
現時点では、このコンテンツはフェイシュ文書以外には表示できません。
ゼロ、一般化可能性
-
一般化可能性とは、新しいデータに適用され、トレーニング後に正確な予測を行うモデルの能力を指します。多くの場合、モデルはトレーニング データに基づいて適切にトレーニングされすぎ、つまり過剰適合され、一般化できません。

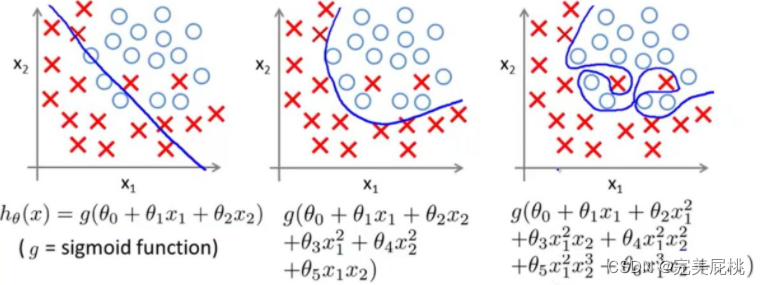
深層学習モデルの過剰適合の理由は、データ上の理由だけではありません。
-
モデルの複雑さが高すぎる: モデルにパラメータやレイヤーが多すぎる場合、トレーニング データの詳細を簡単に記憶できますが、新しいデータに一般化することができません。これにより、テスト データに対するモデルのパフォーマンスが低下する可能性があります。
-
不十分なトレーニング データ: トレーニング データの量が少なすぎる場合、モデルはデータの真の分布を捕捉できない可能性があるため、過剰適合する傾向があります。通常、トレーニング データが増えると、モデルの汎化パフォーマンスが向上します。
-
不適切な機能の選択: 問題に無関係な機能や冗長な機能を選択すると、過剰適合が発生する可能性があります。適切な機能の選択は、モデルのパフォーマンスにとって非常に重要です。
-
トレーニングに時間がかかりすぎる: トレーニングに時間がかかりすぎる場合、モデルは真のデータ パターンではなくノイズを記憶する可能性があります。トレーニング中に早期に停止するなどのテクニックを使用すると、これを回避できます。
-
正則化の欠如: L1 正則化や L2 正則化などの正則化手法は、モデル パラメーターのサイズを制限し、モデルが複雑になりすぎるのを防ぎ、過学習を軽減するのに役立ちます。
-
データの不均衡: トレーニング データ内の異なるクラス間のサンプル数が大きく異なる場合、モデルはより多くのサンプルを持つクラスを予測し、他のクラスを無視する傾向がある可能性があります。
-
ノイズの多いデータ: トレーニング データ内のノイズや誤ったラベル付けにより、モデルがこのノイズに適応しようとする際にモデルが過剰適合する可能性があります。
-
欠落している特徴: トレーニング データに存在しない特徴がテスト データに現れる場合、モデルはこれらの状況に対処できない可能性があり、その結果パフォーマンスが低下します。
-
ランダム性: 深層学習モデルには通常、ある程度のランダム性があり、モデルが初期化されている場合やデータが適切に分割されていない場合、トレーニング結果が不安定になる可能性があります。
過学習を解決するにはどうすればよいでしょうか? 一般化を改善しますか?
1. 通常のテクノロジー
1. 表示の規則性
(1)ドロップアウト: ニューラル ネットワークの過学習を防ぐ簡単な方法(ネットワークから始める)
ドロップアウトは、ネットワーク内の隣接するレイヤー間に適用されます。重要なアイデアは、いくつかのニューロンをランダムに選択し、各トレーニング反復でその出力をゼロに設定することです。これらのニューロンは、この反復における順伝播および逆伝播には参加しません。Dropout の鍵は、一定の確率 (通常は 0.5) でニューロンをドロップすることであり、この確率をドロップアウト率と呼びます。テスト段階では、すべてのニューロンが順方向伝播に参加しますが、目的の出力値を維持するために、その出力はドロップアウト率によってスケーリングされます。

なぜ Dropout が過学習を防ぐことができるのでしょうか?
-
ドロップアウトは、ニューラル ネットワーク内のニューロン間の同時適応を軽減し、特定の特定の特徴に対するモデルの過度の依存を軽減することで、汎化パフォーマンスを向上させます。ドロップアウト手順のため、ドロップアウト ネットワークに 2 つのニューロンが毎回現れるとは限りません。このようにして、重みの更新は固定関係を持つ隠れノードの共同アクションに依存しなくなり、特定の機能が他の特定の機能の下でのみ有効になることがなくなります。これにより、ネットワークは、他のニューロンのランダムなサブセットにも存在する、より堅牢な特徴を学習するようになります。言い換えれば、ニューラル ネットワークが何らかの予測を行っている場合、特定の手掛かりの断片に対してあまり敏感になってはならず、たとえ特定の手掛かりが失われたとしても、他の多くの手掛かりからいくつかの共通の特徴を学習できる必要があります。この観点から見ると、ドロップアウトは L1 および L2 の正則化に似ており、重みを減らすと、特定のニューロン接続の損失に対してネットワークがより堅牢になります。
-
ニューロンをランダムに破棄することにより、Dropout は複数の異なるサブモデルをトレーニングすることと同等であり、問題を解決する方法を共同で学習するため、モデルの堅牢性が向上します。
(2) データ増強(サンプルから始める)
-
データ拡張は、深層学習モデルの汎化パフォーマンスを向上させるために使用される強力な手法です。データ拡張では、トレーニング データに対して一連のランダムな変換と拡張を実行することで新しいトレーニング サンプルを生成します。これにより、モデル学習の多様性が高まり、過剰適合の問題が軽減されます。
-
データ拡張により過剰適合が防止されるのはなぜですか?
過学習を理解する一般的な方法は、パラメーターが多すぎる、サンプルが少なすぎる、というものです。データの拡張はサンプルを追加することと同等であるため、伝達される意味情報は同じであっても、モデルの観点からは異なります。目標は、モデルがトレーニング中にまったく同じ画像を 2 回表示しないことです。これにより、モデルはより多くのデータを観察できるようになり、汎化機能が向上します。一般的なアプローチは次のとおりです。
1) データソースからさらに多くのデータを収集する
2) 元のデータをコピーし、ランダムノイズを追加します。
3) リサンプリング
4) 現在のデータセットに基づいてデータ分布パラメータを推定し、この分布を使用してさらにデータを生成します。
(3)騒音騒音
一般的な正則化のタイプは、トレーニング中にノイズを注入することです。ノイズはニューラル ネットワークの隠れユニットに追加または乗算されます。ディープ ニューラル ネットワークをトレーニングするときに多少の不正確さを許容することで、トレーニングのパフォーマンスが向上するだけでなく、モデルの精度も向上します。入力データ自体にノイズを追加するだけでなく、アクティベーション、重み、または勾配にノイズを追加することもできます。ノイズが少なすぎると効果がありませんが、ノイズが多すぎるとマッピング関数の学習が困難になります。
2. 暗黙の規則性
(1)早期停止
早期停止は、過学習を防ぐために反復回数を切り捨てる方法です。つまり、モデルが反復的にトレーニング データセットに収束する前に反復を停止して、過学習を防ぎます。これは、トレーニング セットの一部を検証セットとして保持する相互検証戦略です。検証セットのパフォーマンスが悪化していることが確認された場合、モデルのトレーニングを停止します。ネットワークを初期化するとき、通常、最初は重みが小さくなりますが、トレーニング時間が長くなるにつれて、一部のネットワークの重みが大きくなる可能性があるためです。適切なタイミングでトレーニングを停止すると、ネットワークの機能を特定の範囲に制限できます。
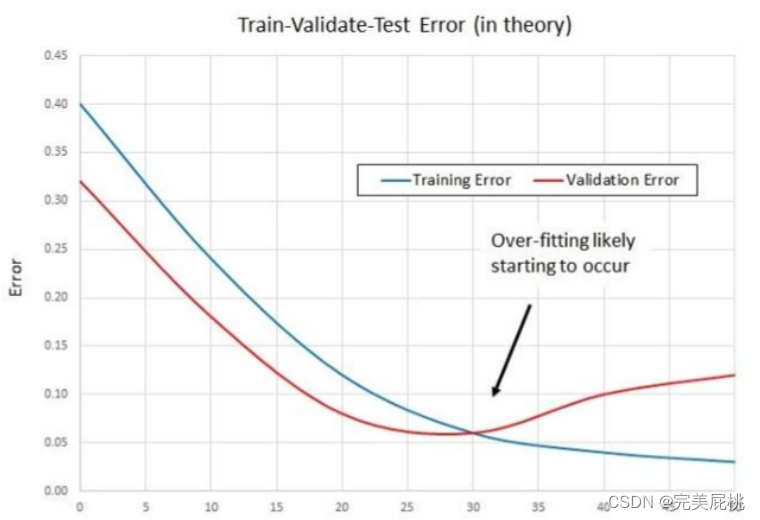
(2)バッチ正規化
バッチ正規化 (BN、Batch Normalization) は、ネットワーク入力を正規化する手法で、前の層のアクティブ化または直接入力に適用されます。この方法により、ネットワークの各層が他の層からできるだけ独立して学習できるようになります。BN は、アクティベーションを調整およびスケーリングすることで入力層を正規化します。
これは、大規模な畳み込みネットワークの学習を何倍も高速化できる非常に有用な正則化手法であり、同時に収束後の分類の精度も大幅に向上させることができます。BN が特定の層をトレーニングするとき、各ミニバッチ データを正規化して出力を N(0,1) の正規分布に正規化し、従来のディープ ニューラル ネットワークをトレーニングする場合の内部共変量シフト (内部ニューロン分布の変化) を削減します。 , 各層の入力の分布が変化しているため、トレーニングは困難です。非常に小さい学習率を使用することしか選択できません。しかし、各層で BN を使用すると、これは効果的に解決できます。問題、学習率は次のようになります。何度も増えました。

2. モデルの最適化
-
特徴量エンジニアリング:
-
適切な特徴を設計および選択すると、モデルがデータ内のパターンをより適切に捕捉し、汎化パフォーマンスを向上させることができます。
-
-
モデルの選択:
-
問題の性質と利用可能なデータに基づいて、適切なモデル アーキテクチャとモデル タイプを選択し、汎化パフォーマンスを向上させます。
-
深層学習を理解するには(まだ)一般化を再考する必要がある(ACM2021)
記事には次のように書かれていました。
(1) トレーニング プロセスと過学習: 深層学習モデルには通常、多数のパラメーターがあるため、モデルはトレーニング データに対して非常に良好なパフォーマンスを発揮できますが、トレーニング データのノイズと詳細を過剰記憶 (オーバーフィット) しやすくなります。 。過学習とは、目に見えないデータに対するモデルのパフォーマンスが低下することです。
(2)過学習と一般化の関係: 深層学習では過学習と一般化の関係が重要な問題となります。この記事では、トレーニング データでは過学習が問題であることはわかっているものの、過学習の程度と目に見えないデータに対するモデルの汎化パフォーマンスとの関係は単純ではない、と指摘しています。これは、トレーニング データを単に記憶するのではなく、高次元空間内の低次元多様体の構造を学習することによってモデルが一般化される可能性があるためです。
(3) 最適化手法と暗黙的な正則化効果: この記事は、確率的勾配降下法 (SGD) などの最適化手法自体が暗黙的な正則化効果を持つ可能性があるという興味深い点を提示しています。SGD は、ランダムなデータのミニバッチを使用して、各トレーニング反復でモデル パラメーターを更新する確率的手法です。著者は、SGD のこのランダム性がモデルの解空間を制限し、学習されたモデルに特定の一般化能力を持たせることができると考えています。これは、最適化手法自体が過学習のリスクを軽減し、汎化パフォーマンスを向上させる上で一定の役割を果たすことを意味します。
3.反撃
機械学習モデルに敵対的データを追加すると、欺瞞的な識別結果が得られる可能性があります。モデルの攻撃耐性を高めることができれば、当然モデルの汎化能力も高めることができます。
論文アドレス:堅牢なマルチメディア レコメンダー システムに向けた敵対的トレーニング (IEEE'2020)
コード: https://github.com/duxy-me/AMR
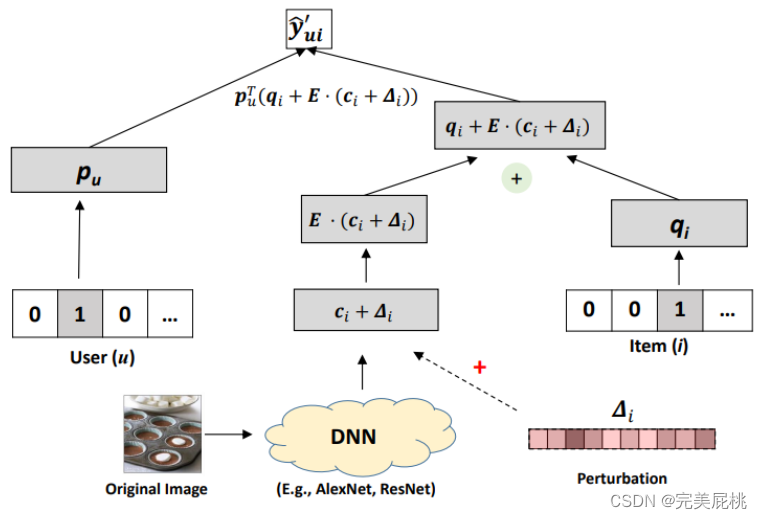
動機:著者は、既存の視覚的なマルチモーダル推奨モデルは十分に堅牢ではないことを提案します。入力画像に小さな人工ノイズ摂動 (敵対的サンプル) を追加した後、図に示すように、推奨リストのランキングが大幅に変化する可能性があります。下に。

イノベーション:著者は、ビジュアル セキュリティの分野からアイデアを引き出し、より堅牢で効率的な推奨モデルを取得するための敵対的トレーニング方法を提案します。敵対的トレーニングは、単に特別なデータ強化方法と考えることができます。
方法:minimax AMR モデルの学習プロセスは、ゲームをプレイするプロセスとして理解できます. 外乱ノイズは VBPR の損失関数を最大化することで得られ、モデルのパラメータは VBPR の損失関数と敵対性を最小化することによって得られます。損失関数。GAN モデルの考え方と同様に、この方法ではモデルがより堅牢になります。
-
トレーニング プロセスはミニマックス ゲームに似ています。記事では、AMR モデルのトレーニングはミニマックス ゲームとみなすことができると述べました。このゲームでは、2 つの主要なプレーヤーはモデル自体と一種の外乱ノイズです。これは、トレーニング プロセスに 2 つの競合する目的または損失関数が含まれることを意味します。
-
VBPR損失関数: VBPR は、ユーザーの過去の行動データと製品の視覚情報を組み合わせて、ユーザーが好む可能性のある製品を予測し、パーソナライズされたランキングを実行するマルチメディア推奨モデルです。トレーニング中に、VBPR の損失関数を使用してモデルの予測誤差を最小限に抑え、パーソナライズされた推奨事項のパフォーマンスを向上させます。
-
敵対的損失関数: トレーニング中に、敵対的損失関数が導入されます。これは、VBPR 損失関数を最大化することを目的とする敵対的な攻撃者 (摂動ノイズ) が存在することを意味します。つまり、攻撃者は入力データにノイズを追加することで VBPR モデルのパフォーマンスを低下させ、推奨事項の誤解を招くことを試みます。
-
モデルパラメータの最適化: トレーニングプロセス中、モデルのパラメータは同時に 2 つの損失関数の影響を受けます。一方で、モデルは、パーソナライズされた推奨事項のパフォーマンスを向上させるために、VBPR 損失関数を削減しようとします。一方、モデルは敵対的な攻撃者のノイズに耐性がある必要があるため、パフォーマンスの安定性を維持するには敵対的損失関数を最小限に抑える必要があります。
-
敵対的トレーニングと堅牢性: このトレーニング プロセスは、ジェネレーターとディスクリミネーターが互いに競合してより現実的なデータを生成する、敵対的生成ネットワーク (GAN) の考え方に似ています。ここでの敵対的トレーニングの目的は、レコメンデーション システムの堅牢性を強化して、より正確にパーソナライズされたレコメンデーションを提供しながら、外部の攻撃や干渉に耐えられるようにすることです。
-
yˆuiu製品に対するユーザーiの評価の予測値です。 -
puユーザーuの潜在ベクトル (または特徴ベクトル) であり、ユーザーの特性を表すために使用されます。 -
qii製品の潜在ベクトル (または特徴ベクトル)であり、製品の特性を表すために使用されます。 -
Eは追加のノイズまたはエラーを表す誤差行列で、通常は何らかの確率分布に従うと想定されます。 -
cii製品のコンテキスト情報のベクトルであり、製品の環境またはコンテキスト上の特徴を表すために使用されます。 -
∆iは、商品の追加オフセットであり、商品の補正項iとして理解できます。i
この式の目的は、ユーザーとアイテムの特徴ベクトル、および追加のコンテキスト情報とエラーを通じてアイテムに対するユーザーの評価を予測することです。通常、モデルのトレーニング プロセスでは潜在ベクトルを調整しpu、qi真の評価と予測された評価の間の誤差を最小限に抑えます。誤差項Eとコンテキスト情報をci使用してモデル内のノイズと環境情報をキャプチャし、予測精度を向上させることができます。
画像特徴抽出モデルは通常、推奨モデルとは別にトレーニングされるため、著者は、抽出された画像表現に敵対的摂動を直接追加する (埋め込み) ことを提案しています。ユーザ u のアイテム i に対する嗜好は次のとおりです。これは、ノイズを付加しない場合のユーザのアイテムに対する嗜好です。

Δi は画像埋め込みに追加される摂動ノイズを表し、ε は摂動の大きさを制御するハイパーパラメータです。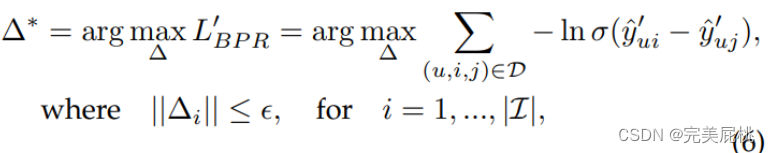
モデルのパラメーターは、次の損失関数を最適化することで取得されます。

y_ui は妨害ノイズのないアイテムに対するユーザーの好みであり、λ は敵対的トレーニングの強度を制御するハイパーパラメータです。λ=0 の場合、AMP は VBPR に劣化し、敵対的損失は特別な正則化項とみなすことができます。
4.転移学習
1. ドメインは通常、データの分布および特徴空間を指します。ドメインには次の要素が含まれます。
データ配布: ドメインはトレーニング データとテスト データの配布に関連します。転移学習では、通常、ソース ドメインとターゲット ドメインが存在します。ソース ドメインはモデルが最初にトレーニングされるドメインであり、ターゲット ドメインはモデルが最終的に良好なパフォーマンスを発揮する必要があるドメインです。これら 2 つのドメインのデータ分布は異なる場合があります。つまり、それらの特性、統計的特性などに違いがあります。
-
ソース ドメイン: これは、トレーニング プロセス中にモデルが接触するドメインであり、通常はモデルのトレーニングに使用されるラベル付きデータです。
-
ターゲット ドメイン: これは、テストまたは適用時にモデルが適用されるドメインで、通常はラベル付きデータがないか、ほとんどありません。
タスク: ドメインはタスクに関連することもよくあります。通常、ソース ドメインには 1 つ以上の関連タスクがあり、転移学習の目的は、これらのタスクの知識をターゲット ドメインの新しいタスクに転送することです。これは、ソース ドメインとターゲット ドメインのタスクは異なる可能性がありますが、それらの間にはある程度の相関関係がある可能性があることを意味します。
2. ドメイン適応:
-
ドメイン適応は、モデルがソース ドメインでトレーニングされ、その知識をターゲット ドメイン上の1 つ以上の関連タスクに転送しようとする転移学習問題です。
-
通常、ソース ドメインとターゲット ドメインにはある程度の相関関係がありますが、データの分布には多少の違いがある場合があります。ドメイン適応の目標は、ソース ドメインとターゲット ドメイン間の分布の違いを減らすことによって、ターゲット ドメインのモデルのパフォーマンスを向上させることです。
-
ドメイン適応では、ソース ドメインとターゲット ドメイン間のタスクが関連していることを前提としているため、モデルをターゲット ドメインのデータ分散に適応させて、ターゲット ドメイン上のタスクのパフォーマンスを向上させることを目的としています。
3. ドメインの一般化:
-
ドメインの一般化は、より困難な転移学習の問題であり、ターゲット ドメインの特定のタスクに関係なく、モデルが複数のソース ドメインでトレーニングされ、その後、目に見えないターゲット ドメインで一般化を試みます。
-
ドメイン汎化では、ソース ドメインとターゲット ドメイン間のタスクは無関係であると想定しており、その目標は、ソース ドメインのタスクに関係なく、ターゲット ドメインで良好な汎化パフォーマンスを達成することです。
-
ドメイン一般化は、ターゲット ドメインにタスク固有のラベル情報がない場合でも、モデルをより適切に一般化することを目的としています。
4. バイアスとは、現実世界の問題を近似するために単純化されたモデルを使用することによって生じる誤差を指します。モデルの平均予測値と真の値の差を表します。高いバイアスは、モデルがデータに十分に適合していないため、基礎となるパターンや関係を把握できないことを示します。
5. 分散とは、異なるトレーニング セットにわたるモデル予測のばらつきを指します。トレーニング データの変動に対するモデルの感度を測定します。分散が高い場合は、モデルがデータを過剰適合しており、ノイズやランダムな変化に対して敏感すぎることを示します。
6. 擬似ラベル付けでは、ラベル付きデータを使用して、ラベルなしデータにラベルを割り当てようとします。具体的には、擬似ラベルは次のように機能します。
-
ラベル付きデータ: まず、トレーニング データの一部にラベルが付けられています。これには、入力特徴と対応するグラウンド トゥルース ラベルが含まれます。
-
ラベルなしデータ: 次に、トレーニング データにはラベルのない部分、つまりラベルなしデータもあります。
-
トレーニングの初期段階: トレーニングの初期段階では、ラベル付きデータを使用してモデルをトレーニングします。これは従来の教師あり学習です。
-
擬似ラベルの生成: 次に、トレーニング済みモデルを使用して、ラベルなしデータを予測し、擬似ラベルを生成します。これらの擬似ラベルは、ラベルなしデータに対するモデルの予測結果です。★
-
ラベル付きラベルと擬似ラベルの組み合わせ: 次に、ラベル付きデータと擬似ラベル付きのラベルなしデータを、さらなるトレーニングのために一緒に使用します。これによりトレーニング データセットが拡張され、モデルがラベルのないデータから学習できるようになります。
-
反復: このプロセスは複数回反復でき、そのたびに新しい疑似ラベルが生成され、モデルのさらなるトレーニングのためにラベル付きデータとマージされます。
教師なしマルチソースフリードメイン適応におけるバイアスと分散のバランスについて ICML2023
論文アドレス: https://proceedings.mlr.press/v202/shen23b/shen23b.pdf
動機: ソース ドメインでトレーニングされたモデルは、異なるターゲット ドメインに適用されると汎化パフォーマンスが低下する可能性があります。教師なしドメインの適応は、ラベル付きソース ドメインから学習した知識をラベルなしターゲット ドメインに転送することで主に軽減され、単一のソース ドメインの適応は主に、ドメイン アライメント (ソース データとターゲット データ間の差異を最小限に抑える) と敵対的トレーニングによって軽減されます。現在、ソース データは通常、基盤となる分布が異なる複数のドメインから収集され、マルチソース ドメイン適応は、複数のソース ドメインからの知識を集約してターゲット ドメインに適応することを目的としています。ただし、プライバシーまたはストレージの制限により、トレーニング ソース モデルのデータにはアクセスできず、トレーニングされたモデルのみにアクセスできます。現在のマルチソースドメイン適応手法は、理論的根拠のない擬似ラベリング技術の改善や新たなトレーニング目標の提案に主眼が置かれており、これらではソースドメインとターゲットドメインの変換を解決できないため、この記事の著者はマルチソースドメインの適応を分析することを目的としています。ドメインの基本的な制限。
寄稿:著者は、MSFDA の汎化エラーは、①ラベル不一致エラー(擬似ラベル分布とターゲットラベル分布の間の不一致、データサンプルに割り当てられたラベルは真のラベルを正確に表現できない)、②特徴の不整合によって引き起こされると考えています。バイアス (空間内の異なるソース ドメインにおけるデータ分布間の差異または不整合を共同で表す) は、③ トレーニング サンプル数の分散に関連します。
上記の問題に対し、筆者は①ドメインアグリゲーションを提案しました。複数のソース ドメインの適切なドメイン集約により、ラベルの不一致の偏りを減らすことができます; ② 選択的な擬似ラベル。トレーニング用に選択的な擬似ラベル付きデータ サブセットを使用すると、ラベルの不一致のバイアスと分散のバランスをさらに調整できます; ③ ジョイント特徴の位置合わせ。統合フィーチャ位置合わせ戦略を使用すると、フィーチャの位置ずれのバイアスを低減することで、ドメイン シフトの問題に明示的に対処できます。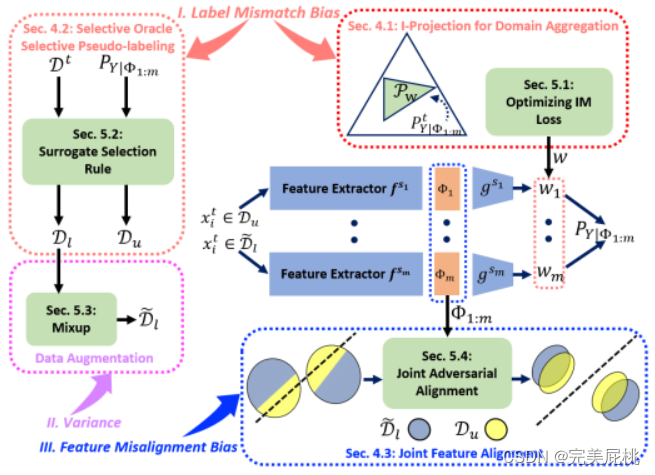
-
ドメイン集約は、複数のソース ドメインからの知識を結合して、ターゲット モデルのパフォーマンスを向上させることを目的としています。ソースドメインとターゲットドメイン間のラベルの不一致によって引き起こされるバイアスを軽減します。教師なしマルチソース ドメインフリー アダプテーション (MSFDA) のコンテキストでのドメイン集約には、主に 2 つの方法があります。1 つの方法は、複数のソース モデルからの予測に均一に重み付けすることですが、ソースが異なるため、これは最良の選択ではない可能性があります。 . ドメインの譲渡可能性はさまざまです。代わりに、非負のドメイン重みを持つ混合分布を考慮します。この場合、各ソース モデルの予測は異なる重み付けされます。このアプローチは、単一のモデルを使用するよりもバイアスを低くすることができ、ドメイン適応の問題に利益をもたらすことができます。最適なブレンド重みを持つソース モデルの数を増やすと、ターゲット モデルのパフォーマンスをさらに向上させることができます。
-
選択的擬似ラベル付けは、ターゲット ドメイン データのサブセットに対して擬似ラベルを生成するための、教師なしマルチソース パッシブ ドメイン アダプテーション (MSFDA) における戦略です。この戦略の目的は、擬似ラベルの生成中に特定の基準を採用して、境界付きラベルがバイアスと一致しないようにしながら、分散を削減して MSFDA のバイアスと分散のトレードオフのバランスを取ることです。選択的な擬似ラベルの生成: MSFDA では、通常、ターゲット ドメインの実際のラベルは利用できないため、トレーニング用に擬似ラベルを生成する必要があります。選択的擬似ラベル付けとは、ターゲット ドメイン内のすべてのサンプルに対してこの操作を実行するのではなく、ターゲット ドメイン データのサブセットに対してのみ擬似ラベルを生成することを指します。ラベル不一致バイアス基準: 生成された擬似ラベルがソースドメインデータのラベル分布とある程度一致していることを保証するために、基準 P(Dl|Y) ≤ P(t|y) が導入されます。ここで、Dl はターゲット ドメイン データ のラベル分布、t はソース ドメイン データを表します。この基準は、疑似ラベルの分布がソース ドメイン ラベルと過度に一致しないことを保証するための一致基準とみなすことができます。ラベル不一致のバイアスと分散の低減: 選択的擬似ラベル付けの主な利点は、ラベル不一致のバイアス (擬似ラベルの不正確さ) と分散 (擬似ラベルによってもたらされるノイズ) の間のトレードオフが低減されることです。信頼性の高いターゲット サンプルに対してのみ擬似ラベルを選択的に生成することで、これらのサンプルには正確な擬似ラベルが含まれる可能性が高く、より信頼性の高いトレーニング信号が提供されるため、擬似ラベルの分散を減らすことができます。トレードオフのバランスをとる: このアプローチは、ラベルの不一致のバイアスと分散の間のトレードオフのバランスをとるのに役立ちます。これにより、追加のトレーニング データの恩恵を受けながら、ターゲット モデルがノイズや不正確な擬似ラベルによって過度に影響を受けないようになります。
-
結合特徴アライメントとは、教師なしマルチソース パッシブ ドメイン アダプテーション (MSFDA) における複数のソース ドメインとターゲット ドメインの特徴表現をアライメントするプロセスを指します。このプロセスの目的は、ソース ドメインとターゲット ドメイン間の一貫性のない特徴表現の分布によって引き起こされる特徴の不整合のバイアスを軽減することです。特徴の不整列バイアスとは、異なるドメインにおける特徴表現間の差異を指し、この差異により、ターゲット ドメインでのモデルのパフォーマンスが低下する可能性があります。マルチソース機能の表現: MSFDA には、通常、複数のソース ドメインと 1 つのターゲット ドメインが存在します。各ドメインには独自の特徴表現があり、通常はディープ ニューラル ネットワークまたはその他の特徴抽出方法によって生成されます。これらの特徴表現はドメインによって異なる場合があります。特徴アライメント: ターゲット ドメインでのモデルのパフォーマンスを向上させるには、特徴アライメントを使用して、ソース ドメインとターゲット ドメイン間の特徴の不整合の偏差を減らす必要があります。特徴の調整の目的は、異なるドメインの特徴の表現をより類似または近づけることです。ジョイント フィーチャの位置合わせ: ジョイント フィーチャの位置合わせとは、ジョイント表現空間内の複数のソース ドメインとターゲット ドメインのフィーチャ表現を位置合わせすることを指します。これは、ソース ドメイン間の特徴量の調整を考慮するだけでなく、ターゲット ドメインの特徴表現をソース ドメインと調整して、同じ表現空間内でより一貫性が保たれるようにすることも考慮することを意味します。ジョイント敵対的特徴アライメント損失: ジョイント特徴アライメントを達成するには、ジョイント敵対的特徴アライメント損失などの損失関数を使用できます。この損失は、モデルのバイアスと分散のバランスをとり、特徴の不整合のバイアスを軽減し、ターゲット ドメインでのモデルのパフォーマンスを向上させるのに役立ちます。通常、これには、共同表現空間内で特徴表現の一貫性を高めるための敵対的トレーニングが含まれます。
-
ドメイン集約のための I-projection
I 投影は、教師なしマルチソース ドメイン適応におけるドメイン集約の手法であり、異なるソース ドメイン間の最大平均差 (MMD) を最小限に抑えることで、異なるソース ドメインの特徴量分布をターゲット ソース ドメインと一致させます。I 投影法は、ソース ドメインの特徴に基づいてターゲット ドメインの特徴表現を繰り返し更新することでこれを実現します。特徴抽出と特徴調整という 2 つの主なステップがあります。特徴抽出では、ターゲット モデルを使用してターゲット ドメインと特徴を抽出します。特徴アライメントでは、抽出されたターゲット特徴が MMD を使用してソース特徴と位置合わせされます。この不運により、ソース ドメインとターゲット ドメイン間の分散の差異が減少し、それによってドメイン適応パフォーマンスが向上します。
IM 損失の最適化: IM 損失によって推定される損失を最大化する情報は、教師なしマルチソース ドメインフリー適応のコンテキストで使用される損失関数です。これは、ソース モデルが個別に決定的でありながらグローバルな予測を行えるように最適化されています。IM 損失は、ソース モデルによって行われた予測のエントロピーと集約された予測のエントロピーの差を最大化することによって計算されます。これにより、ソース モデルは人の予測を確認しながら異なる予測を行うことが奨励され、ラベル付きソース データに即時損失を適用して、ラベルのないターゲット データにおける自信過剰で誤った疑似ラベルが発生するのを回避します。これは、ラベル不一致バイアスを軽減し、ドメイン適応タスクにおけるターゲット モデルのパフォーマンスを向上させるのに役立ちます。
-
選択的オラクル選択的擬似ラベリング
選択的オラクルとは、教師なしマルチソースのパッシブ ドメイン適応における理想的なシナリオを指します。オラクルを使用して、ラベルのサブセットに正しく擬似ラベル付けされたデータのみが含まれるようにすることができます。しかし、実際にはそのような神託はありません。選択的オラクルの利用不能の問題を克服するために、ラベル配布の品質を改善するための擬似ラベルノイズ除去技術と、擬似ラベル付けクエリ戦略のための新しいデータを選択するための信頼レベルを含むエージェント選択ルールが提案されています。選択的擬似ラベル付けは、ターゲット データのサブセットに擬似ラベルを割り当てるマルチソース ドメインフリー適応に使用される手法です。データのサブセットに疑似ラベルを選択的に割り当てることで、バイアスと分散の間のトレードオフのバランスをとることを目的としています。
擬似ラベルのノイズ除去や信頼性クエリ戦略などのエージェント選択ルールは、選択的なオラクルを必要とせずに選択的なラベル解除を実現するのに役立ちます。擬似ラベルのノイズ除去とは、教師なしマルチソースのパッシブ ドメイン適応においてターゲット データに割り当てられた擬似ラベルのノイズを低減するプロセスを指します。ターゲット データに対するソース モデルの予測は非常に混乱を招く可能性があり、プロトタイプ ベースの擬似ラベルのノイズ除去などのさまざまな手法を使用して擬似ラベルの品質を向上できるため、これは非常に重要です。信頼性クエリ戦略は、マルチソース ドメインフリー適応における疑似ラベルの新しいデータを選択するために使用されます。これらの戦略は、より正確に疑似ラベルを割り当てることができる最も信頼性の高いサンプルを特定することを目的としており、より高い信頼性でサンプルを選択することにより、疑似ラベルの品質が向上し、それによって適応パフォーマンスが向上します。
-
ジョイントフィーチャーの位置合わせ
ジョイント フィーチャ アライメントは、ジョイント表現空間内のラベル付きソース データとラベルなしターゲット データのフィーチャ表現を位置合わせする、教師なしマルチソース ドメインフリー適応の手法です。その目標は、ジョイント表現空間内の複数のソース モデルによって引き起こされるフィーチャの不整列バイアスを軽減することであり、ジョイント表現空間内のラベル付きソース データとラベルなしターゲット データの間でフィーチャの整列を強制することが含まれます。
ジョイント敵対的フィーチャ アライメントは、ジョイント フィーチャ アライメントの特定の方法であり、各ソース モデルのフィーチャを組み合わせることによってジョイント フィーチャ表現が構築されます。別個のニューラル ネットワークは、ラベル付きソース データとラベルなしターゲット データの結合特徴を区別する結合弁別器としてトレーニングされます。複数の特徴抽出器が一緒に更新されて単一の識別器を欺き、それによって特徴の整合が達成されます。
実験結果

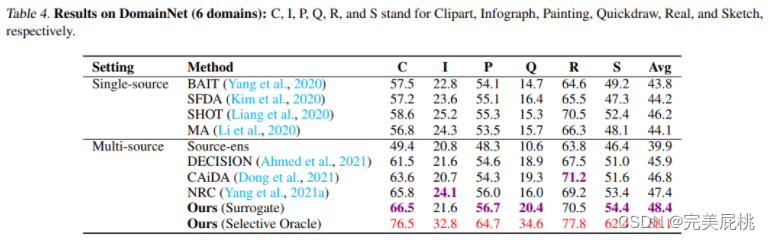
この研究では、Digits-Five、Office-31、Office-Home、および DomainNet という 4 つのベンチマーク データセットを使用して、提案された手法のパフォーマンスを評価します。Digits-Five には、MNIST、SVHN、USPS、MNIST-M、および合成数字を含む 5 つの異なるドメイン名が含まれており、Office-31 には、Amazon、Web カメラ、デジタル一眼レフ カメラを含む 3 つの異なるオフィス環境から収集された 31 のカテゴリが含まれています。Office-Home は、アート、クリップアート、現実世界、製品など、4 つの異なるオフィス環境から収集された 65 のカテゴリを含む、より挑戦的なデータセットです。DomainNet は、最大かつ最も困難なドメイン名適応ベンチマークであり、6 つの異なるドメインから収集された約 600,000 枚の画像が含まれており、クリップ アート、インフォグラフ、絵画、クイックドロー、リアル、スケッチを含む 345 のカテゴリに分類されています。
提案された方法の経験的なパフォーマンスを実証するために、この研究では、提案された方法を、DECISION、CaidA、NRC などの最近提案された最先端 (SOTA) マルチソース ドメイン適応方法と比較します。この調査には、事前トレーニングされたソース モデル (Source-ens と表記) を使用してターゲット ドメインのアンサンブル予測精度を評価するベースラインも含まれています。さらに、この研究では、提案された方法のパフォーマンスを、BAIT、SFDA、SHOT、MAなどのいくつかのSOTAパッシブドメイン適応方法と比較しています。これらの単一ソース手法はソース データへのアクセスも必要とせず、この研究では、適応後に複数の再トレーニングされたソース モデルからの予測の平均を取ることで、マルチソース アンサンブルの結果を比較しています。
ミックスアップ データ拡張は、トレーニング データの多様性を高め、モデルの汎化パフォーマンスを向上させるために使用される手法です。これは、深層学習モデルのトレーニング、特に画像分類や深層学習タスクで一般的に使用されるデータ拡張戦略です。ミックスアップの主なアイデアは、2 つ以上のトレーニング サンプルの特徴とラベルを線形に混合して新しいサンプルを生成し、それによってトレーニング データ セットを拡張することです。
Mixup データ拡張から得られる重要なポイントは次のとおりです。
-
混合サンプル生成: トレーニング サンプルのペアごとに、Mixup はまず 2 つのサンプル (または複数のサンプル) をランダムに選択し、次にそれらの特徴とラベルをランダムな重み係数で線形に混合します。通常、この重み係数は [0, 1] の範囲内で均一にランダムにサンプリングされます。
-
特徴混合: 2 つのサンプル A と B の場合、特徴混合は次の方法で実行されます。
pythonCopy code Mixed_Feature = lambda * Feature_A + (1 - lambda) * Feature_B
ここで、Mixed_Featureは生成された混合特徴、Feature_AはFeature_B2 つのサンプルの特徴、 はlambdaランダムな重み係数です。
-
ラベル混合: Mixup ではラベルも混合します。これは分類タスクでよく使用されます。分類タスクの場合、ラベル ブレンディングは次の方法で実行されます。
pythonCopy code Mixed_Label = lambda * Label_A + (1 - lambda) * Label_B
ここで、Mixed_Labelは生成されたハイブリッド ラベル、Label_AはLabel_B2 つのサンプルのラベルです。
-
損失関数: トレーニング中に、混合サンプルの特徴が順伝播に使用され、混合ラベルを使用して損失が計算されます。通常、モデルの予測と混合ラベル間の差異を測定するには、クロスエントロピー損失またはその他の適切な損失関数が使用されます。
-
利点: ミックスアップ データの強化により、モデルの過学習のリスクが軽減され、モデルの汎化パフォーマンスが向上し、トレーニング データの多様性が増し、入力に対するモデルの堅牢性も向上します。ミックスアップ データ拡張は、ディープ ラーニング タスク、特に画像分類の分野で広く使用されており、特に小規模なデータ セットでのモデルのパフォーマンスの向上に役立つ、シンプルで効果的な正則化手法です。
5.総合学習
アンサンブル学習は、複数のモデルからの予測を組み合わせることで汎化パフォーマンスを向上させる手法です。その中心的な考え方は、複数のモデルの意見を組み合わせることで単一モデルの不確実性と偏りを軽減し、それによってより強力な汎化パフォーマンスを得るというものです。
-
分散の削減: アンサンブル学習では、複数のモデルを組み合わせることでモデルの分散を削減できます。単一のモデルがトレーニング データに過剰適合して高い分散が生じる可能性がありますが、複数の異なるモデルを統合することにより、過適合の傾向が異なる可能性があるため、全体の分散を減らすことができます。これにより、アンサンブル モデルが新しいデータに対してより適切に一般化されます。
-
バイアスを減らす: アンサンブル学習は、モデル内のバイアスを減らすのにも役立ちます。単一のモデルは単純すぎるため、データ内の複雑な関係を捉えることができず、大きなバイアスが生じる可能性があります。複数のモデルの予測を組み合わせることで、単一モデルの欠点を補い、全体的な偏りを減らすことができます。
-
過学習のリスクを軽減する: アンサンブル モデルは複数のモデルで構成されているため、個別のモデルよりも過学習の傾向が低くなります。一部のデータでモデルのパフォーマンスが低い場合、他のモデルのほうがより良い予測を提供できるため、過剰適合のリスクが軽減されます。
-
多様性の向上: アンサンブル学習の有効性は、モデル間の多様性にあります。アンサンブルのモデル間に十分な差別化がある場合、1 つのモデルが間違いを犯した場合、他のモデルがそれを修正する可能性があります。この多様性は、アンサンブル モデルの汎化パフォーマンスの向上に役立ちます。
-
投票または平均のメカニズム: アンサンブル学習では、複数のモデルの予測を組み合わせるために、投票または平均のメカニズムがよく使用されます。これは、各モデルが最終的な予測に重みを与えることを意味します。この方法により、各モデルの意見を効果的に集約し、全体の予測パフォーマンスを向上させることができます。★
-
さまざまなアルゴリズムの組み合わせ: アンサンブル学習では、デシジョン ツリー、サポート ベクター マシン、ニューラル ネットワークなど、さまざまなアルゴリズムのモデルを組み合わせることもできます。このような組み合わせにより、さまざまなアルゴリズムの利点を最大限に活用できるため、汎化パフォーマンスが向上します。
6. モデル蒸留
モデル蒸留は、モデルの汎化パフォーマンスを向上させるために使用されるテクノロジーです。その主なアイデアは、大規模で複雑なモデルの知識を小規模で単純化されたモデルに転送し、それによってモデルのパフォーマンスの移行と向上を実現することです。
-
モデルの複雑さを軽減する: 通常、大規模なディープ ニューラル ネットワークは複雑さとパラメーターの数が高く、トレーニング データに過剰適合する傾向があります。小規模なモデル (スチューデント モデルと呼ばれる) は比較的単純で、パラメータが少なく、新しい未知のデータに簡単に一般化できます。モデルの蒸留を通じて、大規模なモデルの複雑さを小規模なモデルに移すことができ、小規模なモデルがデータ内のパターンをより適切に捕捉できるようになります。
-
モデル知識の伝達: モデルの蒸留では、大きなモデル (教師モデルと呼ばれる) の予測と確率分布を使用して、小さなモデルをガイドします。教師モデルは大規模データでトレーニングされているため、より多くの知識と一般化機能を備えています。小規模モデルは、教師モデルの予測を学習することでこの知識を得ることができ、それにより汎化パフォーマンスが向上します。
-
ソフト ラベル: モデルの蒸留では、教師モデルの出力は通常「ソフト ラベル」とみなされます。これらのソフト ラベルは、ハード カテゴリ ラベルではなく確率分布です。教師モデルのソフトラベルを比較することで、学生モデルはデータの分布と不確実性をよりよく学習できるため、汎化パフォーマンスが向上します。
-
温度パラメータ: 通常、モデル蒸留には温度パラメータがあり、ソフト ラベルの分布の「滑らかさ」を制御するために使用されます。温度パラメーターを適切に調整すると、生徒モデルが教師モデルの知識をよりよく学習できるようになり、汎化パフォーマンスが向上します。
-
正則化効果: モデルの蒸留には正則化効果もあり、スチューデント モデルの過剰適合のリスクを軽減できます。教師モデルと比較すると、生徒モデルは特定のカテゴリを過信して予測するよりも、確率の高いカテゴリを学習することを好みます。
7. 大型モデル時代の科学研究のための 4 つのアイデア
-
Efficient(PEFT): トレーニング効率を向上させます。ここでは PEFT (パラメータ効率的な微調整) を例として取り上げます。
-
既存のもの (事前学習済みモデル)、新しい方向性: 他の人の事前学習済みモデルの使用、新しい研究方向
-
プラグ アンド プレイ: モデル モジュール、目的関数、新しい損失関数、データ拡張メソッドなどのいくつかのプラグ アンド プレイ モジュールを作成します。
-
データセット、評価、調査: データセットを構築し、分析に焦点を当てた記事やレビュー論文を出版します。
8. リソースの構成
オープンソースのドメイン一般化ライブラリ
-
https://github.com/jindongwang/transferlearning/tree/master/code/DeepDG

-
https://github.com/junkunyuan/Awesome-Domain-Generalization
