参照します。https://www.cnblogs.com/secondtonone1/p/7076769.html
基本的な考え方は、大きな同時実行サーバフレームワークのデザインについて話をするのは簡単です
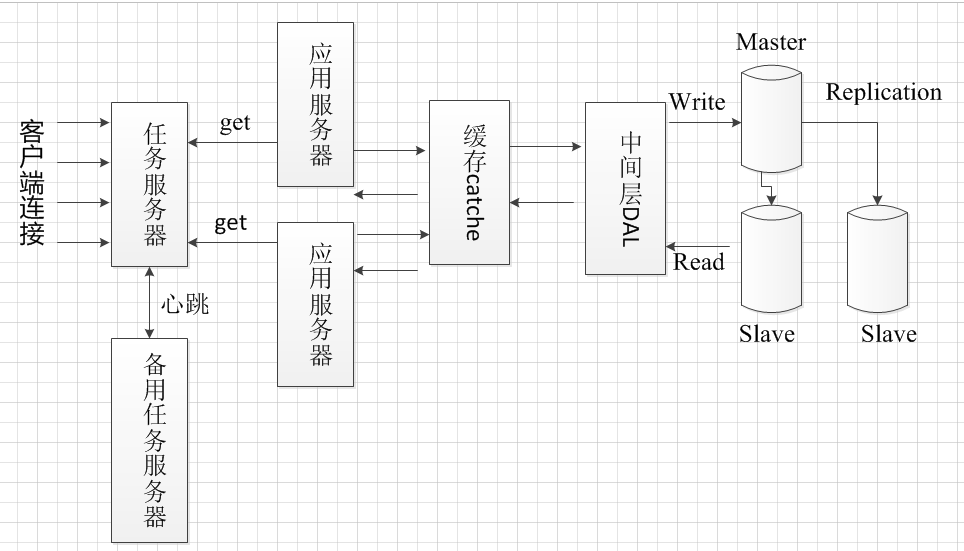
サーバフレームワークは、実質的にC / S構造であり、対応する要求処理は、そのようなものです。
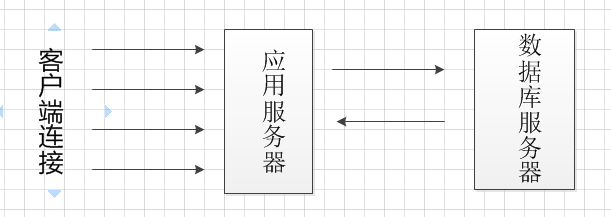
クライアントは、大規模な同時到着を要求非常に深刻な問題、のためのフレームワークがあり、サーバーは、データベース操作の多くを必要とし、データベースが想定される最大接続数
1000万の要求は、アプリケーションサーバへのアクセスがあり、この時間は、アプリケーションサーバは、要求に対処するために1000の要求、そして1000年を待って、残りの99,000を扱うことができます
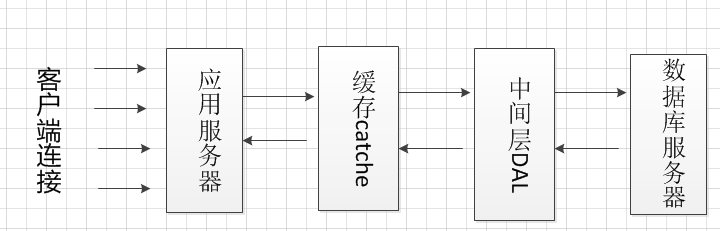
次に、データベース処理にアクセスします。DAL中間層は、アプリケーションサーバおよびデータベースサーバの中央、およびDAL接続プールの設計を使用してバッファキューに増加させることができます。

DALのデザインバッファキュー、待機中のストレージ要求、DALの設計およびデータベース接続プール、プールのデータベース接続の無料接続があり、
次にようにバッファキューおよび要求処理から取り出し、。このアプローチは、事実上、サーバー上の圧力を下げるが、処理速度を増加させません、
要求がキャッシュされ、プロセスの効率はまだ同時データベースの数に制限されていることを保証するだけです。あなたは、このような共通のデータローディングバッファとして、バッファ層を追加することができ、
リクエストが来た場合、キャッシュにデータがある場合はキャッシュにない場合、あなたは、データベースへのアクセスを必要としない、データ・キャッシュを取得するには、アプリケーション・サーバーを起動し、
データベースアクセスのデータを削除し、キャッシュを更新します。
どのようにキャッシュの同期?
2つの手段があります。
最初の方法:キャッシュは当時、データベースクエリに、キャッシュミスならば、一定時間のタイムアウトタイムアウト後、時効です、
更新クエリキャッシュの後、この方法は、リアルタイム、リアルタイム貧弱ではありません。
第二の方法が、データバッファを変更する要求がある更新され、データがDAL、データベース接続のアイドル、次いで永続に変更する場合
保存します。
キャッシュの欠点:
キャッシュは十分な大きさであるときは、キャッシュフィードと呼ばれる、非アクティブ・データ・キャッシュ・メモリをスワップアウトする必要があります。キャッシングアルゴリズムと同様のオペレーティングシステムのページング・アルゴリズム、FIFO、LRU(最低使用頻度)スワップアウトされ、
LFU(最も頻繁に使用される)など。実際のキャッシュ実装を達成するために行く必要はありません、多くのオープンソース技術は、NoSQLの技術は、非リレーショナルデータベースの意味です。
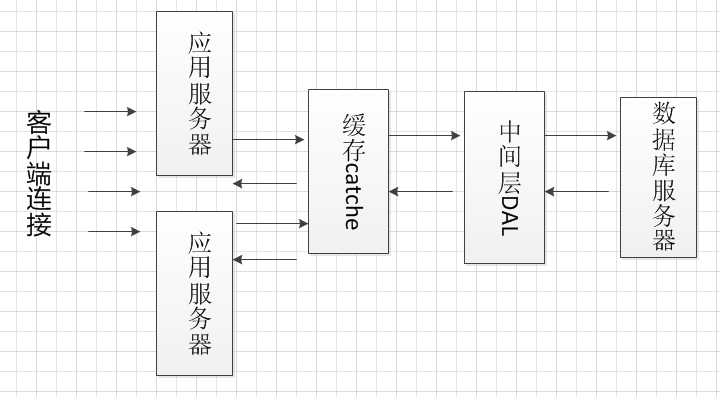
このようようにmemcatchedやRedisの、などの非リレーショナルデータベース。キャッシュは、同じマシン上のアプリケーション・サーバーにデプロイすることができ、それは別のマシンに展開することができます。私はに配備キャッシュサーバーをお勧めします
別のマシンでは、キャッシュは異なるアプリケーションサーバにデプロイされる場合は、2つのアプリケーションサーバーがあるとし、異なるアプリケーションサーバは、互いのキャッシュ、非常に不便にアクセスすることは困難です。キャッシュ
単一サーバー上にデプロイ、各アプリケーションサーバは、キャッシュサーバにアクセスすることができます。
サービス要求の多数のアプリケーションサーバの複数の設計が、到着した場合、キャッシュサーバは、バッファ・キュー・データベース接続プールと中間層を改善するために、セットアップ、
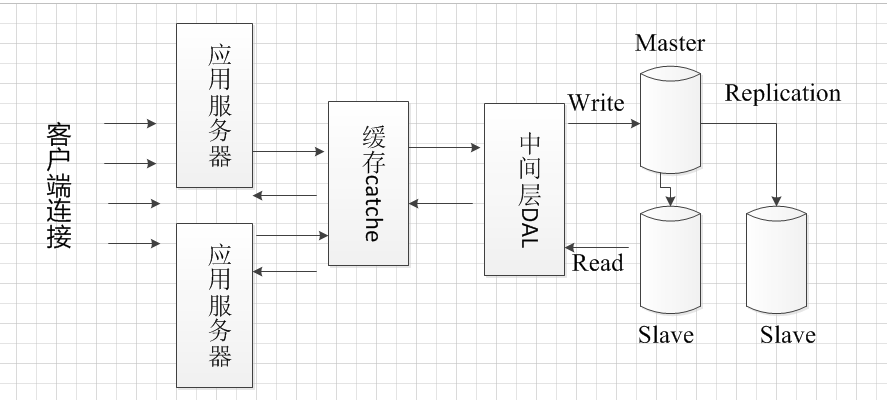
しかし、データベース・サーバのボトルネックは依然として生じます。複雑なデータベース書き込み操作の数が多い、読書の多くのデータベースの操作がブロックされたとき、例えば、我々はこの問題を解決することができます
分離された読み取りおよび書き込みのデータベース。データベース操作が書き込み操作よりも多くなります読んでいるので、あなたは、データベースの負荷分散を行うことができます。主流のデータベースには、レプリケーション・メカニズムを持っています
レプリケーションメカニズムを使用すると、ロードバランシングを実現することができます。マスター・データベースに送ら操作データベース中間層を書き込み、読み出し動作がスレーブデータベースから読み出され、
マスター・データベース内のデータが変更されたとき、データベース複製機構を使用してスレーブデータサーバを同期させます。
同様に、アプリケーションサーバは、アプリケーション・サーバーは、異なるアプリケーションサーバに複数の異なる要求をホストする、負荷分散を達成することができます。
あなたは、各アプリケーションサーバの各アプリケーションサーバへのタスクの合理的な配分をシングルタスクサーバ監視負荷を設計することができます。この方法で
サーバータスクは積極的に、アプリケーションサーバは受動的にタスクを受け入れ、アプリケーション・サーバによう似たタイプでタスク要求をタスクを割り当てます
場合は、分布が非常に合理的です。しかし、我々はアプリケーションサーバAは、3つのタスクを受け入れることを前提とし、アプリケーションサーバBは、負荷分散に合わせて5つのタスクを受け入れます
これらの3つのタスクが複雑な書き込み操作がある場合、5つの簡単なタスクBしている間重量法や最小接続方法は、確かに、Aのタスクに割り当てされますが、
操作、非合理のこの存在の割り当てを読んで、どのようにこの問題を解決するには?

私たちは、アプリケーションサーバがビジー状態の場合、あなたが必要としない、タスクを取得するためのイニシアチブ、イニシアチブは、アプリケーション・サーバーのタスクサーバーを要求するために聞かせて、この問題を解決するための考え方を変更することができます
新しいタスクを要求し、アプリケーションサーバは、タスクのタスク・サーバに要求して自由になり、これが最も合理的な負荷分散です。すべてのアプリケーションサーバーがビジー状態であれば、
那么任务服务器将任务缓存至自己的任务队列,当应用服务器空闲时会来取任务。
考虑这样一个问题,如果任务服务器出现故障怎么办?
任务服务器需要有多台,并且实现failover机制,多台任务服务器之间实现心跳,如果检测不到对方心跳,则使自己成为主任务服务器。
到目前为止,这个框架可以适用于大部分服务器逻辑。为保证数据库的响应速度和处理效率,可以对数据库进行分区。
数据库分区有两种形式(分库、分表)
分库:数据库可以按照一定的逻辑把表分散到不同的数据库。这叫做垂直分区,就是所每个库的表不同,功能不同。
这样做不常见,因为很大情况下,数据库中各个表是关联的,如果将不同的表分配到不同的数据库中,会存在很多不便。
分表:将一个表的不同数据分配到各个数据库,这样每个数据库的表结构是一样的,只是存储的用户数据不同而已,叫做水平
分区。分表的方式很常见,如果数据库的压力增加,我们就采取分表的方式减少数据库的压力。
另外服务器开发的几个性能杀手:
1 数据拷贝,数据从内核态copy到用户态,或者在用户态之间copy会造成性能损失,尽量采用缓存的方式解决。
2 环境切换 ,多线程上下文切换造成开销。如果服务器是单核的,那么采用状态机方式单线程效果最佳。如果是多核的,
合理采用多线程,可以提升性能。
3 内存分配,可以采用内存池,提前分配。
4 锁竞争,加锁解锁会造成一定的效率衰减。
到此为止,服务器框架介绍完毕。
重剑无锋,大巧不
简单谈一谈大并发服务器框架设计的基本思路
基本的服务器框架都是C/S结构的,请求和相应流程是这样的:
这样的框架存在一个很严重的问题,当客户端大并发请求到来,服务器需要进行大量的数据库操作,假设数据库最大连接数为
1000个,此时有10000个请求访问应用服务器,那么应用服务器只能处理1000个请求,剩下99000个等待1000个请求处理好后
再进行访问数据库处理。可以在应用服务器和数据库服务器中间增加中间层DAL,DAL采用缓冲队列和连接池设计。
DAL设计缓冲队列,存储等待的请求,并且DAL中设计数据库连接池,当数据库连接池中有空闲连接,
那么从缓冲队列中取出一个请求处理,以此类推。这种做法有效的降低了服务器的压力,但是没有提高处理速度,
仅仅保证了请求被缓存,处理效率仍受限于数据库的并发数。那么可以再增加一层缓存,将常用的数据加载如缓存,
有请求到来时,应用服务器先从缓存中获取数据,如果缓存中有数据,那么不需要访问数据库,如果缓存中没有,
在访问数据库取出数据,并更新缓存。
缓存如何同步?
有两种手段:
第一种方法: 缓存是具有时效的,在一定时间过后会超时timeout,如果缓存失效,那么重新去数据库查询,
查询后更新缓存,这种方法不是实时的,实时性比较差。
第二种方法:当有请求修改数据时,更新缓存,并且将要修改的数据投入DAL层,当数据库有空闲连接时,再持久化
存盘。
缓存的不足之处:
当缓存足够多时,需要将不活跃缓存数据换出内存,叫做缓存换页。缓存换出算法和操作系统换页算法类似,FIFO,LRU(least recently used),
LFU(least frequently used)等。实际缓存的实现不需要自己去实现,有很多开源技术,nosql技术就是非关系型数据库的意思。
非关系型数据库如redis,memcatched等。缓存可以跟应用服务器部署在同一台机器上,也可以部署在单独机器上。我推荐将缓存服务器部署在
单独机器上,假设有两台应用服务器,如果将缓存部署在不同的应用服务器上,那么不同的应用服务器很难访问彼此的缓存,非常不方便。将缓存
部署在单独服务器上,各个应用服务器都能访问该缓存服务器。
如果有大量的业务请求到来,虽然设计了多个应用服务器,也架设了缓存服务器,完善了中间层的缓冲队列和数据库连接池,
但是数据库服务器仍然会出现瓶颈。比如当有大量复杂的写操作数据库,很多读数据库的操作就被阻塞了,为解决这个问题可
将数据库实现读写分离。由于数据库读操作会比写操作多,那么可以对数据库执行负载均衡。主流数据库都有replication机制,
采用replication机制可以实现负载均衡。中间层的写数据库操作投递到master数据库中,读操作从slave数据库中读取,
当master数据库中数据被修改后,数据库采用replication机制将数据同步给slave服务器。
同样的道理,应用服务器也可以实现负载均衡,架设多个应用服务器,不同的请求分配给不同的应用服务器。
可单独设计一个任务服务器监控各个应用服务器的负载情况,合理的分配任务给各个应用服务器。这种方式
是任务服务器主动地分配任务给应用服务器,应用服务器被动的接受任务,这种方式在任务请求类型相近的
情况下,分配方式非常合理。但是假设应用服务器A接受了3个任务,应用服务器B接受了5个任务,按照负载均衡的
权重法或最小连接法,肯定会分配给A任务,但是如果这3个任务都是复杂的写操作,而B的5个任务都是简单的
读操作,那么这就存在分配的不合理性,如何解决这个问题呢?
可以换一种思路去解决这个问题,让应用服务器主动去请求任务服务器,主动获取任务处理,如果应用服务器处于忙碌状态就不需要
请求新的任务,空闲的应用服务器会去请求任务服务器中的任务,这是最合理的负载均衡。如果所有应用服务器都处于忙碌状态,
那么任务服务器将任务缓存至自己的任务队列,当应用服务器空闲时会来取任务。
考虑这样一个问题,如果任务服务器出现故障怎么办?
任务服务器需要有多台,并且实现failover机制,多台任务服务器之间实现心跳,如果检测不到对方心跳,则使自己成为主任务服务器。
到目前为止,这个框架可以适用于大部分服务器逻辑。为保证数据库的响应速度和处理效率,可以对数据库进行分区。
数据库分区有两种形式(分库、分表)
分库:数据库可以按照一定的逻辑把表分散到不同的数据库。这叫做垂直分区,就是所每个库的表不同,功能不同。
这样做不常见,因为很大情况下,数据库中各个表是关联的,如果将不同的表分配到不同的数据库中,会存在很多不便。
分表:将一个表的不同数据分配到各个数据库,这样每个数据库的表结构是一样的,只是存储的用户数据不同而已,叫做水平
分区。分表的方式很常见,如果数据库的压力增加,我们就采取分表的方式减少数据库的压力。
另外服务器开发的几个性能杀手:
1 数据拷贝,数据从内核态copy到用户态,或者在用户态之间copy会造成性能损失,尽量采用缓存的方式解决。
2 环境切换 ,多线程上下文切换造成开销。如果服务器是单核的,那么采用状态机方式单线程效果最佳。如果是多核的,
合理采用多线程,可以提升性能。
3 内存分配,可以采用内存池,提前分配。
4 锁竞争,加锁解锁会造成一定的效率衰减。
到此为止,服务器框架介绍完毕。