
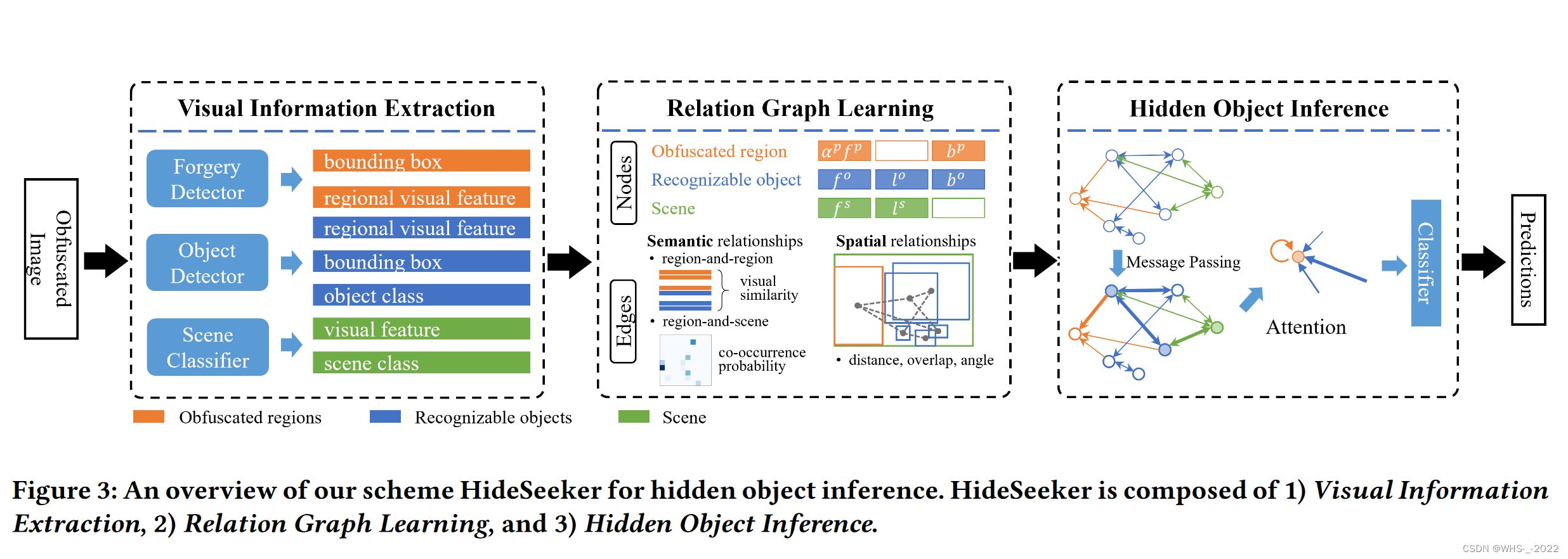
3.1 システム概要 HideSeeker
私たちは、これら 2 つの難読化技術 (ただしこれらに限定されない) によって隠された個人情報を発見するために、「HideSeeker」と呼ばれるソリューションを設計しました。ピクセル化、ぼかし、落書き、ステッカー オーバーレイ、修復などの難読化技術によって部分的に保護されている画像を考慮して、私たちの方法は難読化されたプライバシー領域を特定し、プライバシー領域内の隠れたオブジェクトのカテゴリを推測します。図 3 に示すように、HideSeeker は、視覚情報抽出、関係グラフ学習、および隠れオブジェクト推論の 3 つのモジュールで構成されています。
視覚情報の抽出: まず、隠れたオブジェクトのコンテキスト情報を抽出することを期待します。画像の視覚情報は、意味論的に 3 つのカテゴリ (ぼやけた領域、識別可能なオブジェクト、およびシーン) に分類できることが観察されています。すべての難読化技術は例外なく画像改ざんの痕跡を残すため、難読化された領域を特定するために画像改ざん検出および位置特定モデルのサポートを利用します。認識可能なオブジェクトとシーンを混乱領域のコンテキストとして定義します。物体検出モデルは、地域の特徴を抽出し、識別可能な物体を検出するために適用されます。さらに、画像全体の視覚的特徴をシーンの表現として使用します。
関係グラフの学習: 次に、グラフG = ⟨ V , E 〉 G = ⟨V, E〉を構築します。G=⟨V 、_E 〉、ノードはVVVモデリング混乱領域とそのコンテキスト、エッジ セットEEE は、それらの間の意味的および空間的関係をモデル化します。私たちが注目する 3 種類の視覚情報について、それぞれ混乱領域ノード、識別可能なオブジェクト ノード、およびシーン ノード セットを定義します。さらに、異なるノードのセット間の関係に基づいて異なるエッジを定義します。
隠しオブジェクトの推論: 最後に、構築された画像関係グラフに基づいて、オブジェクト クラスの混乱の確率を推論します。グラフ ニューラル ネットワークを適用して、近傍からコンテキスト情報を繰り返し集約することで、混乱を招く領域ノードの表現を学習します。ノード表現の集約と更新は、ゲート反復ユニット[ 22]によって行われます。さらに、注意メカニズムをグラフ ニューラル ネットワークに集約して、混乱領域、識別可能なオブジェクト、シーン間の潜在的な関係を学習します。
3.2 視覚情報の抽出
このモジュールでは、ぼやけた画像から観察可能なすべての視覚情報を取得します。必要な視覚情報に関しては、プライバシーを保護する画像を人間が観察することからインスピレーションを受けています。人々がソーシャル プラットフォーム上でぼかしが保護された画像を閲覧するとき、視覚的な不一致や他の領域との意味上の異常により、人々の目はぼやけた領域に集中する傾向があります。視聴者が何が保護されているかを知りたい場合、画像に表示されている難読化された領域のコンテキスト情報とそれらの間の関係を観察し、事前の知識を使用して隠されたオブジェクトのカテゴリを推測しようとします。図 2(b) の 2 番目の画像を例にとると、人間は一目見ただけでぼやけた領域、つまり赤いボックスでマークされた領域を簡単に見つけることができます。これに加えて、テーブル上のキーボードとディスプレイ デバイスも識別できます。この写真はおそらくオフィスで撮影されたものであると推測できます。ぼやけていますが、オフィスの机の上にあるぼやけたプライバシー関連の物体はラップトップである可能性があると推測できます。
この直感に基づいて、提案手法はまずぼやけた領域を検出し、その領域の視覚的特徴を抽出します。隠されたオブジェクトのコンテキスト情報は、混乱領域、識別可能なオブジェクト、およびシーンの 3 つのタイプに具体化されます。難読化技術は、プライバシー関連オブジェクトのピクセル値を変更または置き換えます。したがって、分類のために元の視覚的特徴を抽出するために従来の物体検出モデルに依存することは困難です。難読化された画像の分類タスクの場合、領域提案ベースの方法は、難読化されていない画像と比較してパフォーマンスが低下することがよくあります。ただし、難読化は元の画像を改ざんする手段として考えられます。最近の研究では、視覚的な不一致[20,40]、局所的な異常[ 41]、ノイズ パターン[ 55,58]などの手がかりに基づいて、画像改ざんの検出と位置特定が検討されています。私たちは、さまざまな難読化技術にわたって優れた一般化機能を備えた画像改ざん検出および位置特定モデルを適用することを期待しています。ManTra-Net [41] の助けを借りて、バイナリ マスクM ∈ RH × WM∈\mathbb{R}^{H×W} が得られます。M∈RH × W、ここでmij ∈ M m_{ij}∈Mメートルイジ∈Mは次のように定義されます。
mij = { 1 、位置 ( i , j ) のピクセルは難読化されていると予測されます。それ以外の場合は 0 。m_{ij}=\left\{\begin{array}{ll} 1, & \text { 位置 }(i, j) \text { のピクセルは難読化されていると予測されます。} \\ 0, & \text { それ以外の場合。} \end{配列}\right。メートルイジ={ 1 、0、 位置 ( i ,j ) は難読化されていると予測されます。 それ以外の場合 。
ぼやけた領域の位置を抽出するには、ピクセル間の距離を使用してmij m_{ij}を使用します。メートルイジクラスタリングを実行します。同じ難読化領域内のマスク ピクセルは、他の領域のマスク ピクセルよりも近くなる傾向があります。各ピクセル クラスターについて、クラスター化されたピクセルを混同領域の位置として含むことができる最小の境界ボックスを取得します。混同領域の位置はB p = { b 1 p , … , b N pp } B^{p}=\left\{b_{1}^{p}, \ldots, b_{N_{p としてマークされます。 }} ^{p}\右\}Bp={ b1p、…、bNpp}、上付き文字pppは「プライバシー関連」です。さらに、Faster RCNN [30] では、境界ボックスbip ∈ B p b_{i}^{p} \in B^{p}b私p∈Bp 、関心領域 (ROI) プーリング層の後の完全接続 (FC) 層からfip ∈ F p f_{i}^{p} \in F^{p} をf私p∈Fうp。
難読化された領域に隠されたプライバシー関連のオブジェクトに加えて、他の特定可能なオブジェクトが、ユーザーが画像を共有したり、ユーザーが領域を難読化したりする理由になる可能性があります。視覚的特徴が残っているため、物体検出モデルを使用してこれらの物体を簡単に検出および識別できます。識別可能な物体の検出と分類には、既製の物体検出モデルである Faster RCNN [30] を適用します。オブジェクトoi \mathbf{o}_{i}の場合ああ私は、視覚的特徴をf_{i}^{o}で抽出しますf私ああ、混乱領域の場合と同じように。物体検出器の分類と境界ボックス回帰の結果を、それぞれ識別可能な物体のクラスlio ∈ L o l_{i}^{o} \in L^{o} と呼びます。私私ああ∈Lo 和位置 b i o ∈ B o b_{i}^{o} \in B^{o} b私ああ∈Bああ。
[36] によれば、画像のシーンは多くの場合、何らかの個人情報と関連付けられています。例えば、「街中」で撮影された画像に含まれる個人情報は、「車」や「人物」に関するものである可能性が高いです。したがって、私たちはシーンをプライバシー関連オブジェクトの潜在的な指標であると考えます。シナリオ\mathbf{s}の場合sでは、画像の全体的な特徴を表現として学習しようとします。Places365データセット [53]ResNet-50の最後の畳み込み層から派生した視覚的特徴を介してシーンを記述します。Places365データセットには、365 のシーン カテゴリからの約 180 万枚の画像が含まれています。
3.3 リレーショングラフの学習
各画像に対して、抽出された視覚情報から学習した関係グラフGGを使用します。画像を説明するG。このモジュールは、混乱した領域とそのコンテキスト情報の間の意味的および空間的関係を表すグラフを構築することを目的としています。関係グラフをG = ⟨ V , E 〉 G = ⟨V, E〉G=⟨V 、_E⟩,其中 V V Vのノードは、EEEのエッジは、関係。関係グラフの学習についてはアルゴリズム 1 で説明します。混同領域、識別可能なオブジェクト、シーンの 3 種類のセマンティクスを抽出するため、それぞれに対応するノード セットを定義しますV = { V p , V o , V s } V=\left\{V^ {p}, V^ {o}、V^{s}\右\}V={ Vp、Vああ、Vs }:
認識可能なオブジェクト ノード V o V^{o}Vo : 混同領域と同時に出現するオブジェクトを検出し、分類します。物体検出器 Faster RCNN を通じて、識別可能な物体の予測カテゴリと位置を取得できます。各オブジェクトは、識別可能なノード v∈vo として定義されます。次に、カテゴリ ラベル、境界ボックス、および地域の視覚的特徴を、識別可能なオブジェクト ノードのノード表現として連結します: xo = [fo∥lo∥bo]。
難読化領域ノード V p V^{p}Vp : 各ノード V∈V p は画像内の混同領域を表します。境界ボックスで表される領域の位置とオブジェクト検出器から導出された領域の視覚的特徴を取得し、それらをノードにマージします。

シーン ノード V s V^{s}Vs:V s V^{s}Vs には、シーン記述を表すノード V が 1 つだけ含まれます。シーンノード v のノード表現は、視覚的特徴と視覚情報抽出モジュールの分類結果で構成されます。シーン ノード xs をスプライスとして表します。xs = [ fs ∥ ls ∥ 0 ] \mathbf{x}^{s}=\left[f^{s}\left\|l^{s}\right\| \ mathbf{0}\right]バツs=[ fs∥ l∥ _0 ]、ここで 0 は他のノードと同じ寸法を維持するためのパディングです。
ノードuuからuからノードvvvの各有向辺 eu→ v e_{u \rightarrow v}eう→う 表示 u u u 对 v v vの影響。このグラフでは、難読化された領域ノードと識別可能なオブジェクト ノードを総称して領域ノードと呼びます。領域間の意味的および空間的な関係を、領域ノード間のエッジとして計算します。ただし、シーンとリージョンの関係は、リージョン間の関係とは大きく異なります。結局のところ、机とオフィスの空間関係を計算することはできません。したがって、次の 3 種類のエッジを定義します。
シーン ノードとリージョン ノード間のエッジ: シーンとオブジェクトの間には経験的な相関関係があります。たとえば、ビーチではキッチンよりも浮き輪やパラソルを見かける可能性が高く、路上では電子レンジを見かける可能性は低くなります。したがって、実験室条件下で生成したぼやけた画像に基づいて、オブジェクトとシーンの双方向の共起頻度を計算します。図 4 に示すように、以下を渡します。
そしてP ( s , o ) P(\mathbf{s}, \mathbf{o})P ( s ,o )はオブジェクトo \mathbf{o}oとシーン\mathbf{s}s , P ( s ) P(\mathbf{s})の共起頻度P ( s )とP ( o ) P(\mathbf{o})P ( o )はそれぞれオブジェクトo \mathbf{o}oとシーン\mathbf{s}認識可能なオブジェクトノードuuのsの出現頻度uとシーン ノードvvv、それらの関係は共起確率によって測定されます。したがって、私たちはuuu 到 v v vのエッジの重みは
eu → v = P ( v ∣ u ) (3) e_{u \rightarrow v}=P(v \mid u)\tag{3}eう→う=P ( v∣う)( 3 )
領域ノード間のエッジ: ノードuuの場合u 和 v v v はすべてリージョナル ノードです。uu がわかります。u 和 v v v間の意味的および空間的な関係同じカテゴリの 2 つのオブジェクトは、異なるカテゴリのオブジェクトよりも密接に関連しています。視覚的な類似性 (視覚的類似性)、特に視覚的特徴fu f_uを計算することにより、2 つの領域間の意味的関係を測定します。fあなたそしてfv f_vfvデフォルト: vis uv = fufv ⊤ ∥ fu ∥ ⋅ ∥ fv ∥ \operatorname{vis}_{uv}=\frac{f_{u} f_{v}^{\top}}{\left\| f_{u }\右\| \cdot\left\|f_{v}\right\|}ヴィズ紫外線=∥ fあなた∥ ⋅ ∥ fv∥fあなたfv⊤。
ノードuuでの空間関係はu 和 v v vの間の領域uuu 和 v v vの距離、領域の重なり、角度により、 2つの領域の中心 ( [ xu , yu ] , [ xv , yv ] ) \left(\left[x_{u}, y_{u}\right] ,\left) を計算します。[x_{v}, y_{v}\right]\right)( [ xあなた、yあなた】、[ ×v、yv] )それらの間の距離として:dist uv = ∥ bu − bv ∥ 2 \operatorname{dist}_{uv}=\left\|b_{u} -距離紫外線=∥b _あなた−bv∥2。2 つの地域提案の和集合 (IoU) iou uv \operatorname{iou}_{uv}イオウ紫外線(図 5(b) の挿入図を参照) は、領域の重複の尺度です。角度theta uv = arctan ( yu − yvxu − xv ) \operatorname{theta}_{uv}=\arctan \left(\frac{y_{u}-y_{v}}{x_{u} を計算します。 - x_{v}}\right)シータ紫外線=アークタン(バツあなた− ×vyあなた− yv)。地域ノード間の意味論的関係と空間的関係を組み合わせると、uuu 到 v v 辺vの式は次のとおりです。
eu → v = W vvisuv + W d dist uv + W i iou uv + W θ theta uv (4) e_{u \rightarrow v}=\mathbf{W}^{v} \mathrm{vis}_{uv }+\mathbf{W}^{d} \operatorname{dist}_{uv}+\mathbf{W}^{i} \text { iou }_{uv}+\mathbf{W}^{\theta} \text {theta}_{uv}\tag{4}eう→う=W_を参照紫外線+Wd距離紫外線+ W私 は、私は 紫外線+Wθ シータ 紫外線( 4 )
其中 W v \mathbf{W}^{v} Wv、W d \mathbf{W}^{d}Wd、W i \mathbf{W}^{i}Wi和W θ \mathbf{W}^{\theta}Wθ は、意味的関係と空間的関係の重みのバランスをとるパラメーターです。

3.4 隠しオブジェクトの推論
各画像の関係グラフに基づいて、難読化された領域に隠されたプライバシー関連オブジェクトのカテゴリを推測します。私たちは、画像内のシーンと識別可能なオブジェクトを考慮して、隠れたオブジェクト クラスの確率分布を学習することを期待しています。私たちのアルゴリズムについては、アルゴリズム 2 で説明します。

グラフ ニューラル ネットワーク ( GNN ) [32] は、非表示オブジェクトの近傍を通るノード間での反復メッセージの受け渡しを通じて、非表示オブジェクトの表現を記述するのに役立ちます。ttthを定義しますt反復ステップvvvのノードの状態はhv (t) \mathbf{h}_{v}^{(t)} にhv( t )、ノードのステータスを次のように初期化します。
hv(0) = xv 。(5) \mathbf{h}_{v}^{(0)}=\mathbf{x}_{v} .\tag{5}hv( 0 )=バツv。( 5 )
1 つの反復ステップで、xv \mathbf{x}_{v} はノードを集約することによって表されます。バツvおよびその隣接ノードのステータスと表現を更新しますvvvのノードのステータス。通信プロセスは次のように定義できます。
hv(t) = f(xv, x NBR(v), hv(t − 1), h NBR(v)(t − 1)), (6) \mathbf{h}_{v}^{(t )}=\mathbf{f}\left(\mathbf{x}_{v}, \mathbf{x}_{\mathrm{NBR}(v)}, \mathbf{h}_{v}^{( t-1)}, \mathbf{h}_{\mathrm{NBR}(v)}^{(t-1)}\right),\tag{6}hv( t )=f( ×v、バツNBR ( v )、hv( t − 1 )、hNBR ( v )( t − 1 ))、( 6 )
ここでf ( ⋅ ) f(・)f ( ⋅)はパラメトリック関数NBR ( v ) \mathrm{NBR}(v)NBR ( v )はvvを意味しますvの隣接ノード
いくつかの研究では、グラフ畳み込みニューラル ネットワーク(GCN ) が物体検出におけるグラフ推論に寄与していることが示されています[19、43]。彼らはグラフを使用して領域間の関係を記述し、GCN を適用して対象領域の潜在的な視覚表現を学習します。ただし、GCN がこのシナリオに適用される場合、混乱領域の状態が他のノードの学習に悪影響を与える可能性があるという問題に直面します。Gated Graph Neural Network ( GGNN ) [22] に続いて、Gated Recurrent Unit [10] を導入して、混乱領域ノードを制御し、リセット ゲートを通じてオブジェクトを識別します。混乱の状態を更新しながら、ノードの悪影響を軽減します。エリアノードは、アップデートゲートを通じて他のノードから収集されたメッセージを使用します。
各伝播ステップでは、ノードvvv は、グラフの隣接行列に従って、その隣接ノードv ∈ NBR ( v ) v∈\mathrm{NBR}(v)v∈NBR ( v )の集約ノードは x ~ v \widetilde{\mathbf{x}}_{v}として表されますバツ v:
x ~ v ( t ) = E : v ⊤ [ h 1 ( t − 1 ) ⋯ h ∣ V ∣ ( t − 1 ) ] , \extend{\mathbf{x}}_{v}^{(t)} =E_{: v}^{\top}\left[\begin{array}{lll} \mathbf{h}_{1}^{(t-1)} & \cdots \mathbf{h}_{| V|}^{(t-1)}\end{配列}\right],バツ v( t )=E: v⊤[h1( t − 1 )⋯h∣ V ∣( t − 1 )】、
其中 E : v E_{: v} E: vノードvvと一緒ですvに関連する入力エッジは、tt 番目t の伝播ステップでzvt \mathbf{z}_{v}^{t}zvた、rvt \mathbf{r}_{v}^{t}にリセットしますrvた:
zvt = σ ( W zx ~ v ( t ) + U zhv ( t − 1 ) ) 、rvt = σ ( W rx ~ v ( t ) + U rhv ( t − 1 ) ) 、(8) \begin{aligned} \mathbf{z}_{v}^{t}&=\sigma\left(\mathbf{W}^{z} \ワイド割り当て{\mathbf{x}}_{v}^{(t)}+ \ mathbf{U}^{z}\mathbf{h}_{v}^{(t-1)}\right), \\\mathbf{r}_{v}^{t}&=\sigma\ left (\mathbf{W}^{r} \ワイド割り当て{\mathbf{x}}_{v}^{(t)}+\mathbf{U}^{r} \mathbf{h}_{v} ^{ (t-1)}\right), \end{aligned}\tag{8}zvたrvた=p( Wzバツ v( t )+Uzh _v( t − 1 ))、=p( Wrバツ v( t )+Ur hv( t − 1 ))、( 8 )
其中 W z \mathbf{W}^{z} Wz、U z \mathbf{U}^{z}Uz、W r \mathbf{W}^{r}Wr和U r \mathbf{U}^{r}Urはそれぞれ更新ゲートとリセット ゲートの学習可能なパラメーターです。σ σσはシグモイドを表します。zvt \mathbf{z}_{v}^{t} を使用しますzvた和rvt \mathbf{r}_{v}^{t}rvた更新vv _vのノード状態は、tanh \tanhを使用してアクティブ化されます。タン関数:
h ~ v ( t ) = Tanh ( W ⋅ x ~ v ( t ) + U ( rvt ⊙ hv ( t − 1 ) ) ) , hv ( t ) = ( 1 − zvt ) ⊙ hv ( t − 1 ) + zvt ⊙ h ~ v ( t ) , (9) \begin{aligned} \widetilde{\mathbf{h}}_{v}^{(t)}&=\tanh \left(\mathbf{W} \cdot \widetilde{\mathbf{x}}_{v}^{(t)}+\mathbf{U}\left(\mathbf{r}_{v}^{t} \odot \mathbf{h}_{ v}^{(t-1)}\right)\right), \\ \mathbf{h}_{v}^{(t)}&=\left(1-\mathbf{z}_{v} ^{t}\right) \odot \mathbf{h}_{v}^{(t-1)}+\mathbf{z}_{v}^{t} \odot \widetilde{\mathbf{h} }_{v}^{(t)}、\end{整列}\tag{9}h
v( t )hv( t )=胡散臭い( W⋅バツ
v( t )+U( rvた⊙hv( t − 1 )) )、=( 1−zvた)⊙hv( t − 1 )+zvた⊙h
v( t )、( 9 )
その中で、⊙ ⊙⊙は要素ごとの乗算です。
さらに、いくつかのオブジェクトが相互により強く相関する現象も観察されました。たとえば、ある人は、路上の消火栓よりも、同じイベントに参加している他の人との社会的関係によってプライベートであると定義される可能性が高くなります。混乱した領域内のノードの表現に対する他のノードの寄与を測定するためのアテンション メカニズムを追加します。私たちのアテンション メカニズムは、グラフ アテンション ネットワーク ( GAT ) [38]とは少し異なります。混同領域ノードu ∈ V pu \in V^{p}を計算します。あなた∈Vpとその隣接ノードrelevance)
e ~ u → v = fa ( [ W a ⋅ hu ∥ U a ⋅ hv ] ) 、 α u → v = σ ( LeakyReLU ( e ~ u → v ) ) (10) \begin{aligned} \wide assigns}_{u \rightarrow v} & =\mathbf{f}_{a}\left(\left[\mathbf{W}^{a} \cdot \mathbf { h}_{u}\|\mathbf{U}^{a}\cdot\mathbf{h}_{v}\right]\right), \\\alpha_{u\rightarrow v} & =\sigma \ left(\operatorname{LeakyReLU}\left(\wideassignment{e}_{u \rightarrow v}\right)\right) 。\end{整列}\tag{10}e う→うあるう→う=fあ( [ Wある⋅hあなた∥U _ある⋅hv] )、=p( LeakyReLU(e う→う) ).( 10 )
その中には[ ⋅ ∥ ⋅ ] [·∥·][ ⋅∥ ⋅] は混乱領域ノードuuuとその近傍のノードv ∈ NBR ( u ) v∈\mathrm{NBR}(u)v∈NBR ( u )、の連結f}_a(・)fあ( ⋅)は、高次元のノード状態の接続を実数σ σσは活性化されたシグモイドです。この目的のために、隣接ノードの状態を収集し、スプライスする前に注意係数で重み付けします。
hv ′ = ∥ u ∈ NBR ( v ) α u → vhu (11) \mathbf{h}_{v}^{\prime}=\|_{u \in \operatorname{NBR}(v)} \ alpha_{u\rightarrowv}\mathbf{h}_{u}\tag{11}hv「=∥u ∈ NBR ( v )あるう→うhあなた( 11 )
難読化された領域内の隠れたオブジェクトの識別は、結局はノード分類問題に帰着します。最後に、最終的な状態とノードの表現が分類に使用されます。
oi = g ( hi ′ , xi ) o_{i}=\mathbf{g}\left(\mathbf{h}_{i}^{\prime}, \mathbf{x}_{i}\right)ああ私は=g( h私「、バツ私は)
ここでg ( ⋅ ) \mathbf{g}(·)g ( ⋅)は分類器であり、実験ではソフトマックスて実装されました

4 評価
4.7 概要
要約すると、私たちの実験結果は、隠されたオブジェクトの発見と分類の精度を通じて、画像難読化技術におけるプライバシーの再開示のリスクを示しています。客観的には、私たちの方法は、難読化された画像に隠されたプライバシー関連のオブジェクトを発見するために考えられるいくつかの方法よりも大幅に優れています。さらに、私たちのスキームがさまざまな難読化技術に一般化できることを示します。私たちは 10 人のボランティアを募集して、隠されたオブジェクトの難読化された 1,000 枚の画像を観察してもらいました。その結果、テストした難読化技術の半分について、このスキームが人間の目での観察に匹敵することがわかりました。特に、私たちのスキームは、画像が修復によって難読化されている場合に、人間の目では検出できない隠された個人情報を明らかにすることができます。
さらに、モバイルデバイスにシステムを実装し、処理時間コストを評価しました。携帯電話を使用して、難読化された画像内のプライバシーに関連するオブジェクトを 2 秒で推測できます。
6 議論と結論
私たちのアプローチは、物体検出、画像操作の検出と位置特定、シーン分類などのコンピューター ビジョン タスクに使用されるモデルのパフォーマンスに影響を受ける可能性があります。図 11 は、混乱を招く領域の位置特定により精度が平均 0.39% 低下することを示しています。

一方、隠れたオブジェクトの推論は、難読化された領域のコンテキスト情報に依存します。いつ
- (1) 画像内に識別可能なオブジェクトがない場合、ソリューションは失敗する可能性があります。
- (2) 混同領域の割合が画像の 80% を超えている。
最初のケースでは、周囲の物体に関する手がかりがないため、シーンの分類と、そのシーンに強く関連している可能性のある物体のみに頼ることができます。図 9 に示すように、大規模な混乱は推論に深刻な影響を与える可能性があります。画像の 80% 以上が操作されているか遮蔽されている場合、シーンを正確に分類することは困難です。したがって、隠れたオブジェクトのコンテキスト情報をモデル化することは困難です。

この研究では、難読化で保護された画像のプライバシー漏洩リスクを調査するために、難読化された画像内のプライバシー関連の隠されたオブジェクトのカテゴリを明らかにする効果的かつ効率的なスキーム HideSeeker を設計します。オブジェクトの元の視覚的特徴は、難読化技術によって大幅に操作または隠蔽されているため、オブジェクト検出アルゴリズムがそれらを認識できなくなります。私たちは、意味論的および空間的関係グラフを通じて隠れたオブジェクトのコンテキスト情報を統合することで、この課題に対処します。
処理など、いくつかの興味深いタスクが今後の作業として残されています。
- 1) 識別可能な物体の画像はありません。
- 2) 極端にぼやけた領域のある画像。
また、保護されたビデオに隠されたオブジェクトを発見するために研究を拡張する予定です。