大規模な言語モデルは、自然言語処理の最先端を進歩させます。ただし、これらは主に英語または限られた言語セット用に設計されているため、リソースの少ない言語では有効性に大きなギャップが生じます。このギャップを埋めるために、ミュンヘン大学、ヘルシンキ大学、その他の研究者が共同で、広範囲の 534 言語をカバーすることを目的とした MaLA-500 をオープンソース化しました。
MaLA-500 は LLaMA 2 7B に基づいて構築されており、言語拡張トレーニングに多言語データ セット Glot500-c を使用します。 SIB-200に関する研究者の実験結果は、MaLA-500が最先端のコンテキスト学習結果を達成したことを示しています。
Glot500-c には、47 の異なる民族言語をカバーする 534 の言語が含まれており、データ量は最大 2 兆トークンに達します。研究者らは、Glot500-c データセットを選択した理由は、既存の言語モデルの言語範囲を大幅に拡張でき、非常に豊富な言語ファミリーが含まれており、モデルが固有の文法と意味論を学習するのに非常に役立つためであると述べました。言語のルール。
また、一部の高リソース言語の割合は比較的低いですが、Glot500-c の全体的なデータ量は大規模な言語モデルをトレーニングするのに十分です。後続の前処理では、コーパス データセットに対して加重ランダム サンプリングが実行され、トレーニング データ内の低リソース言語の割合が増加し、モデルが特定の言語にさらに重点を置くことができるようになりました。
LLaMA 2-7B に基づいて、MaLA-500 は 2 つの主要な技術革新を行いました。
- 語彙を強化するために、研究者らは、Glot500-c データセットを通じて多言語単語セグメンターをトレーニングし、LLaMA 2 の元の英語語彙を 260 万に拡張し、非英語およびリソースの少ない言語に適応するモデルの能力を大幅に強化しました。

- モデル拡張では、LoRA テクノロジーを使用して、LLaMA 2 に基づいて低ランク適応を実行します。適応行列をトレーニングし、基本的なモデルの重みを凍結するだけで、モデルの元の知識を保持しながら、新しい言語でのモデルの継続的な学習能力を効果的に実現できます。
トレーニングプロセス
トレーニングに関しては、研究者らは 24 個の N カード A100 GPU をトレーニングに使用し、Transformers、PEFT、DeepSpeed を含む 3 つの主流の深層学習フレームワークを使用しました。
その中で、DeepSpeed は分散トレーニングのサポートを提供し、モデルの並列処理を実現できます。PEFT は効率的なモデルの微調整を実装し、Transformers はテキスト生成、迅速な単語理解などのモデル機能の実装を提供します。
トレーニングの効率を向上させるために、MaLA-500 は、GPU コンピューティング リソースの使用を最大化できる ZeRO 冗長オプティマイザーや、混合精度トレーニング用の bfloat16 数値形式など、さまざまなメモリおよびコンピューティング最適化アルゴリズムも使用して、トレーニングのプロセス。
さらに、研究者らは、学習率 2e-4 の従来の SGD トレーニングを使用し、L2 重み減衰 0.01 を使用して、モデルが大きすぎる、過学習、不安定になることを防ぐために、モデル パラメーターに対して多数の最適化も実施しました。コンテンツ出力などの条件。
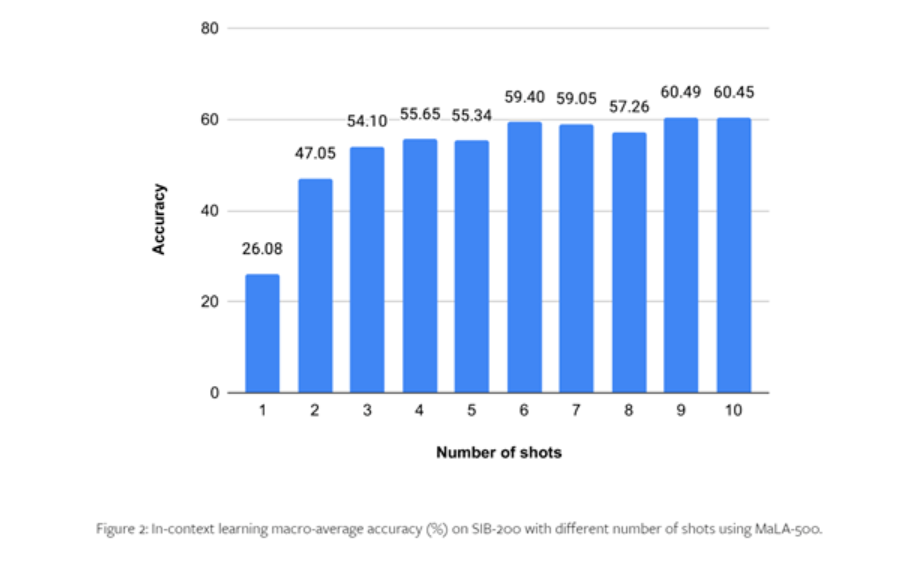
MaLA-500 の性能をテストするために、研究者らは SIB-200 などのデータセットに対して包括的な実験を実施しました。
結果は、元の LLaMA 2 モデルと比較して、トピック分類などの評価タスクにおける MaLA-500 の精度が 12.16% 向上したことを示し、これは MaLA-500 の多言語が多くの既存のオープンソース大規模言語モデルよりも優れていることを示しています。 。
詳細については、論文全文をご覧ください。