背景
ClickHouse はオープンソースの OLAP エンジンであり、世界中の開発者によって広く使用されているだけでなく、Byte のさまざまなアプリケーション シナリオでも見ることができます。ClickHouse は、高いパフォーマンスと分散特性に基づいて、大規模データの分析とクエリのニーズを満たすことができるため、Byte R&D チームは、オープンソースの ClickHouse をベースにした Volcano Engine のクラウドネイティブ データ ウェアハウス ByteHouse を立ち上げました。
研究開発担当者は、日々の業務の中で、ビジネス リンクが長すぎてプロセスの安定性とデータの一貫性を確保することが困難になるという問題に遭遇することがよくありますが、これは分散シナリオやクロスサービス シナリオでより顕著になります。この記事では、この問題の解決策を提案します。それは、火山エンジン ByteHouse に軽量プロセス エンジンを構築して、データの一貫性の問題を解決することです。
軽量のプロセス エンジンを使用すると、統一された標準を使用して、複雑なビジネス リンクのオーケストレーション問題を解決できます。ビジネス コードの可読性と再利用性が向上するだけでなく、コア ビジネス ロジックの開発により重点が置かれ、プロセス全体がより効率的になります。標準化、標準化。
要約すると、プロセス エンジンを使用すると次のような利点があります。
軽量、アクセスしやすい、メモリ操作、保証されたパフォーマンス
容易なメンテナンス、プロセス構成と業務分離、ホットアップデートのサポート
拡張が容易で、豊富な実行戦略とオペレーターのサポート
一般的なアイデア
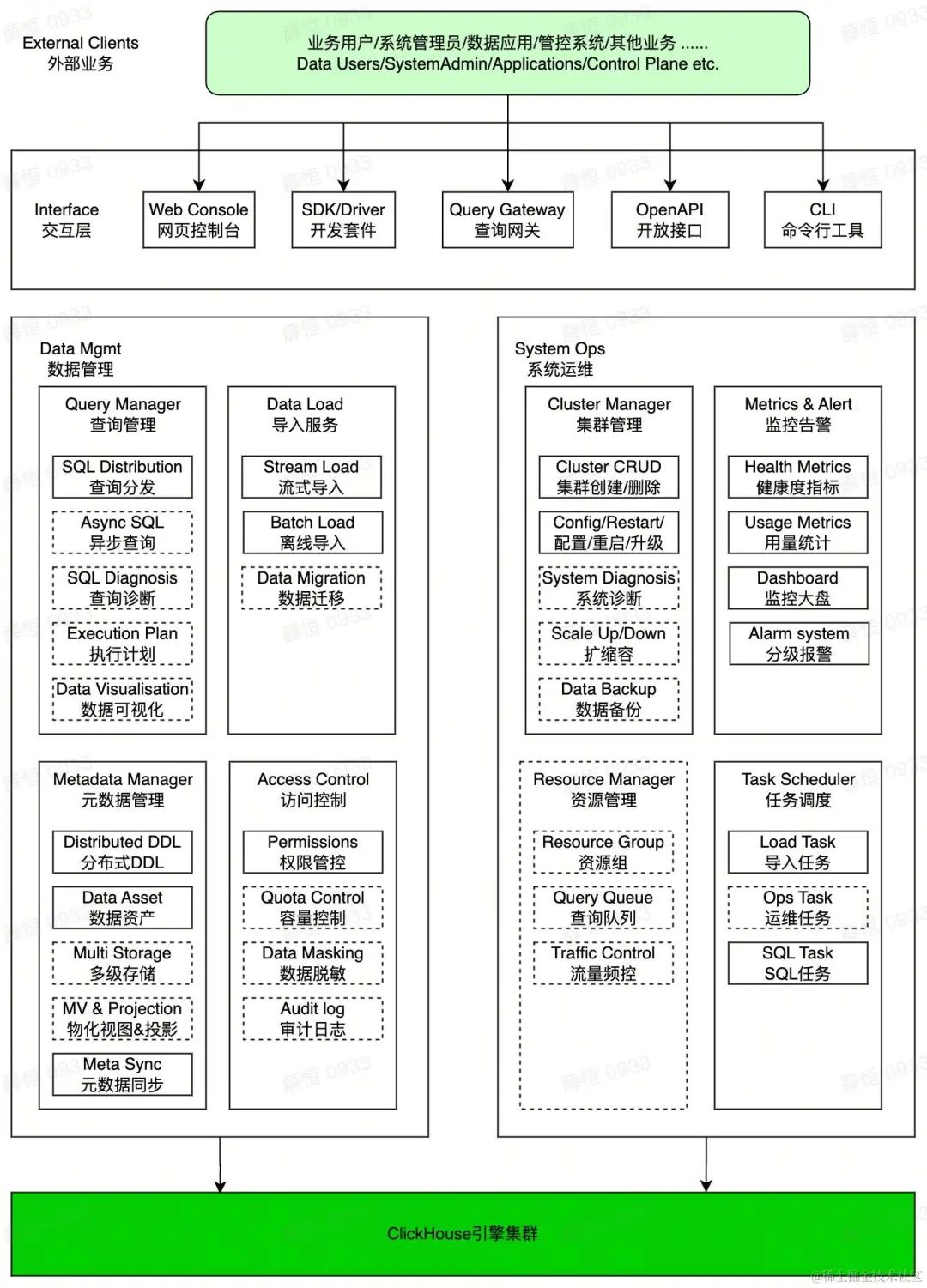
上の図は、ByteHouse Enterprise Edition 管理プラットフォームの機能アーキテクチャ図です。機能アーキテクチャ図からわかるように、ByteHouse のコア機能は ClickHouse クラスターに依存しています。多くのクラスター ノードと大量のデータ計算を伴うビジネス シナリオでは、一貫性のないノード ステータスが発生しやすいため、これが重要です。 ClickHouse クラスター間のステータスの一貫性を確保するため。

データの一貫性を確保するために、ByteHouse は次の機能を提供します。
イベント エンジン: イベント処理センター
ワークフロー エンジン: 軽量プロセス エンジン
照合システム
データの一貫性を確保する最も簡単な方法は、ステート マシンを通じてプロセス実行プロセスを監視することです。
まず、すべてのタスク要求はイベント エンジンに送信され、イベント エンジンは対応するハンドラーにタスクを振り分けて実行し、発行されたすべてのタスクのライフ サイクルを一元管理し、非同期リトライやロールバック補償などの機能を提供します。イベントエンジンにトラフィックが集約されると、その後のサービスのビジネス展開がより便利になります。
次に、より複雑なタスク リクエストの場合は、実行のためにワークフロー エンジンに送信できます。ワークフローはインスタンスを生成し、タスク キューを配置し、プロセス実行インスタンスのライフ サイクルを管理し、失敗時の統合ロールバックと失敗時の再試行を実装します。
最後に、調整サービスは、サービスの利用不能などの特別なシナリオで生成されたダーティ データを処理します。
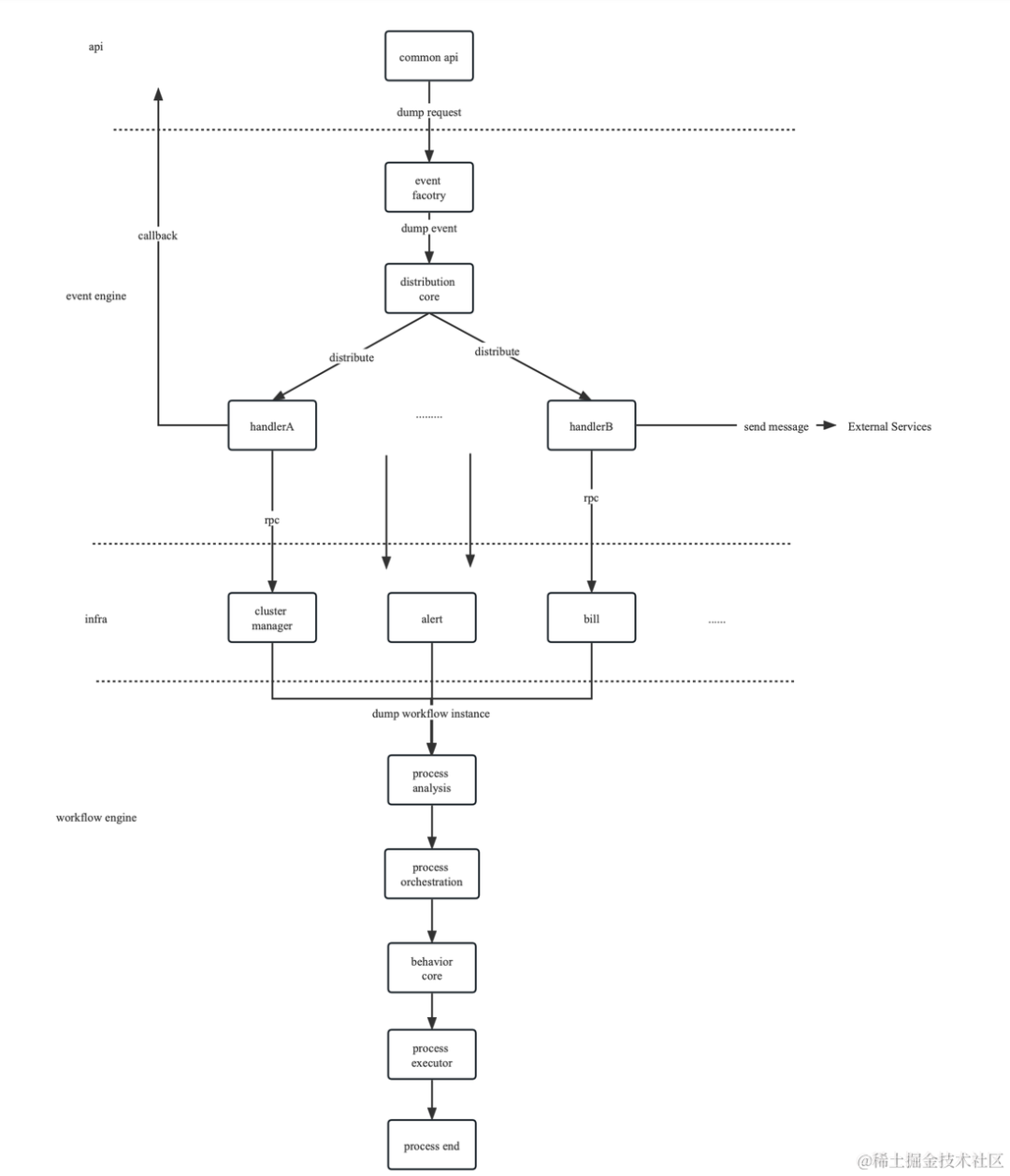
建築デザイン
プロセス監視のアーキテクチャ設計には、主に次のものが含まれます。
プロセス管理層: 主にプロセス構成の解析と初期化、および戦略の調整作業の完了を担当します。
ポリシー動作レイヤー: 実行ノードを調整し、実行タスクを実行者に配信します。
Executor: 実行ノードの実行を管理します。
実行ノード: ビジネスの特定の実装を担当します。
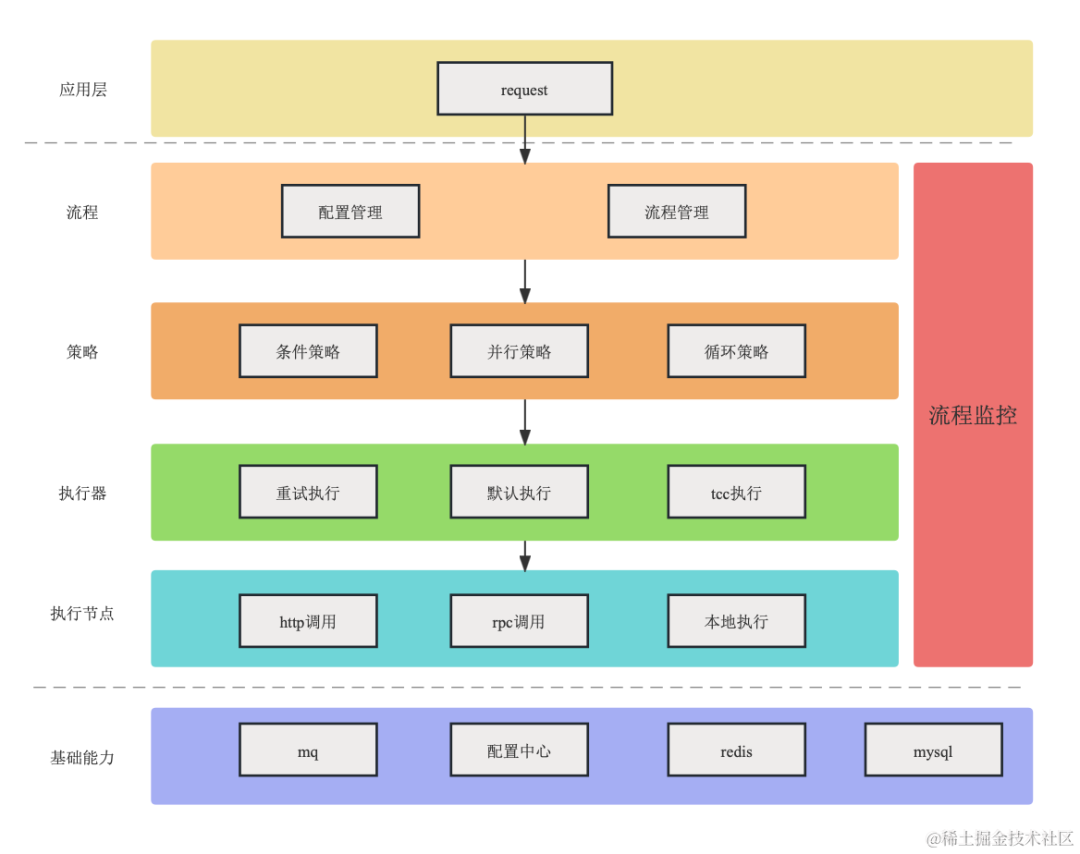
実行計画
実行ノード

プロセス エンジンの中核は「責任チェーン」であり、責任チェーン上のノードの順序に従ってすべてのタスクを順番に実行します。そのため、必要な 3 つの基本ユニットは次のとおりです。
リクエスト: 入力パラメータ
processlist: プロセス実行ノードのリスト
応答: パラメータ出力
研究開発の仕事では、次のような問題に遭遇することがよくあります。
同時に問題が発生した場合、node1、node2、node3 間のデータ インタラクションをどのように実装すればよいでしょうか?
ノード 1 の入力パラメーターとノード 2 とノード 3 の出力パラメーターが異なる場合はどうすればよいですか?
異なるパラメータタイプを持つノードを均一にスケジュールするにはどうすればよいですか?
最も簡単な解決策は、ノードに同じコンテキスト情報を使用させ、実行ノード全体をテンプレート化することです。すべての実行ノードに同じインターフェイス Delegation を実装させ、同じコンテキストのExecutionContextを実行メソッドの入力パラメータとして使用させます。
プロセス内のリクエストとレスポンスについては、executionContext に置くことで、各実行ノードがコンテキストを通じてレスポンスを操作できるようになります。
// Delegation -
type Delegation interface {
Execute(ctx context.Context, executionContext ExecutionContextInterface) apperror.AppError
TryExecute(ctx context.Context, executionContext ExecutionContextInterface) apperror.AppError
ConfirmExecute(ctx context.Context, executionContext ExecutionContextInterface) apperror.AppError
CancelExecute(ctx context.Context, executionContext ExecutionContextInterface) apperror.AppError
Code() string
Type() value.DelegationType
}実行戦略
最小の実行ノードが決まっている場合、ビジネス シナリオでは必ずしもノードを順番に実行して結果を返すわけではないことを考慮する必要があります (ジャンプ、ループ、同時実行はすべて、プロセス実行時の一般的な操作です)。さまざまなビジネス シナリオの再利用性を考慮して、実行ノードの上に実行戦略のレイヤーを追加し、戦略の動作を使用して実行ノードをトリガーするタスクを再編成します。
以下の図は、プロセスを異なる戦略に対応する動作 1 と動作 2 に分割しています。
単純な戦略の例: 順次実行、同時実行、ループ実行、条件付きジャンプ実行など。
実際のビジネスニーズに応じてカスタマイズできます。例は後ほど紹介します。

// ActivityBehavior -
type ActivityBehavior interface {
Enter(ctx context.Context, executionContext ExecutionContextInterface, pvmActivity PvmActivity) apperror.AppError
Execute(ctx context.Context, executionContext ExecutionContextInterface, pvmActivity PvmActivity) apperror.AppError
Leave(ctx context.Context, executionContext ExecutionContextInterface, pvmActivity PvmActivity) apperror.AppError
Code() value.ActivityBehaviorCode
}ポリシー動作には、Enter、Execute、および Leave の 3 つのインターフェイスが用意されています。Enter は実行ノード タスク インスタンスの生成を担当し、Execute はタスク インスタンス操作の調整とトリガーを担当し、Leave は次の動作へのジャンプを担当します。
ストラテジ動作のジャンプ方法はリンクリストに似ており、次のメソッドが継続的に実行されていることがわかりますので、コーディング中は無限ループにならないように注意し、スタックオーバーフローに注意する必要があります。 。
執行者
エグゼキュータの主な機能は、ストラテジと実行ノードを連続して実行することであり、ポリシー動作によって実行コマンドがエグゼキュータに送信され、エグゼキュータが実行ノードをトリガーします。ここでは、実行ノードの種類に応じて、1 回実行され複数回再試行される tcc を含む、実行ノードの 3 つの実行モードにマッピングされます。
// DelegationExecutor -
type DelegationExecutor interface {
execute(ctx context.Context, executionContext ExecutionContextInterface) apperror.AppError
postExecute(ctx context.Context, executionContext ExecutionContextInterface) apperror.AppError
}
func (de *DefaultDelegationExecutor) execute(ctx context.Context, executionContext ExecutionContextInterface) apperror.AppError {
delegationCode := executionContext.GetExecutionInstance().GetDelegationCode()
if len(delegationCode) == 0 || de.DelegationMap[delegationCode] == nil {
logger.Info(ctx, "DefaultDelegationExecutor delegation code not found,use default delegation", zap.String("delegationCode", delegationCode))
delegationCode = string(value.DefaultDelegation)
executionContext.GetExecutionInstance().SetDelegationCode(delegationCode)
}
return de.dumpExecute(ctx, executionContext, delegationCode)
}
func (de *DefaultDelegationExecutor) dumpExecute(ctx context.Context, executionContext ExecutionContextInterface, delegationCode string) apperror.AppError {
FireEvent(ctx, executionContext, value.ExecutionStart)
var err apperror.AppError
delegation := de.DelegationMap[delegationCode]
switch delegation.Type() {
case value.TccDelegation:
err = tccExecute(ctx, executionContext, delegation)
case value.SingleDelegation:
err = singleExecute(ctx, executionContext, delegation)
case value.RetryDelegation:
err = retryExecute(ctx, executionContext, delegation)
}
if err != nil {
logger.Error(ctx, "delegation.Execute_err", zap.Error(err))
return apperror.Trace(err)
}
FireEvent(ctx, executionContext, value.ExecutionEnd)
return nil
}実行コンテキスト
ExecutionContext コンテキストは、以下を含むプロセス実行のすべての詳細を記録するために使用されます。
ProcessEngineConfigurationInterface: プロセス定義情報
ExecutionInstanceInterface: 実行ノードのインスタンス
ActivityInstanceInterface: 実行戦略インスタンス
ProcessInstanceInterface: プロセス インスタンス
リクエスト: 入力パラメータ
応答: 戻り値
プロセス全体の実行の安定性を確保するため、レスポンス以外の他のインスタンス パラメータの書き込みインターフェイスを開くことはお勧めしません。レスポンスは、プロセス インスタンスの実行中に生成される変数情報を格納するために使用できます。
プロセス全体 (ProcessEngineConfiguration) の定義には、構成情報をデータベース内の json 文字列にマップするという最も単純な方法を選択できます。もちろん、読みやすく、データが失われない限り、構成ファイルを読み取ることを選択することもできます。
// ExecutionContextInterface -
type ExecutionContextInterface interface {
GetProcessEngineConfiguration() ProcessEngineConfigurationInterface
SetProcessEngineConfiguration(processEngineConfiguration ProcessEngineConfigurationInterface)
GetExecutionInstance() instance.ExecutionInstanceInterface
SetExecutionInstance(executionInstance instance.ExecutionInstanceInterface)
GetActivityInstance() instance.ActivityInstanceInterface
SetActivityInstance(activityInstance instance.ActivityInstanceInterface)
GetProcessInstance() instance.ProcessInstanceInterface
SetProcessInstance(processInstance instance.ProcessInstanceInterface)
SetNeedPause(needPause bool)
IsNeedPause() bool
SetActivityIndex(activityIndex int)
GetActivityIndex() int
SetActivityBehaviorCode(activityBehaviorCode value.ActivityBehaviorCode)
GetActivityBehaviorCode() value.ActivityBehaviorCode
SetBizUniqueKey(bizUniqueKey string)
GetBizUniqueKey() string
GetRequest() map[string]interface{}
SetRequest(request map[string]interface{})
GetResponse() map[string]string
SetResponse(response map[string]string)
AtomicAddResponse(key string, value string)
}リスナー
リスナーの主な機能は、プロセスの実行中に重要なパラメーター情報を監視することです。上記のエグゼキューター インターフェイスから fireEvent を確認できます。その機能は、メッセージ イベントを送信し、リスナーが対応するイベント タイプをリッスンし、カスタマイズされた動作を完了することです。
アスペクト指向プログラミングと同様に、ログ記録、ノード実行時間の監視、プロセスで生成された応答情報の永続化、リンク追跡の追加など、ノードの実行前後にカスタマイズされたロジックを追加できます。
API
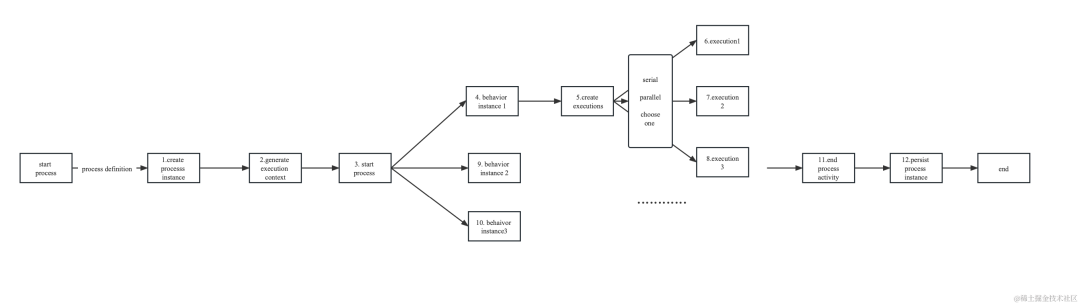
最後に、上記のコンテンツをつなぎ合わせて接続し、3 つの主要なインターフェイスを提供します。
開始: プロセスを開始します
シグナル: 一時停止または異常終了後、実行プロセスを継続します。
アボート:プロセスを強制的に中断します。
process start(){
//1.get and create ProcessEngineConfigurationInterface 解析流程定义
//2.create processInstance 创建流程实例
//3.create ExecutionContext 创建执行上下文
//4. lockstrategy trylock
//5. invoke process start
processinstance.start()
//6. persist processInstance and return
//7. lockstrategy unlock
}
processinstance start(){
// get behavior
// behavior enter
behavior.Enter(ctx, executionContext)
//behavior execute
behavior.Execute(ctx, executionContext)
//behavior leave
behavior.Leave(ctx, executionContext)
}start と比較して、signal は実行の詳細を読み取り、以前に失敗した実行ノードの場所を見つけて、それをコンテキストにロードして、実行を続行する必要があります。
障害が発生したノードの情報を保持するには 2 つの方法があります: 1 つ目は、プロセス実行の終了時に保持することを選択でき、2 つ目は、リスナーを介して各実行ノードで保持を終了することができます。実際のビジネス シナリオのパフォーマンスとデータの一貫性の要件に基づいて、具体的な決定を行ってください。
同時シナリオの考慮
動作ポリシーのカスタマイズ、同時実行、複数の実行ノードやシナリオの処理には必ず問題が発生し、同時に変更するとデータの混乱が確実に発生します。簡単な方法は、ロックされたコンテナを使用して変更可能な情報 (応答) を保存することであり、ここでは github.com/bytedance/gopkg パッケージにカプセル化されたスキップマップが使用されます。
Lockstrategy は、ビジネス シナリオに最適なものを定義できます。最も簡単なソリューションは redis ロックで、システムが異常終了した後の回復の問題も考慮されています。特殊な状況下で例外をロックするソリューションについては、redis 公式 Web サイトを参照してください: https://redis.io/commands/setnx/
フォローアップ作業
軽量プロセス エンジンの基本機能はこれまでに実装されており、その後の拡張と最適化は次の方向で実行できます。
インターフェイスディスプレイにはリンクの実行ステータスを表示できます
戦略的行動の次元が拡張され、さまざまなビジネスシナリオに適応します
サブプロセスの次元を増やし、元の実行ロジックを再利用する
デモの例
以下は単純なプロセス構成の構成情報であり、ここでは同期逐次実行戦略である DefaultBehavior が使用されています。
{
"ProcessContentList":[
{
"Behavior":"DefaultBehavior",
"DelegationList":[
{
"Code":"sample1"
},
{
"Code":"sample2"
},
{
"Code":"sample3"
}
]
},
{
"Behavior":"DefaultBehavior",
"DelegationList":[
{
"Code":"sample4"
},
{
"Code":"sample5"
}
]
}
]
}
リスナーにログを追加すると、プロセス全体の実行を追跡できるようになり、プロセス全体の実行ステータスをより適切に監視できるようになります。
実際の使用
ClickHouse クラスターのスケーリングを例に挙げます。
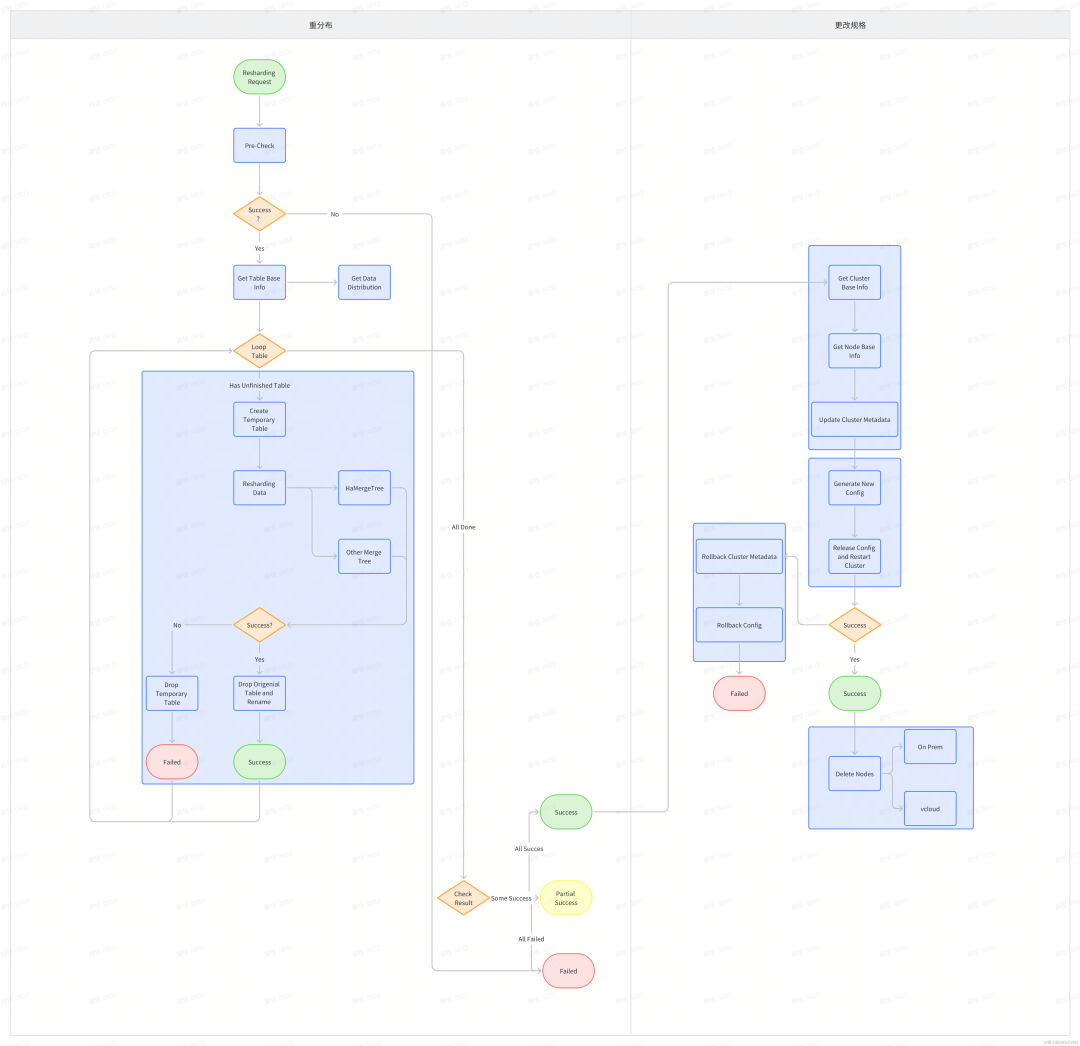
{
"ProcessContentList":[
// 查询所有需要重分布的table
{
"Behavior":"DefaultBehavior",// 顺序执行
"DelegationList":[
{
"Code":"hor_reshard_table_loop"
}
]
},
// 遍历所有table进行数据的重分布
{
"LoopKey":"reshard_table_loop_key",
"Behavior":"NonBlockLoopBehavior",// 非阻塞循环处理
"DelegationList":[
{
"Code":"hor_reshard_table"
}
]
},
// 进行删除节点操作
{
"Behavior":"DefaultBehavior",
"DelegationList":[
{
"Code":"hor_start_remove_node"
},
{
"Code":"hor_prepare_node_vcloud",
"PostCode":"hor_rollback_remove_node_vcloud"// 统一失败回滚处理
},
{
"Code":"hor_update_config_vcloud",
"PostCode":"hor_rollback_remove_node_vcloud"
},
{
"Code":"hor_set_cluster_running",
"PostCode":"hor_rollback_remove_node_vcloud"
},
{
"Code":"hor_release_node"
},
{
"Code":"hor_callback_bill"
}
]
}
]
}要約する
複雑なソリューション設計が受け入れられない限り、プロセス エンジンがすべてのビジネス シナリオに適応することはほぼ不可能であり、サードパーティのプロセス エンジンは日常のビジネス開発にはあまりにも扱いにくいです。軽量プロセス エンジンにより、アクセス方法が簡素化され、http リクエストが多すぎることによるパフォーマンスの低下が軽減され、より柔軟で変更可能になり、問題の追跡が容易になります。
ByteHouse にプロセス エンジンを追加できるため、ロールバックを繰り返す必要がなく、より低コストで再試行できる可能性が高まり、特に長時間かかるタスクのユーザー エクスペリエンスが向上します。さらに、プロセス エンジンはビジネス プロセスをテンプレート化し、インターフェイス サービスの再利用性を高め、ビジネス コードの読みやすさと拡張性を向上させ、後のメンテナンスを容易にすることもできます。
Volcano Engine のクラウド ネイティブ データ ウェアハウス ByteHouse は、Volcano Engine のクラウド ネイティブ データ ウェアハウスです。ユーザーに非常に高速な分析エクスペリエンスを提供し、リアルタイムのデータ分析と大量のデータのオフライン分析をサポートできます。また、便利な伸縮性のある拡張機能と収縮機能も備えています。パフォーマンスとエンタープライズレベルの豊富な機能は、顧客のデジタル変革を支援します。