
2022 年末の ChatGPT の出現以来、人工知能は再び世界の注目を集めており、大規模言語モデル (LLM) に基づく AI は人工知能の分野で「注目のチキン」となっています。それ以来 1 年間、私たちは文生テキストと文生写真の分野における AI の急速な進歩を目の当たりにしてきましたが、文生ビデオの分野の発展は比較的遅かったです。 2024 年の初めに、OpenAI は再び大ヒット作、Vincent のビデオ モデル ソラをリリースしました。コンテンツ作成パズルの最後のピースは AI によって完成されました。
1年前、スミスがヌードルを食べる動画がソーシャルメディアで拡散した。その写真では、俳優は醜い顔立ち、歪んだ姿勢でスパゲッティを食べていた。この恐ろしい写真は、当時 AI 生成ビデオの技術がまだ初期段階にあったことを思い出させます。

わずか1年後、Soraが生成した「東京の街を歩くおしゃれな女性」のAI動画が再びソーシャルメディアを炎上させた。翌年の 3 月、ソラは世界中のアーティストと協力して、伝統を覆す超現実的なアート短編映画シリーズを正式に開始しました。次の短編映画「Air Head」は、有名な監督ウォルターとソラによって制作されました。絵は精巧で本物そっくりで、内容はワイルドで想像力豊かです。 Sora は、デビュー時に Gen-2、Pika、Stable Video Diffusion などの主流の AI ビデオ モデルを「粉砕」したと言えます。

AIの進化は予想をはるかに超えており、近い将来、ショートビデオ、ゲーム、映画やテレビ、広告などの既存の産業構造が大きく変わることは容易に予測できます。ソラの登場により、世界構築のモデルにまた一歩近づいたようです。
なぜソラはあんなに強力な魔法を持っているのでしょうか?どのような魔法の技術が使われているのでしょうか?この記事では、公式技術レポートと多くの関連文書を検討した後、著者が Sora の背後にある技術原則とその成功の鍵について説明します。
1 ソラが解決したい中心的な問題は何ですか?
一言でまとめると、Sora が直面している課題は、複数種類のビジュアル データをどのように統一的な表現方法に変換して、統一的なトレーニングを実行できるようにするかということです。
なぜ統一トレーニングが必要なのでしょうか?この質問に答える前に、まず Sora の以前の主流の AI ビデオ生成のアイデアを見てみましょう。
1.1 ソラ以前のAI動画生成手法
- 単一フレームの画像コンテンツに基づいて展開します
単一フレーム画像に基づく拡張機能は、現在のフレームの内容を使用して次のフレームを予測します。各フレームは前のフレームの続きであるため、連続したビデオ ストリームが形成されます (ビデオの本質はフレームごとに連続的に表示される画像です)。 。
このプロセスでは、通常、テキストの説明を使用して画像が生成され、その画像に基づいてビデオが生成されます。ただし、このアイデアには問題があります。テキストを使用して画像を生成すること自体がランダムであり、画像を使用してビデオを生成すると、このランダム性が 2 倍に増幅され、最終的なビデオの制御性と安定性が非常に低くなります。
- ビデオ全体を直接トレーニングする
単一フレームの導出に基づくビデオ効果は良くないため、アイデアはビデオ全体をトレーニングすることに変更されます。
ここでは、通常、数秒のビデオ クリップが選択され、そのビデオが何を示しているかがモデルに伝えられます。AI は、トレーニング データに似たスタイルのビデオ クリップを生成する方法を学習します。このアイデアの欠点は、AIが学習する内容が断片的であり、長い動画の生成が難しく、動画の連続性が低いことです。
なぜトレーニングに長いビデオを使用しないのかと疑問に思う人もいるかもしれません。主な理由は、ビデオはテキストや画像に比べて非常に大きく、グラフィック カードのビデオ メモリが限られており、長時間のビデオ トレーニングをサポートできないことです。さまざまな制約がある中で、AI の知識量は非常に限られており、「知らない」内容を入力すると、満足のいく結果が得られないことがよくあります。
したがって、AI ビデオのボトルネックを突破したい場合は、これらの中核的な問題を解決する必要があります。
1.2 ビデオモデルトレーニングの課題
ビデオ データには、横画面から縦画面、240p から 4K、さまざまなアスペクト比、さまざまな解像度、さまざまなビデオ属性など、さまざまな形式があります。データの複雑さと多様性は AI トレーニングに大きな困難をもたらし、それが結果的にモデルのパフォーマンスの低下につながります。このため、まずこれらのビデオ データを統一した方法で表現する必要があります。
Sora の中心的なタスクは、すべてのビデオ データを統一フレームワークの下で効果的にトレーニングできるように、複数の種類のビジュアル データを統一表現方法に変換する方法を見つけることです。
1.3 Sora: AGI に向けたマイルストーン
私たちの使命は、汎用人工知能が人類すべてに利益をもたらすことを保証することです。 —— OpenAI
OpenAI の目標は常に明確で、汎用人工知能 (AGI) を実現することですが、Sora の誕生は OpenAI の目標を達成する上でどのような意味を持つのでしょうか?
AGI を実装するには、大規模なモデルが世界を理解する必要があります。 OpenAI の開発全体を通じて、初期の GPT モデルでは AI がテキスト (1 次元、長さのみ) を理解できるようになり、その後発表された DALL・E モデルでは AI が画像 (2 次元、長さと幅) を理解できるようになり、現在では The Sora モデルが登場しています。 AI がビデオ (3 次元、長さ、幅、時間) を理解できるようにします。
AIはテキスト、画像、ビデオを総合的に理解することで、徐々に世界を理解できるようになります。Sora は、OpenAI の AGI の前哨基地であり、技術レポート [1] のタイトルに「ワールド シミュレータとしてのビデオ生成モデル」とあるように、単なるビデオ生成モデルではありません。
Tuoshupai のビジョンは OpenAI の目標と一致しています。拡張主義者らは、少数のシンボルと計算モデルを使用して人間社会と個人の知能をモデル化することが初期の AI の基礎を築いたが、より多くの利益はより大量のデータとより高い計算能力に依存すると信じています。画期的な新しいモデルを構築できない場合は、より多くのデータ セットを探し、より大きなコンピューティング能力を使用してモデルの精度を向上させ、データ コンピューティング能力をモデル能力と交換し、データ コンピューティング システムの革新を推進できます。Tuoshupai がリリースした大型モデル データ コンピューティング システムでは、AI 数理モデル、データ、計算がこれまでにないほどシームレスに接続され、相互に強化され、社会の質の高い発展を促進する新たな生産力となります [2]。
2 ソラ原理の解釈
ソラは、リリースされた最初のヴィンセントビデオモデルではないのに、なぜこれほどの騒動を引き起こしているのでしょうか?その背後にある秘密は何ですか? Sora のトレーニング プロセスを一言で説明すると、元のビデオはビジュアル エンコーダーを通じて潜在空間に圧縮され、時空間パッチに分解され、テキストと結合されます。 条件付き制約を使用して拡散トレーニングとトランスフォーマーによる生成が行われます。画像ブロックは最終的に、対応するビジュアル デコーダを通じてピクセル空間にマッピングされます。
2.1 ビデオ圧縮ネットワーク
Sora はまず、生のビデオ データを低次元の潜在空間特徴に変換します。私たちが毎日見るビデオデータは大きすぎるため、まず AI が処理できる低次元ベクトルに変換する必要があります。ここで、OpenAI は古典的な論文である潜在拡散モデルを利用しています [3]。
この論文の中心点は、元の画像を潜在空間特徴に洗練することであり、これにより、元の画像の重要な特徴情報を保持できるだけでなく、データと情報の量を大幅に圧縮できます。
OpenAI は、ビデオ データの処理をサポートするために、この論文の画像の変分オートエンコーダー (VAE) をアップグレードした可能性があります。このようにして、Sora は、大量の元のビデオ データを低次元の潜在空間特徴に変換できます。つまり、ビデオの主要なコンテンツを表すことができるビデオ内のコア キー情報を抽出できます。
2.2 時空パッチ
大規模な AI ビデオ トレーニングを実行するには、まずトレーニング データの基本単位を定義する必要があります。大規模言語モデル (LLM) では、トレーニングの基本単位は Token[4] です。 OpenAI は、ChatGPT の成功からインスピレーションを得ています。トークン メカニズムは、コード、数学記号、さまざまな自然言語など、さまざまな形式のテキストをエレガントに統合します。Sora はその「トークン」を見つけることができるでしょうか。
過去の研究結果のおかげで、ソラはついにパッチという答えを見つけました。
- ビジョントランスフォーマー(ViT)
パッチとは何ですか?パッチは、口語的には画像ブロックとして理解できます。処理する画像の解像度が高すぎる場合、直接学習することは現実的ではありません。そこで、論文 Vision Transformer [5] では、元の画像を同じサイズの画像ブロック (Patch) に分割し、これらの画像ブロックをシリアル化して位置情報を追加する (Position Embedding) という方法が提案されています。セルフアテンション メカニズムを使用して各画像ブロック間の関係をキャプチャし、最終的に画像全体の内容を理解することで、Transformer アーキテクチャで最もよく知られたシーケンスに変換できます。
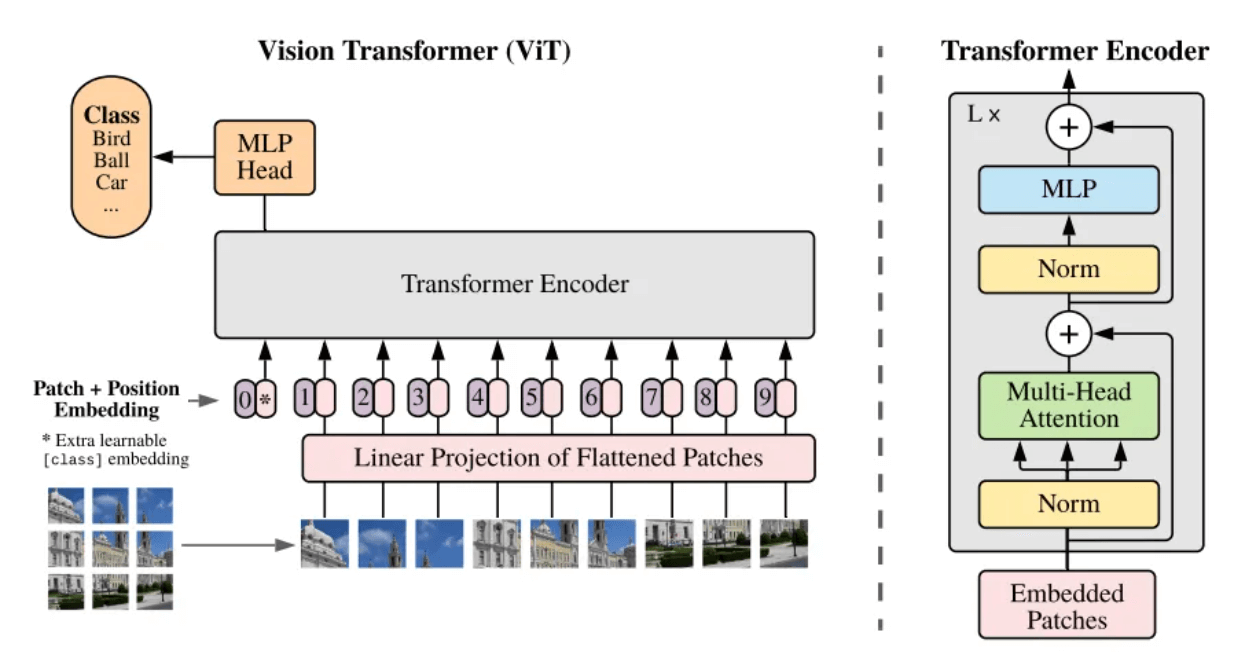
ViTモデルのフレームワーク構造[5]
ビデオは時間軸に沿って分散された一連の画像として見ることができるため、Sora は時間の次元を追加し、静止画像ブロックを時空画像パッチ (時空パッチ) にアップグレードします。各時空間画像ブロックには、ビデオ内の時間情報と空間情報の両方が含まれています。つまり、時空間画像ブロックは、ビデオ内の小さな空間領域を表すだけでなく、一定期間にわたるこの空間領域の変化も表します。時間。
パッチの概念を導入することにより、単一フレーム内の異なる位置にある時空間画像ブロックの空間相関を計算でき、連続するフレーム内の同じ位置にある時空間画像ブロックの時間相関を計算できます。各画像ブロックはもはや孤立して存在するのではなく、周囲の要素と密接に関連しています。このようにして、Sora は、豊富な空間的詳細と時間的ダイナミクスを備えたビデオ コンテンツを理解して生成することができます。

シーケンスフレームを時空間画像ブロックに分解する
- ネイティブ解像度(NaViT)
ただし、ViT モデルには非常に大きな欠点があります。元の画像は正方形でなければならず、各画像ブロックは同じ固定サイズでなければなりません。毎日の動画は横幅か縦幅のみで、正方形の動画はありません。
したがって、OpenAI は別の解決策を見つけました。それは、任意の解像度とアスペクト比の入力コンテンツを処理できる、NaViT の「Patch n' Pack」テクノロジー [6]です。
このテクノロジーは、異なるアスペクト比と解像度のコンテンツを画像ブロックに分割し、さまざまなニーズに応じて画像ブロックのサイズを変更して、統合トレーニングのために同じシーケンスに柔軟にパッケージ化できます。さらに、このテクノロジーは画像の類似性に基づいて同一の画像ブロックを破棄することもできるため、トレーニングのコストが大幅に削減され、トレーニングの高速化が実現します。
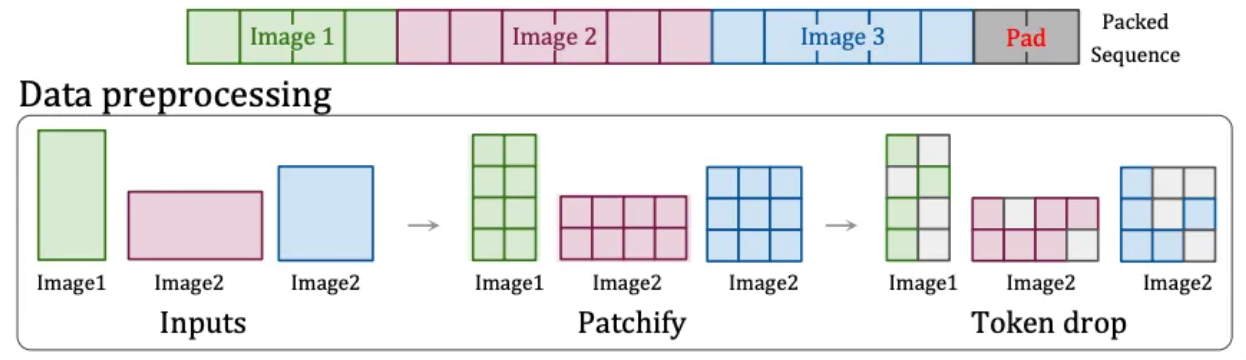
パッチアンドパックテクノロジー[6]
これが、Sora がさまざまな解像度とアスペクト比のビデオの生成をサポートできる理由です。さらに、ネイティブのアスペクト比を使用してトレーニングすると、出力ビデオの構成とフレーミングを改善できます。これは、トリミングによって必然的に情報が失われ、モデルが元の画像の主な内容を誤解しやすくなり、その結果、主な部分の一部しか含まれない画像が生成されるためです。体。
時空間パッチが果たす役割は、大規模言語モデルにおけるトークンの役割と同じです。これは、ビデオを一連の時空間パッチに圧縮して分解するときに、実際に連続的な視覚情報を次のようなものに変換します。モデルによって処理できる一連の個別ユニット。モデルの学習と生成の基礎となります。
2.3 ビデオテキストの説明
上記の説明を通じて、Sora がオリジナルのビデオを最終的な学習可能な時空間ベクトルに変換するプロセスを理解しました。しかし、実際のトレーニングの前に解決する必要がある問題が 1 つあります。それは、このビデオの内容をモデルに伝えることです。
Wensheng ビデオ モデルをトレーニングするには、テキストとビデオの間の対応関係を確立する必要があります。トレーニング中に、対応するテキスト説明を含む多数のビデオが必要になります。ただし、手動で注釈が付けられた説明の品質は低く、不規則です。トレーニングの結果。そこで、OpenAI は自社の DALL・E 3 から再字幕技術 [7] を借用し、ビデオ分野に適用しました。
具体的には、OpenAI はまず、高度に説明的な字幕生成モデルをトレーニングし、このモデルを使用して、仕様に従ってトレーニング セット内のすべてのビデオの詳細な説明情報を生成しました。テキスト説明情報のこの部分は、最終段階で前述の時空間画像パッチと結合されました。マッチングとトレーニングの後、ソラはテキストの説明とビデオ画像のブロックを理解して対応できるようになります。
さらに、OpenAI は GPT を使用して、ユーザーの短いプロンプトをトレーニング中のものと同様のより詳細な説明文に変換します。これにより、Sora はユーザーのプロンプトに正確に従い、高品質のビデオを生成できます。
2.4 ビデオのトレーニングと生成
Sora が拡散トランスフォーマーであること、つまり、Sora がバックボーン ネットワークとして Transformer を備えた拡散モデルであることは、公式技術レポート[1]に明記されています。
- 放送トランス(DiT)
拡散の概念は、例えば、インクを水に滴下すると、時間とともにゆっくりとインクが拡散していく過程であることがわかります。一滴から水中の様々な部分に徐々に拡散します。
この拡散プロセスにインスピレーションを得て、ディフュージョンモデルが誕生しました。これは、Stable Diffusion と Midjourney のベースとなる古典的な「描画」モデルです。その基本原理は、元の画像に徐々にノイズを加えて徐々に完全なノイズ状態にしてから、このプロセスを逆に行う、つまりノイズ除去 (Denoise) して画像を復元することです。モデルに多数の反転経験を学習させることにより、モデルは最終的にノイズ画像から特定の画像コンテンツを生成することを学習します。
レポートによると、ソラ氏の手法は、元の拡散モデルの U-Net アーキテクチャを、彼が最もよく知っている Transformer アーキテクチャに置き換える可能性が高いとのことです。他の深層学習タスクの経験によれば、U-Net と比較して、Transformer アーキテクチャのパラメータは拡張性が高いため、パラメータの数が増加するにつれて、Transformer アーキテクチャのパフォーマンスの向上がより明らかになります。
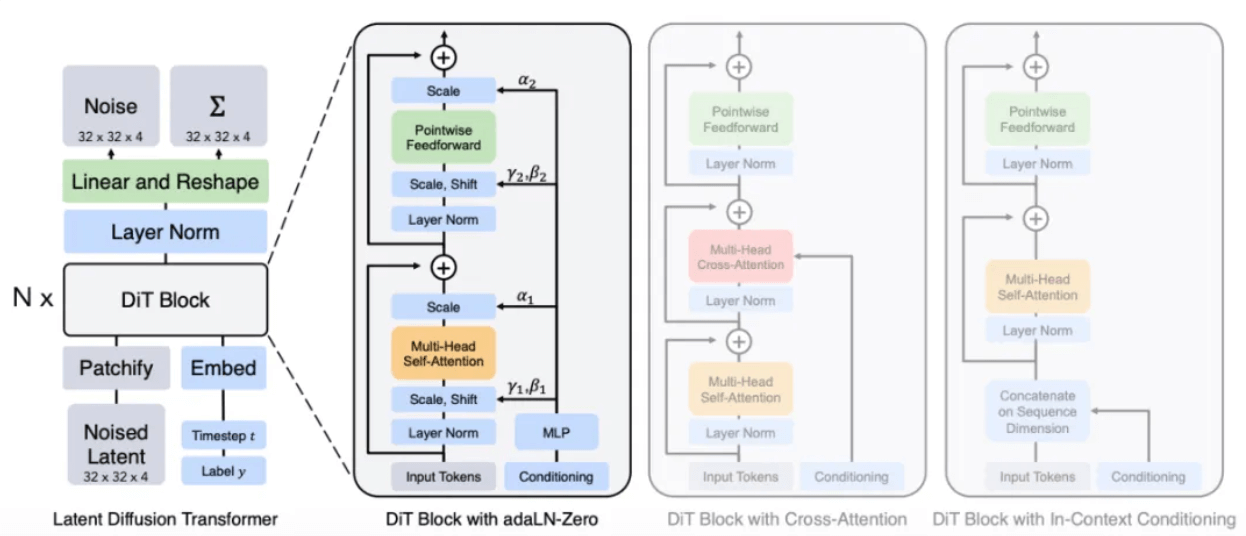
DiT モデルのアーキテクチャ[8]
拡散モデルと同様のプロセスを通じて、トレーニング中にノイズ パッチ (およびテキスト プロンプトなどの条件付き情報) が与えられ、ノイズの追加とノイズ除去が繰り返し行われ、最終的にモデルは元のパッチを予測することを学習します。

ノイズパッチを元の画像パッチに復元します
- ビデオ生成プロセス
最後に、Sora がテキストからビデオを生成するプロセス全体をまとめます。
ユーザーがテキスト説明を入力すると、Sora はまずモデルを呼び出して標準的なビデオ説明文に展開し、次にその説明に基づいてノイズから最初の時空間画像ブロックを生成します。その後、Sora はビデオの生成を続けます。既存の時空間画像ブロックとテキスト条件に基づいて、次の時空間画像ブロックが生成されると推測され (既存のトークンに基づいて次のトークンを予測する GPT と同様)、最後に、生成された潜在的な表現がマッピングされます。対応するデコーダを介してピクセル空間を変換し、ビデオを形成します。
3 データコンピューティングの可能性
Sora の技術レポートを見ると、実際には、Sora は技術的に大きな進歩を遂げていないが、これまでの研究成果をうまく統合していることがわかります。Sora の成功のより重要な理由は、コンピューティング能力とデータの蓄積です。
Sora はトレーニング プロセス中に明らかなスケール効果を示しています。以下の図は、固定入力とシードの場合、計算量が増加するにつれて、生成されるサンプルの品質が大幅に向上することを示しています。

基本演算能力、4倍演算能力、32倍演算能力における効果の比較
さらに、ソラは大量のデータから学習することで、予想外の能力も発揮しました。
➢ 3D の一貫性: Sora は動的なカメラの動きを伴うビデオを生成できます。カメラが移動したり回転したりすると、キャラクターやシーン要素は常に 3 次元空間内で一貫した動きのパターンを維持します。
➢長期的な一貫性とオブジェクトの永続性:ロングショットでは、人、動物、オブジェクトは、遮蔽されたりフレームから外れたりした後でも、一貫した外観を維持します。
➢世界のインタラクティブ性: Sora は、世界の状態に影響を与える動作を簡単な方法でシミュレートできます。たとえば、絵画を説明するビデオでは、各ストロークがキャンバスに跡を残します。
➢デジタルワールドをシミュレート: Sora は、「Minecraft」などのゲームビデオをシミュレートすることもできます。
これらのプロパティは 3D オブジェクトなどに対する明示的な誘導バイアスを必要とせず、純粋にスケール効果の現象です。
4 Tuoshupai 大規模モデル データ コンピューティング システム
Sora の成功は、「より大きな力が奇跡を起こす」戦略の有効性を再び証明しました。モデル規模の継続的な拡大は、パフォーマンスの向上を直接促進します。これは、多数の高品質のデータセットと超強力なデータセットに大きく依存しています。大規模なコンピューティング能力は不可欠です。
佗舟牌は設立当初、自らの使命を「新たな発見のみを目的としたデータコンピューティング」と位置づけ、目標は「無限モデルゲーム」の創造です。同社の大規模モデル データ コンピューティング システムは、クラウド ネイティブ テクノロジーを使用してデータ ストレージとコンピューティングを再構築し、1 つのストレージとマルチエンジン データ コンピューティングを使用して、AI モデルをより大規模かつ高速にし、ビッグ データ システムを大規模モデルの時代に包括的にアップグレードします。
大規模モデル データ コンピューティング システムでは、世界のあらゆるものとその動きをデータに変換し、そのデータを使用して初期モデルをトレーニングし、その後、データ コンピューティング システムに追加します。プロセスは反復され、AI インテリジェンスを無限に探索し続けます。将来的に、Tuoshupai はデータ分野の探索を継続し、コア技術の研究能力を強化し、業界パートナーと協力してデータ要素業界のベストプラクティスを探索し、デジタルインテリジェントな意思決定を促進していきます。
注: OpenAI の公式技術レポートには、一般的なモデリング方法のみが示されており、実装の詳細は含まれていません。この記事に誤りがある場合は、修正してご連絡ください。
参考文献:
- [1]ワールドシミュレータとしてのビデオ生成モデル
- [2]大規模モデルデータ計算システム - 理論
- [3]潜在拡散モデルによる高解像度画像合成
- [4]必要なのは注意力だけです
- [5]画像は 16×16 ワードの価値があります: 大規模な画像認識のためのトランスフォーマー
- [6] Patch n'Pack: NaViT、あらゆるアスペクト比と解像度に対応するビジョン トランスフォーマー
- [7]より良いキャプションによる画像生成の改善
- [8]変圧器を備えたスケーラブルな拡散モデル