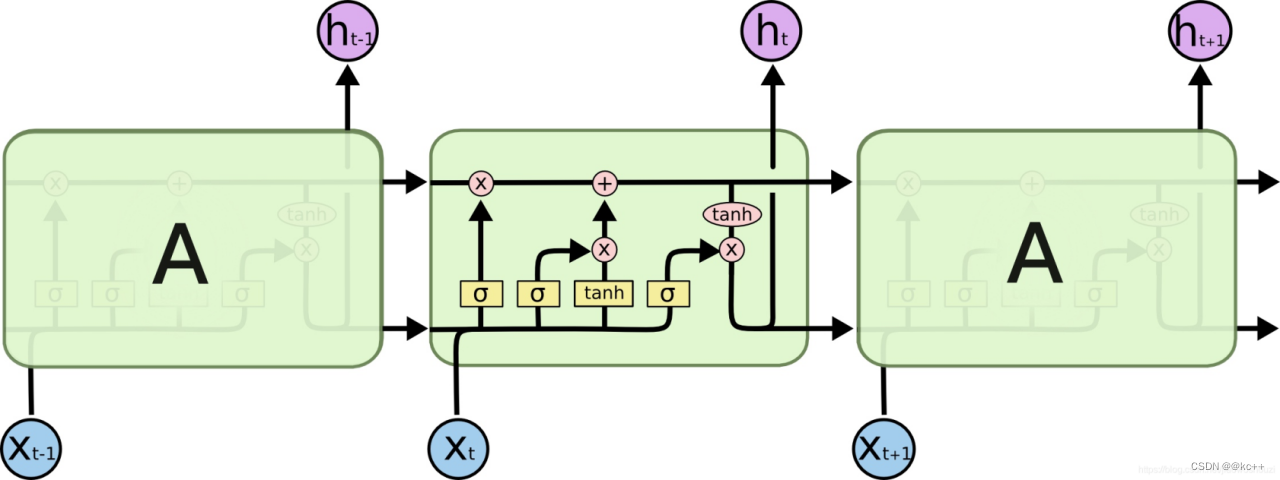
- Devlin 他、2018 BERT の誕生
- 主な機能: 言語モデルをトレーニングするために次の単語を予測する方法を使用する代わりに、テキスト内にランダムに含まれる単語を予測します。
- この方法はMLM(マスクされた言語モデル)と呼ばれます
- 実際、この方法は非常に早い段階で提案されたもので、bert のオリジナルではありませんでした。
コード
#coding:utf8
import torch
import torch.nn as nn
import numpy as np
import math
import random
import os
import re
import matplotlib.pyplot as plt
"""
基于pytorch的rnn语言模型
"""
class LanguageModel(nn.Module):
def __init__(self, input_dim, vocab):
super(LanguageModel, self).__init__()
self.embedding = nn.Embedding(len(vocab) + 1, input_dim)
self.layer = nn.RNN(input_dim, input_dim, num_layers=2, batch_first=True)
self.classify = nn.Linear(input_dim, len(vocab) + 1)
self.dropout = nn.Dropout(0.1)
self.loss = nn.functional.cross_entropy
#当输入真实标签,返回loss值;无真实标签,返回预测值
def forward(self, x, y=None):
x = self.embedding(x) #output shape:(batch_size, sen_len, input_dim)
x, _ = self.layer(x) #output shape:(batch_size, sen_len, input_dim)
x = x[:, -1, :] #output shape:(batch_size, input_dim)
x = self.dropout(x)
y_pred = self.classify(x) #output shape:(batch_size, input_dim)
if y is not None:
return self.loss(y_pred, y)
else:
return torch.softmax(y_pred, dim=-1)
#读取语料获得字符集
#输出一份
def build_vocab_from_corpus(path):
vocab = set()
with open(path, encoding="utf8") as f:
for index, char in enumerate(f.read()):
vocab.add(char)
vocab.add("<UNK>") #增加一个unk token用来处理未登录词
writer = open("vocab.txt", "w", encoding="utf8")
for char in sorted(vocab):
writer.write(char + "\n")
return vocab
#加载字表
def build_vocab(vocab_path):
vocab = {
}
with open(vocab_path, encoding="utf8") as f:
for index, line in enumerate(f):
char = line[:-1] #去掉结尾换行符
vocab[char] = index + 1 #留出0位给pad token
vocab["\n"] = 1
return vocab
#加载语料
def load_corpus(path):
return open(path, encoding="utf8").read()
#随机生成一个样本
#从文本中截取随机窗口,前n个字作为输入,最后一个字作为输出
def build_sample(vocab, window_size, corpus):
start = random.randint(0, len(corpus) - 1 - window_size)
end = start + window_size
window = corpus[start:end]
target = corpus[end]
# print(window, target)
x = [vocab.get(word, vocab["<UNK>"]) for word in window] #将字转换成序号
y = vocab[target]
return x, y
#建立数据集
#sample_length 输入需要的样本数量。需要多少生成多少
#vocab 词表
#window_size 样本长度
#corpus 语料字符串
def build_dataset(sample_length, vocab, window_size, corpus):
dataset_x = []
dataset_y = []
for i in range(sample_length):
x, y = build_sample(vocab, window_size, corpus)
dataset_x.append(x)
dataset_y.append(y)
return torch.LongTensor(dataset_x), torch.LongTensor(dataset_y)
#建立模型
def build_model(vocab, char_dim):
model = LanguageModel(char_dim, vocab)
return model
#计算文本ppl
def calc_perplexity(sentence, model, vocab, window_size):
prob = 0
model.eval()
with torch.no_grad():
for i in range(1, len(sentence)):
start = max(0, i - window_size)
window = sentence[start:i]
x = [vocab.get(char, vocab["<UNK>"]) for char in window]
x = torch.LongTensor([x])
target = sentence[i]
target_index = vocab.get(target, vocab["<UNK>"])
if torch.cuda.is_available():
x = x.cuda()
pred_prob_distribute = model(x)[0]
target_prob = pred_prob_distribute[target_index]
prob += math.log(target_prob, 10)
return 2 ** (prob * ( -1 / len(sentence)))
def train(corpus_path, save_weight=True):
epoch_num = 10 #训练轮数
batch_size = 128 #每次训练样本个数
train_sample = 10000 #每轮训练总共训练的样本总数
char_dim = 128 #每个字的维度
window_size = 6 #样本文本长度
vocab = build_vocab("vocab.txt") #建立字表
corpus = load_corpus(corpus_path) #加载语料
model = build_model(vocab, char_dim) #建立模型
if torch.cuda.is_available():
model = model.cuda()
optim = torch.optim.Adam(model.parameters(), lr=0.001) #建立优化器
for epoch in range(epoch_num):
model.train()
watch_loss = []
for batch in range(int(train_sample / batch_size)):
x, y = build_dataset(batch_size, vocab, window_size, corpus) #构建一组训练样本
if torch.cuda.is_available():
x, y = x.cuda(), y.cuda()
optim.zero_grad() #梯度归零
loss = model(x, y) #计算loss
watch_loss.append(loss.item())
loss.backward() #计算梯度
optim.step() #更新权重
print("=========\n第%d轮平均loss:%f" % (epoch + 1, np.mean(watch_loss)))
if not save_weight:
return
else:
base_name = os.path.basename(corpus_path).replace("txt", "pth")
model_path = os.path.join("model", base_name)
torch.save(model.state_dict(), model_path)
return
#训练corpus文件夹下的所有语料,根据文件名将训练后的模型放到莫得了文件夹
def train_all():
for path in os.listdir("corpus"):
corpus_path = os.path.join("corpus", path)
train(corpus_path)
if __name__ == "__main__":
# build_vocab_from_corpus("corpus/all.txt")
# train("corpus.txt", True)
train_all()
6. 言語モデルの適用
6.1 言語モデルの適用 - 話者の分離
- スピーチの内容で発言者を判断する
- 録音された会話の文字を判断するために言語認識システムで一般的に使用されます。
- 顧客サービス対話の録音など、エージェントまたは顧客を判断する
- 話し手をアクセントで判断する
- 翻訳者: この不運な家にゴキブリがいるなんて想像できますか? これは本当に怖いです!
- 香港と台湾の訛り:どうしてこうなるの?
- Northeast Flavor: 私がそのようなことについて話すのは珍しいことではありませんが、圧倒されます
- 基本的にはテキスト分類タスクです
- カテゴリごとに、カテゴリ コーパスを使用して言語モデルをトレーニングします。
- 新しい入力テキストの場合、すべての言語モデルを使用して文の確率を計算します。
- 最も確率の高いカテゴリを予測カテゴリとして選択します
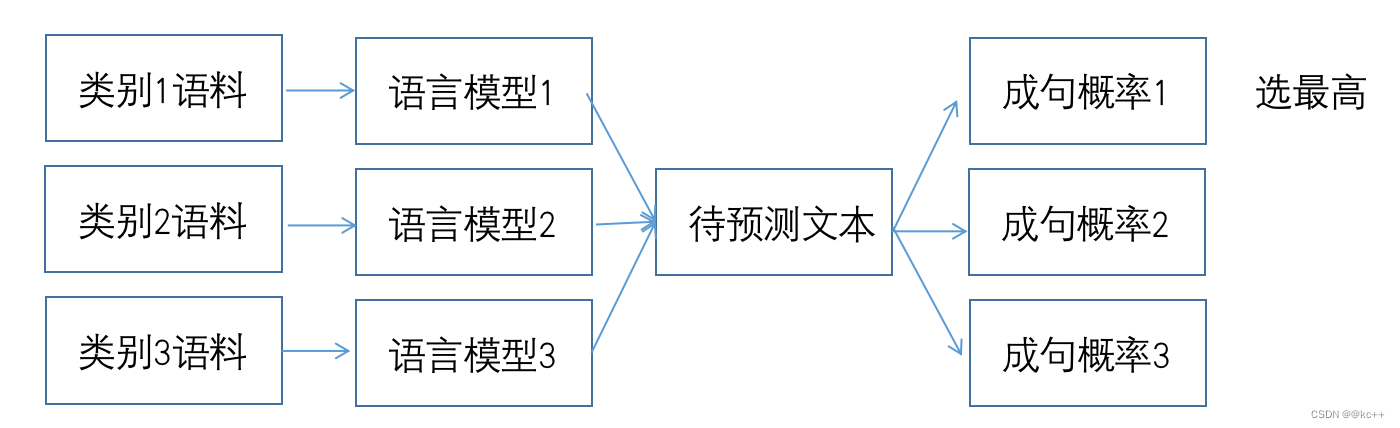
- ベイジアン、rf、ニューラルネットワークなどの一般的なテキスト分類モデルと比較します。
- アドバンテージ:
- 各カテゴリーのモデルは互いに独立しており、サンプルの不均衡やサンプル誤差は他のモデルに影響を与えません。
- 古いカテゴリの効果に影響を与えることなく、いつでも新しいカテゴリを追加できます。
- 効果の面: 一般的には大きな利点はありません
- 効率の観点: 一般に、統一分類モデルよりも低い
6.2 言語モデルの適用 - テキストエラーの修正
- テキスト内の間違いを修正する
- のように:
- 今日行きました暗い扉は人々の英雄を見つめる覚えて記念碑
- 今日は天安門に行って人民英雄記念碑を見てきました
- 間違いは同音異義語や類似した文字などである可能性があります。
- 単語ごとに混同された単語のセットを作成する
- 文全体が文である確率を計算する
- 元の文の単語を混同された単語セットの単語に置き換え、確率を再計算します
- この文のスコアが元の文と比較して一定のしきい値を超えた場合、最もスコアの高い候補文を選択します
- 次の単語について、文の終わりまで手順 3 ~ 4 を繰り返します。

このアプローチにはいくつかの欠点があります。
- 単語が多い問題と少ない問題が解けない
- 閾値の設定は非常に分かりにくく、大きすぎると誤り訂正効果が得られず、小さすぎると大量の置換が発生し、本来の意味が変わってしまう可能性があります。文
- 紛らわしい単語のリストを完成させるのは難しい
- 言語モデルのドメインは変更結果に影響します
- タイプミスが続くと、エラー修正の難易度が大幅に上がります。
- 業界の一般的な慣行:
- 特定の単語を変更する必要があるかどうかを判断するためにのみ、変更ホワイト リストを制限する
- たとえば、shang wu と発音されたすべての断片についてのみ、それを「ビジネス」に変更するかどうかを計算し、残りは無視します。
- 深層学習モデルの場合、タイプミスは許容されるため、エラー修正自体の重要性は低下しており、通常は表示タスクにのみ使用されます。
6.3 言語モデルの適用 - デジタル正規化
- テキストの数値部分を読みやすいスタイルに変換します。
- 言語認識システムの後にテキストを表示する場合によく使用されます。
- のように:
- 秦皇島港の石炭在庫は11月初旬に454万9000トンから773万4000トンに急増し、1999年以来の記録を更新した。
- 秦皇島港の石炭在庫は11月初旬に454万9000トンから773万4000トンに急増し、1999年以来の記録を更新した。
- 仕様に準拠するテキストをオリジナルのコーパスとしてデジタル形式で検索します
- 数値部分(任意形式)を正規表現で検索する
- 数字の部分を形式に合わせて<アラビア数字><漢数字><漢字連読>などのトークンに置き換えます。
- トークンを含むテキストを使用して言語モデルをトレーニングする
- 新しく入力されたテキストについても、正規表現を使用してデジタル部分を見つけ、各トークンをそれぞれ取り込み、言語モデルを使用して確率を計算します。
- 最も確率の高いトークンを最終的なデジタル形式として選択し、ルールに従って変換し、元のテキストを記入します

6.4 言語モデルの適用 - テキストマーキング
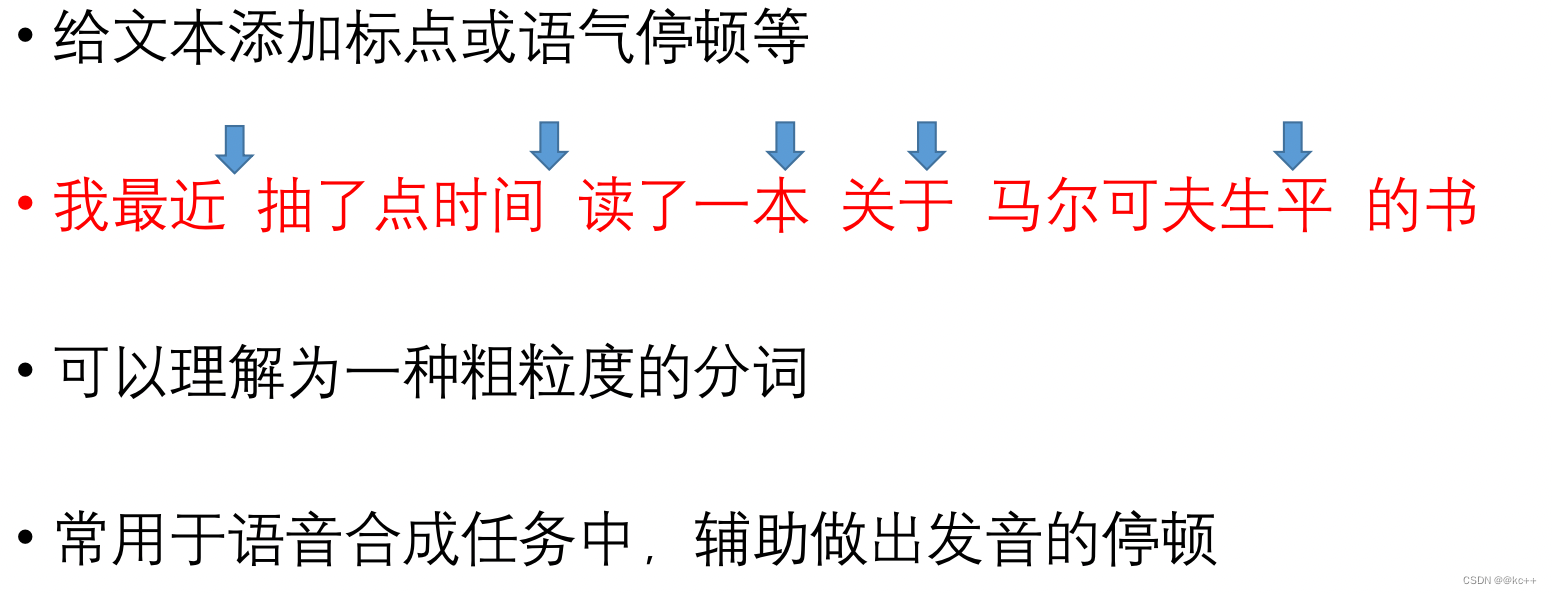

- 基本的にシーケンスのラベル付けタスク
- 単語の分割、テキストの句読点、テキストの段落の分割などのタスクも同様の方法で処理できます。
- 単語の分割または段落の分割に必要なトークンは 1 つだけです。点をマークする場合、複数の区切りトークンを使用して異なる句読点を表すことができます。
7. まとめ
- 言語モデルの中核となる機能は、文を形成する確率を計算することであり、この機能に依存して、さまざまな種類の NLP タスクを多数完了できます。
- 統計ベースの言語モデルとニューラル ネットワーク ベースの言語モデルには、それぞれ独自の使用シナリオがあります。一般的に、統計ベースのモデルの利点はデコード速度にあり、通常はニューラル ネットワーク モデルの方がパフォーマンスが優れています。
- 純粋に PPL を通じて言語モデルを評価することには限界があるため、下流のタスク効果を通じて全体的な評価を行う方が良いでしょう。
- アルゴリズムを深く理解することは、より多くの応用方法を発見するのに役立ちます。
- 一見単純に見える (間違っていても) 仮定が意味のある結果をもたらす可能性があり、実際、これは問題を単純化する一般的な方法です。