記事ディレクトリ
シングルポイントRedisの問題
- データ損失の問題:Redisはメモリ内ストレージであり、サービスを再起動するとデータが失われる可能性があります
- 同時実行の問題:単一ノードのRedis同時実行機能は優れていますが、618などの高い同時実行シナリオには対応できません。
- 障害回復の問題:Redisがダウンした場合、サービスは利用できず、自動障害回復方法が必要です
- ストレージ容量の問題:Redisはメモリに基づいており、単一ノードで保存できるデータの量は、大量のデータの需要を満たすのが困難です。
1.Redisの永続性
1.RDB持久化
RDBのフルネームはRedisデータベースバックアップファイル(Redisデータバックアップファイル)で、Redisデータスナップショットとも呼ばれます。簡単に言えば、メモリ内のすべてのデータをディスクに記録します。Redisインスタンスに障害が発生して再起動すると、スナップショットファイルがディスクから読み取られ、データが復元されます。
スナップショットファイルはRDBファイルと呼ばれ、デフォルトで現在実行中のディレクトリに保存されます。
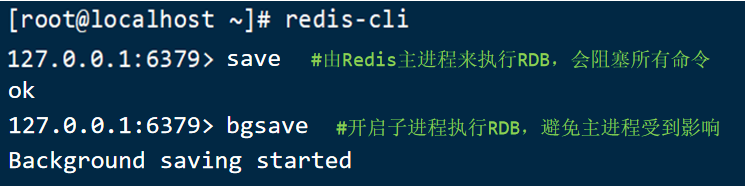 Redis内でRDBをトリガーするメカニズムがあります。これはredis.confファイルにあります。形式は次のとおりです。
Redis内でRDBをトリガーするメカニズムがあります。これはredis.confファイルにあります。形式は次のとおりです。
# 900秒内,如果至少有1个key被修改,则执行bgsave
# 如果是save "" 则表示禁用RDB
save 900 1
RDBの他の構成もredis.confファイルで設定できます
# 是否压缩 ,建议不开启,压缩也会消耗cpu,磁盘的话不值钱
rdbcompression yes
# RDB文件名称
dbfilename dump.rdb
# 文件保存的路径目录
dir ./
bgsaveが起動すると、メインプロセスをフォークして子プロセスを取得し、子プロセスがメインプロセスのメモリデータを共有します。
フォークが完了すると、メモリデータの読み取りとRDBファイルへの書き込みが行われます。
フォークは採用します。コピーオンライトテクノロジー:
- メインプロセスが読み取り操作を実行すると、共有メモリにアクセスします
- メインプロセスが書き込み操作を実行すると、データのコピーがコピーされ、書き込み操作が実行されます。
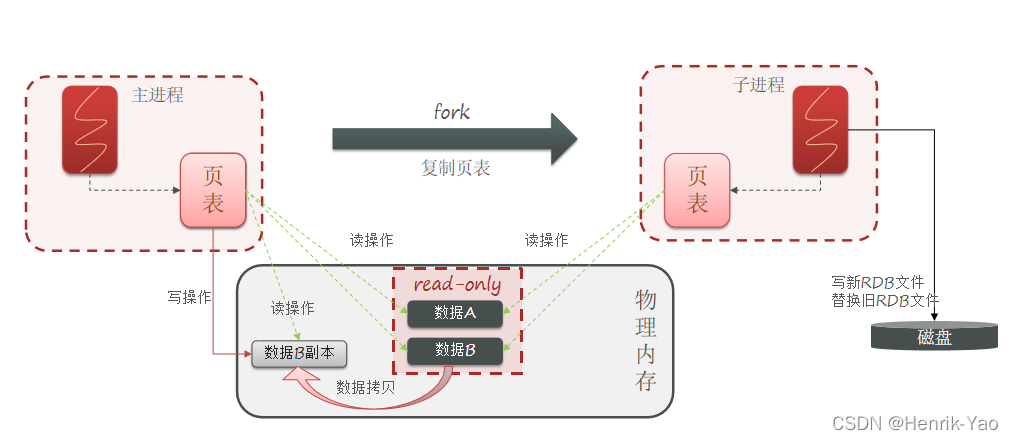
RDBのデメリット:
- RDBの実行間隔が長く、2つのRDB間でデータが失われるリスクがあります。
- 子プロセスのフォーク、圧縮、およびRDBファイルの書き込みには時間がかかります
2.AOFの永続性
AOFのフルネームはAppendOnlyFileです。Redisによって処理された各書き込みコマンドはAOFファイルに記録され、コマンドログファイルと見なすことができます。

AOFはデフォルトで無効になっています。AOFを有効にするには、redis.conf構成ファイルを変更する必要があります。
# 是否开启AOF功能,默认是no
appendonly yes
# AOF文件的名称
appendfilename "appendonly.aof"
AOFコマンドの記録の頻度は、redis.confファイルを使用して構成することもできます。
# 表示每执行一次写命令,立即记录到AOF文件
appendfsync always
# 写命令执行完先放入AOF缓冲区,然后表示每隔1秒将缓冲区数据写到AOF文件,是默认方案
appendfsync everysec
# 写命令执行完先放入AOF缓冲区,由操作系统决定何时将缓冲区内容写回磁盘
appendfsync no

これは記録コマンドであるため、AOFファイルはRDBファイルよりもはるかに大きくなります。また、AOFは同じキーへの複数の書き込みを記録しますが、意味があるのは最後の書き込みのみです。bgrewriteaofコマンドを実行することにより、AOFファイルを書き換えて、最小限のコマンドで同じ効果を得ることができます。

また、しきい値がトリガーされると、RedisはAOFファイルを自動的に書き換えます。しきい値は、redis.confで構成することもできます。
# AOF文件比上次文件 增长超过多少百分比则触发重写
auto-aof-rewrite-percentage 100
# AOF文件体积最小多大以上才触发重写
auto-aof-rewrite-min-size 64mb
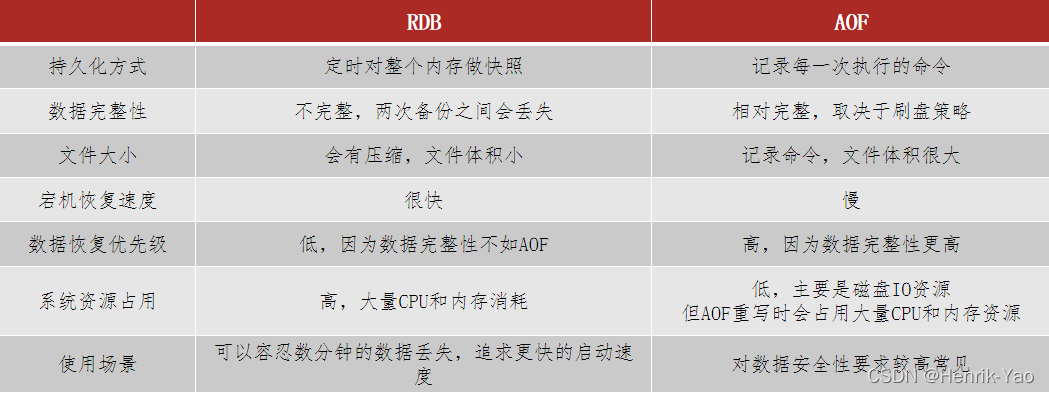
3.コントラスト
RDBとAOFにはそれぞれ長所と短所があり、データセキュリティの要件が高い場合は、実際の開発で組み合わせて使用されることがよくあります。
2.Redisマスタースレーブ
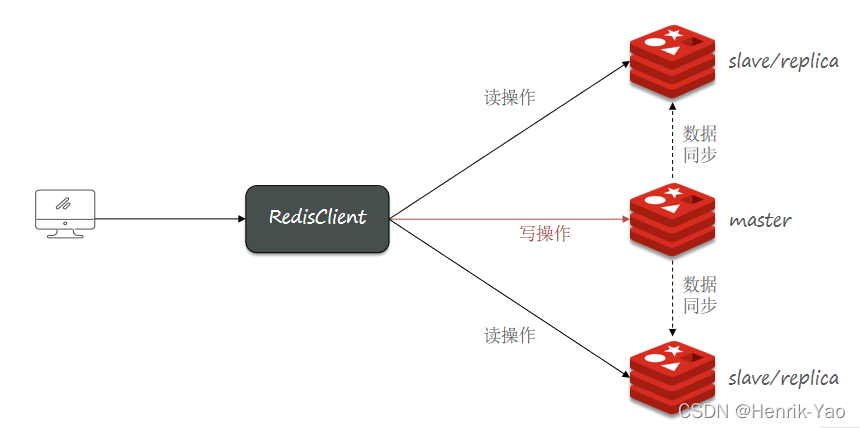
1.マスタースレーブアーキテクチャ
単一ノードのRedisの同時実行機能には制限があります。Redisの同時実行機能をさらに向上させるには、マスタースレーブクラスターを構築して読み取りと書き込みの分離を実現する必要があります。
2.マスター/スレーブ同期
マスターとスレーブの最初の同期は完全同期です:
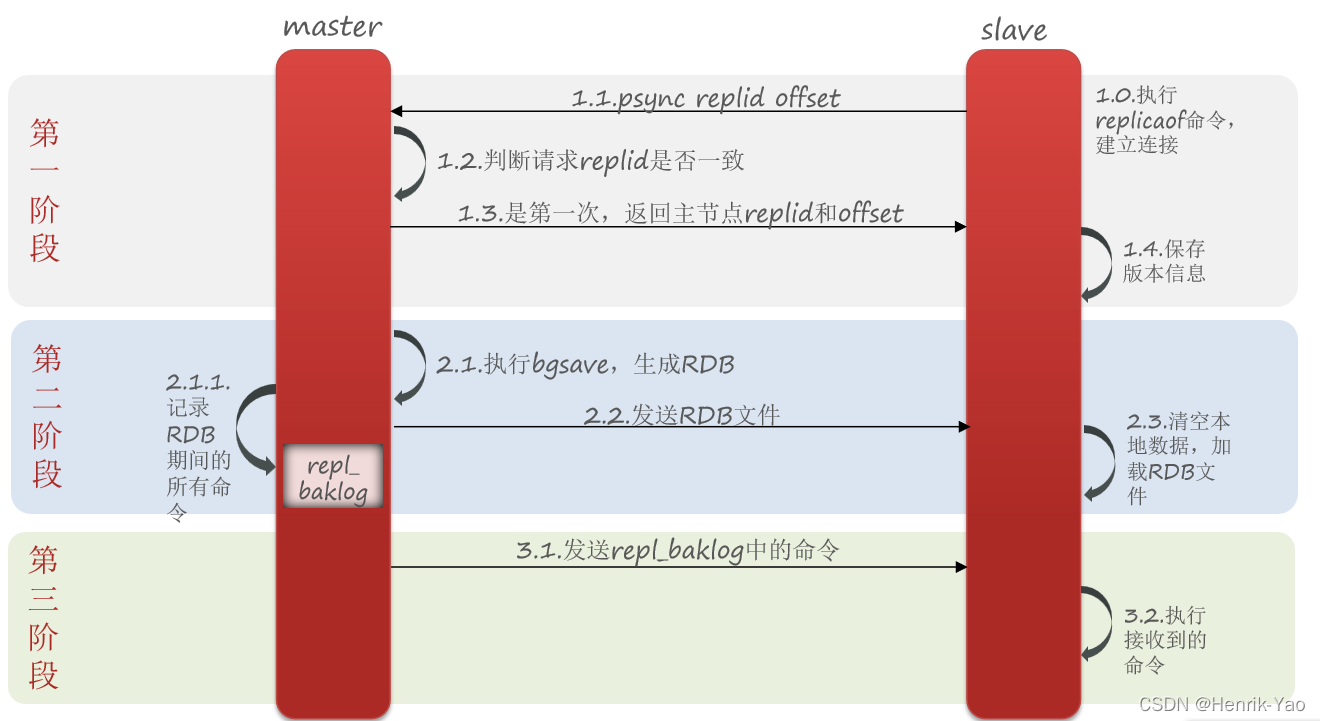
データ同期の場合、スレーブはレプリケーションIDとオフセットをマスターに宣言する必要があります。これにより、マスターは同期する必要のあるデータを決定できます。
- レプリケーションID:略して返信されます。これはデータセットのマークです。IDが一貫している場合は、同じデータセットであることを意味します。各マスターには一意の応答があり、スレーブはマスターノードの応答を継承します
- offset:オフセット。repl_baklogに記録されるデータが増加するにつれて徐々に増加します。スレーブが同期を完了すると、現在の同期のオフセットも記録されます。スレーブのオフセットがマスターのオフセットよりも小さい場合は、スレーブデータがマスターより遅れているため、更新する必要があることを意味します。
完全同期のプロセス:
- スレーブノードは増分同期を要求します
- マスターノードは応答を判断し、不整合を見つけ、増分同期を拒否します
- マスターは完全なメモリデータからRDBを生成し、RDBをスレーブに送信します
- スレーブはローカルデータをクリアし、マスターのRDBをロードします
- マスターはRDB中にコマンドをrepl_baklogに記録し、ログのコマンドをスレーブに送信し続けます
- スレーブは受信したコマンドを実行し、マスターとの同期を維持します
マスターとスレーブの最初の同期は完全同期ですが、スレーブを再起動して同期すると、増分同期が実行されます。

repl_baklogのサイズには上限があり、最も古いデータはいっぱいになると上書きされます。スレーブの切断が長すぎてバックアップされていないデータが上書きされた場合、ログに基づいて増分同期を実行できず、完全同期のみを再度実行できます。
マスター/スレーブ同期の最適化
- マスターでrepl-diskless-syncyesを構成して、ディスクレスレプリケーションを有効にし、完全同期中のディスクIOを回避します。
- 単一のRedisノードのメモリ使用量は、RDBによって引き起こされる過剰なディスクIOを減らすために大きすぎないようにする必要があります
- repl_baklogのサイズを適切に増やし、スレーブがダウンしていることが判明したときにできるだけ早く障害回復を実現し、完全な同期をできるだけ避けます
- マスター上のスレーブノードの数を制限します。スレーブが多すぎる場合は、マスター-スレーブ-スレーブチェーン構造を使用して、マスターの圧力を減らすことができます。

完全同期と増分同期の違い
- 完全同期:マスターは完全なメモリデータからRDBを生成し、RDBをスレーブに送信します。後続のコマンドはrepl_baklogに記録され、スレーブに1つずつ送信されます
- インクリメンタル同期:スレーブは独自のオフセットをマスターに送信し、マスターはrepl_baklogのオフセットの後にスレーブにコマンドを取得します
完全同期実行時間
- スレーブノードが初めてマスターノードに接続するとき
- スレーブノードが長時間切断され、repl_baklogのオフセットが上書きされました
増分同期実行時間
- スレーブノードが切断されて復元され、オフセットがrepl_baklogにある場合
3. RedisSentinel
1.センチネルの機能と原理
センチネルの役割
Redisは、マスタースレーブクラスターの自動障害回復を実現するためのSentinelメカニズムを提供します。歩哨の構造と機能は次のとおりです。
- 監視:Sentinelは、マスターとスレーブが期待どおりに機能していることを常に確認します
- 自動フェイルオーバー:マスターに障害が発生した場合、Sentinelはスレーブをマスターに昇格させます。障害のあるインスタンスが回復すると、新しいマスターもメインになります
- 通知:SentinelはRedisクライアントのサービス検出ソースとして機能し、クラスターフェイルオーバーが発生すると、最新の情報をRedisクライアントにプッシュします。
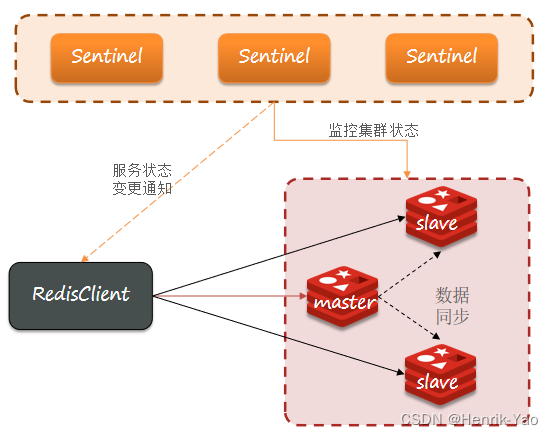
サービスステータスの監視
Sentinelは、ハートビートメカニズムに基づいてサービスステータスを監視し、1秒ごとにクラスターの各インスタンスにpingコマンドを送信します。
- 主観的オフライン:センチネルノードが、インスタンスが指定された時間内に応答しないことを検出した場合、そのインスタンスは主観的にオフラインであると見なされます。
- 客観的オフライン:指定された数(クォーラム)を超えるセンチネルがインスタンスを主観的にオフラインと見なす場合、インスタンスは客観的にオフラインになります。クォーラム値は、Sentinelインスタンスの数の半分以上であることが好ましい

新しいマスターを選出する
マスターの障害が見つかったら、センチネルは軟膏で新しいマスターを選択する必要があります。選択の基準は次のとおりです。
- まず、スレーブノードがマスターノードから切断される時間の長さを決定します。指定された値(ミリ秒後のダウン* 10)を超えると、スレーブノードは除外されます。
- 次に、スレーブノードのスレーブ優先度の値を判断します。優先度が小さいほど優先度が高くなります。0の場合、選挙に参加することはありません。
- スレーブの優先度が同じ場合は、スレーブノードのオフセット値を判断します。値が大きいほど、データが新しくなり、優先度が高くなります。
- 最後のステップは、スレーブノードの実行IDサイズを判断することです。値が小さいほど、優先度が高くなります。
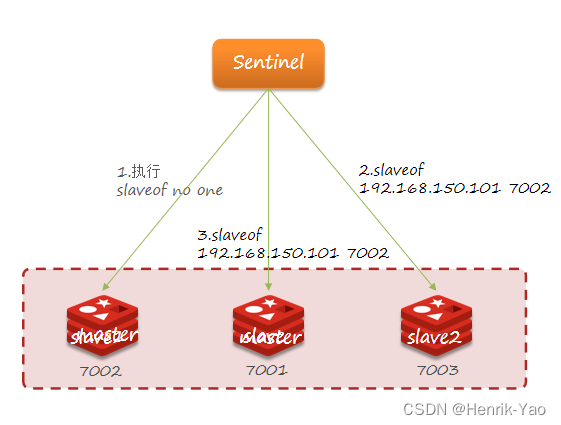
フェイルオーバー
スレーブの1つ(たとえば、slave1)が新しいマスターとして選択された場合、フェイルオーバーの手順は次のとおりです。
- Sentinelはslaveofnooneコマンドを代替slave1ノードに送信して、ノードをマスターにします
- Sentinelはslaveof192.168.150.1017002コマンドを他のすべてのスレーブに送信し、これらのスレーブを新しいマスターのスレーブノードにし、新しいマスターからのデータの同期を開始します。
- 最後に、センチネルは障害のあるノードをスレーブとしてマークし、障害のあるノードが回復すると、自動的に新しいマスターのスレーブノードになります
4.Redisシャーディングクラスター
1.シャードクラスター構造
マスタースレーブとセンチネルは、高可用性と高同時読み取りの問題を解決できます。しかし、まだ解決されていない2つの問題があります。
- 大量のデータストレージの問題
- 高い同時書き込みの問題
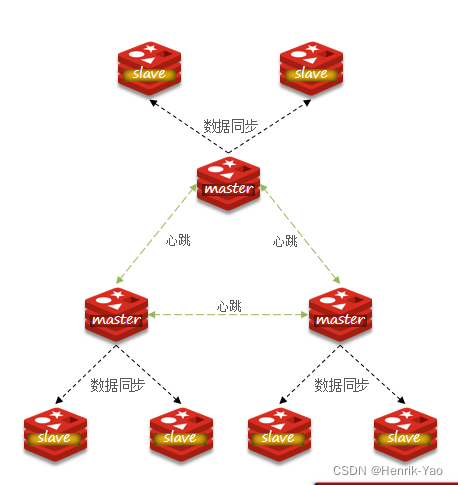
シャードクラスターを使用すると、上記の問題を解決できます。シャードクラスターの特徴:
- クラスタには複数のマスターがあり、各マスターは異なるデータを保存します
- 各マスターは複数のスレーブノードを持つことができます
- マスターはpingを介して互いの健康状態を監視します
- クライアント要求はクラスター内の任意のノードにアクセスでき、最終的には正しいノードに転送されます
2.ハッシュスロット
Redisは、各マスターノードを0から16383までの合計16384スロット(ハッシュスロット)にマップします。クラスター情報を表示すると、次のことがわかります。
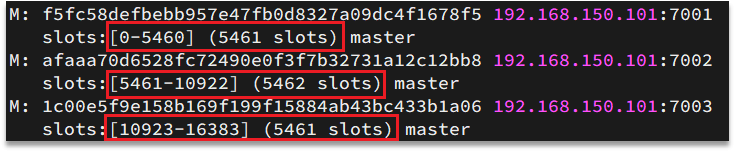
データキーはノードではなく、スロットにバインドされます。Redisは、キーの有効な部分に基づいてスロット値を計算します。
キーに「{}」が含まれ、「{}」に少なくとも1文字が含まれ、「{}」の部分がキーの有効な部分
。「{}」が含まれている場合、キー全体が有効な部分
です。たとえば、キーがnumの場合は、numに従って計算され、{itcast} numの場合は、 itcastに従って計算されます。計算方法は、CRC16アルゴリズムを使用してハッシュ値を取得し、16384の余りを取得することで、結果はスロット値になります。
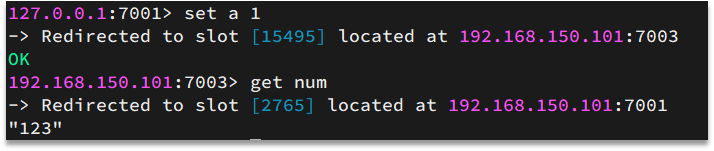
同じタイプのデータを同じRedisインスタンスに保持するにはどうすればよいですか?
このタイプのデータは同じ有効な部分を使用します。たとえば、キーのプレフィックスは{typeId}です。
3.クラスタースケーリング
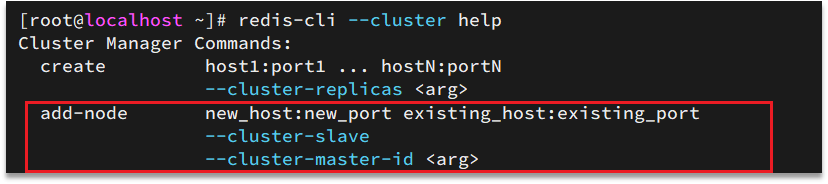
クラスターにノードを追加します
redis-cli --clusterは、クラスターを操作するための多くのコマンドを提供します。これらのコマンドは、次の方法で表示できます。
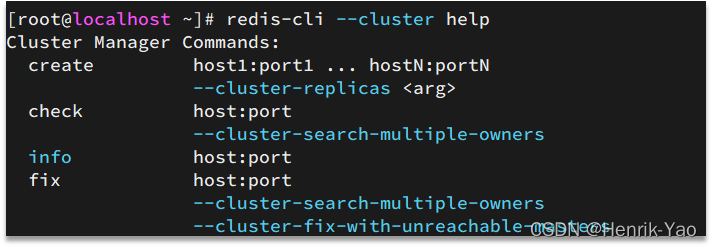
たとえば、ノードを追加するコマンドは次のとおりです。
4.フェイルオーバー
クラスタ内のマスターの1つがダウンするとどうなりますか?
1つ目は、インスタンスが他のインスタンス
との接続を失い、次にダウンタイムが疑われることです。

最後に、オフラインになり、スレーブを新しいマスターに自動的に昇格させることが決定されます。

手動フェイルオーバー
クラスタフェールオーバーコマンドを使用すると、クラスタ内のマスターを手動でシャットダウンし、クラスタフェールオーバーコマンドを実行するスレーブノードに切り替えて、認識できないデータ移行を実現できます。プロセスは次のとおりです。
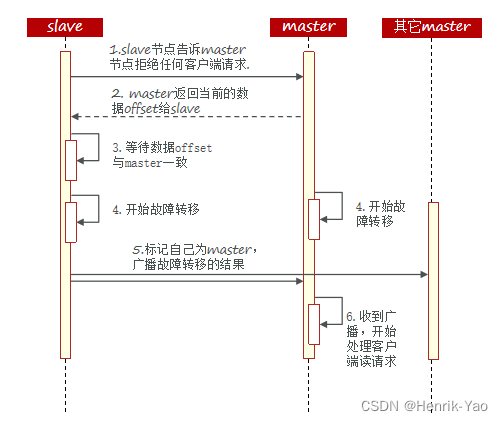
手動フェイルオーバーは、次の3つの異なるモードをサポートします。
- デフォルト:図1〜6に示すように、デフォルトのプロセス
- force:オフセットの整合性チェックを省略します
- 引き継ぎ:データの一貫性を無視し、マスターステータスやその他のマスターの意見を無視して、ステップ5を直接実行します