リレーショナルデータベースと非リレーショナルデータベース
急いによって2019年7月2日16時34分48秒
1.リレーショナルデータベース
1.1コンセプト
リレーショナルデータベースは、データベース内のデータを整理するためにリレーショナル・モデルの使用を指します。リレーショナル・モデルは、2次元テーブルのモデルを指すので、リレーショナルデータベースは、2次元テーブルとなるとの間のデータリンクによって構成されています。
テン現在主流のリレーショナルデータベース:MySQLのは、Microsoft SQL ServerやOracle、SQLiteの、MariaDB(MySQLのブランチ)、PostgreSQLの、Microsoft Accessの、Teradataの、SAP。
1.2構造
(1)の関係が2次元テーブルとして理解することができ、各関係が関係名を有し、多くの場合、テーブル名と言われています。
(2)タプル:しばしばデータベースの記録と呼ばれる、2次元テーブルの行として理解することができます。
(3)プロパティ:多くの場合、データベースのフィールドと呼ばれる、2次元テーブルとして理解することができます。
(4)フィールド:属性値の範囲、データベースの列に、すなわち限界値。
(5)キーワード:属性のセットは、多くの場合、1つ以上の列で構成プライマリ・データベースのキーと呼ばれる独特のタプルを、識別することができます。
(6)の関係モデル:関係の記述を意味します。形式は、名前の関係(1つのプロパティ、項目2、...、N性)は、データベースのテーブル構造であること。
1.3利点
①理解しやすい:2次元テーブルの構造は、論理の世界の概念に非常に近い、リレーショナルモデルはレベルが理解しやすいよう、他のモデルに比べてメッシュ。
②簡単に使用する:一般的なSQLリレーショナルデータベース言語は、操作が非常に便利です。(SQL共通言語)
③保守が容易:インテグリティ(エンティティ整合性、参照整合性の整合性とユーザ定義)の富を大幅にデータの冗長性と一貫性のないデータの確率を低減します。(保守が容易表構造)
1.4ボトルネック
①高同時読み取りおよび要件を記述します。ユーザーの同時実行サイトは非常に高く、多くの場合、2回目の読み出しあたり何千回に達すると書き込み要求を、従来のリレーショナルデータベース、ディスクI / Oは大きなボトルネックとなっています。
②大規模なデータの読み書きの高効率:サイトの毎日の生産は、リレーショナルデータベースのために、膨大であるデータの量は、効率が非常に低く、大量のデータを含むテーブル上のクエリです。
③高いスケーラビリティと可用性:データベースはスケールに最も困難なウェブベースの構造ときな単純なデータベースとWebサーバアプリケーションサーバなどのユーザーアプリケーションとトラフィックの量成長、しかし決してスケール性能と負荷容量とより多くのハードウェアおよびサービスノードを追加することによって。多くのサイトでは、データベース・システムのアップグレードや拡張が非常に苦痛で、24時間サービスを提供する必要があり、多くの場合、メンテナンスやダウンタイムのデータ移行が必要です。
1.5非本質的な機能
(1)サイトでは、リレーショナルデータベースの多くの機能が不要になった:
①トランザクションの整合性:多くのWeb2.0の物事は一方で、物事の一貫性を維持するためのオーバーヘッドがたくさんあるリレーショナルデータベースシステム読んで、一貫性が高くない書き込み。
②リアルタイムの読み取りおよび書き込み:リレーショナルデータベース、データがすぐにクエリを挿入した後、はい、あなたは、このデータを読み取ることができますが、多くのWebアプリケーションに対して、このような高いリアルタイムを必要としない、そのようなメッセージを送るなどその後、わずか数秒後に参照するか、このダイナミックなのにも10秒は完全に許容されています。
特にクエリに関連付けられたマルチテーブルで③複雑なSQL、:大規模データのWebシステムの任意の量は非常に大きなタブー関連クエリを複数のテーブルであり、データ分析、複雑なのSQLクエリ文の複合型、サイトの特にSNSタイプ(SNS具体的にソーシャル・ネットワーキング・ソフトウェアとソーシャル・ネットワーキング・サイトなどのソーシャル・ネットワーキング・サービス)を意味し、だけでなく、ビューのクラスの観点から製品の需要は、このような状況のために避けること。多くの場合、単一のプライマリキーテーブル、クエリ、および簡単な単一テーブルのクエリ条件ページング、SQL関数のみが大幅に弱体化。
(2)リレーショナルデータベースでは、主な理由の貧弱な性能が得られ、クエリに関連付けられたマルチテーブルであり、複雑なデータ型を複雑なSQLクエリステートメントを分析します。ACID特性データベースを確保するために、我々は、フォーマットされたデータ構造に格納されているそのパラダイム、リレーショナルデータベーステーブルの要件に応じて設計されることを試みなければなりません。各フィールドの組成物ではないすべてのフィールドが必要とされるが、データベースはすべてのフィールドに各タプルを割り当てられている場合、そのような構造は、テーブルスローガン間のリンクなどの操作を容易にすることができ、各タプル同じタプルであり、しかし、別の観点から、それはまた、リレーショナルデータベースのパフォーマンスのボトルネックの要因です。
注意:データベーストランザクションが持っている必要がありますACID特性を、ACIDは原子力原子性、一貫性の一貫性、絶縁絶縁、耐久性耐久性です。
2.非リレーショナルデータベース
2.1概念
NoSQLのは、もともと無SQL機能、軽量、オープンソースのリレーショナルデータベースに言及しました。回の開発ニーズと、私たちは「何のSQL」を望んませんでしたが、「何の関係」、つまり、私たちはしばしば、非リレーショナルデータベースについて話しています。2009明確なNoSQLのは、分散型非リレーショナルものを参照するために使用され、一般的にデータ・ストレージ・システムは、ACIDの原則を保証するものではありません従ってください。非リレーショナルデータベースの概念、例えば、キーと値のペアを格納するための、および構造が固定されていないが、各タプルは、必要に応じて、各タプルは、独自のキーと値のペアの一部を追加することができ、異なるフィールドを持つことができるので、あなたはしないでください固定された構成に限定されるもので、オーバーヘッドは、いくつかの時間と空間を減少させることができます。ように、リレーショナルデータベースは、クエリに関連付けられたマルチテーブルである必要はありませんようにこの方法では、ユーザーは、ユーザーに関するさまざまな情報を得るために、必要に応じて自分のニーズにフィールドを追加することができます。唯一の問合せキーに従って完了する必要が対応する値を取得します。しかし、彼はこのような状況のフィールドプロパティ値のために提供SQLクエリとして提供することができないいくつかの制約があるため、非リレーショナルデータベース、。そして、設計の整合性を反映することが難しいです。彼は、より複雑なクエリ、かなり多くの適切なSQLデータベースのために必要な、より単純なデータストレージ、データの一部にのみ適しています。
厳密な意味での非リレーショナルデータベースでは、データベースではなく、構造化データ記憶方法のコレクションは、文書またはキーと値のペアであってもよいです。
2.2分類
非リレーショナルデータベースは、ある特定のアプリケーション要件のために現れるので、特定の用途、高性能な特殊な非リレーショナルデータベース用されています。構造及び適用方法に応じて、以下のカテゴリに分けられる:
(1)高性能同時読み出し及びキー値データベースの書き込みのために:鍵データに格納されたデータベースの一種で、同様のデータベース全体として、各キーは一意の値に対応しています。持っているデータベース機能、高い同時読み取りと書き込みのパフォーマンスを。典型的な代表のRedis、東京内閣、フレア、アマゾン DynamoDBの、Memcachedの、マイクロソフトのAzureコスモスDB、Hazelcast。(2)大規模なデータ・アクセスのためのドキュメント指向データベースを:このようなデータベースの特徴は、あなたがすることができ、あるすぐに膨大な量のデータをクエリデータ。文書保管は、典型的には、主に、アプリケーション内で直接処理することができる、内部表現を使用して文書がキーストア内のプレーンテキストまたはリレーショナル・データベース・システムとして格納することができます。MongoDBは、アマゾンDynamoDBの、Couchbaseの、マイクロソフトに代表される AzureのコスモスDB、CouchDBの。JavamapmapJSON,而JSON
(3)分散データベースのスケーラビリティを向い:従来のリレーショナル・データベースは、特定のデータ状態へのアクセスとして処理ユニットの良好な挙動を読み取るために、データ単位で記憶されています。したがって、リレーショナルデータベースは、行指向のデータベースとして知られています。逆に、列指向データベースなどのデータ、列単位で読み出した良好なデータ単位で記憶されています。問題を解決したいと考え、このようなデータベースは、従来のデータベースのスケーラビリティ上の欠陥の存在であり、そのようなデータベースは増加し、記録のデータ構造の変化量を収容することができ、動的な列は、大規模なデータ記憶装置を収容することができます。列名とレコードキーが固定されていないので、レコードは、行の数千億であってもよいので、それほどスケーラビリティは、二次元のメモリキーと値のストアとして見ることができます。カサンドラ、HBaseの、マイクロソフトのAzureコスモスDBに代表される 、Datastaxエンタープライズ、Accumulo。
(4)データのコンテンツ検索するための検索エンジンデータベース:コンテンツを検索専用に。主にリアルタイム処理と分析近い大量のデータのために使用され、それは、機械学習とデータマイニングのために使用することができます。典型的な代表Elasticsearch、Splunkは、Solrの、MarkLogic、スフィンクス。



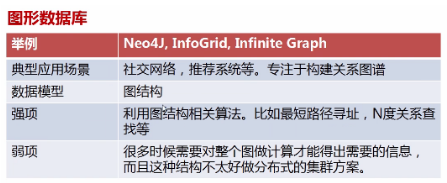
2.3利点
①フレキシブルフォーマット:保存されたデータのフォーマットは、キーと値の形式等の文書、画像、フォームの形態であることができる、柔軟な、幅広いアプリケーションシナリオ、および基本的なリレーショナル・データベース・タイプをサポートします。
②スピード:リレーショナルデータベースが唯一のハードディスクを使用しながら、NoSQLのランダム・アクセス・メモリやハードディスクは、担体として使用することができます。
③高いスケーラビリティ。
④低コスト:NoSQLのデータベースの展開シンプル、基本的にはオープンソースソフトウェア。
2.4欠陥
①SQL文、学習と高いコストをサポートしていません。
②何のトランザクションはありません。
③データ構造は、あまり印象的なものから複雑なクエリ比較的複雑です。
3. PKリレーショナルデータベース非リレーショナルデータベース
① 关系型数据库的最大特点就是事务的一致性:传统的关系型数据库读写操作都是事务的,具有ACID的特点,这个特性使得关系型数据库可以用于几乎所有对一致性有要求的系统中,如典型的银行系统。但是,在网页应用中,尤其是SNS应用中,一致性却不是显得那么重要,两个人看到同一好友的数据更新的时间差那么几秒是可以容忍的,因此,关系型数据库的最大特点在这里已经无用武之地,起码不是那么重要了。相反地,关系型数据库为了维护一致性所付出的巨大代价就是其读写性能比较差,而像微博、facebook这类SNS的应用,对并发读写能力要求极高,关系型数据库已经无法应付(在读方面,传统上为了克服关系型数据库缺陷,提高性能,都是增加一级memcache来静态化网页,而在SNS中,变化太快,memchache已经无能为力了),因此,必须用新的一种数据结构存储来代替关系数据库。
② 关系数据库的另一个特点就是其具有固定的表结构,因此,其扩展性极差,而在SNS中,系统的升级,功能的增加,往往意味着数据结构巨大变动,这一点关系型数据库也难以应付,需要新的结构化数据存储。因此,非关系型数据库应运而生。由于不可能用一种数据结构化存储应付所有的新的需求,所以,非关系型数据库严格上不是一种数据库,应该是一种数据结构化存储方法的集合。
③ 必须强调的是,数据的持久存储,尤其是海量数据的持久存储,还是需要一种关系数据库这员老将。
Oracle那样花费大量成本购买使用,相比关系型数据库价格便宜。
② 查询速度:NoSQL数据库将数据存储于缓存之中,而且不需要经过
SQL层的解析,关系型数据库将数据存储在硬盘中,自然查询速度远不及NoSQL数据库。
③ 存储数据的格式:NoSQL的存储格式是
key-value形式、文档形式、图片形式等等,所以可以存储基础类型以及对象或者集合等各种格式,而数据库则只支持基础类型。
④ 扩展性:关系型数据库有类似join等多表查询机制的限制,导致扩展很艰难。NoSQL基于键值对,数据之间没有耦合性,所以非常容易水平扩展。
⑤ 持久存储:NoSQL不使用于持久存储,海量数据的持久存储,还是需要关系型数据库。
⑥ 数据一致性:非关系型数据库一般强调的是数据最终一致性,不像关系型数据库一样强调数据的强一致性,从非关系型数据库中读到的有可能还是处于一个中间态的数据,NoSQL不提供对事务的处理。
4. CAP理论
CAP理论:一个分布式系统不可能同时满足C(一致性)、A(可用性)、P(分区容错性)三个基本需求,并且最多只能满足其中的两项。对于一个分布式系统来说,分区容错是基本需求,否则不能称之为分布式系统,因此需要在C和A之间寻求平衡。
C(Consistency)一致性:一致性是指更新操作成功并返回客户端完成后,所有节点在同一时间的数据完全一致。与ACID的C完全不同。
A(Availability)可用性:可用性是指服务一直可用,而且是正常响应时间。
P(Partition tolerance)分区容错性:分区容错性是指分布式系统在遇到某节点或网络分区故障的时候,仍然能够对外提供满足一致性和可用性的服务。
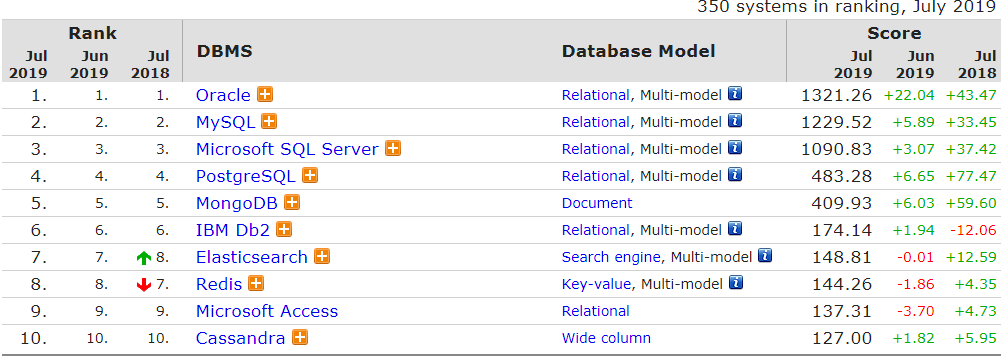
5. 数据库排名查询
参考博客:
https://blog.csdn.net/m0_37947204/article/details/81047934
https://www.cnblogs.com/zylq-blog/p/7595979.html
https://www.jianshu.com/p/fd7b422d5f93