概要
フィルタ(フィルタ)は畳み込みニューラルネットワークの加速度及び圧縮を剪定する最も有効な方法です。本研究では、我々は、アルゴリズムと呼ばれるグローバルフィルタCNNモジュールは、スケーリング係数を乗じた共通チャネルによって出力されたゲートデコレータを、プルーニング提案(すなわちゲートは、G用コード)であることが変換。スケール係数が0に設定されている場合、対応するフィルタを削除するために、対応します。私たちは、原因原因ゼロにスケールファクタのセットの変化に損失を推定するために、とテイラー展開は、グローバルフィルタをソート使用することの重要性を推定するためにテイラー展開関数を使用します。その後、我々は重要でないフィルタを除去することにより、ネットワークを剪定しています。トリミング後、スケールファクタの全ては、元のモジュールに組み込まれるので、特別な操作や構造を導入しません。加えて、我々は、プルーニングの精度を向上させるために、かちかちと呼ばれる反復剪定フレームワークを提案します。多数の実験は、我々のアプローチの有効性を示します。例えば、我々は、しかし、精度の大幅な損失なしに、ResNet-56上で最も先進的な剪定割合、フロップの70%の削減を実施しました。ResNet-50 ImageNetのために、我々のモデルがベースラインモデルよりもフロップで40%削減、トップ-1精度の余分な0.31パーセントをトリミング。CIFAR-10を含む、データセットのさまざまな方法を使って、CIFAR-100、CUB-200、ImageNet ILSVRC-12およびPASCAL VOC 2011。
1はじめに
近年では、我々はCNNs多くのコンピュータビジョンのタスクで顕著な成果[40,48,37,51,24]を目撃しました。現代のGPUの強力なサポートでは、CNNモデルは、より良いパフォーマンスを得るために、より大規模で複雑なように設計することができます。しかし、コンピューティングおよびストレージの消費量の多くは、携帯電話や物事のデバイスのインターネットなどのリソースに制約のあるデバイス上で最も先進的なモデルの展開の妨げになります。1)モデルサイズ:主に3つの制約[28]から。2)メモリランニング。3)操作の数を計算します。広く使用されているVGG-16 [39]モデルの例として。モデルパラメータが消費より多くのストレージスペースの500メガバイトより138百万、できるだけ多くを持っています。中間出力画像を格納するメモリを推定するために、224×224解像度、低エンド機器の重い負担である160億浮動小数点演算(FLOPS)および追加のランタイム93メガバイトにモデルが必要です。したがって、ネットワーク圧縮、加速方法が大きな関心を呼んでいます。
1)定量[34,55,54]:モデル圧縮及び加速度に関する最近の研究は、4つのカテゴリに分けることができます。2)高速畳み込み[2,41]。3)低ランク近似[7,8,50]。4)フィルタリング剪定[1,30,15,25,28,33,56,52]。これらの方法では、フィルタの剪定(また、チャネルプルーンとして知られている)、その重要な利点は、多くの注目を集めました。まず、フィルタは、一般的な刈り込み技法はCNNモデルの様々なタイプに適用することが可能です。第二に、フィルタを組み合わせた他の圧縮と加速技術と非常に簡単にそれを作るモデルトリムのデザインを、変更されません。また、ネットワークは、剪定後に加速を達成するために、特別なハードウェアやソフトウェアを必要としません。
神経の枝刈りは、最初LeCunらは、いくつかのニューロンは削除することができるが、精度の有意な損失を引き起こさないことが分かっ最適脳損傷(OBD)[23,10]によって提案されました。我々は、フィルタ(図1)と呼ばれるこの技術を剪定ようCNNsのために、私たちは、ネットワーク層フィルタを剪定します。
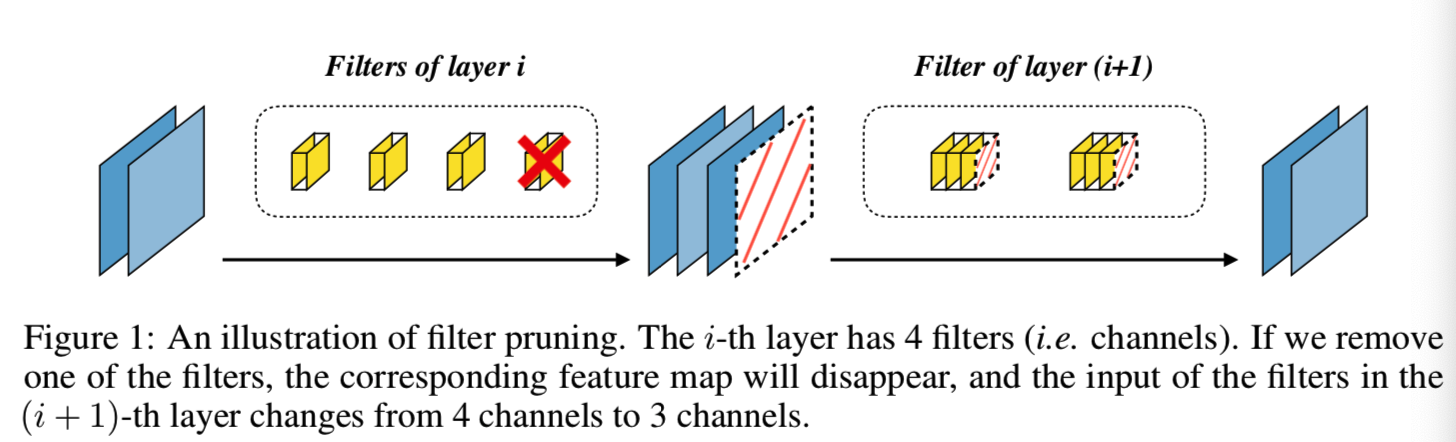
1)層プルーニング[30,15,56]によって層:剪定フィルタに関する研究は、2つのカテゴリに分けることができます。2)グローバル剪定 [25,28,33,52]。層プルーニング法による層は、一定の条件が満たされるまで、層の特性は、再構成誤差を最小にするために、特定のフィルタのすべての層を除去することです。しかし、剪定のフィルタ層は、特に深いネットワークのために、非常に時間がかかるです。また、神経構造検索フィルター剪定アルゴリズムの能力を排除し、定義済みの割合プルーニングを設定するには、各レイヤの必要性は、私たちは、4.3節で説明します。一方、世界的な剪定方法は重要でないフィルタ、彼らが何であるかのレベルに関係なく削除します。グローバルフィルタの利点は、私たちはそれぞれの層のためのプルーン剪定比設定する必要はありませんということです。剪定の全体的な目標与えられた場合には、最適なネットワーク構造を明らかにするアルゴリズムが見つかりました。キーグローバル剪定方法は、(GFIRは、重要性のグローバルフィルタ順序の問題を解決するものであり、株式会社無料で問題がランキングフィルタ重要性を参加します)。
本稿では、2つの部分から構成され、新たなグローバルフィルタ剪定方法を提案する:最初の部分は、問題を解決するために使用GFIRゲートデコアルゴリズムです。第二のフレームは、精度を向上させるかちかちのプルーン、プルーンです。特に、我々は門デコレータは、バッチ正規化[19]を適用し、モジュール改訂ゲートバッチ正規化(GBN)を呼び出す方法を示しています。ゲートデコレーターによって変換されたモジュールがするように設計されていることに留意する必要があるように設計剪定の一時的な目的を満たします。事前に訓練された指定されたモデルに、我々はトリム、その後、BNモジュールGBNを変換します。ときトリムは、我々は通常のGBN BNに戻って変更されます。このため、特別な操作や構造を導入する必要があります。多数の実験は、この方法の有効性を示します。我々は、しかし、精度の有意な損失なしに、最も先進的な剪定割合、プの70%削減[11]にResNet-56を実現します。トップ-1 0.31パーセントの精度を向上させながら、[4] ImageNetにおいて、我々は、フロップをResNet-50 [11]の40%減少しました。次のように私たちの貢献を要約することができます。
我々は2つの部分から構成グローバル剪定フィルタパイプライン、提案する:問題を解決するために使用される一部GFIRゲートデコレータアルゴリズムを、他方がかちかちのプルーンプルーニングフレームの精度を高めるために使用されます。ResNetを使用する場合に加えて、我々はグループ制約を解決するためにプルーニング手法を提案するプルーニング(枝刈り制約)問題が発生しました[11]このような構造ショートカットネットワーク網プルーニングを有しています。
(b)の結果は、我々の方法は、最も先進的な方法より優れていることを示しています。私たちは、広範囲のアルゴリズムの性質とGBNかちかちの枠組みを検討してきました。グローバルフィルタリングプルーニング方法のさらなる証拠は、タスク駆動型のネットワーク構造探索アルゴリズムとして見ることができます。
2関連作品
剪定をフィルタリングします。フィルタの剪定は、ソリューションを有望なのは非常に加速CNNsです。その重要性により、これらのフィルタを排除するために多くの感動作品を評価しました。提案されたコンボリューションカーネル[25]サイズ、[17]など、ゼロ平均パーセンテージの活性化機能(APOZ)ヒューリスティックメトリック(ヒューリスティックメトリック)。羅ら[30]、およびHeら[15]ラッソ回帰を選択するために使用されるフィルタの最小の再構成誤差の下層ことを特徴とします。一方、Yuら[52]は、最終的な再構成誤差感応層と拡散を各フィルタの重要度スコアを最適化します。テイラーを使用Molchanovは、最終的なフィルタの機能の喪失の影響を評価します。トレーニングネットワークの別のタイプは、フィルタやで発見冗長性のいくつかを排除するために、一定の制限の下で動作します。微調整およびフィルタに事前学習モデルの認識の追加損失を適用することにより、荘らの認識が良好な結果を識別し得る能力を保持するのに役立ちます。しかし、損失認識の認識は、その使用の範囲を制限分類タスク用に設計されています。Liuら[28]及びイェら[49]因子は各フィルタに適用されるスケールは、損失がトレーニング増加するスパース制約。丁らは、同じ値を達成するために、複数のフィルタをトレーニングすることによって、新たな最適化法を提案し、冗長フィルタは安全に除去されます。これらの方法は非常に時間がかかる大規模なデータセットのためにあるのトレーニングモデルを、開始する必要があります。
他の方法。異なるパラメータ値の数を減らすことによって、圧縮されたネットワーク量子化方法。32ビット浮動小数点量子化パラメータ三元またはバイナリ(三元)。しかし、これらの積極的な量的政策は通常、精度の損失を伴います。[55、54]適切な定量的戦略定量化ネットワークとも完全な精密ネットワーク越えを使用するときことを示しました。近年では、新しいコンボリューションデザイン。Chenらは、設計された畳み込み部は、単位ファクタリング特徴マップを混合周波数に応じて、プラグアンドプレイをOctConv。実験結果は、計算量を削減しながら、モデルのOctConv精度を向上させることができる、ことを示しています。低ランク分解低ランク行列、複数のネットワークの[7,8,5]近似重み。研究を加速する別の一般的なネットワークは、ネットワークアーキテクチャの設計を探求することでした。[16,36,53,32]多くのコンピューティング・アーキテクチャの効率は、モバイルデバイスのために提案されています。これらのネットワークは、人間の専門家によって設計されています。自動的に神経構造(NAS)を検索するためのコンピュータの利点を組み合わせるために最近では広く注目を集めています。多くの研究は進化の方法に基づき、[35]、[47,27]の勾配に基づいて、[57]強化学習に基づくものを含む、提案されています。それは私たちの提案するアルゴリズムは、このセクションで説明する方法門デコレータが(直交していることは注目に値する直交)。すなわち、これらの方法を組み合わせることができ、ゲートデコレータであり、より高い圧縮率を達成するために処理します。
3メソッド
このセクションでは、我々は最初の問題を解決するためにゲートデコ(GD)GFIRをご紹介します。そして、GDバッチ正規化[19]に適用する方法を示しています。その後、私たちはより良い精度の剪定で、かちかちと呼ばれる反復剪定枠組みを提案します。最後に、我々はネットワークの剪定のショートカット(すなわちresnetネットワークなど)を使用するときに発生する問題を解決するためのテクニックを剪定剪定制約のセットをご紹介します。
3.1問題の定義とゲートデコレータ
正式に、L(X、Y、θ)は、入力データXは、Yは、それぞれのタグ、θは、モデルのパラメータであり、トレーニングモデル損失関数を表します。我々はKで、すべてのネットワークフィルタの集合を表します フィルタトリムフィルタk⊂Kのサブセットを選択することで、θに対応するネットワーク・パラメータから削除K - 。私たちは、θパラメータの左側にあることに注意してくださいK +であるが、残りのパラメータを剪定した後、我々は、θ持つK + ∪θ K - = [シータ]。損失の増加を最小限に抑えるために、我々は慎重に、次の最適化問題を解くことによって、Kを選択する必要があります。
![]()
これは、|| || K 0は、 k個の要素の数、この問題に対する簡単な解決策は、すべての可能なk個を試してみて、損失の影響を最小限に抑えるために最善を選択することです。しかし、それはK || ||計算する必要がある0 CI = [デルタ] L | L(X、Y)を、θ)-L(X-、Y);θはK +)|完全な反復にトリミングされ、これは実現可能深くありませんフィルタの数万を持っているモデル。この問題を解決するために、我々は効果的にフィルターの重要性を評価するためにゲートデコレータを提案します。
マッピング出力z kはフィルタであり、我々は、zはスケールファクタφ∈Rトレーニング乗じおよびz =φzさらなる計算のために使用されてみましょうと仮定する。ゲートφは、フィルタトリマーKに相当するゼロである場合。テイラー展開を用いて、ΔLを剪定について評価することができます。まず、表記の便宜のために、我々は式(2)に書き換えることができる持っている、△L、φ以外X、Y及びモデルパラメータのすべてを含む式Ωの。従ってLはΩ・(Φ)単項関数WRTφがあります。
![]()
次に、テーラー展開式式のL(3)及び(4)を使用して、Ω(0)

連結式(2)及び(4)を得ることができます。
![]()
R 1が、それは、コンピューティングの多くを必要とするため、我々はこれを無視するラグランジュ余りあります。今、我々は、式(5)GFIR問題を解決する、バックプロパゲーション法に基づいて、この問題を容易に計算されることができます。各フィルタK I ∈K、我々は式(6)を使用するが算出されるθ(Φが私は)、即ち、フィルタの重要度スコアは、Dは、トレーニングセットです。
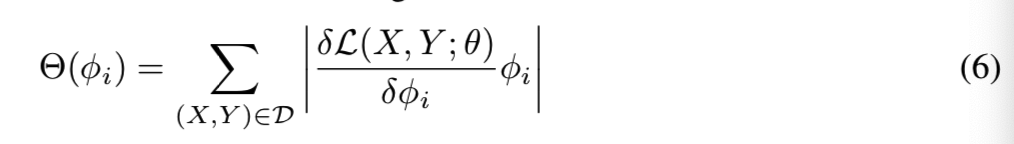
特に、我々はゲートデコレータバッチ正規化[19]に適用され、私たちの実験で使用しました。私たちは、GBNと呼ばれる改訂ゲートバッチ正規化をブロックします。畳み込み層に続く、ほとんどの場合、1)BN層:我々は2つの理由からBNのモジュールを選択しました。したがって、我々は簡単にフィルタし、BN層マッピングの特性との対応関係を見つけることができます。2)当社は、(詳細については、付録Aを参照してください)φに手がかりを提供するランキングでBNγスケーリング係数を使用することができます。

GBNは、式(7)で定義され、φ⃗φはベクトルであり、cはZであるにチャンネルサイズ:
![]()
また、BNは、我々はまた、門デコレータの畳み込みに直接適用することができるネットワークを使用しないでください。付録Bで定義されたゲートで囲われたコンボリューション:

3.2かちかち剪定フレームワーク
このセクションでは、我々はTick-のタック(図2)と呼ばれるフレームの精度を向上させるために反復剪定剪定フレームワークを導入します。
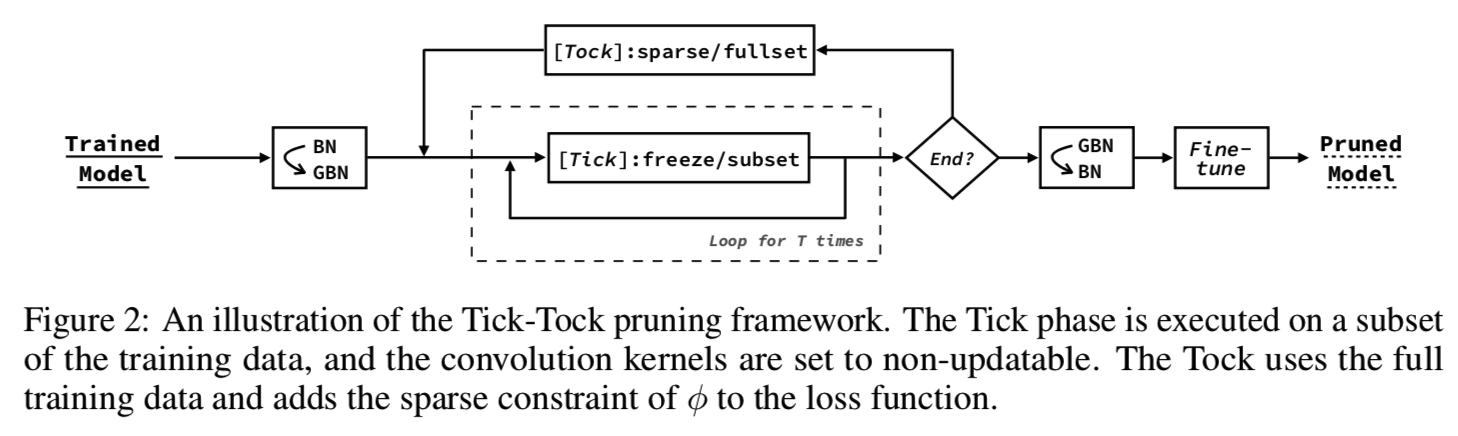
次の目標を取得するために設計された手順をチェック:
1)加速剪定
2)各フィルタの重要度スコアを計算Θ
3)トリムは、修復の問題[19]まで、内部共変量シフトによる
ダニの段階では、各エポックは、我々はモデルを訓練するためにデータを訓練のサブセットを使用し、我々は唯一の直線状のゲートφと最後の層が更新された許可過度の集中を避けるためには、データに合わせて小型で発生します。Θは、方程式(6)に従って後方重要度スコア伝播を計算します。訓練の後、我々は、フィルタのすべての重要度のスコアΘのソートを使用して、フィルタの少なくとも重要な部分を削除します。
Tick阶段可以重复T次,直到进入Tock阶段。Tock阶段的目的是对网络进行微调,以减少由于删除过滤器而导致的错误积累。除此之外,对φ的稀疏约束将添加到训练期间的损失函数中,这有助于揭示了不重要的过滤器和计算Θ更准确。Tock中使用的损失函数如式(8)所示:
![]()
最后,我们对修剪后的网络进行微调以获得更好的性能。Tock步骤和Fine-tune步骤有两个不同之处:1)Fine-tune通常比Tock训练更多的epochs。2)Fine-tune不向loss函数添加稀疏约束。
3.3 Group Pruning for the Constrained Pruning Problem
ResNet[11]及其变体[18、46、43]包含shortcut连接,它将元素明智地添加到由两个剩余块生成的特征映射上。如果我们单独对每一层的过滤器进行修剪,可能会导致shortcut连接中特征映射的不对齐。
若干解决办法被提出。[25,30]绕过这些麻烦的层,只修剪残差块的内层。[28,15]在每个残差块的第一个卷积层之前插入一个额外的采样器,不修剪最后一个卷积层。然而,避免麻烦层的方法限制了修剪比例。此外,采样器解决方案为网络添加了新的结构,这将引入额外的计算延迟。
为了解决这一问题,我们提出了组剪枝的方法:将由纯shortcut connection 连接的GBNs分配给同一组。纯shortcut connection是侧支上没有卷积层的快捷方式,如图3所示:
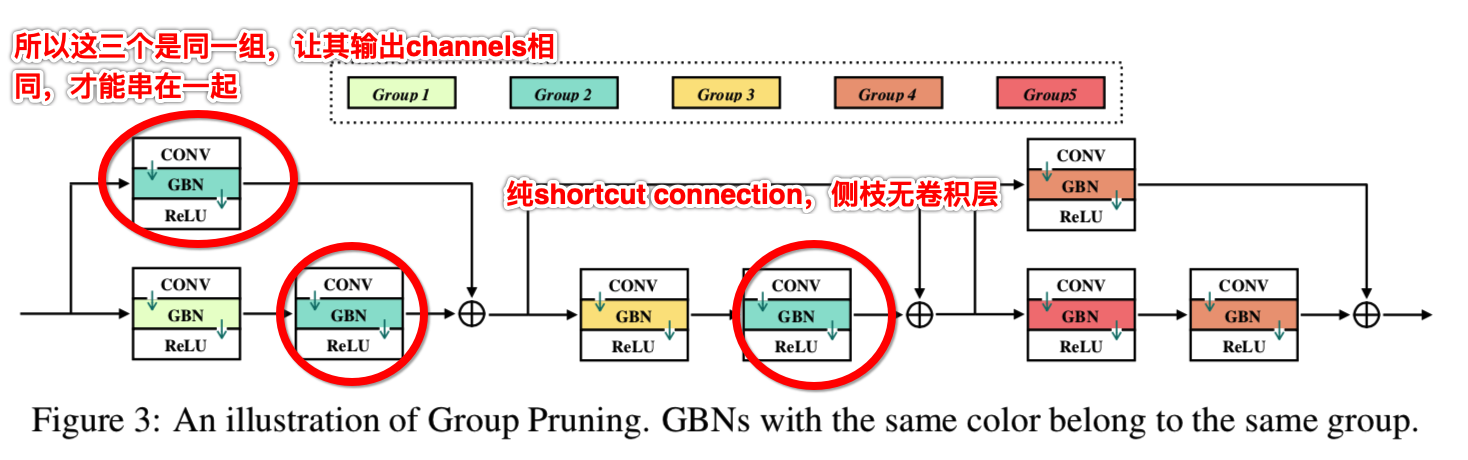
一个组可以被看作是一个虚拟的GBN,它的所有成员共享相同的修剪模式。一个组中过滤器的重要性分数是其成员的总和,如等式(9)所示:

g是在组G中GBN成员之一,在组G中所有成员中排名第j的过滤器的重要性分数定义为Θ(φjG)。
3.4 Compare to the Similar Work.
PCNN [33]も、問題を解決するためにテイラーGFIRを使用しています。
ゲートデコレータとPCNNは次の3つの方法で異なっを提案しました。
1)は、スケールファクタが導入されていないがあるので、PCNNにテイラー多項式図は、推定誤差を累積し、各スコアの一次のフィルタエレメントの評価を合計することの重要性の程度によって特徴付けられます。
2)スケール因子が不足しているため、PCNNは、スパース制約を使用しません。しかし、私たちの実験によれば、スパース制約は、剪定の精度を向上させる上で重要な役割を果たしています。
3)標準クロスレイヤPCNNのスコアが必要であるが、ゲートデコレータのためではありません。方法PCNN図分数クロスレイヤ変化の特徴の大きさと規模につながる可能性が累積スコアの重要度を計算するために使用されるためです。我々は、我々の評価は世界的に同等であるため、エラーの新しい推定値を導入するために標準化し、スコアの標準化をあきらめました。
4回の実験
省略
5。結論
本研究では、トリミングされたグローバルフィルタの目的を果たすために3つのコンポーネントを提案します:
1)ゲートデコレータは、グローバルフィルタの並べ替え重要性(GFIR)問題に対処します。
2)かちかちフレーム、トリミングの精度を向上させることができます。
3)の方法をプルーニンググループプルーニングは制約問題を解決します。
私たちは、グローバルフィルタ剪定方法は、タスク駆動型のネットワーク構造探索アルゴリズムとして見ることができることを証明します。多数の実験を示し、最も高度なフィルタリング剪定方法のいくつかには、この方法よりも優れています。