目次
2. シングルポイント アーキテクチャと比較したマスター/スレーブ アーキテクチャの利点
3. マスター/スレーブ レプリケーションの原理とワークフロー
フェーズ 2: マスター サーバーがデータをスレーブ サーバーに同期します。
フェーズ 3: マスター サーバーが新しい書き込み操作コマンドをスレーブ サーバーに送信します。
マスター サーバーはどの増分データをスレーブ サーバーに送信するかをどのようにして知るのでしょうか?
3. Sentinel はノードに本当に障害があるかどうかをどのように判断しますか?
4.マスター/スレーブフェイルオーバーを実行するのはどのセンチネルですか?
検査の最初のラウンド: 最も高い優先順位を持つスレーブ ノードが勝ちます。
2 回目の検査: レプリケーションの進行状況が最も高いスレーブ ノードが勝ちます。
3 回目の検査: ID 番号が小さいスレーブ ノードが勝ちます。
ステップ 2: スレーブ ノードが新しいマスター ノードを指すようにする
ステップ 3: マスター ノードが交換されたことを顧客に通知する
ステップ 4: 古いマスター ノードをスレーブ ノードに変更する
7. Sentinel クラスターはどのようにしてスレーブ ノードの情報を知るのですか?
4. Redis クラスターの最大スロット数が 16384 であるのはなぜですか?
8. Redis Cluser はどのようにして高可用性を確保しますか?
ステップ 2: オフライン マスター ノードのスロットを新しいノードに割り当てる
ステップ 3: マスターノードが交換されたことをクラスターに通知します。
ステップ 4: 古いマスター ノードをスレーブ ノードに変更する
1. マスター/スレーブ レプリケーション
1。概要
マスター/スレーブ レプリケーションとは、1 つの Redis サーバーから他の Redis サーバーにデータをコピーすることを指します。前者をマスターノード、後者をスレーブノードと呼びます。
- データのレプリケーションは一方向であり、マスター ノードからスレーブ ノードへのみです。
- デフォルトでは、各 Redis サーバーはマスター ノードであり、マスター ノードは複数のスレーブ ノードを持つことができます (またはスレーブ ノードを持たないこともできます)。スレーブ ノードはスレーブ ノードを持つこともできますが、スレーブ ノードが持つことができるマスター ノードは 1 つだけです。
- マスター ノードは書き込みと読み取りが可能で、主に書き込み操作を担当しますが、スレーブ ノードは読み取り操作のみを実行できます。
- ホストがシャットダウンされた後も、スレーブ データは通常どおり使用できます。つまり、ホストが再起動して復帰するのを待ちながら、引き続き読み取ることができます。
2. シングルポイント アーキテクチャと比較したマスター/スレーブ アーキテクチャの利点
- データの冗長性と高可用性: Redis サーバーの単一点障害を回避するために、複数のサーバーが用意され、相互に接続されます。データの複数のコピーをコピーして異なるサーバーに保存し、それらを接続してデータが同期されていることを確認します。サーバーの 1 つがダウンしても、他のサーバーは引き続きサービスを提供できます。
-
ロードバランシングにより読み取りパフォーマンスが向上します。マスター/スレーブレプリケーションに基づいて、読み取りと書き込みの分離と組み合わせることで、マスターノードは書き込みサービスを提供し、スレーブノードは読み取りサービスを提供できます(つまり、Redisデータを書き込むとき、アプリケーションはマスターに接続します)ノードを使用し、Redis データを読み取る場合、アプリケーションはスレーブ ノードを接続してサーバー負荷を共有します。特に、書き込みが少なく読み取りが多いシナリオでは、複数のスレーブ ノードを通じて読み取り負荷を共有すると、Redis サーバーの同時実行性が大幅に向上します。
3. マスター/スレーブ レプリケーションの原理とワークフロー
最初の同期
スレーブ サーバー salve が開始されると、マスター サーバーとの最初の同期が実行されます。マスターサーバーとスレーブサーバー間の最初の同期プロセスは、次の 3 つの段階に分けることができます。
- 最初の段階では、リンクを確立し、同期をネゴシエートします。
- 第 2 段階では、マスター サーバーがデータをスレーブ サーバーに同期します。
- 3 番目の段階では、マスター サーバーが新しい書き込み操作コマンドをスレーブ サーバーに送信します。
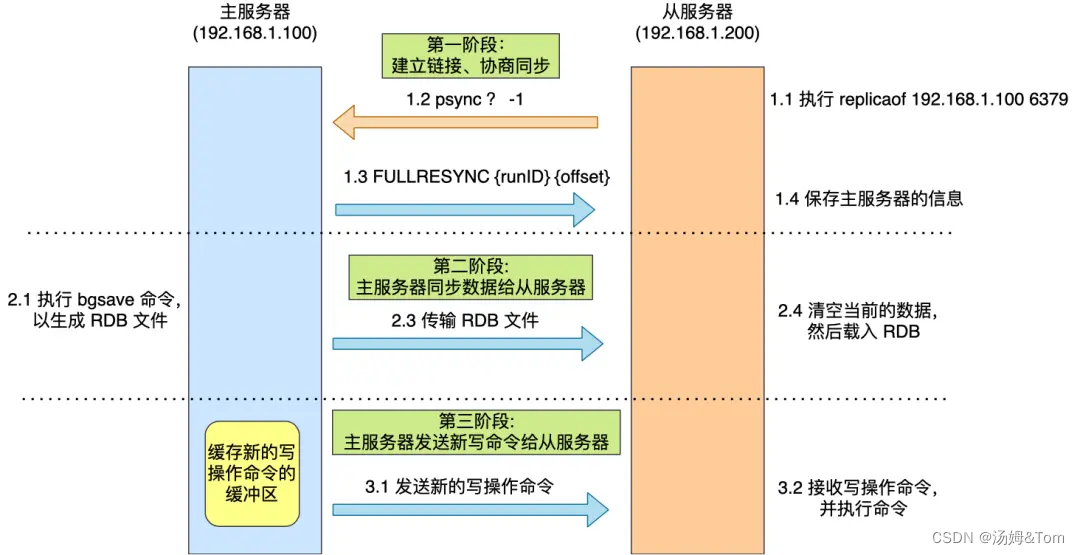
第 1 段階: リンクの確立と同期のネゴシエーション
- レプリカオブコマンドを実行した後、スレーブサーバーはマスターサーバーに psync コマンドを送信し、データ同期が必要であることを示します。psync コマンドには、マスター サーバーの runID とレプリケーション進行状況オフセットという 2 つのパラメータが含まれます。
- メインサーバーは psync コマンドを受信後、 応答コマンドとしてFULLRESYNC を使用して相手に戻ります。この応答コマンドは、メイン サーバーの runID とメイン サーバーの現在のレプリケーション進行状況オフセットという2 つのパラメータを取ります。サーバーから応答を受信すると、両方の値が記録されます。
FULLRESYNC 応答コマンドの目的は、完全レプリケーションを使用することです。つまり、マスター サーバーはすべてのデータをスレーブ サーバーに同期します。
フェーズ 2: マスター サーバーがデータをスレーブ サーバーに同期します。
- 次に、マスターサーバーは bgsave コマンドを実行して RDB ファイルを生成し、そのファイルをスレーブサーバーに送信します。
- サーバーから RDB ファイルを受信すると、現在のデータがクリアされてから、RDB ファイルがロードされます。
ここで注意すべき点の 1 つは、メイン サーバーによる RDB の生成プロセスはメイン スレッドをブロックしないことです。これは、bgsave コマンドが RDB ファイルを生成するためのサブプロセスを生成し、非同期で動作するため、Redis は引き続きコマンドを処理できるためです。通常は。
ただし、この間の書き込み操作コマンドは生成したばかりのRDBファイルには記録されず、マスタサーバとスレーブサーバの間でデータの不整合が発生します。マスター サーバーとスレーブ サーバーのデータの一貫性を確保するために、マスター サーバーは、受信した書き込み操作コマンドを次の 3 つの時間間隔でレプリケーション バッファーに書き込みます。
- メインサーバーによる RDB ファイルの生成中。
- マスターサーバーがスレーブサーバーにRDBファイルを送信している間。
- RDB ファイルを「サーバーから」ロードする際。
フェーズ 3: マスター サーバーが新しい書き込み操作コマンドをスレーブ サーバーに送信します。
- マスターサーバーが生成したRDBファイルが送信され、スレーブサーバーがRDBファイルを受信すると、古いデータはすべて破棄され、RDBデータがメモリにロードされます。RDB がロードされると、確認メッセージがメイン サーバーに返信されます。
- 次に、マスターサーバーはレプリケーションバッファー に記録された書き込み操作コマンドをスレーブサーバーに送信し、スレーブサーバーはマスターサーバーのレプリケーションバッファー から送信されたコマンドを実行します。このとき、マスターサーバーとスレーブサーバーのデータは一致します。
この時点で、マスター/スレーブ サーバーの最初の同期が完了します。
長い接続に基づくコマンドの伝播
マスター/スレーブ サーバーが最初の同期を完了した後、両者の間で TCP 接続が維持されます。この接続は長期接続であり、頻繁な TCP 接続と切断によって引き起こされるパフォーマンスのオーバーヘッドを回避することが目的です。
その後、マスター サーバーはこの接続を通じて書き込み操作コマンドをスレーブ サーバーに伝播し続けることができ、スレーブ サーバーがコマンドを実行してマスター サーバーのデータベース状態を同じにします。
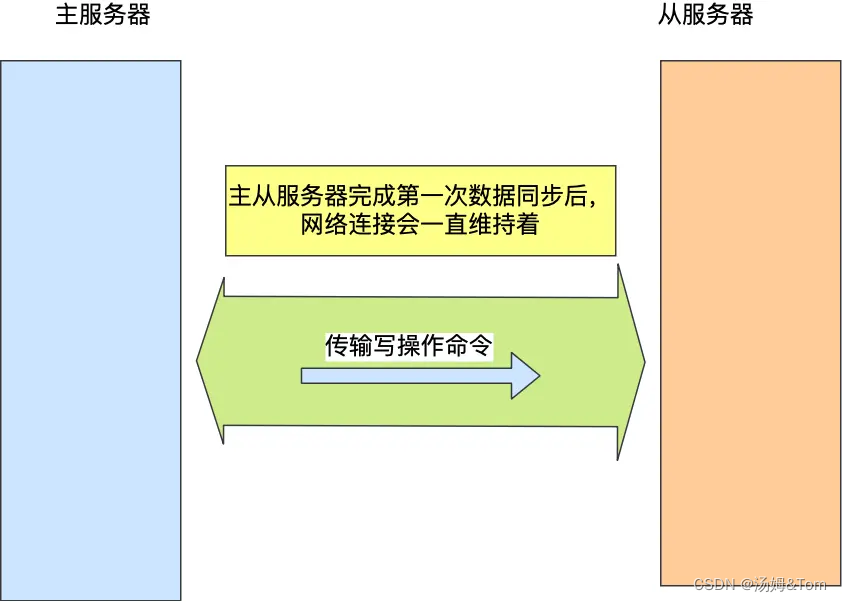
Redis は相互ピンポン精神検出メカニズムを使用して、ノードが適切に動作しているかどうかを判断します。ノードの半分以上がノードに ping を実行してもポン応答がなかった場合、クラスターはノードがダウンしていると判断し、ノードから切断します。接続する。
Redis マスター ノードとスレーブ ノードによって送信される間隔は異なり、それらの機能も若干異なります。
- デフォルトでは、Redis マスター ノードは 10 秒ごとにスレーブ ノードに ping コマンドを送信し、スレーブ ノードの生存と接続ステータスを確認します。送信頻度はパラメーター repl-ping-slave-period で制御できます。
- Redis スレーブ ノードは、次の目的で、replconf ack{offset} コマンドを 1 秒ごとに送信して、現在のレプリケーション オフセットをマスター ノードに報告します。
- マスター/スレーブノードのネットワークステータスをリアルタイムで監視します。
- 自身のレプリケーション オフセットを報告し、レプリケーション データが失われたかどうかを確認します。スレーブ ノードのデータが失われた場合、失われたデータはマスター ノードのレプリケーション バッファから取得されます。
メインサーバーにかかるプレッシャーを共有する
問題の導入
前の分析では、マスター サーバーとスレーブ サーバー間の最初のデータ同期プロセス中に、マスター サーバーが RDB ファイルの生成と RDB ファイルの転送という 2 つの時間のかかる操作を実行することがわかり ました。
マスター サーバーは複数のスレーブ サーバーを持つことができますが、非常に多くのスレーブ サーバーがあり、それらがすべてマスター サーバーと完全に同期している場合、次の 2 つの問題が発生します。
- bgsaveコマンドでRDBファイルを生成するため、メインサーバは子プロセスの作成にfork()を使用してビジー状態となり、メインサーバのメモリデータが大きくない場合、fork()関数実行時にメインスレッドがブロックされてしまいます。が実行されるため、Redis はリクエストを正常に処理できなくなります。
- RDB ファイルの送信はメイン サーバーのネットワーク帯域幅を占有し、コマンド リクエストに対するメイン サーバーの応答に影響を与えます。
この状況は、会社を立ち上げたばかりのようなもので、従業員の数が少ないため、上司一人で従業員の管理を行っていますが、会社が発展し従業員の数が増えると、上司は徐々に経営を引き受けることができなくなります。すべての従業員の。
「マネージャー」の役割を持つスレーブ
この問題を解決するには、上司が複数の一般社員を管理する管理職を設け、上司は管理者のみを管理すればよい。
Redis も同様で、スレーブ サーバーは独自のスレーブ サーバーを持つことができ、スレーブ サーバーを持つスレーブ サーバーをマネージャーの役割とみなすことができ、マスター サーバーの同期データを受信するだけでなく、データの同期も行うことができます。マスターサーバーとして同時にスレーブサーバーに送信しますが、それでも書き込み操作を実行できません。構成は次のとおりです。

このようにして、マスター サーバー上で RDB を生成および送信するプレッシャーを、マネージャーとして機能するスレーブ サーバーにオフロードできます。
増分コピー
問題の導入
マスター/スレーブ サーバーは最初の同期を完了すると、長い接続に基づいてコマンドを伝達します。マスターサーバーとスレーブサーバー間のネットワーク接続が切断されると、コマンドが伝播されなくなり、スレーブサーバー上のデータとマスターサーバーのデータの整合性が取れなくなり、クライアントが「スレーブサーバー」から古いデータを読み取る可能性があります。 。

- Redis 2.8 より前では、コマンド同期中にマスター サーバーとスレーブ サーバーの間でネットワークが切断され復元された場合、スレーブ サーバーはマスター サーバーとの完全なレプリケーションを再度実行していましたが、明らかにこのオーバーヘッドは大きすぎるため、改善が必要です。
- したがって、Redis 2.8 以降では、ネットワークが切断されて復元された後、スレーブ マスター サーバーとスレーブ サーバーは増分レプリケーションを使用して同期を継続します。つまり、ネットワーク切断中にマスター サーバーが受信した書き込み操作コマンドのみが同期されます。スレーブサーバー。
ネットワーク回復後の増分コピーのプロセスは次のとおりです。
 増分コピープロセス
増分コピープロセス
- スレーブ サーバーはネットワークを復元した後、マスター サーバーにpsync コマンドを送信しますが、このとき、psync コマンドの offset パラメーターは -1 ではありません。
- コマンドを受信した後、マスター サーバーはCONTINUE 応答コマンドを使用して、増分レプリケーションを使用してデータを同期するようにスレーブ サーバーに指示します。
- 次に、マスター サービスは、マスター サーバーとスレーブ サーバーの切断中に実行された書き込みコマンドをスレーブ サーバーに送信し、スレーブ サーバーがこれらのコマンドを実行します。
マスター サーバーはどの増分データをスレーブ サーバーに送信するかをどのようにして知るのでしょうか?
答えは次の 2 つのことにあります。
- repl_backlog_buffer:マスター/スレーブ サーバーが切断された後に差分データを検索するために使用される「リング」バッファーです。マスター サーバーがコマンドを伝播するとき、書き込みコマンドをスレーブ サーバーに送信するだけでなく、書き込みコマンドをスレーブ サーバーに書き込みます。スレーブサーバーは repl_backlog_buffer バッファーに保存されるため、このバッファーには最後に伝播された書き込みコマンドが保持されます。
- レプリケーション オフセット:上のバッファの同期の進行状況をマークします。マスター サーバーとスレーブ サーバーには独自のオフセットがあります。マスター サーバーは master_repl_offset を使用して「書き込み」位置を記録し、スレーブ サーバーは smile_repl_offset を使用して「読み取り」位置を記録します. .
ネットワークが切断された後、スレーブ サーバーがマスター サーバーに再接続すると、スレーブ サーバーは自身のレプリケーション オフセット、slave_repl_offset をpsync コマンドを通じてマスター サーバーに送信します。マスター サーバーは、自身のmaster_repl_offset とマスター サーバー間のギャップに基づいて決定します。 lave_repl_offset:スレーブ サーバーでどの同期操作が実行されるか:
- スレーブ サーバーから読み取られるデータがまだ repl_backlog_buffer バッファ内にあると判断された場合、マスター サーバーは増分同期を使用します。
- 逆に、スレーブ サーバーから読み取られるデータが repl_backlog_buffer バッファーに存在しないと判断された場合、マスター サーバーは完全同期を使用します。
マスター サーバーが repl_backlog_buffer でマスター サーバーとスレーブ サーバー間の差分 (増分) データを見つけると、増分データをレプリケーション バッファーに書き込みます。このバッファーについては前にも説明しました。スレーブに伝播されるキャッシュです。サーバーコマンド。
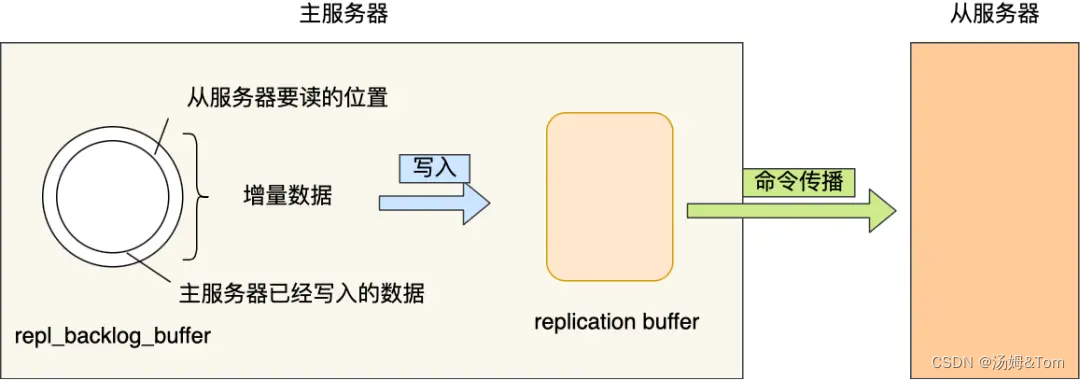
repl_backlog_buffer キャッシュ バッファのデフォルト サイズは 1M で、リング バッファであるため、バッファがいっぱいになったときにメイン サーバーが書き込みを続けると、以前のデータが上書きされます。そのため、マスターサーバーの書き込み速度がスレーブサーバーの読み込み速度を大きく上回ると、バッファ内のデータが一気に上書きされてしまいます。
したがって、ネットワークが復旧したときにメイン サーバーが完全同期を頻繁に使用することを避けるために、repl_backlog_buffer バッファ サイズをできるだけ大きく調整して、スレーブ サーバーから読み取られるデータが上書きされる可能性を減らす必要があります。そのため、メインサーバーは増分同期を使用します。
repl_backlog_buffer バッファを調整する
repl_backlog_buffer の最小サイズは、この式に従って推定できます。

- Second は、スレーブ サーバーが切断された後、マスター サーバーに再接続するのに必要な平均時間 (秒単位) です。
- write_size_per_second は、メイン サーバーによって生成される 1 秒あたりの書き込みコマンド データの平均量です。
たとえば、プライマリ サーバーが 1 秒あたり平均 1 MB の書き込みコマンドを生成し、セカンダリ サーバーが切断された後、プライマリ サーバーに再接続するのに平均 5 秒かかるとします。この場合、repl_backlog_buffer のサイズは 5 MB 未満にすることはできません。5 MB 未満にしないと、新しい書き込みコマンドが古いデータを上書きします。
もちろん、何らかの緊急事態に対処するために、repl_backlog_buffer のサイズをこの基準の 2 倍、つまり 10 MB に設定できます。
4. マスター/スレーブアーキテクチャの欠点
Redis のマスター/スレーブ アーキテクチャでは、マスター/スレーブ モードにより読み取りと書き込みが分離されるため、マスター ノード (マスター) がハングアップすると、クライアントの書き込み操作リクエストに対応するマスター ノードがなくなり、マスターが存在しなくなります。スレーブノード(slave)を提供するノードでデータの同期を行います。
 現時点でサービスを復元したい場合は、手動で介入し、「スレーブ ノード」を選択して「マスター ノード」に切り替え、他のスレーブ ノードが新しいマスター ノードを指すようにする必要があります。 Redis マスター ノードに接続されている上流クライアントにも通知する必要があり、構成内のマスター ノードの IP アドレスを「新しいマスター ノード」の IP アドレスに更新します。
現時点でサービスを復元したい場合は、手動で介入し、「スレーブ ノード」を選択して「マスター ノード」に切り替え、他のスレーブ ノードが新しいマスター ノードを指すようにする必要があります。 Redis マスター ノードに接続されている上流クライアントにも通知する必要があり、構成内のマスター ノードの IP アドレスを「新しいマスター ノード」の IP アドレスに更新します。
2. センチネルの仕組み
1.コンセプト
Redis のマスター/スレーブ アーキテクチャでは、マスター ノード (マスター) がハングアップした場合、手動による介入が必要になります。したがって、「マスターノード」の状態を監視し、マスターノードがダウンしていることが判明した場合、投票数に基づいて「スレーブノード」を「マスターノード」に自動的に切り替えることが、ノードとクライアントから新しいマスターノードの関連情報を通知する、これがセンチネルメカニズムです。
2. センチネルの役割
- マスター/スレーブ監視: マスター/スレーブ Redis ライブラリが正常に実行されているかどうかを監視します。
- フェイルオーバー: マスターが異常な場合、マスター/スレーブ切り替えが実行され、スレーブの 1 つが新しいマスターとして使用されます。
- メッセージ通知: Sentinel はフェイルオーバーの結果をクライアントに送信できます
- 構成センター: クライアントは Sentinel に接続することにより、現在の Redis サービスのマスター ノード アドレスを取得します。
注: Sentinel はクラスターの監視と保守のみを行い、データは保存しません。
3. Sentinel はノードに本当に障害があるかどうかをどのように判断しますか?
Sentinel は 1 秒ごとにすべてのマスターノードとスレーブノードに PING コマンドを送信し、マスターノードとスレーブノードは PING コマンドを受信すると応答コマンドを Sentinel に送信することで、正常に動作しているかどうかを判断できます。
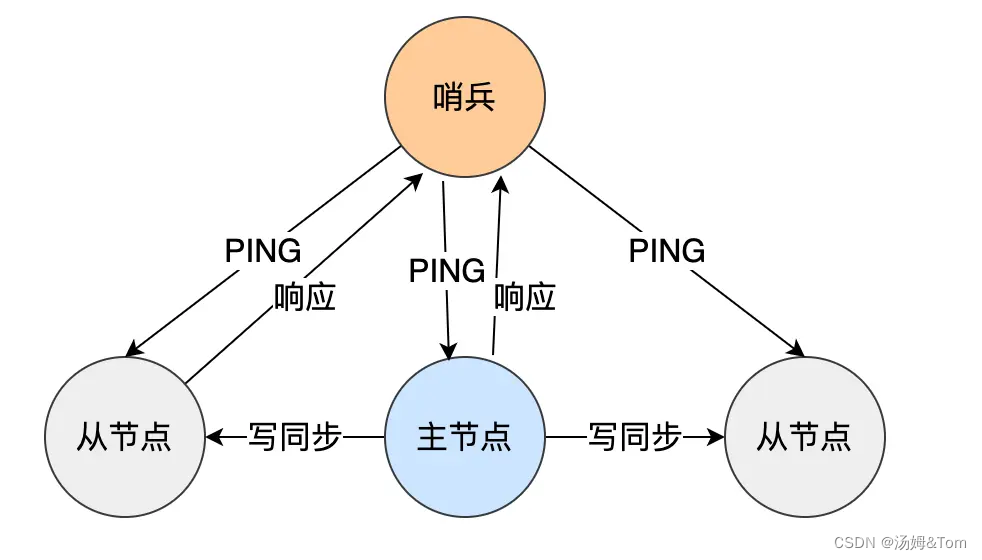
マスター ノードまたはスレーブ ノードが指定された時間内に Sentinel の PING コマンドに応答しない場合、Sentinel はそれらを「主観的にオフライン」としてマークします。この「所定の時間」は、設定項目のdown-after-millisecedsパラメータにより設定され、単位はミリ秒である。
主観的なオフライン
「主観的オフライン」は、単一のセンチネルに対して行われます。ネットワークの混雑などにより、誤判断が発生しやすくなります。そのため、誤判断を軽減するために、センチネルはデプロイ時に 1 つのノードのみをデプロイするのではなく、複数のノードを使用します。 (センチネル クラスターをデプロイするには少なくとも 3 台のマシンが必要です)複数のセンチネル ノードをまとめて判断することで、ネットワークの状態が悪いために単一のセンチネル ノードが誤ってマスター ノードがオフラインであると判断する状況を回避できます。同時に、複数の監視ネットワークが同時に不安定になる可能性は低く、一緒に判断すれば誤判断率も減らすことができます。
オフラインでの目標
主観があるところには客観があります。セントリーがマスターノードが「主観的にオフライン」であると判断すると、他のセントリーにコマンドを発行します。このコマンドを受信した他のセントリーは、マスターノードのネットワーク状況に基づいて合意を形成します。自分自身とマスター ノード投票または投票を拒否するための応答。

このセンチネルの承認投票数がセンチネル構成ファイルのクォーラム構成項目で設定された値に達すると、マスター ノードはセンチネルによって「客観的にオフライン」としてマークされます。
たとえば、現在 3 つのセンチネルがあり、クォーラム構成は 2 です。この場合、マスター ノードを「客観的にオフライン」としてマークするには、センチネルが 2 つの承認投票を必要とします。これら 2 つの賛成票には、歩哨自身の 1 票と他の 2 人の歩哨の賛成票が含まれます。
注: クォーラムの値は通常、センチネルの数の半分に 1 を加えた値に設定されます。たとえば、センチネルが 3 つある場合は、2 を設定します。また、センチネル ノードの数は奇数である必要があります。
Sentinel がマスター ノードが客観的にオフラインであると判断した後、Sentinel は複数の「スレーブ ノード」から新しいマスター ノードとなるスレーブ ノードの選択を開始します。
4.マスター/スレーブフェイルオーバーを実行するのはどのセンチネルですか?
センチネル メカニズムを使用する場合、センチネル クラスターをデプロイする必要があると前に述べましたが、マスターに障害が発生した場合、誰がマスター/スレーブ フェイルオーバーを実行するのでしょうか? 一緒に行きたいですか?明らかに違います。
マスター ノードが客観的にオフラインであると判断されると、各センチネル ノードはリーダー センチネル ノードを選出するためにネゴシエートし、リーダー ノードはフェイルオーバー (障害移行) を実行します。
候補者は誰ですか
どのセンチネル ノードがマスター ノードが「客観的にオフライン」であると判断するか、このセンチネル ノードが候補となり、いわゆる候補はリーダーになりたいセンチネルです。
たとえば、センチネルが 3 人いるとします。Sentinel B は、マスター ノードが「主観的にオフライン」であると最初に判断すると、is-master-down-by-addr コマンドを他のインスタンスに送信します。その後、他のセンチネルは、マスター ノードとのネットワーク接続に基づいて、投票に同意するか投票を拒否することで応答します。
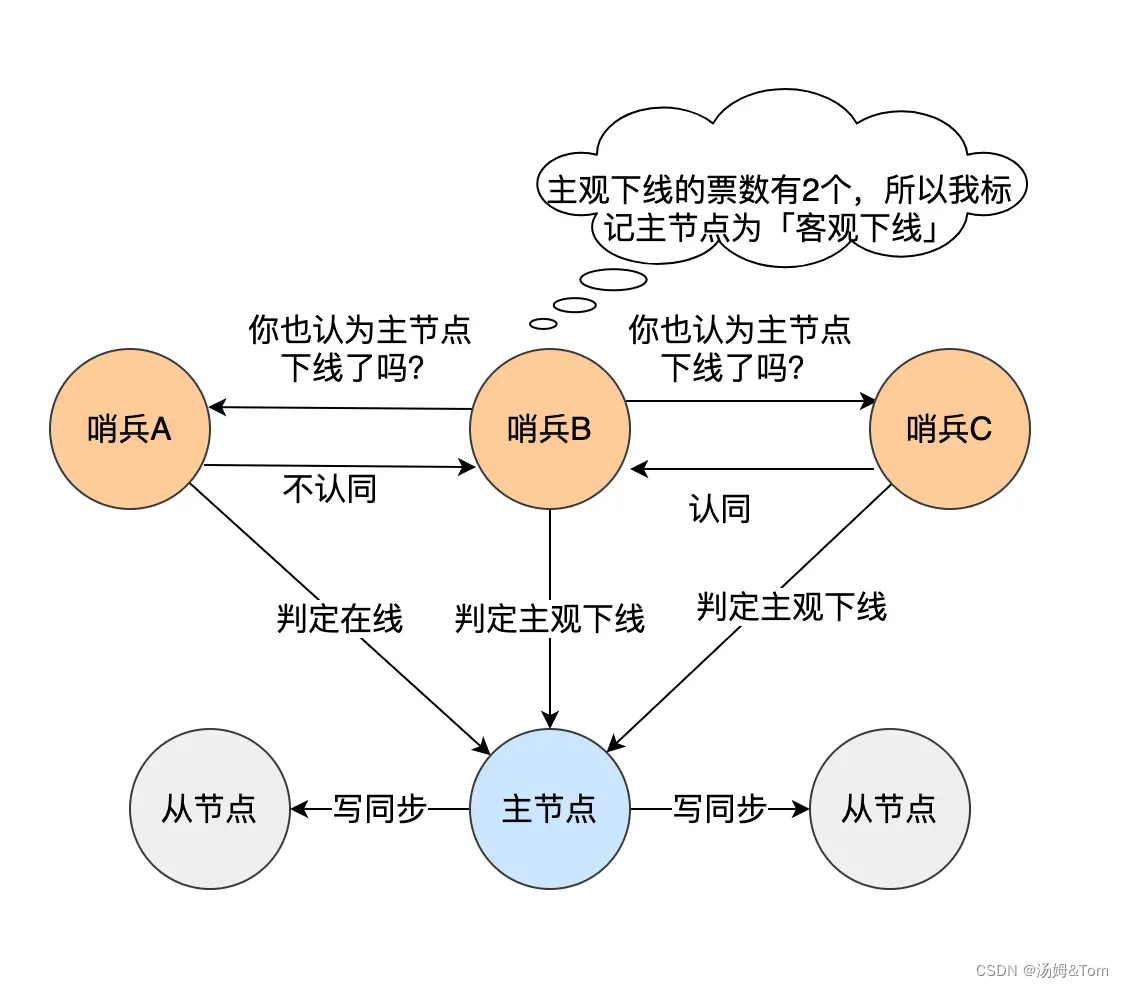
Sentinel B が受け取った承認投票数が Sentinel 設定ファイルのクォーラム設定項目で設定された値に達すると、マスター ノードは「客観的オフライン」としてマークされ、この時点で Sentinel B はリーダー候補となります。
リーダーの選び方
候補者は、マスター/スレーブ切り替えを実行するリーダーになりたいことを示すコマンドを他のセンチネルに送信し、他のすべてのセンチネルに投票させます。選挙で使用されるアルゴリズムは Raft アルゴリズムです。Raft アルゴリズムの基本的な考え方は早い者勝ちです。 つまり、選挙の 1 回のラウンドで、センチネル B がリーダーになるための申請書を A に送信します。は他のセンチネルに同意していませんが、B がリーダーになることに同意します。
各センチネルには投票の機会が 1 回だけあり、それが使い果たされると投票に参加できなくなります。自分自身または他の人に投票できますが、自分自身に投票できるのは候補者だけです。
投票プロセス中に、「候補者」がリーダーに選出されるには、次の 2 つの条件を満たす必要があります。
- まず、半数以上の賛成票を獲得します。
- 次に、受信した投票数は、Sentinel 構成ファイルのクォーラム値以上である必要があります。
たとえば、センチネル ノードが 3 つあり、クォーラムが 2 に設定されていると仮定すると、リーダーになりたいセンチネルは、2 票の賛成票を獲得している限り、正常に選出されます。条件が満たされない場合は、新たな選挙を実施する必要があります。
ある時点で、マスター ノードが客観的にオフラインであると判断したセンチネル ノードが 2 つだけ存在する場合、各候補者はまず自分自身に投票し、次に他のセンチネルへの投票要求を開始します。有権者は、「候補者A」から先に投票要求を受け取った場合には、先に投票しますが、投票機会を使い切って「候補者B」から投票要求を受け取った場合は、投票を拒否します。このとき、候補者Aが先に上記2つの条件を満たしているため、「候補者A」がリーダーに選出されます。
5. マスター/スレーブフェイルオーバープロセス
Sentinel クラスターでの投票によって Sentinel リーダーが選出された後、次の図に示すように、マスター/スレーブ フェイルオーバー プロセスを実行できます。

マスター/スレーブフェイルオーバー操作は、次の 4 つのステップで構成されます。
- ステップ 1: オフラインのマスターノード (旧マスターノード) 配下のすべての「スレーブノード」からスレーブノードを選択し、マスターノードに変換します。
- ステップ 2: オフラインのマスター ノードの下にあるすべての「スレーブ ノード」がレプリケーション ターゲットを変更して、「新しいマスター ノード」をコピーします。
- ステップ 3: 「パブリッシャー/サブスクライバー メカニズム」を通じて、新しいマスター ノードの IP アドレスと情報をクライアントに通知します。
- ステップ 4: 古いマスター ノードの監視を継続し、古いマスター ノードがオンラインに戻ったら、それを新しいマスター ノードのスレーブ ノードとして設定します。
ステップ 1: 新しいマスター ノードを選択する
フェイルオーバー操作の最初のステップは、オフラインのマスター ノードの下にあるすべての「スレーブ ノード」の中から良好なステータスと完全なデータを持つスレーブ ノードを選択し、次に SLAVEOF no one コマンドをこの「スレーブ ノード」に送信し、これを変換することです。スレーブノード」を「マスターノード」に変更します。
選考プロセスは次のとおりです。
- 第 1 ラウンドの検査: Sentinel はまず優先度に従ってスレーブ ノードを並べ替えます。優先度が小さいほど、ランキングが高くなります。
- 2 回目の検査: 優先順位が同じ場合は、レプリケーションの添字を確認し、「マスター ノード」からより多くのレプリケーション データを受信した方が優先されます。
- 3 回目の検査: 優先順位と添え字が同じ場合、ID が小さいスレーブ ノードを選択します。
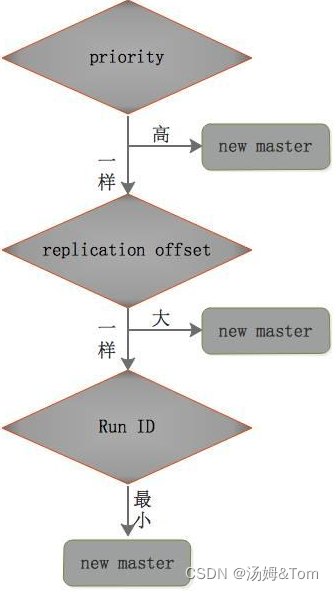
検査の最初のラウンド: 最も高い優先順位を持つスレーブ ノードが勝ちます。
Redisにはslave-priorityという設定項目があり、スレーブノードの優先度を設定できます。各スレーブノードのサーバ構成は必ずしも同じである必要はなく、サーバの性能構成に応じてスレーブノードの優先度を設定できます。
たとえば、「A スレーブ ノード」の物理メモリがすべてのスレーブ ノードの中で最大である場合、「A スレーブ ノード」の優先度を最高に設定できます。このようにして、センチネルが最初の検討ラウンドを実行すると、最も高い優先順位を持つスレーブ ノード A が最初に勝ち、新しいマスター ノードになります。
2 回目の検査: レプリケーションの進行状況が最も高いスレーブ ノードが勝ちます。
最初の検査ラウンドで、最高の優先順位を持つ 2 つのスレーブ ノードがあることが判明した場合、2 番目の検査ラウンドが実行され、2 つのスレーブ ノードのレプリケーションの進行状況が比較されます。
マスター/スレーブ アーキテクチャについて話したときに、レプリケーションの進行状況について前に説明しました: マスター/スレーブ アーキテクチャでは、マスター ノードは書き込み操作をスレーブ ノードに同期します。このプロセスでは、マスター ノードは master_repl_offset を使用して最新の書き込みを記録します。repl_backlog_bufferの操作(下図の「マスター サーバーが書き込んだデータ」の位置)、およびスレーブ ノードは、slave_repl_offset 値を使用して現在のレプリケーションの進行状況 (「スレーブ サーバーが書き込んだ位置」の位置) を記録します。下図の「読みたい」)。

スレーブ ノードのslave_repl_offsetがmaster_repl_offsetに最も近い場合、そのレプリケーションの進行状況が最も高いことを意味するため、新しいマスター ノードとして選択できます。
3 回目の検査: ID 番号が小さいスレーブ ノードが勝ちます。
2 回目の検査で 2 つのスレーブ ノードの優先度とレプリケーションの進行状況が同じであることが判明した場合、3 回目の検査で 2 つのスレーブ ノードの ID 番号が比較されます。スレーブノードを一意に識別し、ID 番号が小さいスレーブノードが優先されます。
スレーブ ノードが選出された後、センチネル リーダーは選択したスレーブ ノードに SLAVEOF no one コマンドを送信し、スレーブ ノードがスレーブ ノードとしてのステータスを解放し、新しいマスター ノードに変えます。以下の図に示すように、センチネル リーダーは、選択したスレーブ ノード server2 に SLAVEOF no one コマンドを送信し、スレーブ ノードを新しいマスター ノードにアップグレードします。
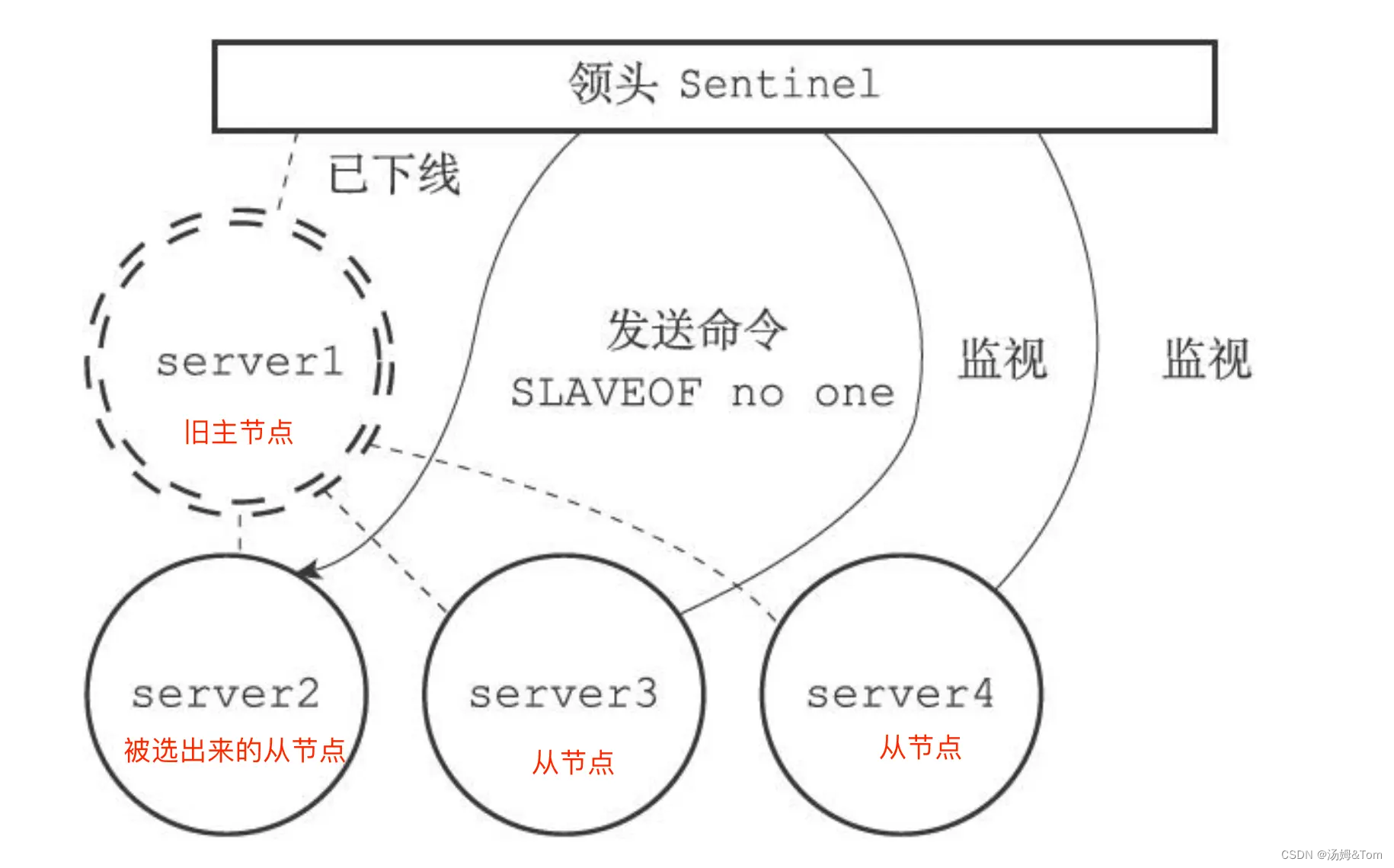
SLAVEOF no oneコマンドを送信し た後 、センチネル リーダーはアップグレードされたスレーブ ノードに1 秒に 1 回 INFOコマンドを送信し(フェールオーバー前、INFO コマンドの頻度は 10 秒に 1 回)、コマンドの応答を監視します。アップグレードされたノードの役割情報が元のスレーブからマスターに変更されると、セントリー リーダーは、選択されたスレーブ ノードがマスター ノードに正常にアップグレードされたことを認識します。
次の図に示すように、選択したスレーブ ノード server2 が新しいマスター ノードにアップグレードされます。

ステップ 2: スレーブ ノードが新しいマスター ノードを指すようにする
新しいマスター ノードが表示されたら、センチネル リーダーの次のステップは、オフラインのマスター ノードの下にあるすべての「スレーブ ノード」が「新しいマスター ノード」を指すようにすることです。このアクションは、 SLAVEOFコマンドを「スレーブノード」 を満たす必要があります。
以下の図に示すように、センチネル リーダーはすべてのスレーブ ノード (server3 とserver4) に SLAVEOF を送信し、それらが新しいマスター ノードのスレーブ ノードになることを許可します。

ステップ 3: マスター ノードが交換されたことを顧客に通知する
これまでの一連の操作を経て、ようやく Sentinel クラスタのマスター/スレーブ切り替えが完了しましたが、新しいマスターノードの情報はどのようにしてクライアントに通知されるのでしょうか?
これは主に、Redis のパブリッシャー/サブスクライバー メカニズムを通じて実現されます。各センチネル ノードはパブリッシャー/サブスクライバー メカニズムを提供し、クライアントはセンチネルからのメッセージをサブスクライブできます。Sentinel は多くのメッセージ サブスクリプション チャネルを提供します。チャネルごとに、マスター/スレーブ ノードの切り替えプロセスにおけるさまざまなキー イベントが含まれます。いくつかの一般的なイベントは次のとおりです。

クライアントは Sentinel との接続を確立した後、Sentinel が提供するチャネルにサブスクライブします。マスター/スレーブの切り替えが完了すると、Sentinel は新しいマスター ノードの IP アドレスとポート メッセージを +switch-master チャネルにパブリッシュします。このとき、クライアントはこのメッセージを受信し、新しいマスター ノードの IP アドレスを使用できます。マスターノード ポートと通信しました。
これらのイベント通知により、パブリッシャー/サブスクライバー メカニズムを通じて、クライアントはマスター/スレーブ切り替え後の新しいマスター ノードの接続情報を取得できるだけでなく、マスター/スレーブ ノード切り替え中に発生するさまざまな重要なイベントを監視することもできます。このようにして、クライアントはマスター/スレーブ切り替えがどの段階にあるかを知ることができ、切り替えの進行状況を理解するのに役立ちます。
ステップ 4: 古いマスター ノードをスレーブ ノードに変更する
フェイルオーバー操作で最後に行うことは、古いマスター ノードの監視を継続することです。古いマスター ノードがオンラインに戻ると、Sentinel クラスターはそれに SLAVEOF コマンドを送信して、新しいマスター ノードのスレーブ ノードにし ます。下に示された:

この時点で、マスター/スレーブ ノード全体のフェイルオーバーが完了します。
6. Sentinel クラスターの形成方法
実際、センチネル情報を構成するときは、マスター ノード名、マスター ノードの IP アドレスとポート番号、およびクォーラム値を設定するパラメーターを入力するだけです。
sentinel monitor <master-name> <ip> <redis-port> <quorum>
他のセンチネルノードの情報を入力する必要はありませんが、お互いをどのように認識しているのでしょうか?
実際、これらはRedis のパブリッシャー/サブスクライバー メカニズムを通じてお互いを発見することもできます。マスター/スレーブ クラスターでは、マスター ノードに __sentinel__:hello という名前のチャネルがあり、これを通じてさまざまなセンチネルが相互に検出し、通信します。
以下の図では、Sentinel A がその IP アドレスとポート情報を __sentinel__:hello チャネルに公開し、Sentinel B と C がこのチャネルにサブスクライブしています。このとき、Sentinel B と C は、このチャネルから Sentinel A の IP アドレスとポート番号を直接取得できます。その後、センチネル B と C はセンチネル A とのネットワーク接続を確立できます。
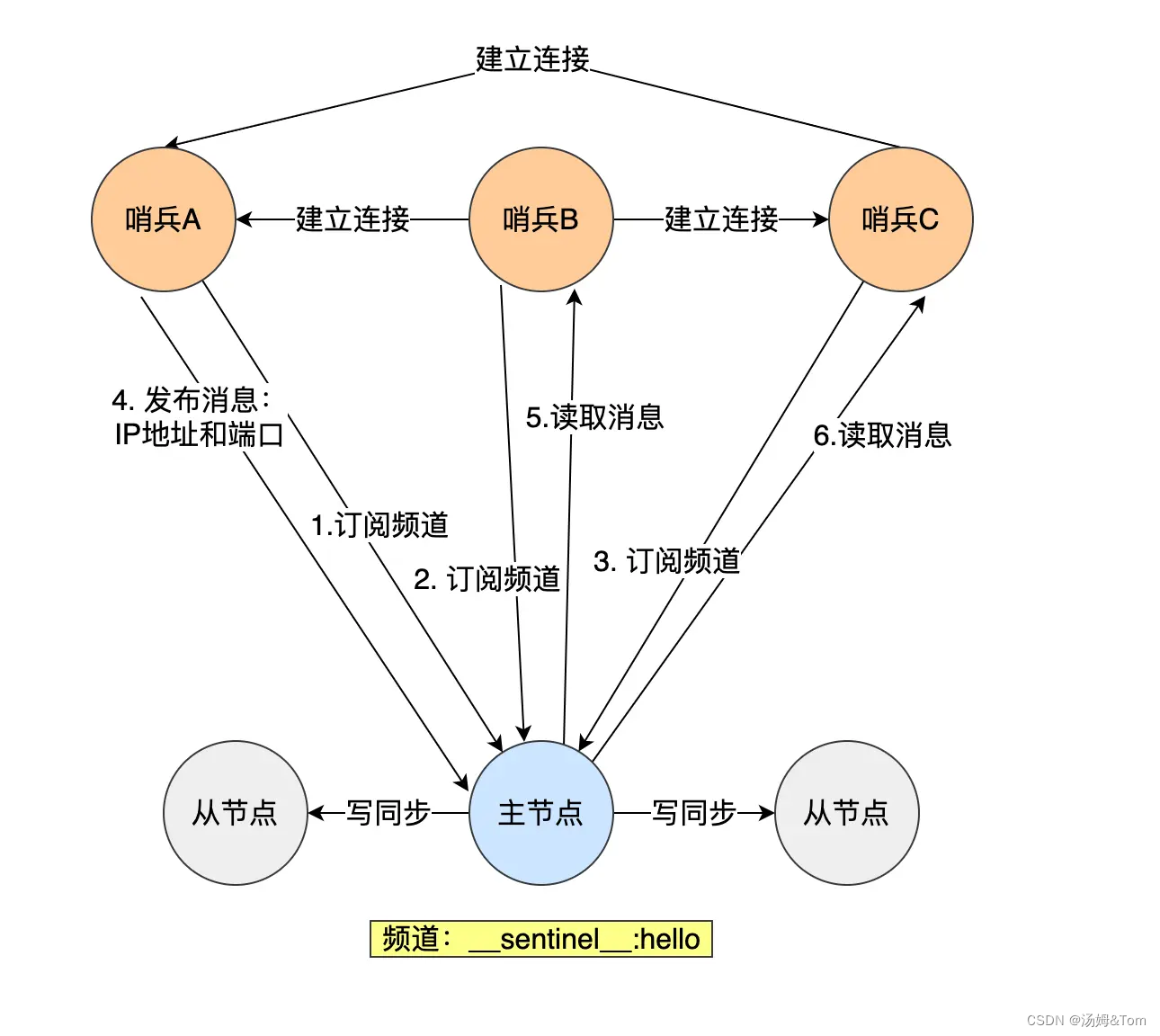
このようにして、Sentinel B と C もネットワーク接続を確立できるため、Sentinel クラスターが形成されます。
7. Sentinel クラスターはどのようにしてスレーブ ノードの情報を知るのですか?
マスター ノードはすべての「スレーブ ノード」の情報を知っているため、センチネルは10 秒ごとにマスター ノードにINFOコマンドを送信して、すべての「スレーブ ノード」の情報を取得します。
下図に示すように、Sentinel B はマスター ノードに INFO コマンドを送信し、このコマンドを受信したマスター ノードはスレーブ ノード リストを Sentinel に返します。次に、センチネルは、スレーブ ノード リストの接続情報に基づいて各スレーブ ノードとの接続を確立し、この接続上でスレーブ ノードを継続的に監視できます。センチネル A と C は、同じ方法でスレーブ ノードとの接続を確立できます。

Redis のパブリッシャー/サブスクライバー メカニズムを通じて、センチネルは相互に認識し、クラスターを形成することができます。同時に、センチネルは INFO コマンドを通じてマスター ノード内のすべてのスレーブ ノード接続情報を取得し、スレーブとの接続を確立できます。ノードに接続され、監視されます。
3. クラスターのシャーディング
1. 問題の導入
Sentinel モードは、高可用性と高同時読み取りの問題を解決しますが、まだ欠点があります。
- Sentry モードでは、各 Redis サーバーが同じデータを保存するため、メモリが無駄になり、大量のデータを保存することが困難になります。
- セントリー モードにはマスターが 1 つしかないため、大量の同時書き込みをサポートすることが困難になります。
これによりクラスターモードが誕生しました
2. クラスタモードの特徴
- Redis クラスターは複数のマスターをサポートしており、各マスターは複数のスレーブをマウントでき、各マスターは異なるデータを保存します。
- マスターはping を通じてお互いの健康状態を検出し、お互いを選出し、センチネルに依存しなくなります。
- クライアントが Redis ノードに接続するとき、クラスター内のすべてのノードに接続する必要はなくなり、最終的には正しいノードに転送されるため、クラスター内の使用可能なノードに接続するだけで済みます。
注:クラスター ノードがキーと値のペアとキーと値のペアの有効期限を保存する方法は、Redis スタンドアロン モードと同じです。唯一の違いは、ノードはデータベース No. 0 のみを使用できるのに対し、スタンドアロン Redis サーバーはデータベース No. 0 を使用できないことです。制限。
3. データパーティション理論
①ノードが残りのパーティションを取得
ユーザーによるすべての読み取りおよび書き込み操作は、ハッシュ(キー) % N マシン数という式に基づいて行われ、ハッシュ値が計算されて、データがどのノードにマップされるかを決定します。
このソリューションには問題があります。ノードの拡大や縮小など、ノードの数が変化すると、データ ノードのマッピング関係を再計算する必要があり、これによりデータの再移行が発生し、すべてのキャッシュが無効になります。
② 一貫性のあるハッシュ分割
ここでは詳しく説明しませんが、Hao Gang 先生のビデオを見ることをお勧めします。彼はとても上手に話します。
Haogang: 詳細_bilibili_bilibili の一貫したハッシュ アルゴリズムを説明する 7 分間のビデオ
③ハッシュスロットパーティション
Redis クラスターは一貫したハッシュを使用しませんが、ハッシュ スロットの概念を導入します。
ハッシュスロット(スロット)はデータとノードの間に位置し、データとノードの関係を管理するために使用され、ノード上にスロットを配置し、そのスロットにデータを配置することに相当します。
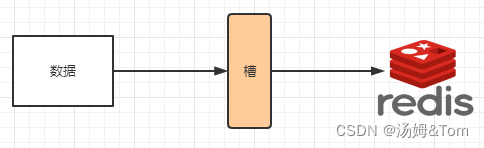
スロットは粒度の問題を解決します。これは粒度を大きくすることと同じであり、データの移動が容易になります。ハッシュはマッピングの問題を解決し、キーのハッシュ値を使用してスロットを計算するため、データの分散が容易になります。
Redis クラスターには 16384 のハッシュ スロットがあります。最初に各キーのCRC16 ハッシュ値を計算し、次に 16384 を法にしてどのスロットに配置するかを決定します。クラスター内の各ノードは、ハッシュ スロットの一部を担当します。たとえば、現在のクラスターに 3 つのノードがある場合、次のようになります。
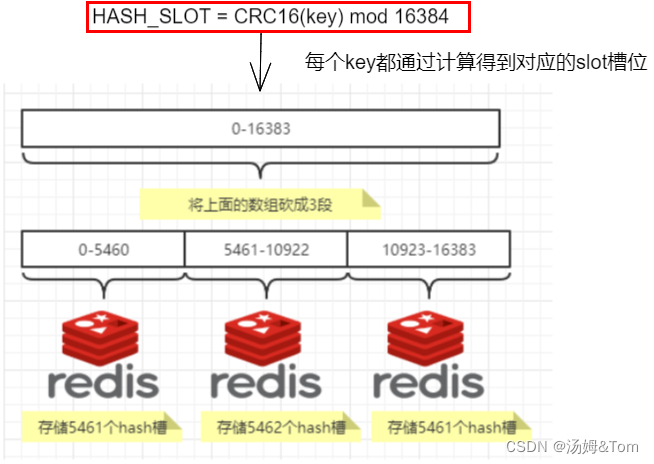
4. Redis クラスターの最大スロット数が 16384 であるのはなぜですか?
CRC16 アルゴリズムによって生成されるハッシュ値は 16 ビットで、このアルゴリズムは 2^16=65536 個の値を生成できます。つまり、値は 0 ~ 65535 の間に分布しています。さらに大きい値 65536 があるのに、なぜ 16384 だけで十分なのでしょうか。作者がMOD操作をしていたとき、なぜmod16384ではなくmod65536にしなかったのでしょうか?
Redis クラスターのノードは、次のルールに従って ping メッセージを送信します。
- 1秒ごとに5つのノードがランダムに選択され、最も長い時間通信がなかったノードが見つけられ、pingメッセージが送信されます。
- ローカル ノード リストは 100 ミリ秒ごとにスキャンされ、ノードが最後に pong メッセージを受信した時間がcluster-node-timeout/2 を超えていることが判明した場合は、ping メッセージがすぐに送信されます。
ハートビート パケットのメッセージ ヘッダーにはmyslots の char 配列があり、これはビットマップです。各ビットはスロットを表します。ビットが 1 の場合、スロットがこのノードに属していることを意味します。

(1) スロットが 65536 の場合、ハートビート情報を送信するメッセージ ヘッダーが 8k に達し、送信されるハートビート パケットが大きすぎるため、帯域幅が無駄になります。
- メッセージ ヘッダーで最も多くのスペースを占めるのは、myslots[CLUSTER_SLOTS/8] です。スロットが 65536 の場合、このブロックのサイズは次のようになります: 65536÷8÷1024=8kb
- メッセージ ヘッダーで最も多くのスペースを占めるのは、myslots[CLUSTER_SLOTS/8] です。スロットが 16384 の場合、このブロックのサイズは 16384÷8÷1024=2kb となります。
(2) Redis クラスタのマスターノード数は基本的に1,000を超えることはできず、多すぎるとネットワークの混雑が発生する可能性があります。
クラスタ ノードの数が多いほど、ハートビート パケットのメッセージ本文に含まれるデータも多くなります。ノードが 1,000 を超える場合も、ネットワークの輻輳が発生します。したがって、redis 作成者は、redis クラスター ノードの数が 1,000 を超えることを推奨しません。したがって、ノード数が 1,000 未満の Redis クラスターの場合は、16384 スロットで十分です。65536 まで拡張する必要はありません。
(3) スロットが小さいほど圧縮率が高く、伝送しやすくなります。
Redis マスター ノードの構成情報では、担当するハッシュ スロットがビットマップの形式で保存されます。ビットマップは送信プロセス中に圧縮されます。ビットマップの充填率(スロット/N、N はスロットを表します)ノード数) が大きいほど、低いほど圧縮率が高くなります。したがって、スロット数が少ないほど、フィルレートは低下し、圧縮率は増加します。
5. クラスター内でコマンドを実行する
データベース内の 16384 個のスロットがすべて割り当てられると、クラスタはオンライン状態になります。これは、クライアントがクラスタ内のノードにデータ コマンドを送信できるときです。コマンドによって処理されるキーがどのスロットに属しているかを計算する必要があります。 . そしてそれが自分に割り当てられているかどうかを確認します。
キーが配置されているスロットが現在のノードに割り当てられている場合、ノードは次のコマンドを直接実行します。

キーが配置されているスロットが現在のノードに割り当てられていない場合、ノードはクライアントに MOVED エラーを返します (クラスター モードでは、MOVED エラーは非表示になり表示されませんが、リダイレクト済みとして直接表示されます)。正しいノードにリダイレクトし、実行したいコマンドを再度送信します。


6.スロットの再割り当て
Redis クラスターが拡張/縮小されると、スロットが再割り当てされます。
- Redis クラスターのスロット再割り当て操作では、ノードに割り当てられている任意の数のスロットを別のノード (ターゲット ノード) に変更でき、関連するスロットが属するキーと値のペアもソース ノードからターゲット ノードに移動されます。ノードの優れた
- リシャーディング操作はオンラインで実行できます。リシャーディング プロセス中、クラスターをオフラインにする必要はなく、ソース ノードとターゲット ノードの両方がコマンド リクエストの処理を続行できます。
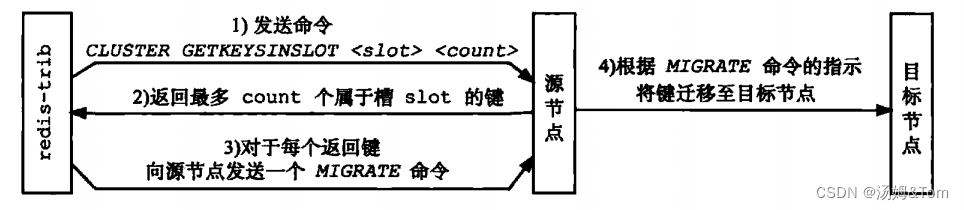
- Redis クラスター内のスロットの再分配は、クラスター管理ソフトウェア redis-trib によって実行されます。Redis は、再シャーディングに必要なすべてのコマンドを提供します。redis-trib は、ソース ノードとターゲット ノードにコマンドを送信することによって再シャーディングします。
7. MOVEDエラーとASKエラー
移動エラー
前述したように、キーが配置されているスロットが現在のノードに割り当てられていない場合、ノードは MOVED エラーをクライアントに返します (これは非表示になります)。
MOVED エラーの形式は次のとおりです。
MOVED <slot> <ip>:<port>
ここで、slot はキーが配置されているスロットであり、ip と port はスロットの処理を担当するノードの IP アドレスとポート番号です。
# 表示槽10086正由127.0.0.1,端口号为7002的节点负责。
MOVED 10086 127.0.0.1:7002通常、クラスター クライアントはクラスター内の複数のノードとのソケット接続を作成します。いわゆるノード ステアリングとは、実際にはコマンドを送信するソケットを変更することを意味します。
クライアントがリダイレクトしたいノードとのソケット接続をまだ確立していない場合、クライアントはまずMOVED エラーによって提供された IP アドレスとポート番号に基づいてノードに接続し、次にリダイレクトします。
ASKエラー
リシャーディング中に、ソース ノードがスロットをターゲット ノードに移行すると、移行されたスロットに属するキーと値のペアの一部がソース ノードに保存され、キーと値のペアの他の部分が保存されるという状況が発生する可能性があります。ソースノード内 ターゲットノード内
クライアントがデータベース キーに関連するコマンドをソース ノードに送信し、コマンドによって処理されるデータベース キーがたまたま移行中のスロットに属している場合:
- ソース ノードはまず、指定されたキーを自身のデータベース内で検索し、見つかった場合は、クライアントから送信されたコマンドを直接実行します。
- 逆に、ソース ノードが自身のデータベース内で指定されたキーを見つけられない場合、キーはターゲット ノードに移行されている可能性があり、ソース ノードはクライアントに ASK エラー (これも非表示) を返し、クライアントをガイドします。スロットがインポートされているターゲット ノードに移動し、実行するコマンドを再度送信します。

MOVED エラーを受信したときの状況と同様に、クラスターモードの redis-cli は、ASK エラーを受信したときにエラーを出力しませんが、エラーによって提供された IP アドレスとポートに基づいてリダイレクトアクションを自動的に実行します。
ASKエラーとMOVEDエラーの違い
- MOVED エラーは、スロットの責任が 1 つのノードから別のノードに移されたことを示します。
- ASK エラーは、移行スロット プロセス中のキー処理に対する 2 つのノードの責任を示します。
8. Redis Cluser はどのようにして高可用性を確保しますか?
Redis Cluster は主に、障害検出とフェイルオーバーという 2 つの戦略に基づいて高可用性を確保します。実際、これら 2 つの戦略の処理はセントリー モードの処理に似ています。
故障検出
クラスター内の各ノードは、クラスター内の他のノードに PING メッセージを定期的に送信して、他のノードがオンラインかどうかを検出します。PING メッセージを受信したノードが、指定された時間内に PING メッセージを送信したノードに PONG メッセージを返さなかった場合、次に送信 PING メッセージを受信したノードは、PING メッセージ ノードをオフラインの疑いがあるものとしてマークします(失敗の可能性、PFAIL)。

クラスター内のスロットの処理を担当するマスター ノードの半分以上が特定のノード X を PFAIL としてマークすると、特定のマスター ノードはマスター ノード X をオフライン (FAIL) としてマークし、このメッセージをブロードキャストします。これにより、他のすべてのノードがはすぐにマスター ノード X を FAIL としてマークします。
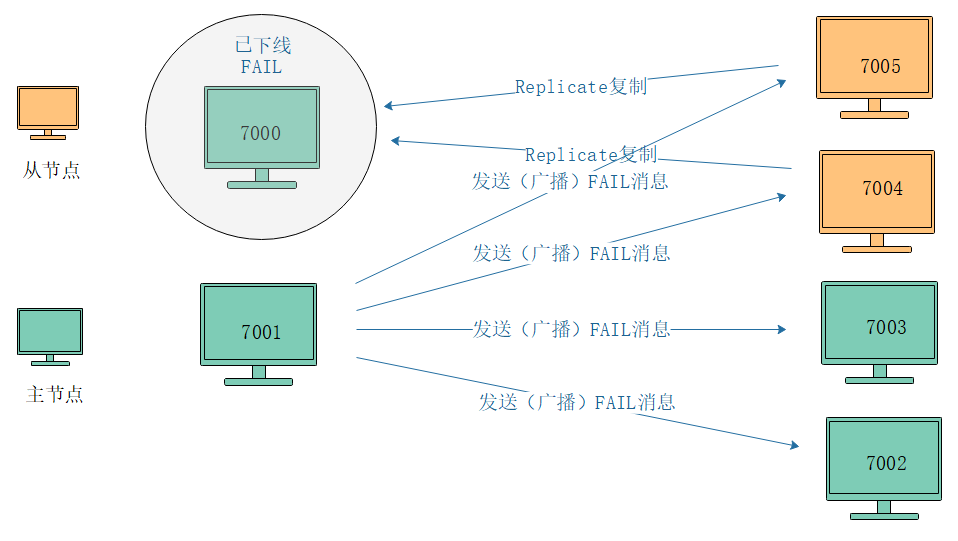
仮定:
- Redis クラスターには 4 つのマスター ノード: 7000 ~ 7003 と 2 つのスレーブ ノード: 7004 および 7005 があります。
- この時点では、7000はオフラインになっており、マスタノード7001はマスタノード7000がPFAILに入ったと考える。
- 同時に、マスターノード7002および7003も、マスターノード7000がオフライン状態に入ったと信じている。
このようにして、マスター ノードの半分以上がノード 7000 に障害が発生したと考え、7001 は 7000 を FAIL ステータスとしてマークし、マスター ノード 7000 が FAIL であるというメッセージをクラスターにブロードキャストします。
フェイルオーバー
ステップ 1: 新しいマスター ノードを選択する
- オフラインのマスターノードのすべてのスレーブノードの中から 1 つをマスターノードとして選択します。ここの選出方法もSentinelと似ています。
- 選択されたスレーブ ノードはSLAVEOF no one コマンドを実行し、新しいマスター ノードになります。
ステップ 2: オフライン マスター ノードのスロットを新しいノードに割り当てる
新しいマスター ノードは、オフライン マスター ノードへのすべてのスロット割り当てを取り消し、すべてのスロットを自分自身に割り当てます。
ステップ 3: マスターノードが交換されたことをクラスターに通知します。
新しいマスター ノードは、クラスターに PONG メッセージをブロードキャストして、他のノードに「私がマスター ノードになり、オフライン ノードを担当する処理スロットを引き継ぎます」ということを知らせます。
新しいマスター ノードは、処理を担当するスロットに関連するコマンド リクエストの受信を開始します。
ステップ 4: 古いマスター ノードをスレーブ ノードに変更する
例: 4 つのマスター ノード 7000、7001、7002、および 7003 を含むクラスターに、2 つのノード 7004 および 7005 を追加し、マスター ノード 7000 の 2 つのスレーブ ノードとして機能します。

この時点でマスター ノード 7000 がオフライン (ダウンタイム) になった場合、クラスター内にはまだ複数のマスター ノードが存在します。ノード 7000 の 2 つのスレーブ ノード 7004 と 7005 の 1 つがマスター ノードとして選択されます。たとえば、7004 が選択された場合この新しいノードは、元のノード 7000 によって処理されたスロットを引き継ぎ、クライアントによって送信されたリクエストの処理を継続しますが、この時点では 7005 が 7004 のスレーブ ノードとして機能します。

ノード 7000 がオフラインになってから再びオンラインになると、ノード 7004 のスレーブ ノードとして機能します。
