アプリオリ関連解析アルゴリズム
アプリオリアルゴリズムは、相関ルール、最も有名な関連解析アルゴリズムの1を生産するために必要な頻出アイテムセットをマイニングするための基本的なアルゴリズムです。
1.アプリオリアルゴリズム
アイテムセット - アプリオリアルゴリズムはK-品目が(K + 1)探索使用レイヤー法により層の反復検索を使用します。検索を改善し、頻繁にアイテムの対応するセットの階層的な処理効率を生成するために、アプリオリアルゴリズムは効果的頻出アイテム集合の探索空間を低減することができる重要な特性を利用します。
アプリオリプロパティ:頻繁項目セットのすべての空でない部分集合にも頻出アイテムセットでなければなりません。追加されたエントリ項目がAを設定するためにBを設定した場合、Aは、すなわち、Aが頻繁ではないが、最小支持項目セットの閾値を満たさない場合には、であり、は、新しいアイテムのセット(AUB)は、頻繁にすることはできません。
アプリオリ単純なアルゴリズムは、主に次のステップです。
1)シングルパス走査データセットによって各項目の支持の程度を決定します。これが行われたら、F1のコレクションすべて頻繁1項目集合を得ることができます。
2)頻繁な繰り返しの使用(K-1)を求める-新たな候補K-項目集合を生成する品目セットを。
3)カウント候補セットをサポートするために、もう一度サブセット関数候補の全てがトランザクションT K-品目セットのそれぞれに含まれるかを決定するために、データベースをスキャンします。
4)候補支援countオプションのセットを計算した後、アルゴリズムは、すべての候補がカウントはサポートの設定した閾値未満のサポートが削除されます。
5)繰り返し工程(2)、(3)、(4)、新しい高頻度項目セット生成アルゴリズムは終了しない場合。
頻出アイテム集合を見つけるための戦略 - アプリオリアルゴリズムは、「テスト生成」を使用するステップアルゴリズムによって工程です。(K-1)で - がある場合、アイテムサブセット、頻繁に - プロセスが新たに生成されたK-品目がすべて(K-1)ことを確認しなければならない」の項目のセットにK-品目セットを生成しますそれが取り除か現在の候補の中から集中できるように、頻繁ではありません。
候補項目を生成する方法は以下の通りです。
1)ブルートフォース方法
2項目セットから開始後1項目のセットからすべてのエントリが完全に綴るあります。例えば、スペル3-すべての可能性をリストするために、1項目3項目セット。アイテムセットが頻繁にある場合 - 次に、すなわち、現在のすべての項目(K-1)の組を決定する、プルーンに係るアルゴリズムを剪定。
2) 法律
法律
1項目(K-1) - K-アイテムセットアイテムセット、次いでプルーニングを生成します。各K-頻度の高い項目セットは(K-1)によって頻繁であるため、この方法は、完全 - であり、頻繁なアイテムセット1アイテムが生成しました。そのためオーダーで、この方法は、頻繁に繰り返さK-の大品目を生産します。
3) 法
法
二つの頻繁な(K-1) - K-アイテムセットアイテムの候補セットを生成するが、2つが頻繁(K-1) - 品目K-2は、同じアイテムでなければならない前に、最後の項目が異なっていなければなりません。各候補は、頻繁に(K-1)で設定されているので - アイテムのコレクションと形成された、それはK-2の候補サブセットの残りの候補プルーニングが頻繁にあることを確実にするために追加のステップを必要とします。
2.高頻度項目セットから相関ルールを生成します
それは最小サポートと最小確信度の規則を満たす直接からの強い相関ルールを生成することができ、トランザクションデータからの頻出アイテムセットを一回の集中見つけます。相関ルールを計算サポートは、これら2つの項目を数えるので自信は、データを再度物事を設定スキャンする必要はありませんが、既に生成するように設定頻出アイテムの時に設定されています。
前記X1、信頼閾値を満たしていなければならない、フォームのX1→Y1ー→X1ルール、XがYの部分集合であり、ルールX→Y→Xが信頼閾値を満たさない場合に、頻出集合Yが存在すると仮定Xはのサブセットです。この性質によれば、頻出集合{A、B、C、D}、アソシエーションルールからのアソシエーションルールを生成するために想定される{B、C、D}→{A}は低い信頼を有する、後者は、部材を廃棄することができ、関連するすべてのAを含みますなどのルール、{C、D}→{A、B}、{B、D}→{C}など。
3.アルゴリズムの長所と短所
アプリオリアルゴリズムが大幅層ごとに生成頻出集合の効率を向上させる、超越的性質を用いて古典的な頻出アイテム集合アルゴリズムとして生成、それは単純で、低データセットの要件を理解することは容易です。しかし、綿密のアプリケーションと、その欠点は徐々に、以下の2点での主な性能のボトルネックを露呈しました。
- 繰り返しトランザクションデータセットはI / O負荷の多くを必要とスキャンします。各サイクルkに対して、各要素のCK候補セットが追加LKかどうかを設定されたスキャンデータによって検証されなければなりません。
- 大規模な候補セットを生成することができます。候補セットの数が指数関数的な成長で、候補時間と空間のような大規模なセットが課題となっています。
FP-ツリー相関分析アルゴリズム
2000年には、頻出パターン木(頻出パターン木、FP-木)に基づいて、FP-成長アルゴリズムを提案したハンJiaweiは、頻出パターンを発見しました。アイデアは、FP-ツリー、ツリーへのデータセットのマッピングデータを作成した後、木FPツリーに基づいて、すべての頻出アイテムセットを見つけることです。
FP-成長アルゴリズムは、2つのスキャン取引データセット、FP-ツリーにおけるそれらの圧縮及び貯蔵に従って降順に各企業支援に含まれる頻出項目を、意味します。
プロセスで頻出パターンを発見したら、トランザクションデータセットをスキャンする必要はありませんが、唯一のFP-ツリーで見つけることができます。FP-成長は直接法頻繁に再帰モードで呼び出して、全体の検出プロセスはまた、候補パターンを生成する必要はありません。データのみが二回スキャンしているので、FP-成長アルゴリズムAprioriのアルゴリズムは、効率の実装に問題がまたアプリオリアルゴリズムよりも有意に良好である克服します。
1. FP-ツリー構造
データ構造の数にI / O回数、FP-ツリーアルゴリズムを軽減するには、一時的にデータを格納します。図に示すように、ヘッダ・テーブル・エントリ、FP-ツリーノードおよびリンク:このデータ構造は、3つの部分を含みます。
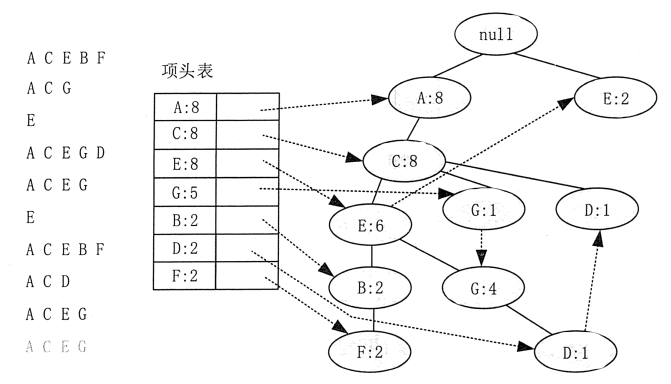
図1 FP-ツリーデータ構造。
最初の部分は、ヘッダ・テーブル・エントリであり、全ての記録1-頻出アイテム集合の数が降順に応じて、表示されます。例えば、図1において、Aは、従って、最初の場所でデータの全10セットで8回現れます。
第二の部分は、FP-ツリー、FP-ツリーメモリにマッピング元のデータセットです。
第3の部分は、ノード・リストです。ヘッドテーブルは、すべての頻出1項目はFP-ツリー1-項目セット内の位置へ旋回点で頻繁に現れる結節点のリストです。これは、検索および更新するために、ヘッドテーブルのエントリとFP-ツリーとの間の接触を容易にするために、主にあります。
項目1)ヘッダ・テーブルを確立します
FP-ツリー項目の設立は、ヘッドテーブルを確立する必要があります。1 - 数はすべての高頻度項目セットを与えるために設定された第1のスキャンデータ。その後に頻繁に1項目ヘッダ・テーブル・エントリ、エントリしきい値以下サポートを削除し、降順をサポートします。
第2の走査データセット、まれ1項目を除いた元のデータを読み出し、降順をサポートします。
この例では、10件のデータがあり、第1のデータおよび第1のスキャン1アイテム数Fは、O、Iは、L、J、P、M、Nのみ(サポート閾値以下、一度表示され見つかりました20%)を、彼らは最初のテーブルのエントリには表示されません。支持体のサイズ、ヘッド・テーブル・エントリの組成に応じて降順に残りのA、C、E、G、B、D、F。
降順各まれ1項目を除くデータ、およびサポートのための第2の走査データが続きます。例えば、データ項目A、B、C、E、F、O O頻繁ノン-1-項目で、このように除去され、唯一のA、B、C、E、F。ソート順をサポートし、それは、C、E、B、Fとなり、そのため他のデータ項目。頻出アイテム集合の生データセット1-ソート順FPツリーの裏面を作成する際に、可能な限り共通の祖先ノードであってもよいです。
2つのスキャンは、アイテムの第1セットが確立された後、図2に示すように、ソートされたデータセットが、ありました。
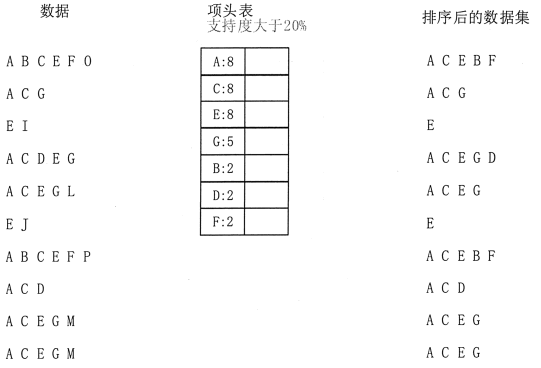
図2 FP-ツリー用語ヘッダが表すことを意図しています
2)FP-ツリー確立
項目ヘッダテーブルとソートされたデータセットを使用すると、FP-ツリーが確立されて始めることができます。
FP-ツリーが先頭にはデータがなく、FP-ツリーを確立する記事に設定ソートされたデータを読み込み、およびFPツリーに挿入されます。挿入された場合、上位ノードは、先祖ノードであり、後方子孫ノードです。共通の祖先がある場合は、対応する共通の祖先ノードが1でカウントされます。新しいノードが表示された場合に挿入した後、ノードに対応するヘッダ・テーブル・エントリは、ノードリンクリストに新しいノードを通過します。すべてのデータがFPツリーに挿入されるまでは、FP-ツリーが作成されます。
以下の説明は、FP-ツリーを確立するプロセスに例示されています。図に示すように、まず、第1のデータA、C、E、E、Fを挿入します。この場合、無ノードFPツリーでは、このようにA、C、Eは、Bは、Fは、独立したパスは、すべてのノードは、一つ、新しいノードに対応するノードリンクリストによってテーブルの最初の用語としてカウントされます。
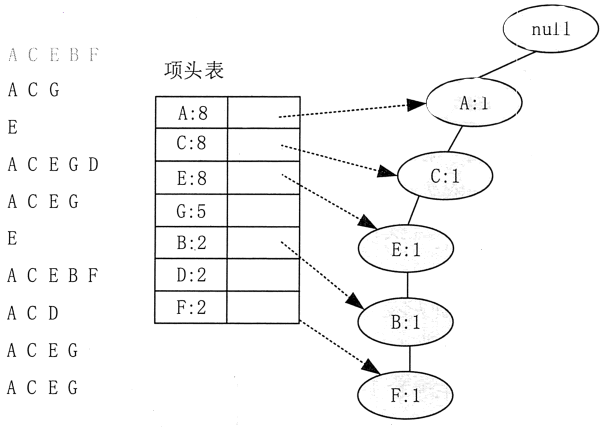
3 FP-ツリー1概略構成図
接着插入数据 A、C、G,如图 4 所示。由于 A、C、G 和现有的 FP-Tree 可以有共有的祖先结点序列 A、C,因此只需要增加一个新结点 G,将新结点 G 的计数记为 1,同时 A 和 C 的计数加 1 成为 2。当然,对应的 G 结点的结点链表要更新。
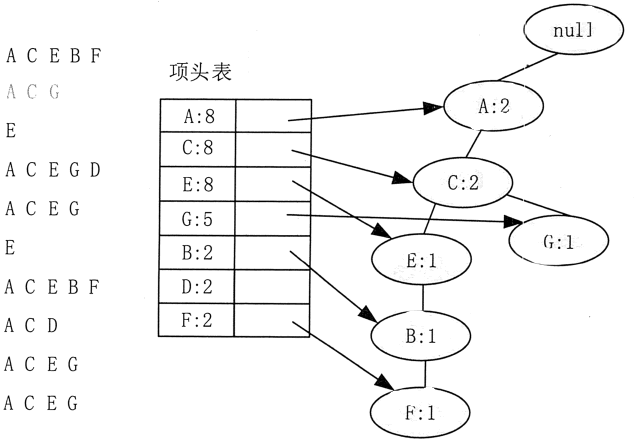
图 4 FP-Tree的构造示意2
用同样的办法可以更新后面 8 条数据,最后构成的 FP-Tree,如图 1 所示。由于原理类似,就不再逐步描述。
2. FP-Tree 的挖掘
下面讲解如何从 FP-Tree 挖掘频繁项集。基于 FP-Tree、项头表及结点链表,首先要从项头表的底部项依次向上挖掘。对于项头表对应于 FP-Tree 的每一项,要找到它的条件模式基。
条件模式基是指以要挖掘的结点作为叶子结点所对应的 FP 子树。得到这个 FP 子树,将子树中每个结点的计数设置为叶子结点的计数,并删除计数低于支持度的结点。基于这个条件模式基,就可以递归挖掘得到频繁项集了。
还是以上面的例子来进行讲解。先从最底部的 F 结点开始,寻找 F 结点的条件模式基,由于 F 在 FP-Tree 中只有一个结点,因此候选就只有图 5 左边所示的一条路径,对应 {A:8,C:8,E:6,B:2,F:2}。接着将所有的祖先结点计数设置为叶子结点的计数,即 FP 子树变成 {A:2,C:2,E:2,B:2,F:2}。
条件模式基可以不写叶子结点,因此最终的 F 的条件模式基如图 5 右边所示。
基于条件模式基,很容易得到 F 的频繁 2-项集为 {A:2,F:2},{C:2,F:2},{E:2,F:2}, {B:2,F:2}。递归合并 2—项集,可得到频繁 3—项集为{A:2,C:2,F:2}, {A:2,E:2,F:2}, {A:2,B:2,F:2}, {C:2,E:2, F:2}, {C:2,B2, F:2}, {E:2,B2, F:2}。递归合并 3-项集,可得到频繁 4—项集为{A:2,C:2,E:2,F:2},{A:2,C:2,B2,F:2}, {C:2,E:2,B2,F:2}。一直递归下去,得到最大的频繁项集为频繁 5-项集,为 {A:2,C:2,E:2,B2,F:2}。
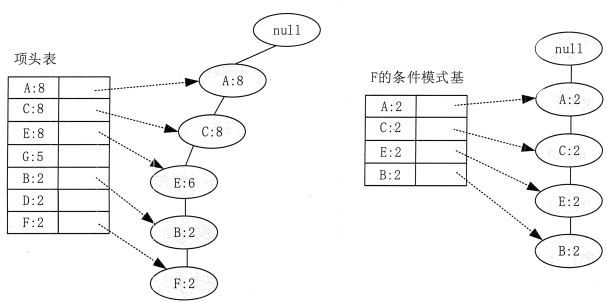
图 3 FP-Tree的挖掘示意1
F 结点挖掘完后,可以开始挖掘 D 结点。D 结点比 F 结点复杂一些,因为它有两个叶子结点,因此首先得到的 FP 子树如图 5左边所示。
接着将所有的祖先结点计数设置为叶子结点的计数,即变成 {A:2,C:2,E:1 G:1,D:1,D:1}。此时,E 结点和 G 结点由于在条件模式基里面的支持度低于阈值,所以被删除,最终,去除了低支持度结点和叶子结点后的 D 结点的条件模式基为 {A:2,C:2}。通过它,可以很容易得到 D 结点的频繁 2-项集为 {A:2,D:2},{C:2,D:2}。递归合并 2-项集,可得到频繁 3-项集为 {A:2,C:2,D:2}。D 结点对应的最大的频繁项集为频繁 3_项集。
用同样的方法可以递归挖掘到 B 的最大频繁项集为频繁 4-项集 {A:2,C:2,E:2,B2}。继续挖掘,可以递归挖掘到 G 的最大频繁项集为频繁 4-项集 {A:5,C:5,E:4,G:4},E 的最大频繁项集为频繁 3-项集 {A:6,C:6,E:6},C 的最大频繁项集为频繁 2-项集{A:8,C:8}。由于 A 的条件模式基为空,因此可以不用去挖掘了。
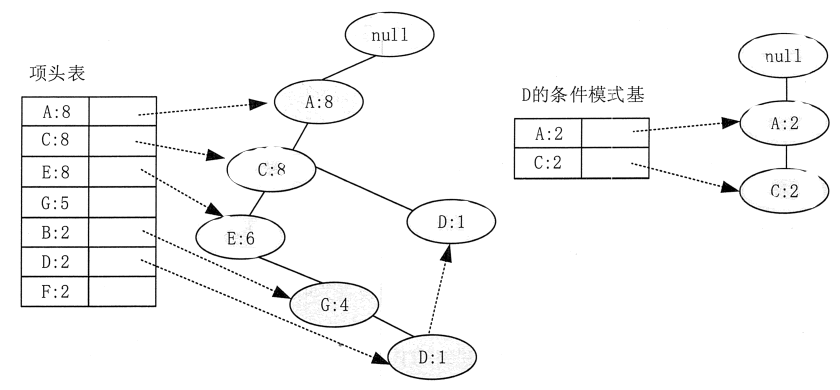
图 4 FP-Tree的挖掘示意2
至此得到了所有的频繁项集,如果只是要最大的频繁 k-项集,则从上面的分析可以看到,最大的频繁项集为 5-项集,包括{A:2,C:2,E:2,B:2,F:2}。
3. MLlib 的 FP-Growth 算法实例
Spark MLlib 中 FP-Growth 算法的实现类 FPGrowth 具有以下参数。
class FPGrowth private (
private var minSupport: Double,
private var numPartitions: Int) extends Logging with Serializable
变量的含义如下。
- minSupport 为频繁项集的支持度阈值,默认值为0.3。
- numPartitions 为数据的分区个数,也就是并发计算的个数。
首先,通过调用 FPGrowth.run 方法构建 FP-Growth 树,树中将会存储频繁项集的数据信息,该方法会返回 FPGrowthModel;然后,调用 FPGrowthModel.generateAssociationRules 方法生成置信度高于阈值的关联规则,以及每个关联规则的置信度。
实例:导入训练数据集,使用 FP-Growth 算法挖掘出关联规则。该实例使用的数据存放在 fpg.data 文档中,提供了 6 个交易样本数据集。样本数据如下所示。
r z h k p
z y x w v u t s
s x o n r
x z y m t s q e
z
x z y r q t p
数据文件的每一行是一个交易记录,包括了该次交易的所有物品代码,每个字母表示一个物品,字母之间用空格分隔。
实现的代码如下所示。
- import org.apache.spark.mllib.fpm.FPGrowth import org.apache.spark.{SparkConf,SparkContext}
- object FP_GrowthTest {
- def main(args:Array[String]){
- val conf = new SparkConf().setAppName(“FPGrowthTest”).setMaster(“local[4]”)
- val sc = new SparkContext(conf)
- //设置参数
- val minSupport = 0.2 //最小支持度
- val minConfidence = 0.8 //最小置信度
- val numPartitions = 2 //数据分区数
- //取出数据
- val data = sc.textFile(“data/mllib/fpg.data”)
- //把数据通过空格分割
- val transactions = data.map (x=>x.split (“”))
- transactions.cache()
- //创建一个 FPGrowth 的算法实列
- val fpg = new FPGrowth()
- fpg.setMinSupport(minSupport)
- fpg.setNumPartitions(numPartitions)
- //使用样本数据建立模型
- val model = fpg.run(transactions)
- //查看所有的频繁项集,并且列出它出现的次数
- model.freqItemsets.collect().foreach(itemset=>{
- printIn (itemset.items.mkString(“[“,“,”,“]”)+itemset.freq)
- })
- //通过置信度筛选出推荐规则
- //antecedent 表示前项,consequent 表示后项
- //confidence 表示规则的置信度
- model.generateAssociationRules(minConfidence).collect().foreach(rule=>{printIn(rule.antecedent.mkString(“,”)+“–>” + rule.consequent.mkString(“”)+“–>”+rule.confidence)
- })
- //查看规则生成的数量
- printIn(model.generateAssociationRules (minConfidence).collect().length)
运行结果会打印频繁项集和关联规则。
部分频繁项集如下。
[t] , 3
[t, x] ,3
[t, x, z] , 3
[t, z] , 3
[s] , 3
[s, t] , 2
[s, t, x] , 2
[s, t, x, z] , 2
[s, t, z], 2
[s, x] , 2
[s, x, z] , 2
部分关联规则如下。
S、T、X - > Z - > 1.0
S、T、X - > Y - > 1.0
Q、X - > T - > 1.0
Q、X - > Y - > 1.0
Q、X - > Z - > 1.0
Q 、Y、Z - > T - > 1.0
Q、Y、Z - > X - > 1.0
T、X、Z - > Y - > 1.0
、Q、X、Z - > T - > 1.0
、Q、X、Z - > Y - > 1.0
57 協会は、データマイニング解析ルール
58 アプリオリアルゴリズムとFP-ツリー・アルゴリズム
59 の大規模なデータ精度のマーケティングに基づいて、
60 ベースのパーソナライズされた推薦システムビッグデータ
61 ビッグデータ予測
62. 他のビッグデータアプリケーション
63を。ビッグデータとは、産業界で使用可能な
64の金融業界では、大規模なアプリケーションデータ
65 インターネット業界におけるビッグデータアプリケーション
66 物流業界におけるビッグデータの応用