データベースのデータモデルは、理解するための鍵は、このセクションのHBaseインライン・データ・モデル、データ・モデルに関連する基本的な概念であり、物理的及び概念図HBaseのデータベースビューを記述する。
データ・モデルの概要
HBaseのは、スパース、多次元、注文したマップです。
この表の各セルは、行キー、列グループ、および同定することがタイムスタンプ列修飾子によってインデックス付けされます。各セルの値は、文字列データは、noを入力原因不明です。ユーザデータはテーブルに格納されている場合、各列は、固有の行とキーの列の任意の数を有します。
1つ以上の列からなるグループによるテーブルの各行は、列ファミリーは、任意の数の列を含むことができます。同じモードでは、列グループを構成する各列は、グループ番号と列名は同じであるが、各列内の各列グループ内の列の数が異なっていてもよい、すなわち、同じです図に示すように。
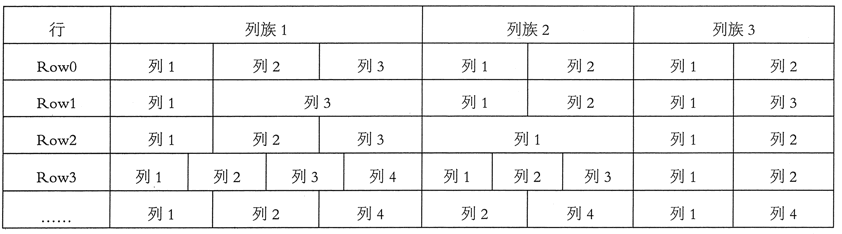
概略的に図2のデータモデル。1 HBaseの
一緒にHBaseの中に格納されたデータ内の同じ列ファミリは、列の家族支援動的拡張は、事前に定義された列数なしで、いつでも新しい列を追加することができます。したがって、表の各行が、同じ列ファミリーを持つことになり、非常に異なる列を有することができます。このため、全体のマッピングテーブルのデータの各行は、いくつかの列の値は空であるので、HBaseのテーブルは疎です。
HBaseの時に更新操作、および旧バージョンがまだ保持され、データの古いバージョンを削除しますが、新しいバージョンを生成しません。
ユーザーはHBaseの予約のバージョンの数を設定することができます。データベースを照会では、ユーザはすべてのバージョンを取得するには一定の時間、または時間から最新バージョンを入手するように選択することができます。クエリ時間がタイムスタンプを提供していない場合、システムは、最新の時間、現在のバージョンからのデータを返します。
;他は、最近の期間内に保存されたバージョンでは、そのような先月のような1つは、最後のバージョンのデータを保存することです:HBaseのデータ復旧方法の2つのバージョンを提供します。
基本的な概念データモデル
HBaseのデータは、行と列と、それは多次元マップ構造であり、テーブルに格納されています。このセクションでは、統一されたプレゼンテーションのためのHBaseのデータモデルに関連する基本的な概念を説明しています。、
1.テーブル(表)
HBaseのテーブルは、多数の行と列から成るデータテーブルを編成するために用い、カラムは、列グループに分割されます。
2行(行)
テーブルの内部では、各行はデータオブジェクトを表します。各行は、キー(行キー)と1つの以上の列の行から成ります。行キーが一意の行、行キーとアルファベット順に、格納するバイナリバイトにない特定のデータ型を識別する。
テーブルがストアキーを順次に行毎であるので、行キー設計が非常に重要です。テーブルデザインサイトを記録する場合、キーの重要な設計原理行が近い位置に格納するラインキーに関連付けられている、例えば、ラインキー(たとえば、ドメイン名を逆にする必要がある、org.apache.www、org.apache.mail、 org.apache.jira)、この設計は非常に近いテーブルの位置に格納されているApacheのに関連付けられているドメイン名を可能にします。
;線分結合によって一定間隔に複数行のデータへのアクセス、フルテーブルスキャン単一ライン取引を得る単一の行キーによって:表の行のみ三つの方法にアクセスします。
3.列(カラム)
そのようなファミリーとして間隔「の」:カラム(カラムファミリー)と修飾子カラム(カラム修飾子)によって、芳香族関節識別子列qualifiero
グループ4.列(カラムファミリー)
HBaseのテーブルの定義では、事前の列ファミリに設定する必要が、テーブル内のすべての列が内部の列の家族に整理する必要があるとき。決定列ファミリたら、それは物理的なストレージHBaseの本当の構造に影響を与えるように容易、変更することはできませんが、列の修飾子列ファミリは、それに対応する値を動的に追加または削除することができます。
テーブルの各行は、同じ列グループを有しているが、テーブルが疎な構造となるように冗長データをある程度回避することができるように、各列グループ内の列は、一貫性の修飾子列が必要としません。
HBaseの列ファミリは、列のコレクションです。すべての列の列ファミリーメンバーすべてが同じ接頭辞を持って、例えば、コース:歴史やコース:家族の数学のコースが記載されています。「:」それは、セパレータグループ列で、列名は、接頭語を区別するために使用されています。列の家族はあなたが常に新しい列を作成することができ、テーブルがセットアップ時に宣言する必要があります。
修飾子カラム(列修飾子)
修飾子をマップする列でファミリーデータ列。列の修飾子は、前に定義せずに、異なる行の間で一貫している必要はありません。店舗へのバイナリバイトに特別な修飾子列のデータ型はありません。
6.単位(セル)
セルデータのセルに記憶された識別データとともにユニットが参照されるキー行、列と列グループ修飾子は、ストアへのバイナリバイトへの特定のデータ型がありません。
7.タイムスタンプ(タイムスタンプ)
デフォルトでは、各データユニットは、バージョン識別にタイムスタンプを挿入を使用します。
データユニットを読み出すときのタイムスタンプが指定されていない場合、デフォルトでは、最新のデータを返す、新しいデータユニットを書き、タイムスタンプが設定されていない場合は、現在の時刻がデフォルトです。グループのデータユニットのそれぞれのバージョン番号欄は、デフォルトでは、HBaseの別々三つのバージョンHBaseのデータ保持を維持しています。
概念図
HBaseのの概念図で、テーブルは、スパース、多次元マッピング関係とみなすことができ、「+ OKキー列ファミリー:カラム足制限タイムスタンプオペレータ+」形式特定のデータユニットを見つけることができます。HBaseのテーブルが疎であるため、ので、いくつかの列が空白になることがあります。
HBaseの図2は概念図、メモリページテーブル情報の断片です。行キーは、このような逆www.cnn.com com.cnn.wwwとして逆UKL、です。
逆URLの利点は、あなたが同じサイトからのデータコンテンツを作ることができるということですが、サイトのユーザーのデータ読み出し速度を向上させることができ、隣接する位置に格納されています。内容欄ファミリは、ページの内容を保存されている、アンカー列ファミリは、このページの参照リンクを格納している、ページメディアタイプのMIME列ファミリーストアを。

図2 HBaseの概念図。
図2のデータのみ一列に与えCom.cnn.wwwサイト概念図は、一意に、ラインが「com.cnn.www」であり、このラインは、関連するタイムスタンプに対応する論理データを修正した各時間を識別する。4つのテーブルがあります:内容:HTML、
アンカー:cnnsi.com、アンカー:my.look.caとパントマイム:タイプ、列のプレフィックスの各列は、グループが属するとして与えられます。
それは図3、総コンテンツページバージョン3から分かるように、それぞれ、タイムスタンプT3、T5及びT6に対応します。Webページには、2つのページを引用my.look.caあるとcnnsi.com、時刻t8とT9を引用しました。T6開始からWebメディアタイプ "text / htmlの"。
データユニットは、すなわち、[:カラム修飾子、タイムスタンプ列のキー、列グループ]に「三次元座標」とすることができる見つけることができます。
例えば、図3において:
- 【「Com.cnn.www」、アンカー:cnnsi.com、T9「CNN」としてセルに対応するデータ。
- 【「Com.cnn.www」、アンカー:my.look.ca、T8]呉「CNN.com」に対応する単一のデータです。
- 【「Com.cnn.www」、MIME:タイプ、T6「テキスト/ HTML」に対応するデータ単位。
図3は、概念図をHBaseの表から分かるように、グループ内の各列に格納されたデータの各列のために必要とされていないが、各列は、同じ列グループを含んでいます。例えば、図3におけるデータの最初の2つの行、列の内容と列の内容芳香族MIMEは空です。データ線3後、カラムの内容が空のアンカー基です。データの2つの行の後に、列グループMIMEの内容は空です。
物理ビュー
概念的な透視が、HBaseの各テーブルは、多くの行で構成されているが、物理ストレージレベルでは、ストレージ列ベースではなくラインベースとしてリレーショナルデータベースを使用することですストレージ。これは、1つの重要な違いのHBaseとリレーショナルデータベースです。
図2は、物理的な記憶を行う場合、図2のように格納されます。33の断片概念図です。換言すれば、HBaseのテーブルは、コンテンツ、アンカーおよびMIME 3列ファミリに応じて別々に格納されます。同じ列グループに属するデータは、同時に、一緒に保持され、ラインキーで各列グループが格納され、さらにタイムスタンプを含みます。
図2の概念図では、これらの値は列の上に存在しない、つまり、多くの列が空で見ることができます。物理ビューでは、これらの空の列がnullに格納されていませんが、ストレージスペースを大幅に節約することができた、保存されません。ときにこれらのギャップユニット要求は、ヌル値を戻します。
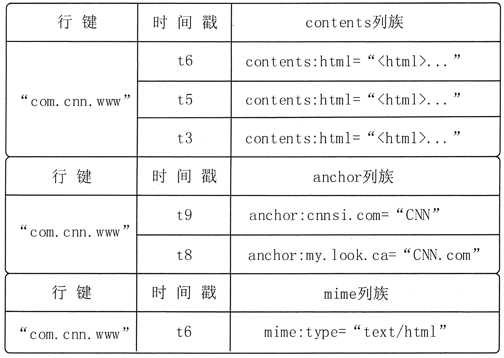
図3 HBaseの物理ビュー。
21. A HDFS基本原理とデザイン
22 A HDFSアーキテクチャ及び実装機構
23 A HDFS読み出しおよび書き込みデータ
24 A HDFS 2つの動作モード
25 A のNoSQLプロファイル
26 A のNoSQL型プロファイル
27 のHBaseプロファイル
28 HBaseの柱状データモデル
29 HBaseのシェル
30は、メイン操作機構.HBase
31 のJava .HBase共通APIを
32にJavaプログラミングAPIのHBaseのインスタンス
33 のHadoopのMapReduce
34. HadoopのMapReduceのフレームワーク
35 のHadoop MapReduceのワークフロー
36 ワードカウント:MapReduceのケーススタディ
37 のHadoopをMapReduceの機構
38. MapReduceのプログラミング例