アンカー DETR(AAAI 2022)
改善する:
- 提案されたアンカーベースのオブジェクトクエリ
- 提案された注意バリアント - RCDA
以前の DETR では、ターゲット クエリは学習可能な埋め込みのセットでした。ただし、それぞれの学習可能な埋め込みには明確な意味がないため (ランダムに初期化されるため)、最終的にどこに集中するかについては説明がありません。さらに、各オブジェクトのクエリは特定の領域に焦点を当てていないため、トレーニング中の最適化も困難です。

DETR での視覚化に関する注意: (スロットは 100 個のクエリのうちの 1 つです)

ここでの3つの予測パターンは、同じであってもよいし、異なっていてもよい。
シンプルなモデル
DETRから特に大きな変更はありません
6encoder、6decoder、右下隅はアンカーポイントです
デコーダのqとkに位置埋め込みが追加されます
オブジェクト クエリ:[100,256] アンカー ポイントを追加し、それを位置埋め込みにエンコードし、元の oq を置き換えます。
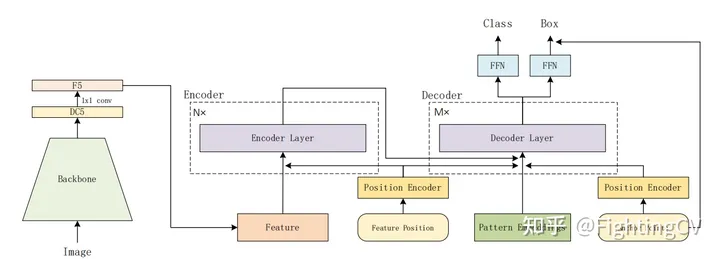
アンカーポイントを生成するには2つの方法があります
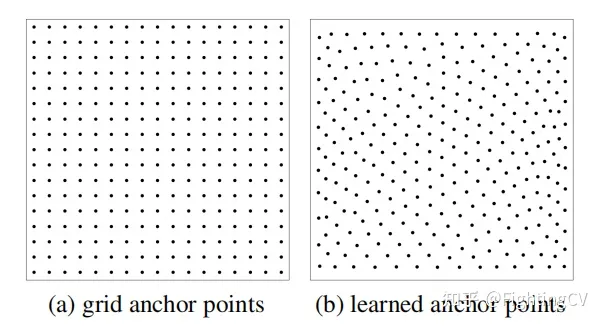
(a) アンカーは固定されており、幅と高さは均一に分布し、サンプリングは均一です。
(b) まず、テンソルの点を 0 ~ 1 の一様分布でランダムに初期化し、それを学習パラメータ (埋め込み) として使用すると、実験効果は良好です。

アンカーポイントをオブジェクトクエリに変換

まず、学習されたアンカー ポイント [100 (NA), 2] を取得します。
次に、sin/cos を介して [100, 256] 高周波位置コーディングに変換します(コード内の関数は pos2posemb2d)。
2 層の MLP 学習(コード内のadapt_pos2d)の後、Q_P: [Np (パターン), 256] に変換されます。
コードと記事の間には、次のようないくつかの違いがあります。

各アンカーポイントに対する複数の予測
100 個の参照ポイントがあり、各ポイントがターゲットを予測すると仮定すると、実際の画像には同じポイントの近くに複数のターゲットがある可能性があります。
アンカー detr は 1 点に対して複数のモード (3 種類) を予測するように設計されており、各点に Np 個のモードが設定されます (Np=3)
元の detr、オブジェクト クエリは [100,256]、それぞれは [1,256]
アンカー detr は、次のようにパターンの埋め込みを追加します;
Q fi = Embedding ( N p , C ) Q_{f}^{i}=\operatorname{Embedding}\left(N_{p}, C\right)Qf私は=埋め込み( Np、C )
つまり、各点には Np(3) 個のパターン [3, 256] があり、論文では Np=300、パターン=3、つまり 900 点になります。
最終的に、パターン埋め込みのQ_pとアンカー ポイントを追加するだけで、最終的なオブジェクト クエリが得られます。パターン位置クエリは次のように表現できます。
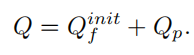
実際、上記の式はコード内では使用されていません。
前のコード図のコードでは、参照ポイントが 300 から 900 まで直接繰り返されています。
何か間違ったことを理解している場合は思い出してください。
コードパターンは最初のデコーダの入力であり、元の detr の tgt はすべて 0 です。

行と列の分離されたアテンション
削減されるのはメモリのオーバーヘッドです。!!!
行と列の分解アテンション メカニズムにより収束が加速され、q の長さは 900 で、メモリとメモリのオーバーヘッドが削減されます。

元のトランスフォーマー入力トークン (H*W) は 1 次元入力にフラット化されます。
軸 (W)、行次元で最初に計算されます
Ay (H)、Ay 演算を実行
Ay と Z は高さの次元で加重和を実行します
QK はすべて行と列の分解を実行しますが、V は分解しません [Nq, H*W]
オリジナルアテンション: Nq * H * W * M (頭)
RCDA:
斧:Nq * W * M
は: Nq * H * M
2つの行列の大きさを比較するだけです 図の右側が比例式です 2つの次元を比較した後、左はW * M/Cです Wは32(DC5)、M=8とします、C=256。同じです。C と W*M を見てください。
DC5 は、ホール コンボリューションがバックボーン ネットワーク (デフォルトの resnet50) の最終ステージに追加され、プーリング層が解像度を 2 倍に削減することを意味します。
実験
1. 異なるリニア アテンションのメモリと AP の比較
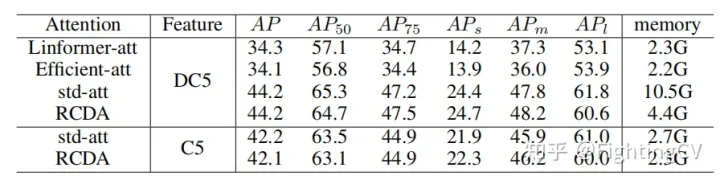
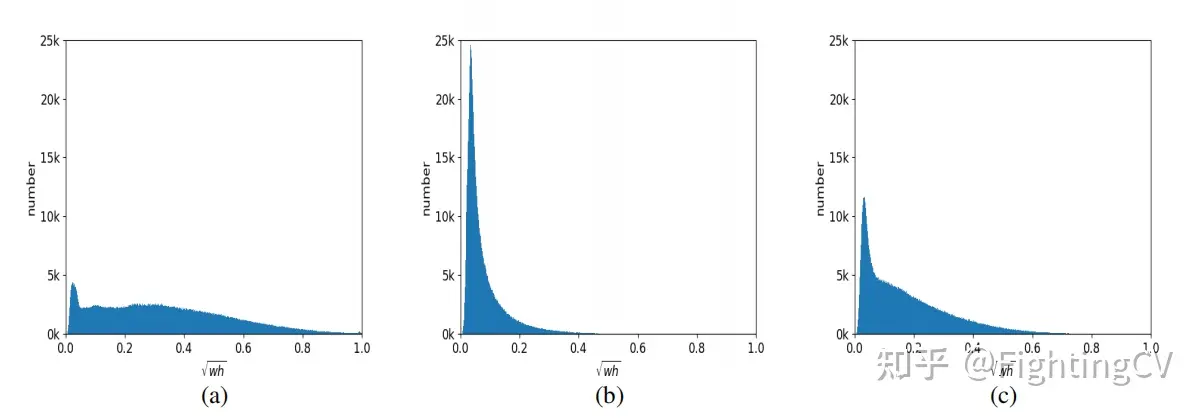
2. 通常、モード a は大きなオブジェクト用、モード b は小さなオブジェクト用、モード c はよりバランスが取れています。
参考
https://www.bilibili.com/video/BV148411M7ev/?spm_id_from=333.788&vd_source=4e2df178682eb78a7ad1cc398e6e154d