
1. 背景
繰り返しの作業とコード標準: B エンド フロントエンド コードの開発プロセス中、開発者は常に繰り返し開発という問題点に直面します。多くの CRUD ページの要素モジュールは基本的に似ていますが、依然として手動で開発する必要があります。単純な要素の構築に時間がかかるため、開発コストが削減され、ビジネス要件に応じた開発効率がまた、さまざまな開発者のコーディング スタイルに一貫性がないため、他の開発者がアジャイル反復中に開始するコストが高くなります。
AI は単純な脳力を置き換えます。大規模な AI モデルの継続的な開発により、AI は単純な理解機能を備え、言語を命令に変換できます。基本ページを構築するための一般的な手順は、日常の基本ページ構築のニーズを満たし、一般的なシナリオでのビジネス開発の効率を向上させることができます。
2. 生成されたリンクのリスト
B 面ページのリスト、フォーム、詳細はすべて生成でき、リンクは大まかに次の手順に分けられます。
-
自然言語を入力してください
-
大規模モデルと組み合わせて、指定されたルールに従って対応する建設情報が抽出されます。
-
コード テンプレートと AST 出力フロントエンド コードを組み合わせたビルド情報
3. ニーズを明示する
グラフィカルな構成
補助コード生成の最初のステップは、どのような種類のインターフェイスを開発するかを指示することです。これに関して、私たちが最初に考えるのは、ユーザーが現在主流のローコード製品形式であるページ構成です。次の図のような一連のグラフィカル構成:
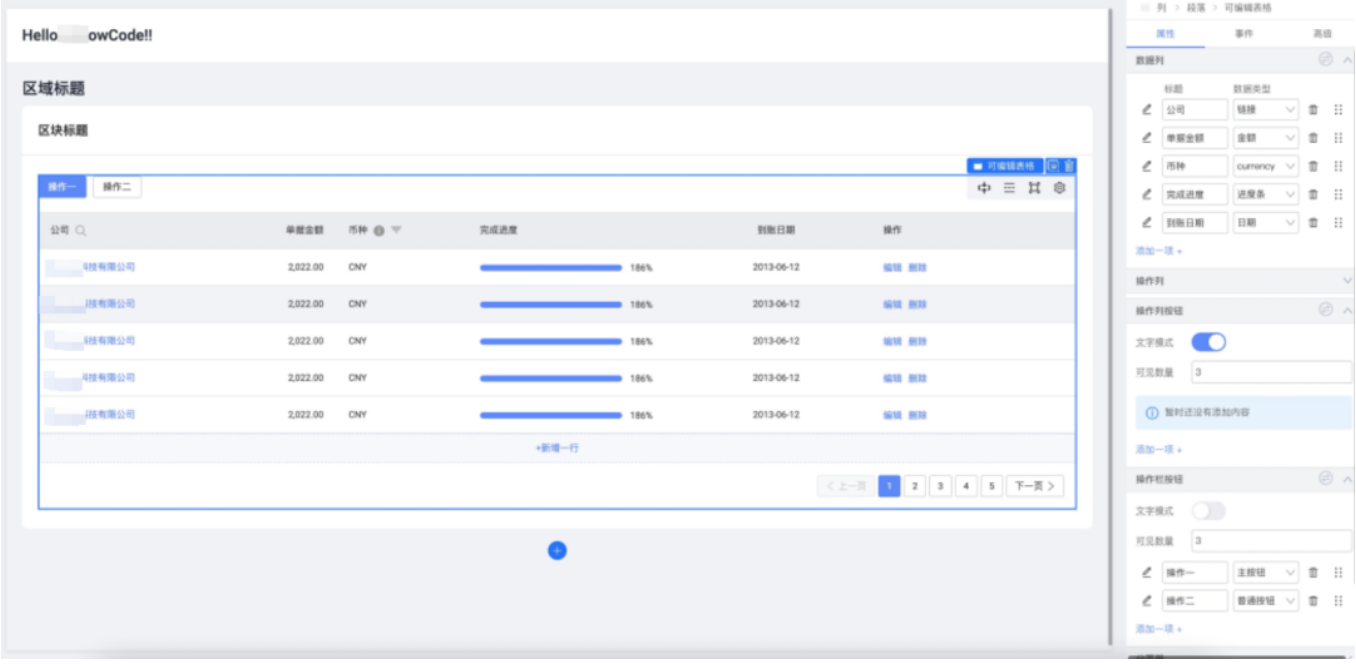
上記の構成方法は、一般的なシナリオ (比較的単純なバックグラウンド ロジックを備えた CURD ページなど) または特定のビジネス シナリオ (会場の構築など) の効率を向上させる効果があります。ロジックの継続的な反復を必要とする比較的複雑な要件の場合、構成はグラフィカル操作を通じて行われるため、対話型設計の要件はより高く、要件の複雑さが増すにつれて、構成は対話形式で行われます。ますます複雑になり、メンテナンスコストはますます高くなっています。したがって、ページ構成でのフロントエンド フィールドの使用は比較的制限されます。
AIが直接コードを生成する
AI によって生成されたコードは主にツールの機能シナリオで使用されますが、企業内の特定のビジネス シナリオのニーズについては、次の点を考慮する必要がある場合があります。
-
カスタマイズの生成:会社のチームには独自のテクノロジー スタックと強力な一般コンポーネントがあり、この知識は事前トレーニングする必要があります。現在、長いテキストの事前トレーニング コンテンツは単一セッション インジェクションのみをサポートしており、トークンの消費量が高くなります。 ;
-
精度: AI によって生成されたコードの精度の課題は比較的大きく、また、事前トレーニングにはプロンプトの大部分が含まれているため、モデルの錯覚と相まって、ビジネス コードの失敗率が高くなります。現時点では比較的高く、精度は補助エンコーディングを検討するための中心的な指標です。これが解決できない場合、補助エンコーディングの効果は大幅に減少します。
-
不完全な生成されたコンテンツ:単一の GPT セッションの制限により、複雑な要件の場合、コード生成が切り詰められ、生成の成功率に影響を与える可能性があります。
自然言語から指示へ
実際、GPT には自然言語を命令に変換するという非常に重要な機能もあります。命令はアクションです。たとえば、関数メソッドが実装されており、入力が自然言語であると仮定します。プロンプトでは、特定のいくつかの単語を安定して出力できますが、これらの単語を出力することでさらにアクションを実行できますか?これには、グラフィカル構成に比べて次の利点があります。
-
学習閾値が低い:自然言語自体が人間の母国語であるため、自分の考えに従ってページを記述すればよいことはもちろん、記述内容は一定の基準に従う必要がありますが、グラフィック構成に比べて効率が高くなります。が大幅に改善されました。
-
複雑さのブラックボックス:構成ページの複雑さに応じてグラフィカル構成の複雑さがユーザーの目の前に表示されるため、ユーザーは複雑な構成ページの操作に迷う可能性があり、構成コストが徐々に増加します。 ;
-
アジャイル反復:ユーザー側にページ構成機能を追加する場合、大規模モデルに基づく対話方式ではいくつかのプロンプトを追加するだけで済みますが、グラフィカル構成では素早い入力を容易にするために複雑なフォームの開発が必要です。
ここで質問があるかもしれません:
生成された命令情報も大きなモデルの錯覚に悩まされるのではありませんか?毎回生成されるコマンド情報の安定性と一貫性を確保するにはどうすればよいでしょうか?
自然言語から命令への変換は、次の理由から実現可能です。
-
長いテキストを重要な情報に変換することは要約コンテンツに属し、要約シナリオにおける大規模なモデルの精度は拡散シナリオよりもはるかに高くなります。
-
指示情報は要件内の重要な情報のみを抽出し、コード技術スタックでの事前トレーニングを必要としないため、プロンプトを最適化する余地が多くあります。プロンプトの内容を最適化および改善することで、出力精度を効果的に向上させることができます。 ;
-
精度は、異なる式要件を入力したシナリオごとに、単一のテスト予測出力を通じて検証できます。 badCase が発生した場合は、最適化後に badCase の単一のテストにアクセスします。精度が向上し続けることを確認します。
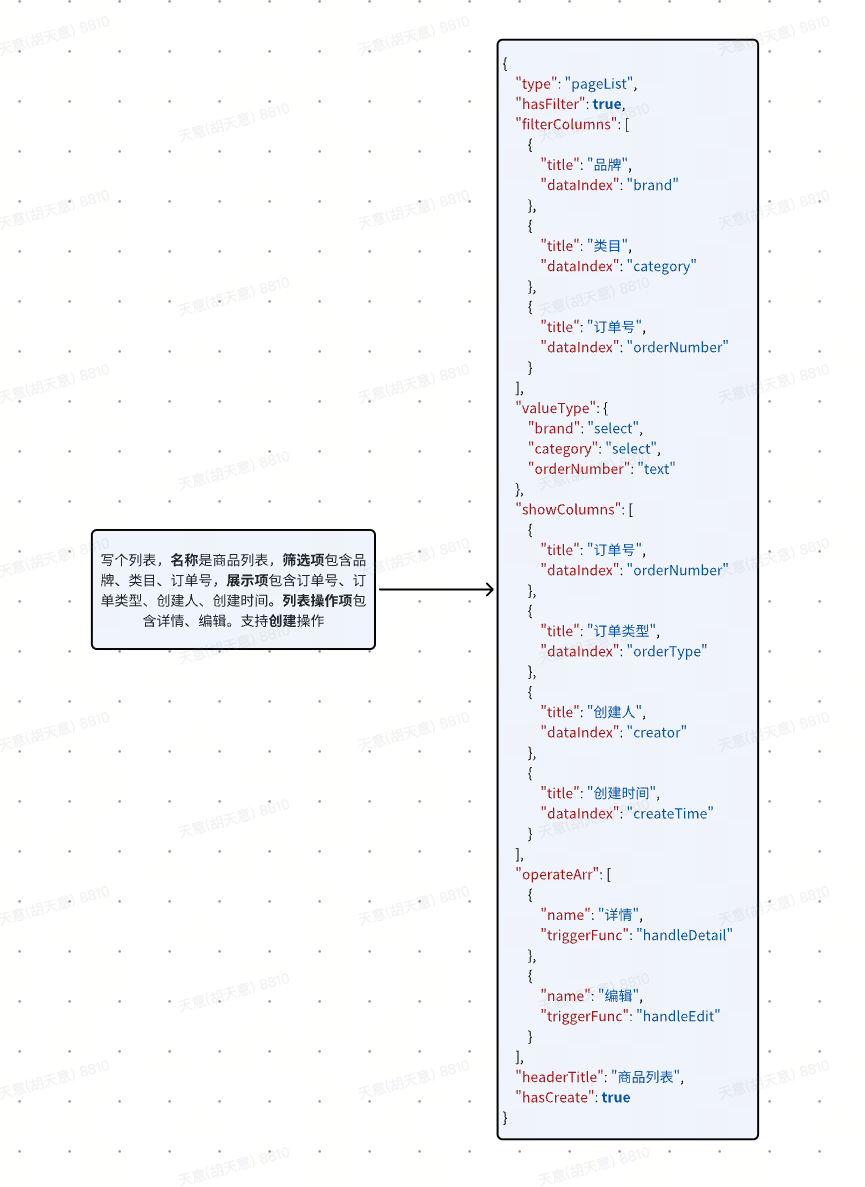
最終的な情報変換結果を見てみましょう。
コード支援の場合、ユーザーの要求の説明に基づいて、そのような情報は PROMPT 処理を通じて取得できます。コード生成のための基本的な情報を提供します。
4. 情報をコードに変換する
大規模モデル (つまり、上記の例では JSON) を通じて自然言語に対応するコード化可能な情報を取得した後、この情報に基づいてコードを変換できます。明確なシナリオを持つページの場合、通常はメイン コード テンプレート (リスト、フォーム、説明フレーム) + ビジネス コンポーネントに分割できます。
変換プロセス

コードはどうやって開発したのでしょうか?
実際、このステップは、要件を取得した後、私たちの脳が重要な情報、つまり上記の自然言語変換命令を抽出し、vscode でファイルを作成することに非常に似ています。次の操作を実行します。
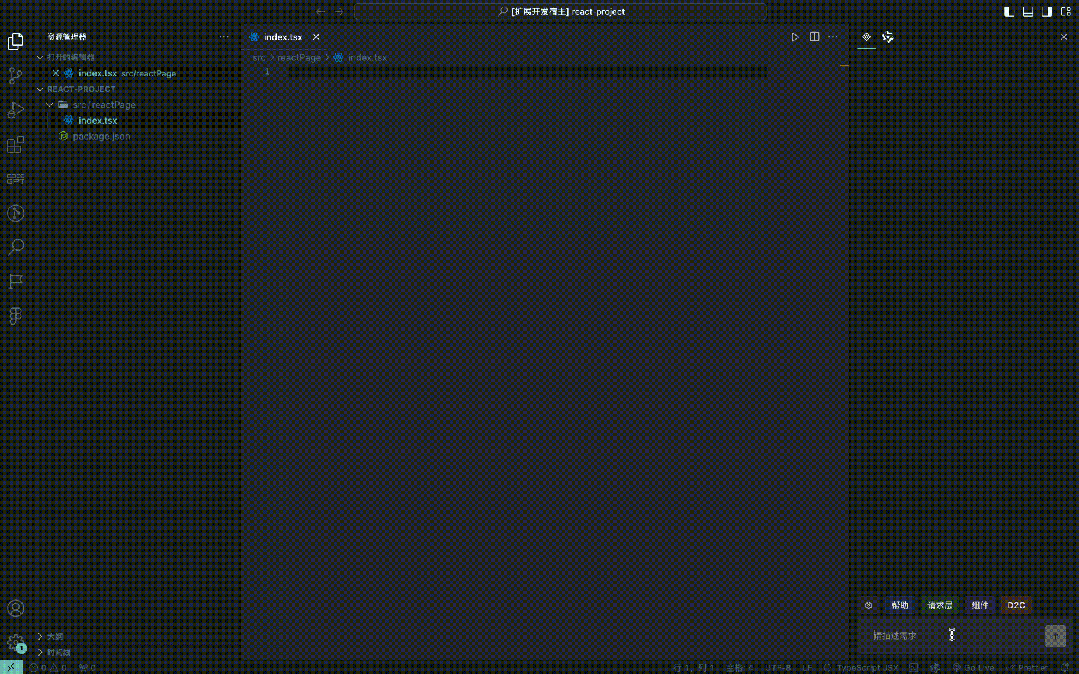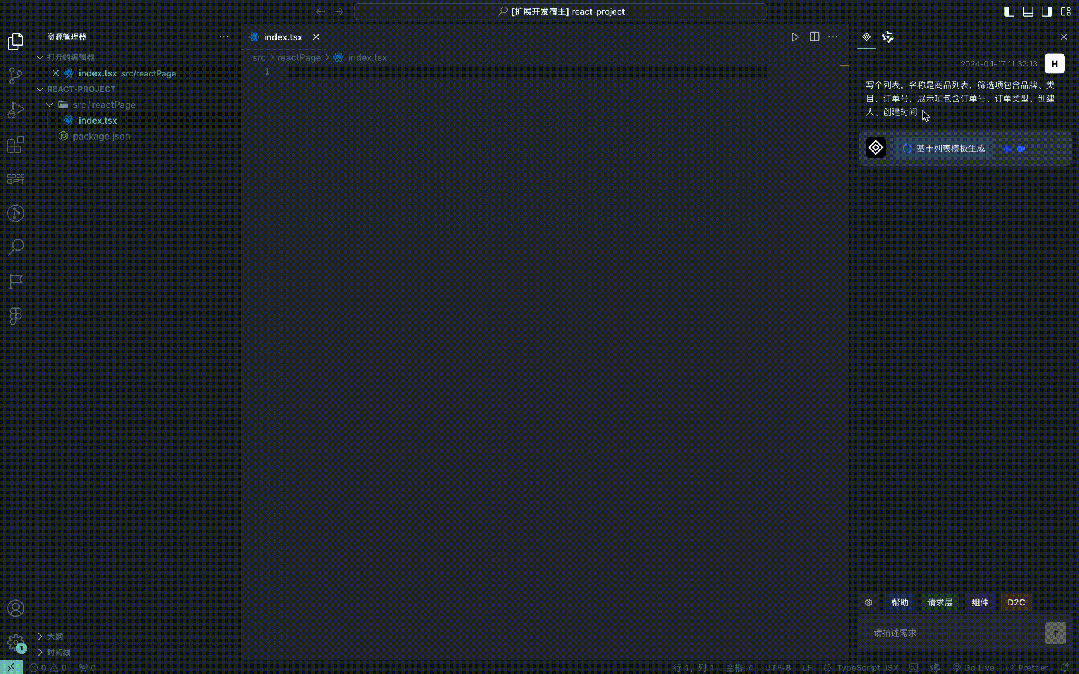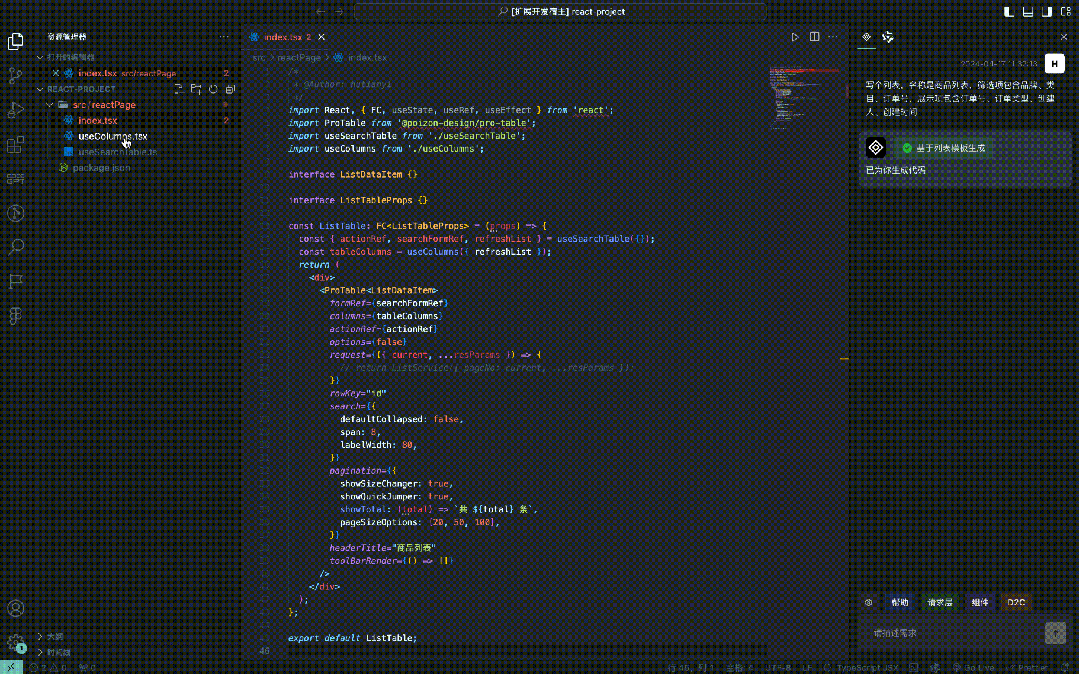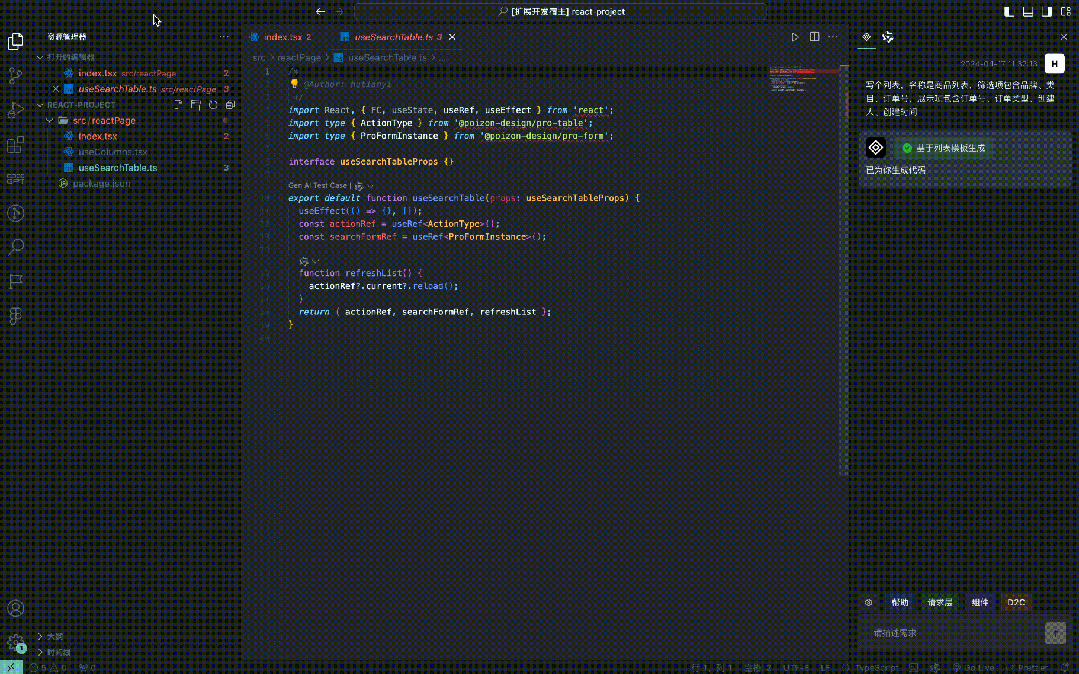
まず、コード テンプレートを作成し、シナリオに応じて対応する高機能コンポーネントを導入する必要があります。たとえば、リストには ProTable、フォームには ProForm を導入します。
ProTable などの強力なコンポーネントに基づいており、それに headerTitle、pageSize、その他のリスト関連情報などのいくつかのプロパティが追加されています。
デマンド記述に従ってコンポーネントを導入します。例えば、フィルタ項目にカテゴリ選択があることが認識されると、useColumnsに新しいビジネスコンポーネントが追加されます。デマンドの説明に応じて、新しいインポートおよびエクスポート ビジネス コンポーネントがページ上の指定された位置に追加されます。
モック リンクを取得し、リクエスト レイヤーを追加して、ページ上の指定された場所に導入します。
上記の一般的なコード挿入シナリオは JSON にカプセル化でき、AST 挿入または文字列テンプレート置換と組み合わせたコード テンプレートを通じて、対応するコードが生成されます。
5. ソースコードの生成
位置
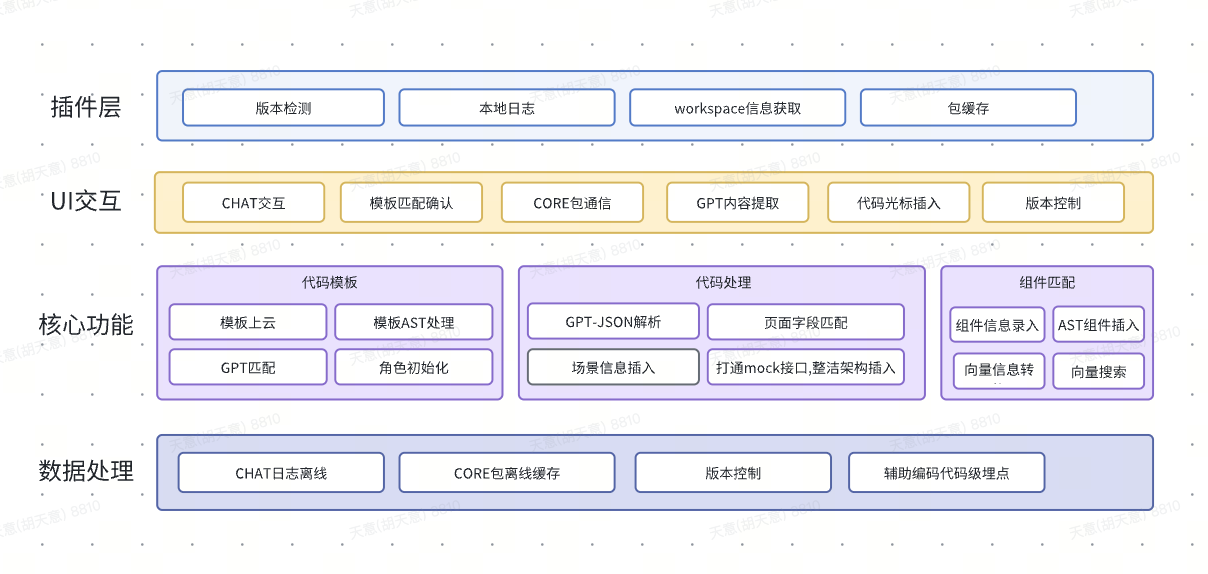
ソース コード支援は主に、開発者が繰り返し行う作業を減らし、コーディング効率を向上させるのに役立ちます。ローコードでは、特定のシナリオで完全なページを構築することに重点が置かれており、ページ関数は数え切れないほどあります。業界のローコード構築にも優れたプラクティスがあります。ソース コード補助ツールは、ユーザーが可能な限り多くのビジネス要件コードを初期化できるように設計されており、その後の変更とメンテナンスはコード レベルでユーザーに引き継がれるため、新しいページの開発効率が向上します。
具体的な機能アーキテクチャを以下に示します。
6. コンポーネントベクトルの検索と埋め込み
フロントエンド開発では、開発するコードを減らすことが重要ですが、一方では、コンポーネントの導入リンクを迅速に最適化するために、より高速なページ生成と適切なコンポーネントの抽出が非常に重要です。初期化テンプレートとストック コード内のコンポーネントを見つけます。
コンポーネントベクトル紹介リンク
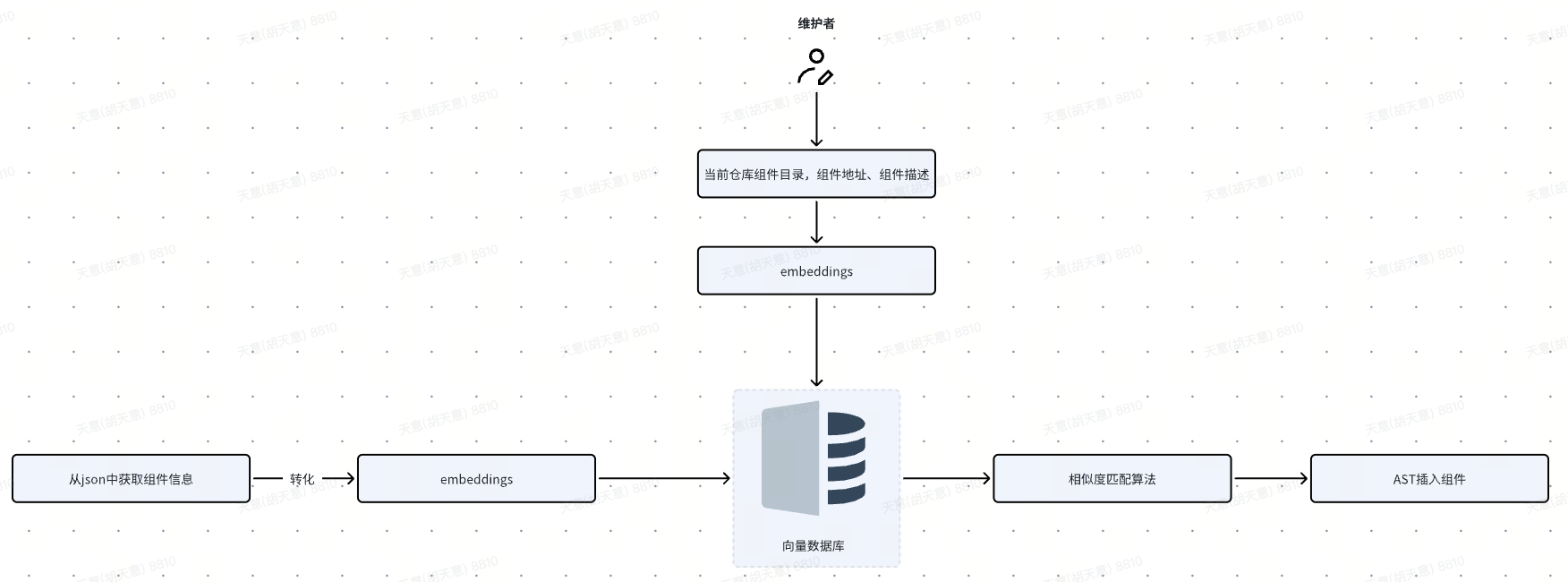
コンポーネント情報の入力
コンポーネントの説明内容とコンポーネント導入パラダイムの迅速な取得をサポートし、ワンクリックでコンポーネントを入力すると、コンポーネントの説明がベクトル データに変換され、ベクトル データベースに保存されます。

コンポーネントベクトル検索
ユーザーが説明を入力すると、その説明はベクトルに変換され、コサイン類似度に基づいてコンポーネント リストと比較され、最も類似性の高い TOP N コンポーネントが検索されます。
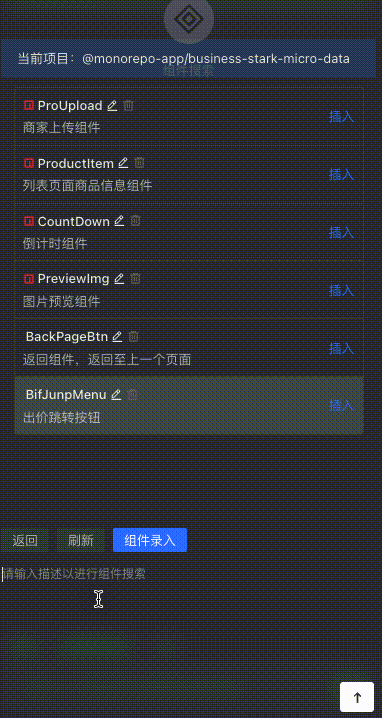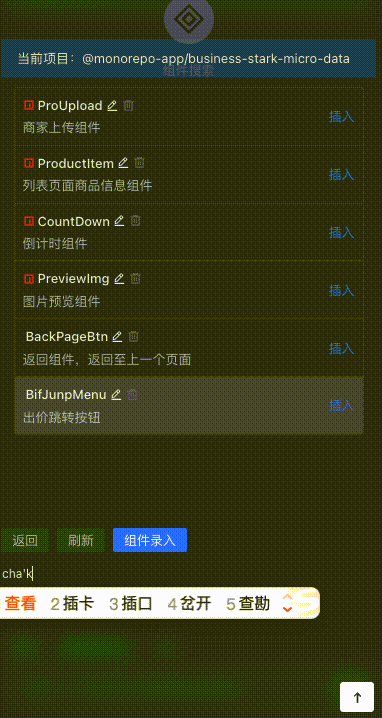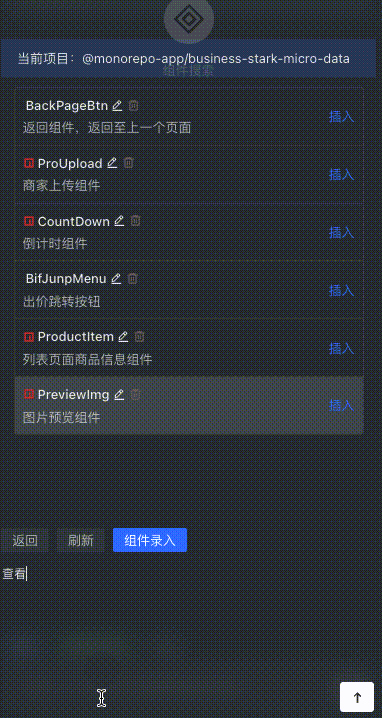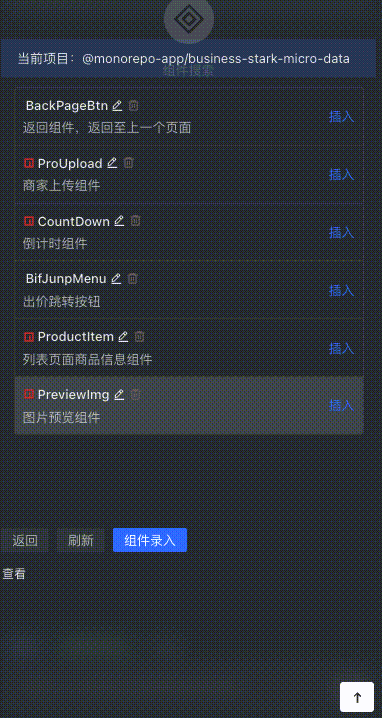
コンポーネントの素早い挿入
ユーザーは、銘柄コード内で一致度が最も高い部品を記述して素早く検索し、Enter キーを押して挿入できます。
7. 今後の見通し
-
コンポーネント埋め込みテンプレート:現在、コンポーネントはすでにベクトル検索をサポートしています。ベクトル検索は、ソース コード ページを結合することによって生成され、コンポーネントの動的なマッチングとテンプレートへの埋め込みをサポートします。
-
既存のコードの編集と生成:現在、新しいページのソース コード生成のみがサポートされていますが、将来的には既存のページへのローカル コードの追加もサポートされる予定です。
-
コード テンプレート パイプライン: AST のコード操作ツールは、自然言語とコード記述をさらに結び付け、シーン拡張の効率を向上させます。
※本文/神の御心
この記事は Dewu Technology によるものです。さらに興味深い記事については、 Dewu Technology 公式 Web サイトをご覧ください。
Dewu Technology の許可なく転載することは固く禁じられています。さもなければ、法律に従って法的責任が追及されます。
私はオープンソース紅蒙を諦めることにしました 、オープンソース紅蒙の父である王成露氏:オープンソース紅蒙は 中国の基本ソフトウェア分野における唯一の建築革新産業ソフトウェアイベントです - OGG 1.0がリリースされ、ファーウェイがすべてのソースコードを提供します。 Google Readerが「コードクソ山」に殺される Fedora Linux 40が正式リリース 元Microsoft開発者:Windows 11のパフォーマンスは「ばかばかしいほど悪い」 馬化騰氏と周宏毅氏が「恨みを晴らす」ために握手 有名ゲーム会社が新たな規制を発行:従業員の結婚祝いは10万元を超えてはならない Ubuntu 24.04 LTSが正式リリース Pinduoduoが不正競争の罪で判決 賠償金500万元