過去10年間で、機械学習に対する人々の関心は爆発的に高まりました。機械学習は、コンピュータープログラム、業界の会議、メディアでほぼ毎日見られます。機械学習に関する多くの議論は、「機械学習で何ができるか」と「人間が機械学習で何をしたいのか」を混同しています。基本的に、機械学習とは、アルゴリズムを使用して生データから情報を抽出し、特定のタイプのモデルを使用してそれを表現し、モデルを使用して、モデルによって表現されていない他のデータを推測することです。
神经网络就是机器学习各类模型中的其中一类,并且已经存在了至少50年。神经网络的基本单位是节点,它的想法大致来源于哺乳动物大脑中的生物神经元。生物大脑中的神经元节点之间的链接是随着时间推移不断演化的,而神经网络中的神经元节点链接也借鉴了这一点,会不断演化(通过“训练”的方式)。
神经网络中很多重要框架的建立和改进都完成于二十世纪八十年代中期和九十年代初期。然而,要想获得较好结果需要大量的时间和数据,由于当时计算机的能力有限,神经网络的发展受到了一定的阻碍,人们的关注度也随之下降。二十一世纪初期,计算机的运算能力呈指数级增长,业界也见证了计算机技术发展的“寒武纪爆炸”——这在之前都是无法想象的。深度学习以一个竞争者的姿态出现,在计算能力爆炸式增长的十年里脱颖而出,并且赢得了许多重要的机器学习竞赛。其热度在2017年仍然不减。如今,在机器学习的出现的地方我们都能看到深度学习的身影。
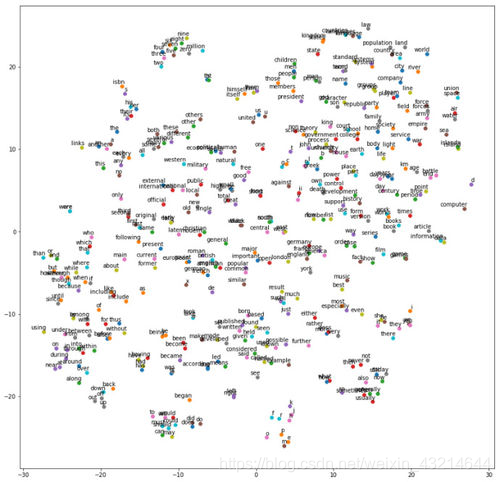
这是柳猫自己做的一个小例子,词向量的 t-SNE 投影,通过相似性进行聚类。
https://img4.mukewang.com/5c06355e0001943706900664.jpg
最近,我开始阅读关于深度学习的学术论文。根据我的个人研究,以下文章对这个领域的发展产生了巨大的影响:
1998年、NYUの記事「ドキュメント認識に適用される勾配ベースの学習」では、機械学習における畳み込みニューラルネットワークのアプリケーションが紹介されました。
トロントの2009年の記事「DeepBoltzmannMachines」(Deep Boltzmann Machines)は、多くの隠れ層を含むボルツマンマシンの新しい学習アルゴリズムを提案しました。
スタンフォード大学とGoogleが2012年に共同で発行した記事「大規模な教師なし学習を使用した高レベルの特徴の構築」は、ラベルのないデータのみを使用して高度な特定のクラスの特徴検出器を構築するという問題を解決します。
Berkeleyの2013年の記事「一般的な視覚認識のための深い畳み込み活性化機能」(DeCAF-一般的な視覚認識のための深い畳み込み活性化機能)は、DeCAFと呼ばれるアルゴリズムをリリースしました。これは、関連するネットワークパラメータ、ビジョンを使用した深い畳み込み活性化機能の実現のオープンソースです。研究者は、一連の視覚的概念学習パラダイムを使用して、詳細な実験を行うことができます。
DeepMindの2016年の記事「深層強化学習でAtariをプレイする」は、強化学習を通じて高次元の感覚入力から直接制御戦略を正常に学習できる最初の深層学習モデルを提案しました。
柳猫整理了人工智能工程师 10 个用于解决机器学习问题的强大的深度学习方法。但是,我们首先需要定义什么是深度学习。
如何定义深度学习是很多人面临的一个挑战,因为它的形式在过去的十年中已经慢慢地发生了改变。下图直观地展示了人工智能,机器学习和深度学习之间的关系。
https://img3.mukewang.com/5c0635b3000135f406900699.jpg
人工智能领域广泛,存在时间较长。深度学习是机器学习领域的一个子集,而机器学习是人工智能领域的一个子集。一般将深度学习网络与“典型”前馈多层网络从如下方面进行区分:
深層学習ネットワークには、フィードフォワードネットワークよりも多くのニューロンがあります
ディープラーニングネットワークがレイヤーを接続する方法はより複雑です
深層学習ネットワークには、トレーニングのための「カンブリア紀の爆発」のようなコンピューティング機能が必要です。
ディープラーニングネットワークは自動的に特徴を抽出できます
上文提到的“更多的神经元”是指近年来神经元的数量不断增加,就可以用更复杂的模型来表示。层也从多层网络中每一层完全连接,发展到卷积神经网络中神经元片段的局部连接,以及与递归神经网络中的同一神经元的循环连接(与前一层的连接除外)。
因此,深度学习可以被定义为以下四个基本网络框架中具有大量参数和层数的神经网络:
教師なし事前トレーニング済みネットワーク
畳み込みニューラルネットワーク
リカレントニューラルネットワーク
リカレントニューラルネットワーク
在这篇文章中,我主要讨论三个框架:
畳み込みニューラルネットワーク(畳み込みニューラルネットワーク)は、基本的に、共有ウェイトを使用して空間を拡張する標準的なニューラルネットワークです。畳み込みニューラルネットワークは主に内部畳み込みを通じて画像を認識し、内部畳み込みは画像上の認識されたオブジェクトのエッジを見ることができます。
リカレントニューラルネットワーク(リカレントニューラルネットワーク)は、基本的に時間とともに拡張する標準的なニューラルネットワークであり、次のレイヤーに同時に入るのではなく、次のタイムステップに入るエッジを抽出します。リカレントニューラルネットワークは、主に音声信号やテキストなどのシーケンスを認識するために使用されます。内部循環とは、ネットワークに短期記憶があることを意味します。
再帰型ニューラルネットワークは、入力シーケンスにリアルタイムプレーンがない階層型ネットワークに似ていますが、ツリーのように階層的に処理する必要があります。これらのフレームワークには、次の10の方法を適用できます。
1.
バックプロパゲーションバックプロパゲーションは、関数の組み合わせ(ニューラルネットワークなど)の形式で、関数の偏導関数(または勾配)を計算する簡単な方法です。勾配ベースの方法を使用して最適化問題を解決する場合(勾配降下法はそのうちの1つにすぎません)、関数勾配は各反復で計算する必要があります。

对于一个神经网络,其目标函数是组合形式。那么应该如何计算梯度呢?有2种常规方法:
(1)差分分析法。関数形式がわかっている場合、導関数の計算には連鎖律(基本計算)のみを使用する必要があります。
(2)差分法による近似微分。関数評価の大きさの順序はO(N)であるため、この方法は計算量が多くなります。ここで、Nはパラメーターの数です。差分分析法と比較すると、この方法は計算量が多くなりますが、デバッグ時には、通常、バックプロパゲーションの効果を検証するために有限差分が使用されます。
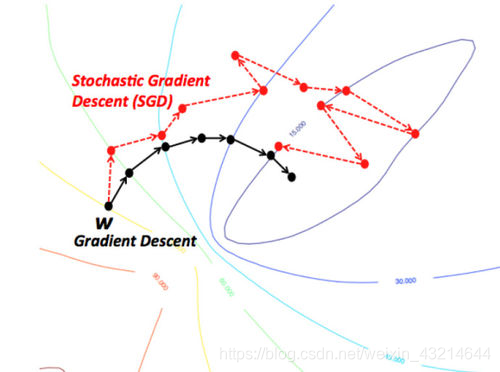
2.確率的勾配降下法勾配降下法
の直感的な理解は、山の頂上から始まる川を想像することです。この川は山の方向に丘陵地帯の最下点まで流れており、これが最急降下法の目標です。
我们所期望的最理想的情况就是河流在到达最终目的地(最低点)之前不会停下。在机器学习中,这等价于我们已经找到了从初始点(山顶)开始行走的全局最小值(或最优值)。然而,可能由于地形原因,河流的路径中会出现很多坑洼,而这会使得河流停滞不前。在机器学习术语中,这种坑洼称为局部最优解,而这不是我们想要的结果。有很多方法可以解决局部最优问题。
https://img2.mukewang.com/5c06362a00014d8706900512.jpg
因此,由于地形(即函数性质)的限制,梯度下降算法很容易卡在局部最小值。但是,如果能够找到一个特殊的山地形状(比如碗状,术语称作凸函数),那么算法总是能够找到最优点。在进行最优化时,遇到这些特殊的地形(凸函数)自然是最好的。另外,山顶初始位置(即函数的初始值)不同,最终到达山底的路径也完全不同。同样,不同的流速(即梯度下降算法的学习速率或步长)也会导致到达目的地的方式有差异。是否会陷入或避开一个坑洼(局部最小值),都会受到这两个因素的影响。
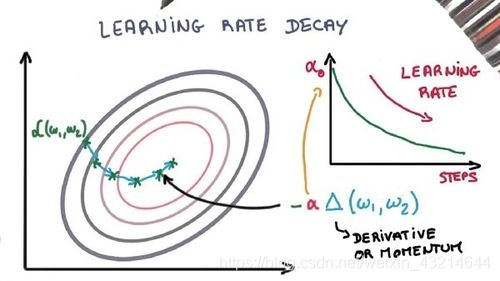
3.学習率の減衰
確率的勾配降下最適化アルゴリズムの学習率を調整すると、パフォーマンスが向上し、トレーニング時間が短縮されます。これは、学習率アニーリングまたは適応学習率と呼ばれます。トレーニングで最も単純で最も一般的に使用される学習率適応方法は、学習率を徐々に下げることです。トレーニングの初期段階でより大きな学習率を使用すると、学習率を大幅に調整できます。トレーニングの後期段階では、学習率を下げ、より小さな率で重みを更新します。この方法は、早い段階でより良い重みを取得することをすばやく学習し、後の段階で重みを微調整することができます。
https://img1.mukewang.com/5c0636580001f7f106000337.jpg
两个流行而简单的学习率衰减方法如下:
学習率を直線的に徐々に減らします
特定の時点での学習率を大幅に低下させます
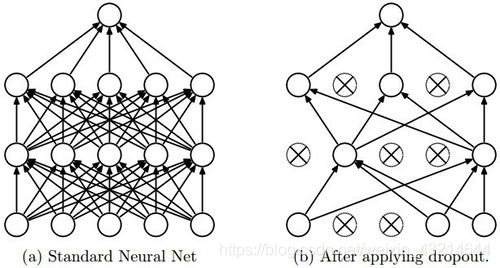
4.
多数のパラメーターを持つDropoutのディープニューラルネットワークは、非常に強力な機械学習システムです。ただし、このようなネットワークでは、過剰適合は非常に深刻な問題です。さらに、大規模ネットワークの実行速度は非常に遅いため、テスト段階で複数の異なる大規模ニューラルネットワークの予測を組み合わせて過剰適合の問題を解決することは非常に困難です。ドロップアウトメソッドはこの問題を解決できます。
https://img3.mukewang.com/5c0636700001b21806140328.jpg
其主要思想是,在训练过程中随机地从神经网络中删除单元(以及相应的连接),这样可以防止单元间的过度适应。训练过程中,在指数级不同“稀疏度”的网络中剔除样本。在测试阶段,很容易通过使用具有较小权重的单解开网络(single untwined network),将这些稀疏网络的预测结果求平均来进行近似。这能有效地避免过拟合,并且相对于其他正则化方法能得到更大的性能提升。Dropout 技术已经被证明在计算机视觉、语音识别、文本分类和计算生物学等领域的有监督学习任务中能提升神经网络的性能,并在多个基准数据集中达到最优秀的效果。
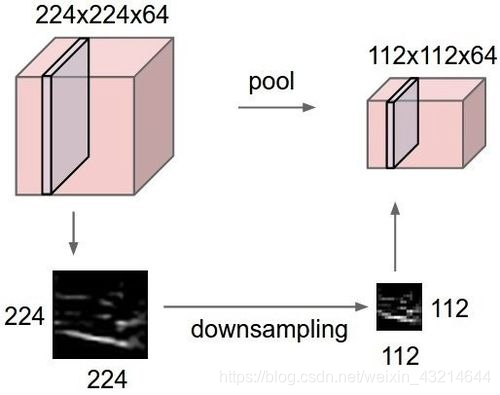
5.最大プール
最大プールは、サンプルに基づく離散化手法です。目標は、入力表現(画像、隠れ層の出力行列など)をダウンサンプリングし、次元を減らし、サブ領域の特徴に関する仮定を可能にすることです。
https://img2.mukewang.com/5c0636870001512e05140406.jpg
通过提供表征的抽象形式,这种方法可以在某种程度上解决过拟合问题。同样,它也通过减少学习参数的数目以及提供基本的内部表征转换不变性来减少计算量。最大池是通过将最大过滤器应用于通常不重叠的初始表征子区域来完成的。
6.バッチ標準化
もちろん、ディープネットワークを含むニューラルネットワークは、重みと学習パラメーターの初期値を注意深く調整する必要があります。バッチ標準化により、このプロセスが容易になります。
权重问题:
ランダム選択や経験的選択など、重みの初期値をどのように設定しても、初期重みと学習後の重みは大きく異なります。重みの小さなバッチを検討してください。最初は、必要な機能のアクティブ化に多くの外れ値が存在する可能性があります。
ディープニューラルネットワーク自体は病的です。つまり、最初の層の小さな変化が後の層の大きな変化につながります。
在反向传播过程中,这些现象会导致梯度的偏移,这就意味着在学习权重以产生所需要的输出之前,梯度必须补偿异常值。而这将导致需要额外的时间才能收敛。
https://img1.mukewang.com/5c06371e0001d81f06900497.jpg
批量标准化将这些梯度从异常值调整为正常值,并在小批量范围内(通过标准化)使其向共同的目标收敛。
学习率问题:
一般的に言えば、学習率は比較的小さいため、異常な活性化の勾配はすでに学習された重みに影響を与えないため、勾配のごく一部のみが重みの修正に使用されます。
バッチ標準化により、これらの異常なアクティブ化の可能性が減少し、より大きな学習率を使用して学習プロセスを加速できます。電動フォークリフトタイヤ
7.長期および短期記憶
長期および短期記憶ネットワーク(LSTM)と他のリカレントニューラルネットワークのニューロンには、次の3つの違いがあります。
いつニューロンに入力を許可するかを決定できます
前のタイムステップで計算されたものをいつ記憶するかを決定できます
出力を次のタイムスタンプに渡すタイミングを決定できます。LSTMの利点は、現在の入力のみに基づいて上記のすべてを決定できることです。以下のチャートをご覧ください。
https://img3.mukewang.com/5c0637380001003806900394.jpg
当前时间戳的输入信号 x(t) 决定了上述三点。
入力ゲートが最初のポイントを決定します。
忘却ゲートは2番目のポイントを決定します。
出力ゲートが3番目のポイントを決定します。これらの3つの決定は、入力によってのみ行うことができます。これは、入力に基づいて突然のコンテキスト切り替えを処理できる脳の動作メカニズムに触発されています。
8.スキップグラム
単語埋め込みモデルの目的は、各単語の高次元の密な表現を学習することです。埋め込みベクトル間の類似性は、対応する単語間の意味的または構文的な類似性を示します。スキップグラムは、単語埋め込みアルゴリズムを学習するためのモデルです。スキップグラムモデル(他の多くの単語埋め込みモデルを含む)の背後にある主な考え方は、2つの語彙アイテムが類似したコンテキストを持っている場合、それらは類似しているということです。
https://img3.mukewang.com/5c0638020001fcc905950404.jpg
换句话说,假设有一个句子,比如“cats are mammals”,如果用“dogs”替换“cats”,该句子仍然是有意义的。因此在这个例子中,“dogs”和“cats”有相似的上下文(即“are mammals”)。
基于以上假设,我们可以考虑一个上下文窗口(包含 K 个连续项)。然后跳过其中一个词,试着学习一个可以得到除了跳过的这个词以外所有词项,并且可以预测跳过的词的神经网络。因此,如果两个词在一个大语料库中多次具有相似的上下文,那么这些词的嵌入向量将会是相似的。
9.連続的な単語の袋モデル
自然言語処理では、ドキュメント内の各単語を数値ベクトルとして表現し、類似したコンテキストで表示される単語が類似または類似のベクトル表現を持つようにします。連続単語バッグモデルでは、特定の単語のコンテキストを使用して単語を予測することが目標です。
https://img2.mukewang.com/5c06377e000156f406000337.jpg
首先在一个大的语料库中抽取大量的句子,每看到一个单词,同时抽取它的上下文。然后我们将上下文单词输入到一个神经网络,并预测在这个上下文中心的单词。
当我们有成千上万个这样的上下文词汇和中心词时,我们就得到了一个神经网络数据集的实例。然后训练这个神经网络,在经过编码的隐藏层的最终输出中,我们得到了特定单词的嵌入式表达。当我们对大量的句子进行训练时也能发现,类似上下文中的单词都可以得到相似的向量。
10.転移学習
畳み込みニューラルネットワークが画像を処理する方法を考えてみましょう。画像があり、それに畳み込みを適用し、出力としてピクセルの組み合わせを取得するとします。これらの出力がエッジであり、畳み込みが再度適用されると仮定すると、出力はエッジまたはラインの組み合わせになります。その後、畳み込みが再度適用され、このときの出力は線の組み合わせなどになります。各レベルで特定のパターンを探すことと考えてください。ニューラルネットワークの最後の層は通常、非常に特殊になります。
如果基于 ImageNet 进行训练,那么神经网络的最后一层或许就是在寻找儿童、狗或者飞机之类的完整图像。再往后倒退几层,可能会看到神经网络在寻找眼睛、耳朵、嘴巴或者轮子等组成部分。
https://img1.mukewang.com/5c0637ac0001ca1306380359.jpg

深度卷积神经网络中的每一层逐步建立起越来越高层次的特征表征,最后几层通常是专门针对输入数据。另一方面,前面的层则更为通用,主要用来在一大类图片中有找到许多简单的模式。
迁移学习就是在一个数据集上训练卷积神经网络时,去掉最后一层,在不同的数据集上重新训练模型的最后一层。直观来讲,就是重新训练模型以识别不同的高级特征。因此,训练时间会减少很多,所以在没有足够的数据或者需要太多的资源时,迁移学习是一个很有用的工具。