
作者:ナミ
Cloud Message Queue Kafka バージョンでコードレス ダンプを実行する必要があるのはなぜですか?
Cloud Message Queue Kafka バージョン自体は、高スループット、低遅延、スケーラビリティの特徴を備えた分散ストリーム処理プラットフォームです。リアルタイム データ処理やストリーミング データ送信のシナリオで広く使用されています。ただし、Cloud Message Queue Kafka バージョンを他のデータ ソースやデータ宛先と統合するには、データの送信と同期を実現するために追加の開発/コンポーネントが必要となり、顧客は研究開発、運用、保守などに多額の投資を必要とします。
研究開発効率を向上させるために、Cloud Message Queue Kafka バージョンは Alibaba Cloud 製品と連携してコードフリー、フルマネージド、サーバーレス機能をサポートし、Cloud Message Queue Kafka バージョンから OSS へのダンピングをサポートします。この機能の利点は次のとおりです。
- 単純
<!---->
-
- アジャイル開発、シンプルな構成でこの機能をサポートできます
- さまざまなアプリケーションの OSS データを簡単にダンプする
- 複雑なソフトウェアやインフラストラクチャは必要ありません
<!---->
- フルマネージド
<!---->
-
- サーバーレス コンピューティング機能を提供する
- 運用もメンテナンスも無料
- 成熟した機能
<!---->
- 低コスト
<!---->
-
- Cloud Message Queue の Kafka バージョン自体には追加料金はなく、基礎となる依存関係関数の計算は量に基づいて課金されます。
- Function Compute はこのシナリオ向けに徹底的に最適化されており、CDN キャッシュ メカニズム、動的計算、および派生コピー ストレージのコストの導入など、低コストを実現するアーキテクチャと組み合わされています。
- 製品統合リンクに対する特定の料金割引
クラウド メッセージ キュー Kafka バージョン + OSS メイン アプリケーション シナリオ
-
データのバックアップとアーカイブ
OSS はデータのバックアップおよびアーカイブ機能を提供します。お客様は、重要なデータを OSS にバックアップして、データの災害復旧機能を提供することを選択できます。OSS はデータの耐久性と信頼性を保証し、データのセキュリティと可用性を保証します。同時に、OSS は、アクセス頻度の低いデータを長期保存するためのアーカイブ ストレージ機能も提供します。お客様は、OSS のアーカイブ ストレージ カテゴリにデータをアーカイブして、ストレージ コストを節約し、必要に応じてデータ回復を実行できます。
-
ビッグデータ分析
Alibaba Cloud のオブジェクト ストレージ OSS は、ビッグデータのストレージ プラットフォームとして使用できます。お客様は、データ分析、データマイニング、機械学習などの後続のタスクのために、さまざまなタイプのビッグデータ ファイル (ログ ファイル、センサー データ、ユーザー行動データなど) を OSS に保存できます。お客様は、ビッグデータの保存、処理、分析タスクを Alibaba Cloud 上で完了することができ、柔軟な拡張と高パフォーマンスのビッグデータ処理を実現できます。
-
FC計算結果のキャッシュ
Alibaba Cloud Function Compute (FC) は、ユーザーが低コストかつ高い弾力性でコードを実行できるようにするイベント駆動型のサーバーレス コンピューティング サービスです。Alibaba Cloud Object Storage OSS は、安全で安定した拡張性の高いクラウド ストレージ機能を提供するクラウド データ ストレージ サービスです。FC はステートレス コンピューティング サービスであり、永続的なローカル ストレージを提供しません。そのため、関数の実行中にデータを保存してアクセスする必要がある場合は、OSS と組み合わせることで、データを OSS に保存できます。これにより、データの永続的な保存が実現され、関数計算の一時的な性質によってデータが失われることがなくなります。
コードダンプ製品の機能の概要

1.0 コード開発:ダンプ/コネクタは、さまざまなデータ ソースおよびデータ送信先との統合機能を提供します。Cloud Message Queue Kafka のバージョン ダンプ/コネクタ機能を使用すると、開発者は複雑なデータ統合コードを記述する必要がなく、対応するコネクタを構成するだけでデータの送信と同期を実現できるため、データ統合プロセスが大幅に簡素化されます。
2. 構成サポート:ユーザーは、自分のニーズやビジネス シナリオに応じて、転送ルールやストレージ戦略を柔軟に構成できます。時間、キーワード、トピックなどのディメンションに基づいて転送する場合でも、フォルダー、ファイル名などのディメンションに基づいてストレージをサポートする場合でも、シンプルな構成で実装して個別のニーズを満たすことができます。
3. 高い信頼性と耐障害性:ダンプ/コネクタにより、データの高い信頼性と耐障害性が保証されます。データ送信中、コネクタはデータの冗長性と障害回復を自動的に処理し、データが失われたり損傷したりしないようにします。これにより、ユーザーはデータ送信や例外処理の詳細に注意を払う必要がなくなり、ビジネスロジックの開発に集中できるようになります。
4. サーバーレス:要求された負荷に応じて、コンピューティング リソースを自動的に拡張および削減できます。従来の事前割り当てサーバーと比較して、サーバーレスは実際のニーズにより柔軟に適応し、リソースの無駄とコストを削減できます。このコンポーネントは基盤となるインフラストラクチャの管理と保守を担当し、顧客はサーバーの構成と管理について気にする必要はありません。
使用説明書
前提条件
1. Cloud Message Queue Kafka 版インスタンスの準備[ 1]
- 依存関係はオープンです。作成の前提条件を参照してください[ 2]
ステップ 1: ターゲット サービス リソースを作成する
オブジェクトストレージ OSS コンソールにストレージスペース (バケット) を作成します。詳細な手順については、「コンソールでの記憶域スペースの作成[ 3]」を参照してください。
この記事では、oss-sink-connector-bucket バケットを例として取り上げます。
ステップ 2: OSS シンク コネクタを作成して開始する
Cloud Message Queue Kafka バージョンのコンソール[ 4]にログインし、概要ページのリソース配布領域でリージョンを選択します。
左側のナビゲーション バーで、[コネクタ エコシステムの統合] > [メッセージ アウトフロー (シンク)] を選択します。
メッセージ アウトフロー (シンク) ページで、[タスクの作成] をクリックします。
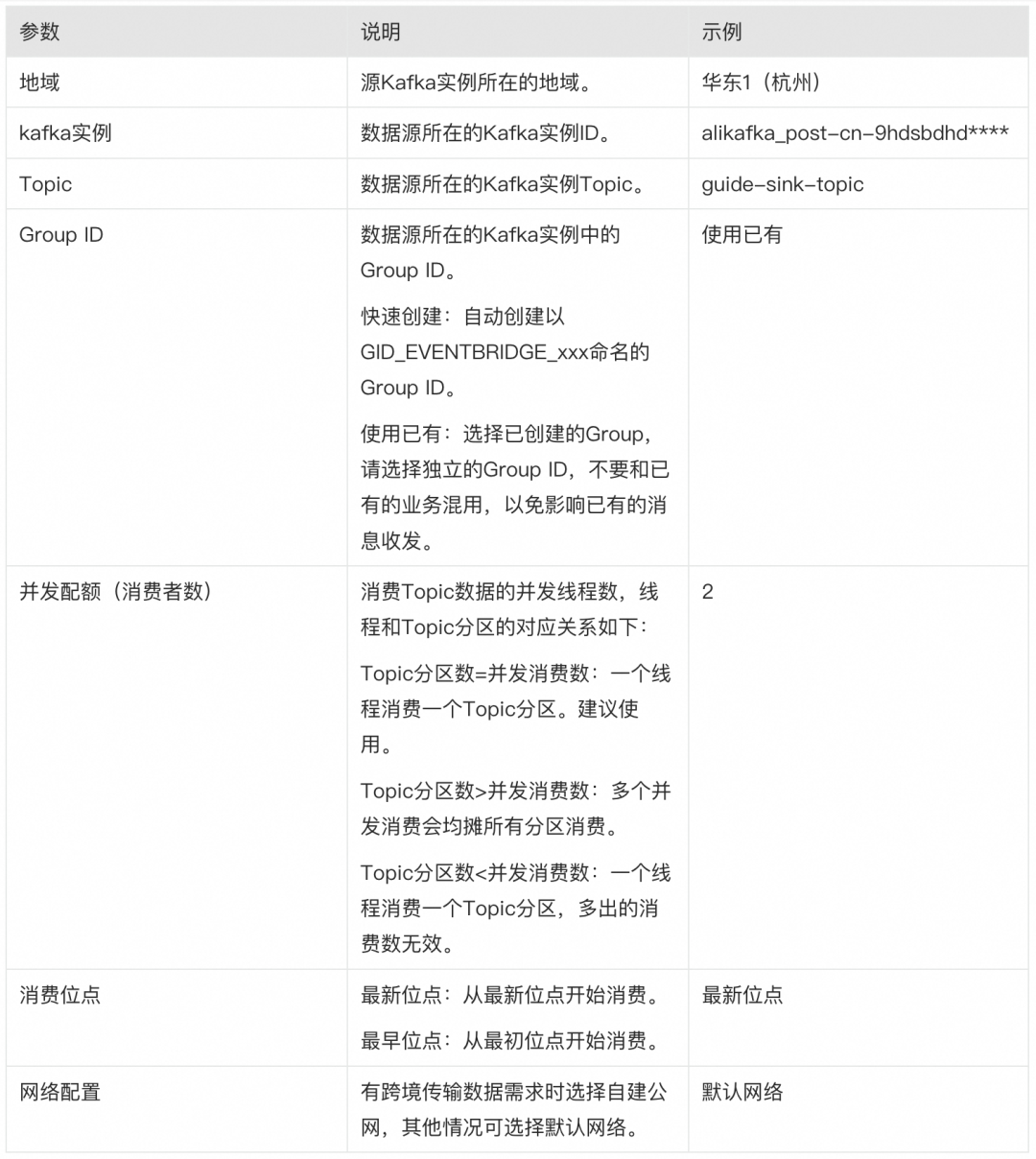
メッセージ アウトフロー作成パネルで、次のパラメータを設定し、[OK] をクリックします。
基本情報領域でタスク名を設定し、流出タイプとして OSS を選択します。
リソース設定領域で、次のパラメータを設定します。

上記の構成を完了したら、メッセージ アウトフロー (シンク) ページで、新しく作成した OSS シンク コネクタ タスクを見つけて、右側の操作列の [開始] をクリックします。ステータス バーが開始から実行に変わると、コネクタは正常に作成されています。
ステップ 3: OSS シンク コネクタをテストする
メッセージ アウトフロー (シンク) ページで、OSS シンク コネクタ タスクのイベント ソース列のソース トピックをクリックします。
[トピックの詳細] ページで、[エクスペリエンス] をクリックしてメッセージを送信します。
クイック エクスペリエンス メッセージング パネルで、以下に示すようにメッセージの内容を構成し、[OK] をクリックします。
メッセージ アウトフロー (シンク) ページで、OSS シンク コネクタ タスクのイベント ターゲット列のターゲット バケットをクリックします。
[バケット] ページで、左側のナビゲーション バーで [ファイル管理] > [ファイル リスト] を選択し、バケットの最も深いパスを入力します。
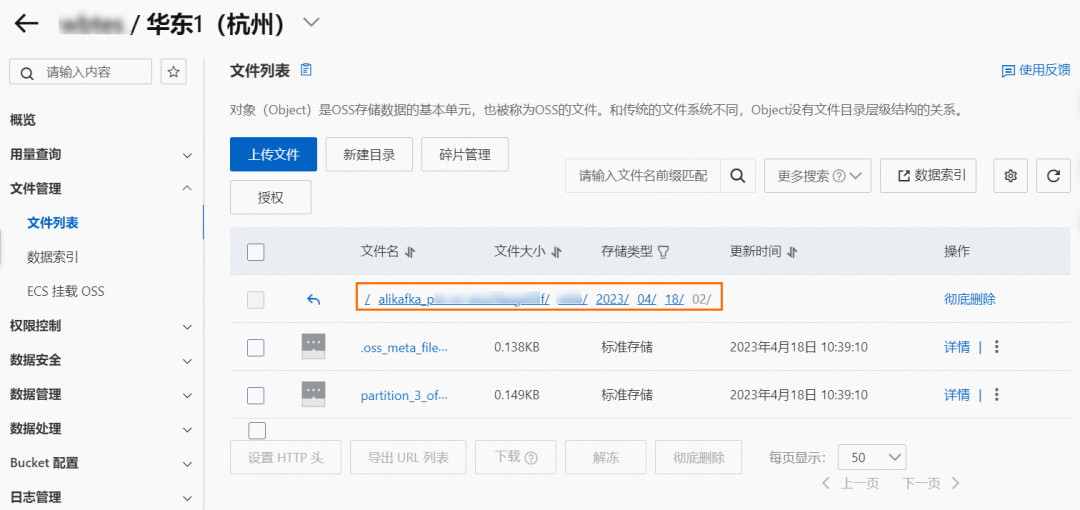
このパスには、次の 2 種類のオブジェクトがあることがわかります。
- システムメタファイル:形式は .oss_meta_file_partition_{partitionID} です。ファイル数は上流トピックのパーティション数と同じです。バッチ情報を記録するために使用されます。特に注意する必要はありません。
- データ ファイル:形式は、partition_{partitionID} offset {offset}_{8-bit Random string} です。パーティションの複数のメッセージがオブジェクトに集約されている場合、オブジェクト名のオフセットは、このバッチの最小オフセット値になります。メッセージ。
対応するオブジェクトの右側にある操作列で、 > [ダウンロード] を選択します。
> [ダウンロード] を選択します。
ダウンロードしたファイルを開いてメッセージの内容を確認します。

図に示すように、複数のメッセージは改行で区切られます。
関連リンク:
[1] Cloud Message Queue Kafka版インスタンスの準備
https://help.aliyun.com/zh/apsaramq-for-kafka/getting-started/getting-started-overview
[2]前提を作る
https://help.aliyun.com/zh/apsaramq-for-kafka/user-guide/prerequisites#concept-2323967
[3] コンソールがストレージスペースを作成する
https://help.aliyun.com/zh/oss/getting-started/console-quick-start#task-u3p-3n4-tdb
[4] Cloud Message Queue Kafka バージョンのコンソール
ここをクリックして、クラウド メッセージ キュー Kafka バージョン V3 パブリック ベータ版が正式に開始されました。
Bilibiliは2度クラッシュ、テンセントの「3.29」第1レベル事故…2023年のダウンタイム事故トップ10を振り返る Vue 3.4「スラムダンク」リリース MySQL 5.7、莫曲、李条条…2023年の「停止」を振り返る 続き” (オープンソース) プロジェクトと Web サイトが 30 年前の IDE を振り返る: TUI のみ、明るい背景色... Vim 9.1 がリリース、 Redis の父 Bram Moolenaar に捧げ、「ラピッド レビュー」LLM プログラミング: Omniscient 全能&&愚かな 「ポスト・オープンソースの時代が来た。ライセンスの有効期限が切れ、一般ユーザーにサービスを提供できなくなった。チャイナ ユニコムブロードバンドが突然アップロード速度を制限し、多くのユーザーが苦情を申し立てた。Windows 幹部は改善を約束した: Make the Start」メニューもまた素晴らしいです。 パスカルの父、ニクラス・ヴィルトが亡くなりました。