1. なぜクルーバイナリツリーを使用するのですか?
まず、通常の二分木の欠点を見てみましょう。以下は通常のバイナリ ツリー (連鎖ストレージ方式) です。
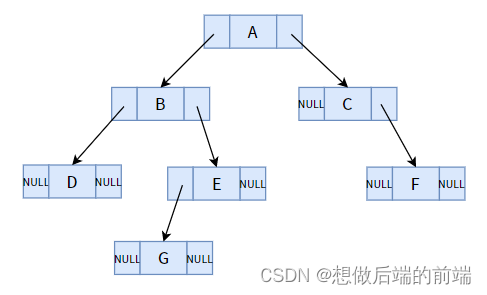
一見、矛盾しているように見えますか?構造全体には合計 7 つのノードと合計 14 のポインター フィールドがあり、そのうち 8 つのポインター フィールドは空です。 n 個のノードを持つバイナリ ツリーの場合、合計 n+1 個のヌル ポインタ フィールドが存在します。このルールはすべてのバイナリ ツリーに適用されます。
非常に多くの NULL ポインター フィールドが無駄だと思いませんか?データ構造とアルゴリズムの学習の焦点は、時間効率とスペース利用率を向上させる方法を見つけることです。非常に多くのポインター フィールドが無駄になっています。なんとももったいないことです。
したがって、それらを有効に活用する方法を見つけて、バイナリ ツリー データ構造をより効果的に使用するために使用する必要があります。
では、それをどう活用すればいいのでしょうか?
バイナリ ツリーのトラバースの本質は、バイナリ ツリー内の非線形構造のノードを線形シーケンスに変換して、簡単にトラバースできるようにすることです。
たとえば、上図の順序トラバーサル シーケンスは DBGEACF です。
線形シーケンス (線形テーブル) には、直接の先行処理と直接の後続処理の概念があります。たとえば、順序どおりのトラバーサル シーケンスでは、B の直接の先行者は D で、直接の後続者は G です。
B の直接の先行者と直接の後続者を知ることができる理由は、順走査アルゴリズムに従って二分木の順走査シーケンスを書き出し、このシーケンスを使用して先行者と後続者が誰であるかを知るためです。誰が。
バイナリ ツリー内の親ノードと子ノードの間には直接の関係しかないため、直接の先行ノードと直接の後続ノードはバイナリ ツリーから直接取得できません。つまり、バイナリ ツリーのノード ポインタ フィールドには、ノードのアドレスのみが格納されます。その子ノード。
現在の要件は、バイナリ ツリーからインオーダー トラバーサル モードでノードの直接の先行ノードと直接の後続ノードを直接取得できるようにしたいことです。
このとき、手がかりバイナリツリーを使用する必要があります。
2. 手がかり二分木とは何ですか?
もちろん、ノードのポインター フィールドを使用して、直前の先行ノードと直後の後継ノードのアドレスを保存する必要があります。
実際、上図の通常の二分木 (中間順序でトラバースすることで得られるシーケンス) では、一部のノード (ポインター フィールドが空ではないノード) は、ノードの左側の子 G など、直接の先行者または後続者を見つけることができます。 E これはノード E の直接の先行ノードであり、ノード A の右の子 C はノード A の直接の後続ノードです。
ただし、一部のノードでは機能しません (ポインタ フィールドが空です)。たとえば、ノード G の直接の後継者は E で、直接の先行者は B です。しかし、そのような結論は二分木では導き出すことができません。どうやってするの?ノード G の 2 つのポインタ フィールドが両方とも NULL で使用されていないことに気付きました。そこで、これら 2 つのポインタを使用して、それぞれ前任者と後続者を指すようにするとよいのではないでしょうか?
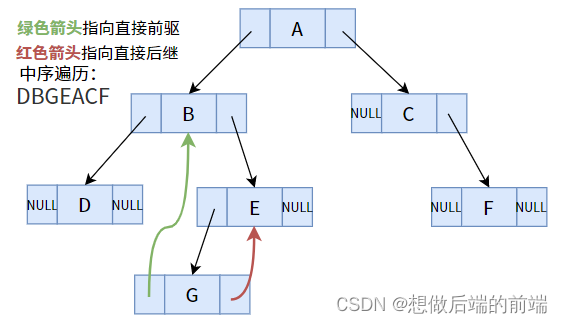
まさに両者の長所を生かした、まさに天国のような試合です。しかし、問題は解決されていません!
先行ノードまたは後続ノードを指すためにヌル ポインタ フィールドを使用するため、これは、ノード E やノード B など、ポインタ フィールドが空ではないノードにとって矛盾します。
対立があるのですから、その根本原因を突き止めて解決しなければなりません。
矛盾の原因は、ノードのポインタ フィールドが空である場合と空ではない場合、ポインタの指す位置が一致しないことです。つまり、空でない場合に子を指すポインターと、ポインターが空である場合の先行または後続との間に矛盾があります。
次に、適切な薬を服用し、空のポインタフィールドと空でないポインタフィールドを区別し、空でない場合は子を指し、空の場合は先行または後続を指すことをポインタに明確に伝えます。これには、2 つのポインタのそれぞれにフラグ ビットを追加する必要があります。
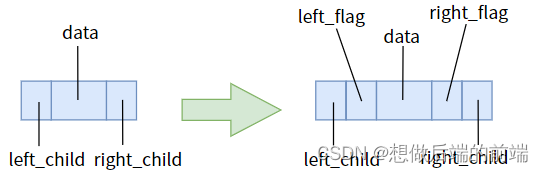
そして次の規則に同意します:
left_flag == 0 の場合、ポインタ left_child は左の子を指します
。 left_flag == 1 の場合、ポインタ left_child は直前の子を指します。
right_flag == 0 の場合、ポインタ right_child は右を指します。
right_flag == 1 の場合、ポインタ right_child は直前のポインタを指します。
バイナリ ツリーのノードを変更する必要があります。
/*线索二叉树的结点的结构体*/
typedef struct Node {
char data; //数据域
struct Node *left_child; //左指针域
int left_flag; //左指针标志位
struct Node *right_child; //右指针域
int right_flag; //右指针标志位
} TTreeNode;
フラグビットを使用すると、すべてを整理できます。直前の先行者および後続者へのポインターを手がかりと呼びます。フラグが 0 のポインタは子へのポインタ、フラグが 1 のポインタは手がかりです。
バイナリリンクリストツリーは上記のようなノード構造を持ち、すべてのヌルポインタを手がかりに変えたものをバイナリクルーツリーといいます。
3. 手がかり二分木を作成するにはどうすればよいですか?
通常の二分木では、特定の走査順序でノードの直接の先行者または後続者を取得したい場合、走査順序を知る前に、毎回走査して取得する必要があります。手がかり二分木では、それを一度トラバースするだけで済みます (手がかり二分木を作成するときのトラバース)。それ以降、手がかり二分木は各ノードの直接の先行者と後続者を「記憶」することができ、取得する必要はありません。将来の走査順序を通じてそれを先駆者または後続者。
通常の二分木を特定の走査方法に従って手がかり付き二分木に変換するプロセスを二分木のスレッド化と呼びます。
次に、順序トラバーサルを使用して、次のバイナリ ツリー 手がかりを手がかりバイナリ ツリーに変換します。
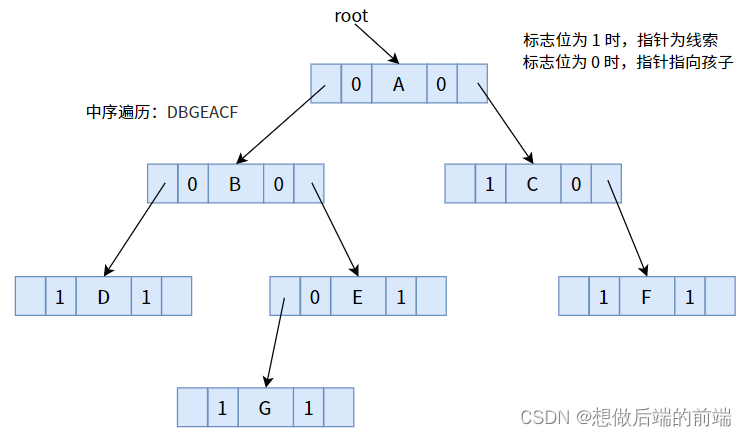
フラグ ビット 1 を持つポインタを使用してシーケンスを順序どおりにトラバースし、先行者または後続者を指すようにします
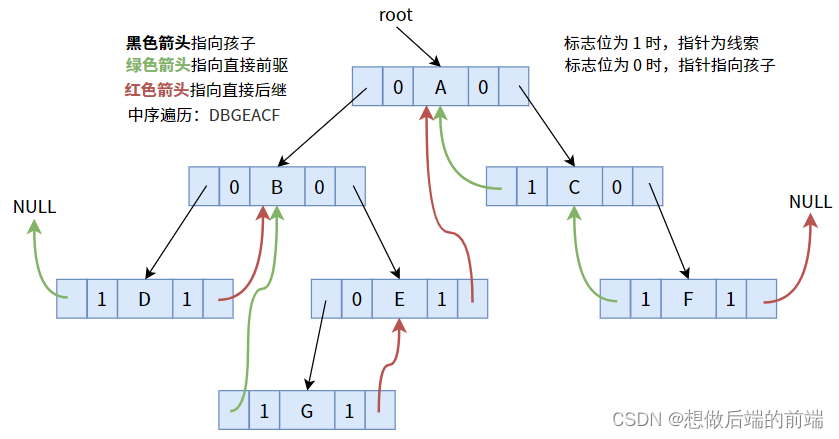
。 、ノード D には直接の先行者がなく、ノード F には直接の後続者がないため、ポインタは NULL です。
この時点で、n 個のノードを持つバイナリ ツリー内の n+1 個のヌル ポインタ フィールドによって引き起こされる無駄は解決されました。解決策は、ヌル ポインタ フィールドを利用するために各ノードのポインタにフラグ ビットを追加することです。フラグ ビットには 0 または 1 のブール値が格納されます。これは、無駄な NULL ポインタ フィールドに比べて比較的コスト効率が高くなります。さらに、バイナリ ツリーには新しい機能があり、特定の走査順序でのノード間の先行者と後続の関係をバイナリ ツリーに保存できます。
4. 手がかりの実現
手がかり二分木は通常の二分木から取得され、特定の走査順序で取得されることに注意してください。なぜなら、手がかりはノードの先行者と後続者を知った後でしか設定できず、先行者と後続者の関係は二分木を通して直接反映することができず、二分木を走査して得られる線形シーケンスを通じてのみ関係を取得できるからです。したがって、何らかのトラバーサルメソッドを通じて先行者と後続者の関係を持つシーケンスを取得した後、ノードのヌルポインタを変更して、手がかりを設定することができます。
つまり、スレッド化の本質は、特定の走査順序でバイナリ ツリーを走査するプロセス中に、ノードのヌル ポインタがその走査順序での直前の先行ノードまたは直接の後続ノードを指すように変更するプロセスです。
したがって、コードの一般的な構造は同じです。トラバーサル コード内の印刷コードをスレッド コードに置き換え、その他の変更を加えるだけです。
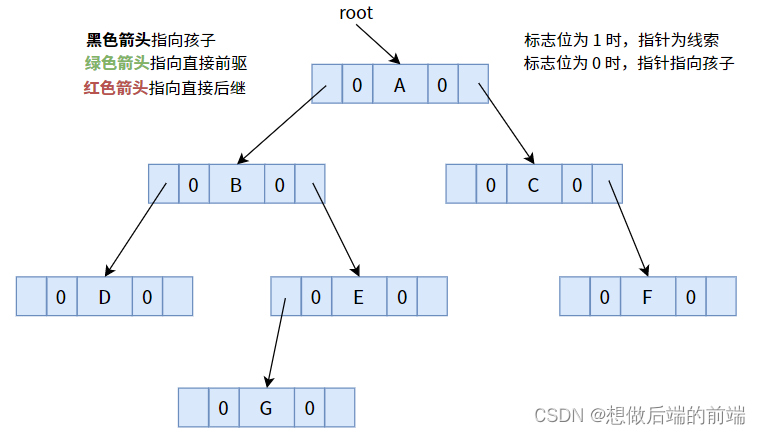
次の図は、3 種類の手がかりを導入する例です。
スレッド化されていないバイナリ ツリーでは、すべてのフラグがデフォルトで 0 に設定されます。
4.1. シーケンス間のスレッド化
インオーダー走査順序に従って手がかりを与えると、次の図が得られます。
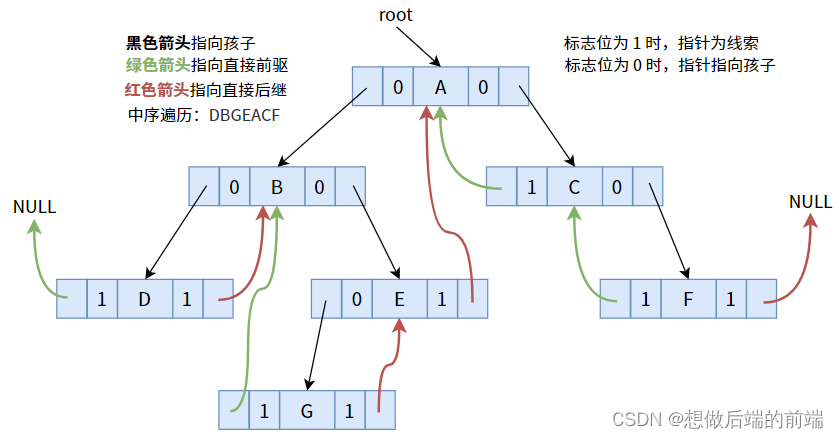
まず、次の内容をもう一度明確にしましょう。
- バイナリツリーをトラバースしながらスレッド化を実行します。
- インオーダートラバーサルの順序は、左のサブツリー >> ルート >> 右のサブツリーです。
- スレッド化により、ヌル ポインター フィールドとそれに対応するフラグ ビットという 2 つのものが変更されます。
- 変更するにはどうすればよいですか? NULL ポインタ フィールドを直前の先行者または後続者に設定します。
したがって、私たちの質問は次のようになります。
- すべての null ポインター フィールドを検索します。
- NULL ポインター フィールドが属するノード、直接の先行ノードと直接の後続ノードを事前順序で検索します。
- ポインターが手がかりと呼ばれるように、ヌル ポインター フィールドとそのフラグの内容を変更します。
注: バイナリ ツリーをトラバースするときに再帰を使用したため、スレッド化するときにも再帰を使用します。
具体的なコードは次のとおりです。
//全局变量 prev 指针,指向刚访问过的结点
TTreeNode *prev = NULL;
/**
* 中序线索化
*/
void inorder_threading(TTreeNode *root)
{
if (root == NULL) {
//若二叉树为空,做空操作
return;
}
inorder_threading(root->left_child);
if (root->left_child == NULL) {
root->left_flag = 1;
root->left_child = prev;
}
if (prev != NULL && prev->right_child == NULL) {
prev->right_flag = 1;
prev->right_child = root;
}
prev = root;
inorder_threading(root->right_child);
}
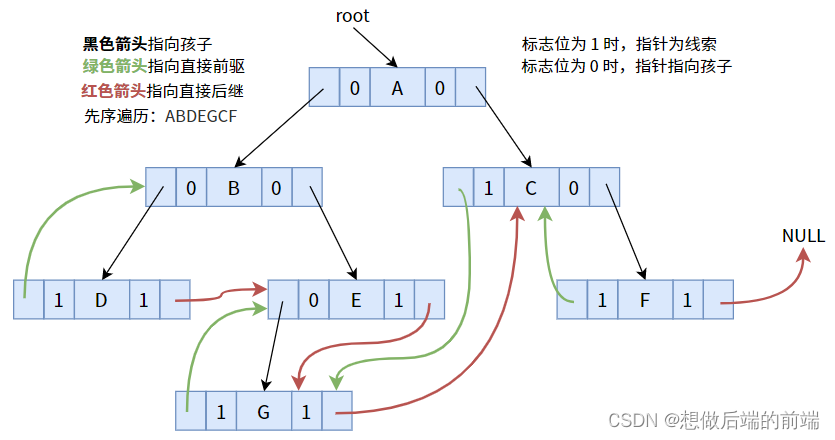
4.2. 予約注文のスレッド化
事前注文シーケンスに従って手がかりを与えると、次の図が得られます。
具体的なコードは次のとおりです。
// 全局变量 prev 指针,指向刚访问过的结点
TTreeNode *prev = NULL;
/**
* 先序线索化
*/
void preorder_threading(TTreeNode *root)
{
if (root == NULL) {
return;
}
if (root->left_child == NULL) {
root->left_flag = 1;
root->left_child = prev;
}
if (prev != NULL && prev->right_child == NULL) {
prev->right_flag = 1;
prev->right_child = root;
}
prev = root;
if (root->left_flag == 0) {
preorder_threading(root->left_child);
}
if (root->right_flag == 0) {
preorder_threading(root->right_child);
}
}
4.3. ポストオーダースレッディング
事後走査順序に従って手がかりを与えると、次の図が得られます。
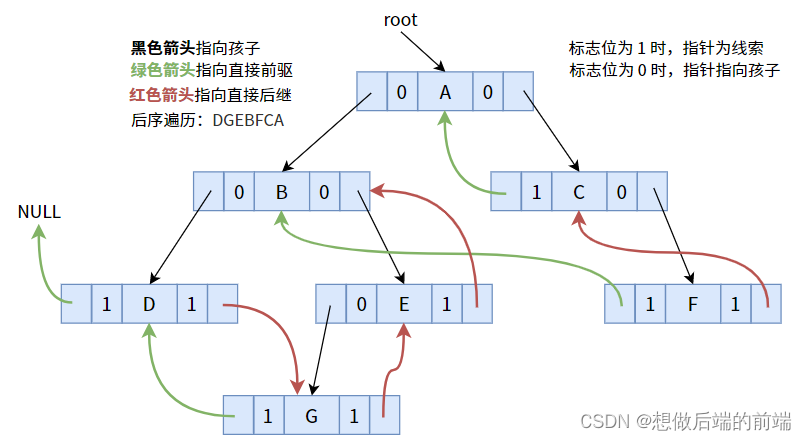
具体的なコードは次のとおりです。
//全局变量 prev 指针,指向刚访问过的结点
TTreeNode *prev = NULL;
/**
* 后序线索化
*/
void postorder_threading(TTreeNode *root)
{
if (root == NULL) {
return;
}
postorder_threading(root->left_child);
postorder_threading(root->right_child);
if (root->left_child == NULL) {
root->left_flag = 1;
root->left_child = prev;
}
if (prev != NULL && prev->right_child == NULL) {
prev->right_flag = 1;
prev->right_child = root;
}
prev = root;
}
5. まとめ
スレッド化されたバイナリ ツリーは、バイナリ ツリー内の null ポインタ フィールドを最大限に活用し、バイナリ ツリーに新しい機能を与えます。つまり、1 回のトラバーサルを通過した後、そのノード間の先行者と後続者の関係をバイナリ ツリーに保存できます。
したがって、ノードの直接の先行ノードまたは後続ノードを見つけるためにバイナリ ツリーを頻繁にトラバースする必要がある場合は、手がかりバイナリ ツリーを使用することが非常に適切です。