元のリンク:http://www.notescloud.top/cloudSearch/detail?id = 2356
一般的な深層学習アルゴリズムの概要
おすすめの本
ディープラーニングアルゴリズムpractice.pdf:http:
//www.notescloud.top/cloudSearch/detail?id = 2355
多くの人は、深層学習は機械学習よりも進んでいると誤解しています。実際、ディープラーニングは機械学習の一分野です。多層構造のモデルとして理解できます。具体的には、深層学習は、機械学習の深い構造を持つニューラルネットワークアルゴリズムです。つまり、機械学習>ニューラルネットワークアルゴリズム>ディープニューラルネットワーク(ディープラーニング)です。
ディープラーニングの理論的導出は大きすぎて複雑です。いくつかの一般的なディープラーニングアルゴリズムもあいまいです。何度も読んだ後、間隔を置いて忘れてしまいます。次に、システムを整理します(履歴、致命的な問題から)。特定のアルゴリズムのアイデア、フレームワーク、長所と短所、および改善の方向性、およびCNNとRNNの比較の要約)。
1.歴史:多層パーセプトロンからニューラルネットワークおよびディープラーニング
ニューラルネットワーク技術は、1950年代と1960年代にパーセプトロンと呼ばれ、入力層、出力層、および隠れ層を備えていました。入力特徴ベクトルは、隠れ層変換を介して出力層に到達し、分類結果が出力層で取得されます。(無関係なこと:コンピューティング技術の後退により、パーセプトロンの伝達関数は、レオスタットを引いて抵抗をワイヤーで変更することによって機械的に実現されました。密なワイヤーを引っ張っている科学者の外観を補います...)
心理学者Rosenblattが提案した単層パーセプトロンには、深刻すぎて深刻ではないという問題があります。つまり、少し複雑な機能(最も一般的な「排他的OR」操作など)では何もできません。
この欠点は、1980年代まで、Rumelhart、Williams、Hinton、LeCunなどによって発明された多層パーセプトロンによって解決されませんでした。多層パーセプトロンは、XORロジックをシミュレートできないという以前の欠点を解決し、同時に、より多くのレイヤーも許可されますネットワークは、現実世界の複雑な状況をより適切に表現できます。
多層パーセプトロンは、初期の離散伝達関数の束縛を取り除き、シグモイドやタンなどの連続関数を使用して、励起に対するニューロンの応答をシミュレートし、トレーニングアルゴリズムでワーボスによって発明されたバックプロパゲーションBPアルゴリズムを使用できます。これが現在[ニューラルネットワーク]について話していることです。BPアルゴリズムはBPニューラルネットワークとも呼ばれます。特定のプロセスは、私の再版記事(http://blog.csdn.net/abc200941410128/article/details/78708319)にあります。)。
しかし、BPニューラルネットワーク(多層パーセプトロン)は致命的な問題に直面しています(次のセクションを参照)。ニューラルネットワーク層の数が増えるにつれて、2つの大きな問題があります。1つは、最適化関数がローカル最適解に分類される可能性が高くなることと、この「トラップ」が真のグローバル最適からますます遠ざかることです。限られたデータでトレーニングされた深いネットワークのパフォーマンスは、浅いネットワークほど良くありません。同時に、無視できないもう1つの問題は、「勾配消失」の現象がより深刻であるということです。
2006年、ヒントンは事前トレーニング法を使用して局所最適解問題を軽減し、隠れ層を7層にプッシュしました。ニューラルネットワークは本当の意味で「深さ」を持っているため、深層学習の熱狂が明らかになりました。次にDBN、 CNN、RNN、LSTMなどが徐々に登場しました。
ここでは「深さ」の固定定義はありません。4層ネットワークは音声認識では「より深い」と見なすことができ、20層を超えるネットワークは画像認識では珍しいことではありません。
勾配の消失を克服するために、ReLUやmaxoutなどの伝達関数がシグモイドに置き換わり、今日のDNNの基本形を形成しています。構造だけでは、完全にリンクされた多層パーセプトロンに違いはありません。
第二に、ディープニューラルネットワークの致命的な問題
ニューラルネットワーク層の数が増えるにつれて、3つの主要な問題があります。1つは非凸最適化問題です。つまり、最適化関数は局所最適解に分類される可能性が高くなります。2つ目は勾配消失です( Gradient Vanish)問題; 3番目は過剰適合問題です。
2.1非凸最適化の問題
線形回帰は本質的に多変量線形関数最適化問題です。f(x、y)= x + y
多層ニューラルネットワークとします。本質は多変量K
次関数最適化問題です。f(x、y)= xy in線形回帰では、検索の任意のポイントから開始して、最終的にグローバル最小値近くまで下がる必要があります。したがって、0に設定しても問題はありません(これが、初期値が0の線形回帰方程式を解くことが多い理由です)。
多層ニューラルネットワークでは、さまざまなポイントから開始して、極小値でスタックする可能性があります。極小値は、ニューラルネットワーク構造によってもたらされる長引く影です。隠れ層の数が増えると、非凸目的関数はますます複雑になり、極小点は、限られたデータでトレーニングされた深層を使用して増加します。ネットワークのパフォーマンスは、浅いネットワークほど良くありません。。回避する方法は、通常、重みの初期化です。初期化スキームを統一するために、入力は通常[-1,1]にスケーリングされますが、グローバル最適化が達成できるという保証はありません。実際、これは科学者が研究している未解決の問題でもあります。
したがって、本質的に、深層構造によってもたらされる非凸最適化はまだ解決できず(現在のさまざまな深層学習アルゴリズムやその他の非凸最適化問題を含む)、深層構造の開発が制限されます。
2.2(勾配消失)勾配消失の問題
この問題は、実際には不適切な活性化関数によって引き起こされます。複数のレイヤーでシグモイド関数を使用すると、エラーが出力レイヤーから指数関数的に減衰します。数学では、活性化関数の機能は、入力データを0から1にマップすることです(tanhは-1から+1にマップします)。マッピングの理由としては、データを正規化することに加えて、特定の範囲内に収まるようにデータを制御することが考えられます。もちろん、他にも詳細があります。たとえば、シグモイド(tanh)をアクティブにすると、ゼロ(または中心点)の前後のデータの小さな変化に、の変化を無視して、より注意を払うことができます。極端なデータ。たとえば、ReLUは勾配の消失を回避することもできます。の役割。一般に、Sigmoid(tanh)は主に完全に接続された層で使用され、ReLUは主に畳み込み層で使用されます。
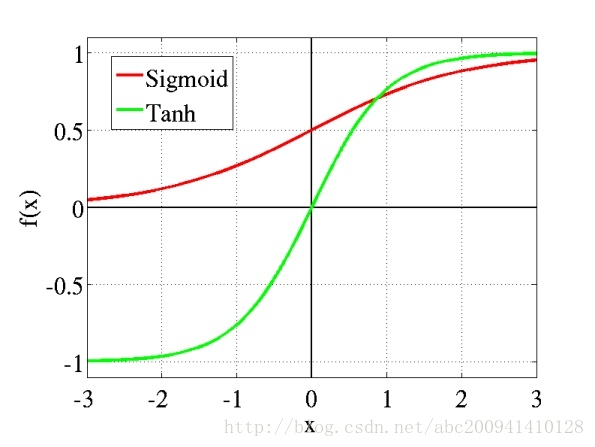
シグモイド
ReLUの
「勾配消失」現象、具体的には、ニューロンの入出力関数としてシグモイドを使用することがよくあります。振幅が1の信号の場合、BPが勾配を伝搬して戻すと、通過する各層の勾配は0.25に減衰します。層の数が多い場合、勾配が指数関数的に減衰した後、下の層は基本的に効果的なトレーニング信号を受信できません。
幸い、この問題は、2006年にHintonによって提案されたレイヤーごとの貪欲なトレーニング前の重み行列の変更によって軽減され、ReLuは最近基本的な解決策を提案しました。
2012年、HintonグループのAlex Krizhevskyは、CNNで新しく提案されたReLu関数を最初に使用しました。これは、勾配消失の影響をあまり受けません。
2014年、Googleの研究者であるJia Yangqingは、ReLuをアーティファクトとして使用して、CNNを22層の巨大なディープネットワークに拡張することに成功しました。
Gradient Vanishに悩まされているRNNの場合、そのバリアントLSTMもこの問題を克服します。
2.3過剰適合の問題
これはニューラルネットワークの最後の致命的な問題です。過剰適合、巨大な構造とパラメーターにより、トレーニングエラーは非常に低くなりますが、テストエラーは途方もなく高くなります。
過剰適合は、勾配消失および極小値と混合することもできます。具体的なゲームプレイは次のとおりです。
勾配消失のため、深度構造の下層はトレーニングがほとんど不可能ですが、上層はトレーニングが非常に簡単です。
下層はトレーニングできないため、非線形変換や誤った変換を行わずに元の入力情報を上層に簡単にプッシュできます。これにより、高層の解離フィーチャの圧力が高くなりすぎます。
特徴を分離できない場合、必須のエラー監視トレーニングにより、モデルが入力データに直接適合します。
その結果、最適化は良好ですが、一般化は不十分です。これは、SVMやデシジョンツリーなどの浅い構造の障害でもあります。
ベンジオは、最適化にローカルデータを使用するこれらの浅い構造は、事前の知識に基づいていると指摘しました(事前):滑らかさ
、つまり、サンプル(xi、yi)が与えられた場合、可能な限り数値的に最適化するため、トレーニングされたモデルは近似x、出力近似y。
ただし、入力値が2つの異なる鳥などの一般的な移行を経ると、鳥の色が異なり、画像内の比率が異なるため、SVMと決定木はほとんど役に立ちません。
高次元データ(画像、音声、テキストなど)が、特徴を分離するのではなく、入力データに対して単に数値学習を行うことは無意味だからです。
それが最後でした。低レベルの生徒は動かず、高レベルの生徒はランダムに学習していたため、すぐに魅力の盆地に落ち、ニューラルネットワークのトリプルキルを完了しました。
3、ディープラーニングの基本モデル
深層学習の基本モデルは、多層パーセプトロンモデル、深層ニューラルネットワークモデル、リカレントニューラルネットワークモデルの3つのカテゴリに大別されます。その代表的なものは、DBN(ディープビリーフネットワーク)ディープビリーフネットワーク、CNN(畳み込みニューラルネットワーク)畳み込みニューラルネットワーク、RNN(リカレントニューラルネットワーク)リカレントニューラルネットワークです。
3.1 DBN(ディープビリーフネットワーク)ディープビリーフネットワーク
2006年、Geoffrey Hintonは、Deep Belief Network(DBN)とその効率的な学習アルゴリズムであるPre-training + Fine Tuningを提案し、その後の深層学習アルゴリズムのメインフレームワークとなった「Science」で公開しました。DBNは生成モデルであり、ニューロン間の重みをトレーニングすることで、ニューラルネットワーク全体に最大確率に従ってトレーニングデータを生成させることができます。したがって、DBNを使用して機能を識別し、データを分類するだけでなく、DBNを使用してデータを生成することもできます。
3.1.1ネットワーク構造
Deep Belief Network(DBN)は、制限付きボルツマンマシン(RBM)の複数の層を積み重ねることによって形成され、上部RBMの非表示層は次のRBMの可視層として機能します。
(1)RBM
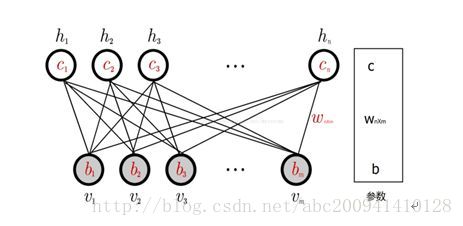
一般的なRBMネットワーク構造を上図に示します。これは、m個の可視層ユニットとn個の隠れ層ユニットからなる2層モデルであり、その中で、層内のニューロンは接続されておらず、ニューロンは接続されていません。つまり、可視層の状態が与えられると、隠れ層の活性化状態は独立し、逆に、隠れ層の状態が与えられると、可視層は独立しています。これにより、層内のニューロン間の条件付き独立性が保証され、確率分布の計算とトレーニングの複雑さが軽減されます。RBMは、無向グラフモデルと見なすことができます。可視層ニューロンと隠れ層ニューロンの間の接続の重みは双方向です。つまり、可視層から隠れ層への接続の重みはWであり、隠れ層から隠れ層への接続の重みは可視層はW 'です。上記のパラメータに加えて、RBMのパラメータには可視層バイアスbと隠れ層バイアスcも含まれます。RBM可視層と非表示層ユニットによって定義される分布は、バイナリユニット、ガウスユニット、正規化線形ユニットなど、実際のニーズに応じて置き換えることができます。これらの異なるユニットの主な違いは、アクティブ化機能が異なることです
(2) DBN
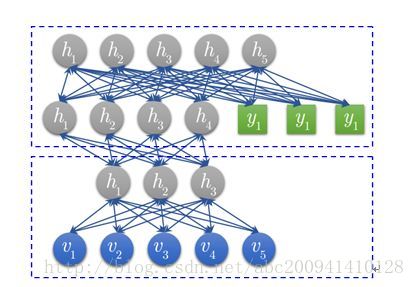
DBNモデルは、RBMがスタックされた複数のレイヤーで構成されます。トレーニングセットにラベルデータがある場合、RBMの最後のレイヤーの表示レイヤーには、RBMの前のレイヤーの非表示レイヤーユニットとラベルレイヤーユニットの両方が含まれます。最上位RBMの可視層に500個のニューロンがあり、トレーニングデータが10個のカテゴリに分類されるとすると、最上位RBMの可視層には510個の優勢ニューロンがあります。各トレーニングデータに対して、対応するラベルニューロンが開かれます。1などオフになり、0に設定されます
3.1.2トレーニングプロセスと長所と短所
DBNトレーニングには、事前トレーニングと微調整の2つのステップが含まれます。事前トレーニングプロセスは、各RBMをレイヤーごとにトレーニングするのと同じです。事前トレーニング後のDBNを使用して、トレーニングデータをシミュレートできます。の識別パフォーマンスをさらに向上させるためにネットワーク、微調整調整プロセスでは、ラベルデータを使用して、BPアルゴリズムを介してネットワークパラメータを微調整します。
DBNの長所と短所の要約は、主に生成モデルと判別モデルの長所と短所の要約に焦点を当てています。
1.利点:
- 生成モデルは同時確率密度分布を学習するため、統計的な観点からデータの分布を表すことができ、類似データ自体の類似性を反映できます。
- 生成モデルは、識別モデルと同等の条件付き確率分布を復元でき、識別モデルは同時分布を取得できないため、生成モデルとして使用できません。
2.デメリット:
- 生成モデルは、異なるカテゴリ間の最適な分類面がどこにあるかを気にしないため、分類問題で使用する場合、分類精度は識別モデルほど高くない可能性があります。
- 生成モデルはデータの同時分布を学習するため、学習問題の複雑さはある程度高くなります。
- 入力データには、並進不変性が必要です。
判別モデルと生成モデルについては、(http://blog.csdn.net/erlib/article/details/53585134)を参照してください。
3.1.3改良されたモデル
DBNには多くのバリエーションがあり、その改善は主に、畳み込みDBN(CDBN)や条件付きRBM(条件付きRBM)などの構成要素である「パーツ」RBMの改善に焦点を当てています。
入力は単に画像マトリックスを1次元ベクトルに変換するためのものであるため、DBNは画像の2次元構造情報を考慮しません。CDBNは、隣接するピクセルの空間的関係を使用して、畳み込みRBM(CRBM)と呼ばれるモデルを通じて生成されたモデルの変換不変性を実現し、高次元画像に簡単に変換できます。
DBNは、観測変数の時間接続の学習を明示的に処理しません。条件付きRBMは、シーケンスデータをシミュレートするための追加の条件付き入力として、前の瞬間の可視レイヤー単位変数を考慮します。このバリアントは、音声信号処理の分野でより広く使用されています。 。多く。
3.2 CNN(畳み込みニューラルネットワーク)畳み込みニューラルネットワーク
畳み込みニューラルネットワークは一種の人工ニューラルネットワークであり、音声分析と画像認識の分野で研究のホットスポットになっています。その重み共有ネットワーク構造により、生物学的神経ネットワークにより類似したものになり、ネットワークモデルの複雑さが軽減され、重みの数が削減されます。この利点は、ネットワークの入力が多次元画像である場合により明白であるため、画像をネットワークの入力として直接使用でき、従来の認識アルゴリズムでの複雑な特徴抽出およびデータ再構成プロセスを回避できます。
完全にリンクされたDNNの構造では、下位層のニューロンとすべての上位層のニューロンが接続を形成できます。これにより、パラメーターの数が増加します。たとえば、1000 * 1000ピクセルの画像の場合、このレイヤーだけで10 ^ 12の重みをトレーニングする必要があります。現時点では、畳み込みニューラルネットワークCNNを使用できます。CNNの場合、上層と下層のすべてのニューロンを直接接続できるわけではなく、「畳み込みカーネル」を介して仲介します。同じ畳み込みカーネルがすべての画像で共有され、畳み込み操作後も画像は元の位置関係を保持します。画像入力層から隠れ層へのパラメータは、即座に100 * 100 * 100 = 10 ^ 6に減少します。
畳み込みネットワークは、2次元形状を認識するように特別に設計された多層パーセプトロンです。このネットワーク構造は、変換とスケーリング:変形、傾斜、またはその他のフォームは非常に不変です。
3.2.1ネットワーク構造
畳み込みニューラルネットワークは多層ニューラルネットワークであり、その基本的な操作単位には、畳み込み操作、プール操作、完全接続操作、および認識操作が含まれます。
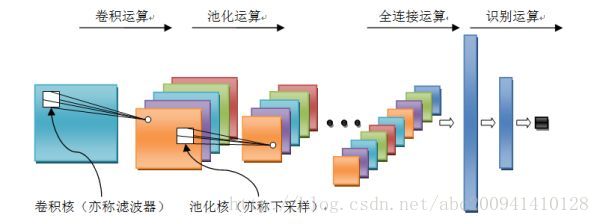
- 畳み込み演算:前の層の特徴マップは、学習可能な畳み込みカーネルで畳み込まれます。活性化関数後の畳み込み結果の出力は、この層のニューロンを形成し、この層の特徴マップを形成します。これは、特徴抽出とも呼ばれます。層では、各ニューロンの入力が前の層の局所受容フィールドに接続され、局所特徴が抽出されます。局所特徴が抽出されると、それと他の特徴との間の位置関係が決定されます。l
- プーリング操作:特徴を集約し、次元を減らして計算量を減らすことができます。入力信号を重複しないエリアに分割し、エリアごとにプーリング(ダウンサンプリング)することでネットワークの空間分解能を低下させます。たとえば、最大プーリングは選択したエリアの最大値であり、平均プーリングは計算エリアです。内の平均値。この操作により、信号のオフセットと歪みが排除されます。
- 完全に接続された操作:入力信号が複数の畳み込みカーネルプーリング操作を受けた後、出力は複数の信号セットになります。完全に接続された操作の後、複数の信号セットが順次結合されて信号セットになります。
認識計算:上記の計算プロセスは特徴学習計算であり、計算に基づくビジネス要件(分類または回帰問題)に基づく分類または回帰計算のためにネットワークの層を追加する必要があります。
3.2.2トレーニングプロセスと長所と短所
畳み込みネットワークは、本質的に一種の入出力マッピングです。既知のモデルが畳み込みネットワークをトレーニングしている限り、入力と出力の間の正確な数式を必要とせずに、入力と出力の間の多数のマッピング関係を学習できます。ネットワークには、入力ペアと出力ペアの間でマッピングする機能があります。畳み込みネットワークは教師ありトレーニングを実行するため、そのサンプルセットは(入力信号、ラベル値)の形式のベクトルペアで構成されます。
1.利点:
- 重み共有戦略により、トレーニングが必要なパラメーターが削減されます。同じ重みにより、フィルターは信号の位置に影響されることなく信号の特性を検出できるため、トレーニングされたモデルの一般化が強化されます。
- プーリング操作は、ネットワークの空間分解能を低下させる可能性があり、それによって信号の小さなオフセットと歪みが排除されるため、入力データの並進不変性は高くなりません。
2.デメリット:
- 深いモデルは、勾配散逸の問題を起こしやすいです。
3.2.3改良されたモデル
畳み込みニューラルネットワークは、さまざまな分野で優れた結果を達成しているため、近年最も広く研究され、適用されているディープニューラルネットワークです。より有名な畳み込みニューラルネットワークモデルには、主に1986年のLenet、2012年のAlexnet、2014年のGoogleNet、2014年のVGG、2015年のDeep ResidualLearningが含まれます。これらの畳み込みニューラルネットワークの改良版では、モデルの深さやモデルの組織構造に一定の違いがありますが、モデルの構造は同じで、基本的に畳み込み操作、プーリング操作、完全接続操作、認識操作が含まれます。 。
3.3 RNN(リカレントニューラルネットワーク)リカレントニューラルネットワーク
上記の問題に加えて、完全に接続されたDNNには、時系列の変化をモデル化できないという別の問題があります。ただし、サンプルが表示される時系列は、自然言語処理、音声認識、手書き認識などのアプリケーションにとって非常に重要です。ちなみに、この需要に適応するために、サブジェクトサイクリックニューラルネットワークRNNによって言及された別のニューラルネットワーク構造があります(なぜ多くがサイクルと呼ばれるのかわかりません。コンピューター用語では、サイクルは一般的に同じレベルです。リカレントは実際には時間の再帰であるため、この記事では彼をリカレントニューラルネットワークと呼びます)。
通常の完全に接続されたネットワークまたはCNNでは、ニューロンの各層の信号は上位層にのみ伝播でき、サンプルの処理は常に独立しているため、フィードフォワードニューラルネットワークと呼ばれます。RNNでは、ニューロンの出力は、次のタイムスタンプで直接影響を与える可能性があります。
つまり、時間(t + 1)でのネットワークの最終結果O(t + 1)は、その時点での入力とすべての履歴の結果です。RNNは、時間内に送信されるニューラルネットワークと見なすことができ、その深さは時間の長さです。前述したように、「勾配消失」の現象が再び現れようとしていますが、今回は時間
の勾配消失を解決するために時間軸上で発生し、機械学習分野は長短を展開しました。タームメモリユニット(LSTM)、ドアを通してスイッチは時間内にメモリ機能を実現し、勾配が消えるのを防ぎます。
3.3.1ネットワーク構造
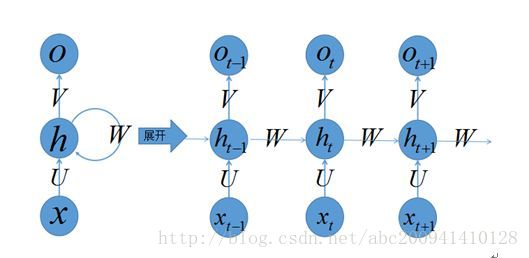
左側はリカレントニューラルネットワークの元の構造です。真ん中の威圧的な閉ループを最初に破棄すると、実際には「入力層=>隠れ層=>出力層」の単純な3層構造になりますが、は、図のもう1つの見慣れないものです。閉ループは、隠れ層への入力後、隠れ層もそれ自体に入力されることを意味します。これにより、ネットワークはメモリ機能を持つことができます。リカレントニューラルネットワークには記憶能力があると言いますが、この能力は、Wを介して前の入力状態を要約し、次の入力の補助として使用することです。非表示の状態は次のように理解できます。h= f(既存の入力+過去のメモリの概要)
3.3.2トレーニングプロセスと長所と短所
リカレントニューラルネットワークでは、前の信号が入力に重ね合わされるため、逆伝導は従来のニューラルネットワークとは異なります。これは、時間tの入力層の場合、残差が出力だけでなく、その後、隠れ層。逆転送アルゴリズムにより、出力層の誤差を使用して各重みの勾配を解決し、次に勾配降下法を使用して各重みを更新します。
1.利点:
- モデルは時間次元の深いモデルであり、シーケンスの内容をモデル化できます。
2.デメリット:
- トレーニングが必要なパラメータは多数あり、勾配散逸または勾配爆発の問題が発生する傾向があります。
- 特徴学習能力はありません。
3.3.3改良されたモデル
リカレントニューラルネットワークモデルを使用してシーケンスデータを処理できます。リカレントニューラルネットワークには多数のパラメーターが含まれており、トレーニングが困難です(時間次元での勾配散逸または勾配爆発)。したがって、次のような一連のRNN最適化が登場しました。ネットワーク構造、ソリューションアルゴリズム、並列化。
近年、双方向RNN(BRNN)とLSTMは、画像のキャプション、言語の翻訳、手書き認識において画期的な進歩を遂げました。
3.4ハイブリッド構造
上記の3つのネットワーク、および前述の深層残余学習とLSTMに加えて、深層学習には他にも多くの構造があります。たとえば、RNNは履歴情報を継承できるので、将来の情報も吸収できますか?シーケンス信号解析では、将来を予測できれば、識別に役立つはずです。したがって、双方向RNNと双方向LSTMがあり、これらは過去と将来の情報を同時に利用します。双方向RNN、双方向LSTMは、履歴情報と将来の情報を同時に使用します。
実際、実際のアプリケーションでは、ネットワークの種類に関係なく、混合されることがよくあります。たとえば、CNNとRNNは、上位層の出力の前に完全に接続された層に接続されることがよくあります。特定のネットワークがどのカテゴリに属するかを判断するのは困難です。 。
ディープラーニングへの熱意が続くにつれて、より柔軟な組み合わせとより多くのネットワーク構造が開発されることを想像するのは難しいことではありません。常に変化しているように見えますが、研究者の出発点は間違いなく特定の問題を解決することです。この分野で研究を行いたい場合は、これらの構造のそれぞれの特性と、それらが目標を達成するための手段を注意深く分析することをお勧めします。
3.5CNNとRNNの比較
RNNの重要な機能は、可変長の入力を処理して特定の出力を取得できることです。入力が長くても短くてもかまいません。たとえば、翻訳モデルをトレーニングする場合、文の長さは固定されていません。CNNを使用して、トレーニング用の固定ピクセル画像のように入力することはできません。また、RNNのサイクル特性を利用して簡単に行うことができます。
シーケンス信号のアプリケーションでは、CNNは事前設定された信号長(入力ベクトルの長さ)にのみ応答し、RNNの応答長が学習されます。
特徴に対するCNNの応答は線形であり、RNNはこの漸進的な方向で非線形です。これも大きな違いになります。
CNNは画像の問題の解決を専門としており、特徴抽出レイヤーとして使用し、入力レイヤーに配置して、最後にMLPを使用して分類することができます。
RNNは時系列問題の解決を専門としており、時系列情報を抽出するために使用され、特徴抽出レイヤー(CNNなど)の後に配置されます。
RNN、再帰型ネットワーク、シーケンスデータに使用され、lstmによって補完される特定のメモリ効果があります。
CNNは空間マッピングに焦点を当てる必要があり、画像データはこのシーンに特に適しています。
CNN畳み込みは、ローカル特徴からグローバル特徴を近似するのが得意であり、
RNNは時系列を処理するのが得意です。
4、いくつかの基本的な概念と知識
4.1線形回帰、線形ニューラルネットワーク、ロジスティック/ソフトマックス回帰
このリファレンスhttp://blog.csdn.net/erlib/article/details/53585134
またはその他の情報。
4.2畳み込み、プーリング、活性化関数などについて
入門リファレンス:http://blog.csdn.net/u010859498/article/details/78794405 GoogleBaiduの
詳細
4.3優れた入門資料を推奨する
国立台湾大学電気工学科のLiHongyi教授は、配布資料「Understanding Deep Learning inOneDay」の
簡単な翻訳を行いました
https://www.jianshu.com/p/c30f7c944b66
参考資料:
http://blog.csdn.net/erlib/article/details/53585134
https://www.zhihu.com/question/34681168/answer/156552873
http://blog.csdn.net/u010859498/article / details / 78794405