1月17日、上海でScholar Puyuan 2.0(InternLM2)の記者会見とScholar Puyuan Large Model Challengeの開始式が開催された。上海人工知能研究所とSenseTimeは、香港中文大学および復旦大学と協力して、新世代の大規模言語モデル研究者Puyu 2.0 (InternLM2)を正式にリリースしました。

オープンソースアドレス
レポートによると、InternLM2 は 2 兆 6,000 億トークンの高品質コーパスでトレーニングされました。初代学者 Puyu (InternLM) の設定を踏襲し、InternLM2 には 7B と 20B の 2 つのパラメータ仕様と、さまざまな複雑なアプリケーション シナリオのニーズを満たすベース バージョンとダイアログ バージョンが含まれています。上海 AI 研究所は、「高品質のオープンソースでイノベーションを促進する」というコンセプトを堅持し、InternLM2 の商用ライセンスを無償で提供し続けています。
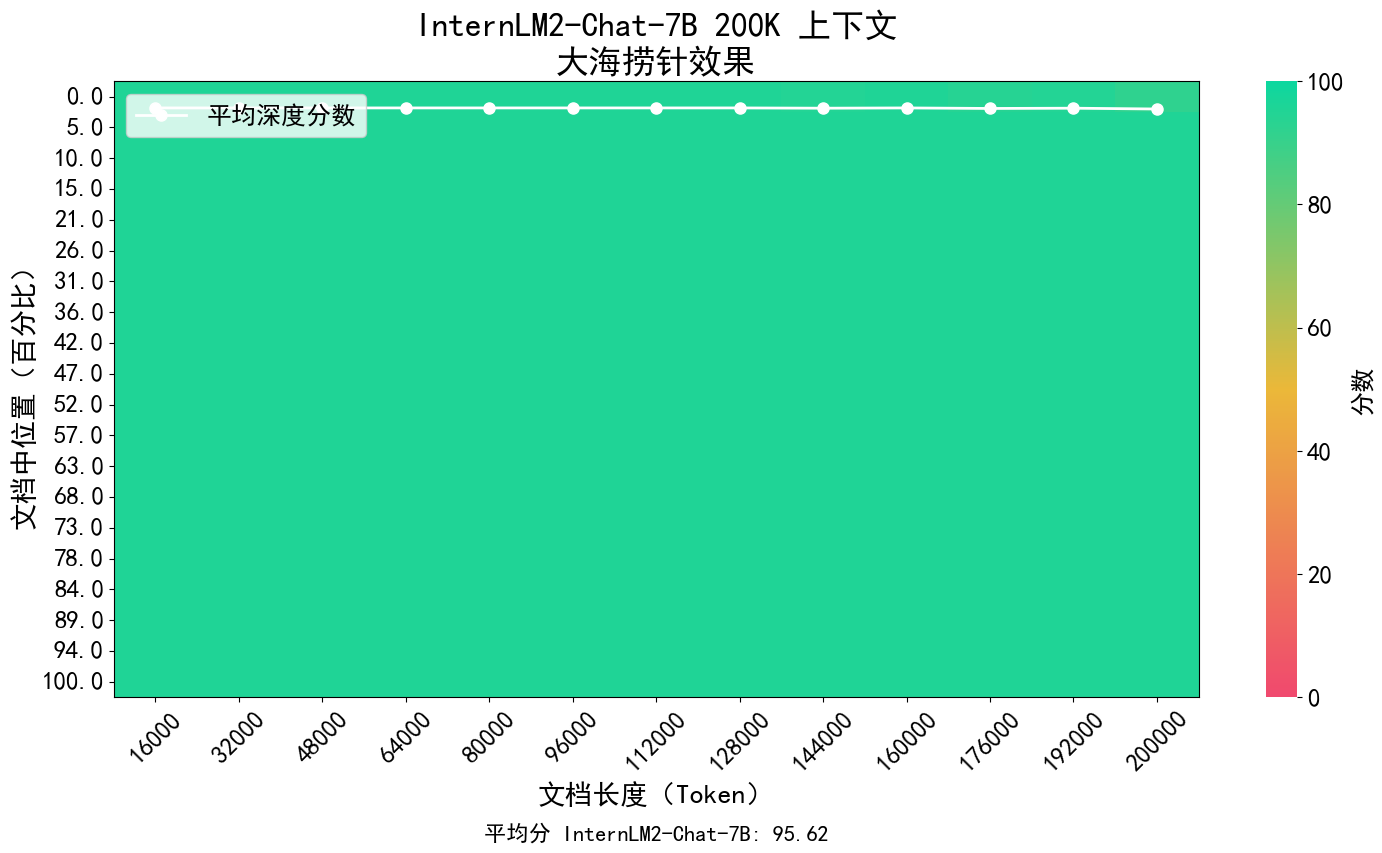
InternLM2 の核となるコンセプトは、言語モデリングの本質に立ち返ることであり、コーパスの品質と情報密度を向上させ、数学を大幅に進歩させることにより、モデル ベースの言語モデリング機能の質的向上を達成することに取り組んでいます。コーディング、対話、作成などの面で進歩が見られ、総合的なパフォーマンスは同規模のオープンソース モデルのトップレベルに達しました。20万トークンのコンテキストをサポートし、約30万の漢字の入力コンテンツを一度に受信して処理し、重要な情報を正確に抽出して、長いテキストの「干し草の山から針を見つける」ことを実現します。
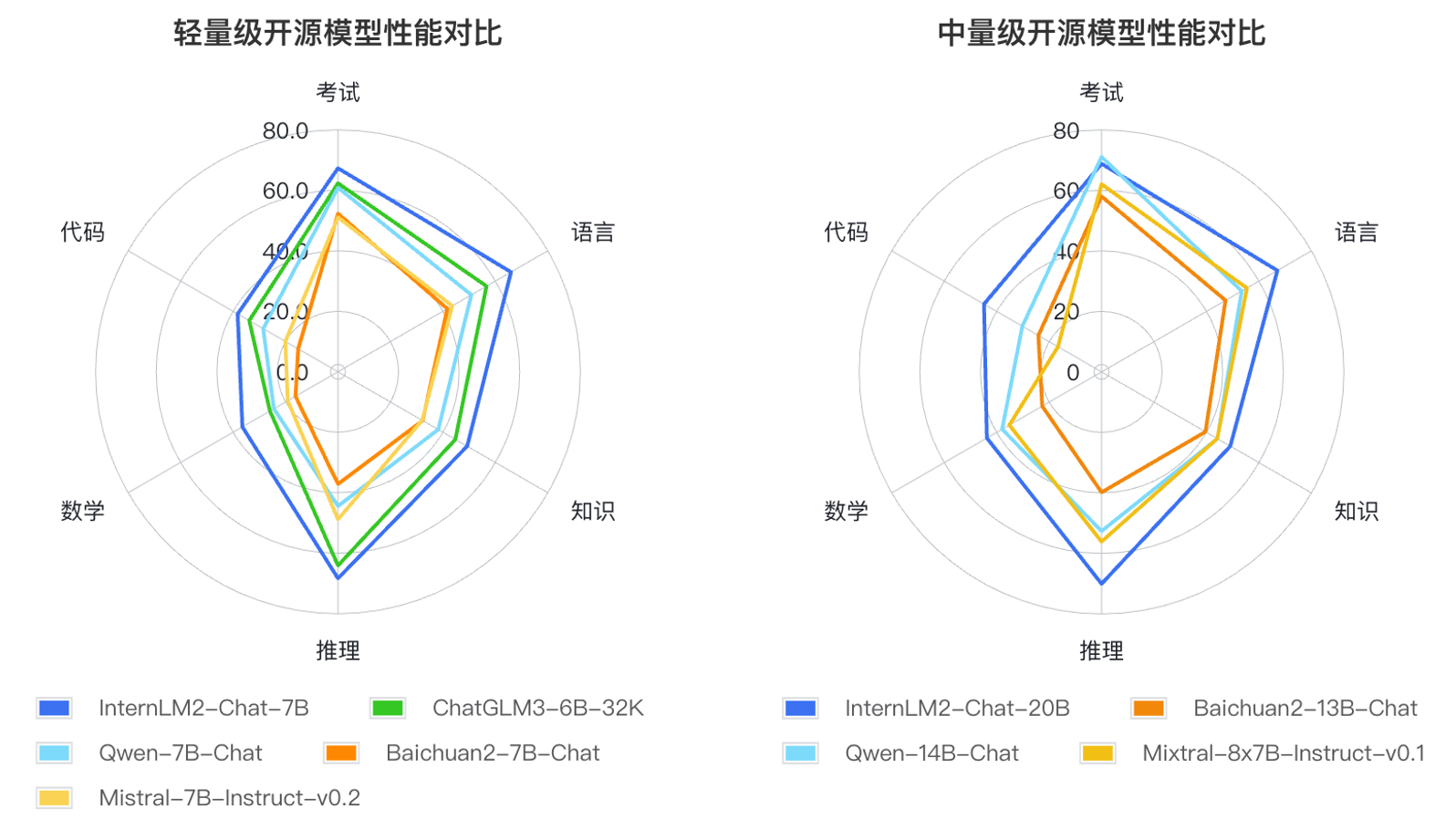
また、InternLM2 はさまざまな機能において総合的な進歩を遂げており、第 1 世代の InternLM と比較して、推論、数学、コーディングなどの機能が大幅に向上し、その総合的な機能は同レベルのオープンソース モデルを上回っています。
研究者らは、大規模な言語モデルの適用方法とユーザーが懸念する主な領域に基づいて、言語、知識、推論、数学、コード、試験などの 6 つのコンピテンシーの側面を定義し、同じ規模の複数のモデルのパフォーマンスをテストしました。主流評価セット55セットで総合的に性能を評価しました。評価の結果、同サイズのモデルでは、軽量版(7B)と中量版(20B)の InternLM2 が良好な性能を発揮することがわかりました。