記事ディレクトリ
サウザンドモデル戦争はいよいよ本格化し、ChatGPTを徹底的に理解することが勝利の鍵となります。
声明: 書籍の寄付活動はブロガーと出版社の協力によるものであり、ファンのみの特典です。
この号の書籍: 「ChatGPT の原則と実践」
参加方法: コメント エリアでブロガーをフォローする: いいね | コレクション |
コメント エリアにメッセージを残す: 「AI の新時代を受け入れる」
活動期限: : 9 月 18 日2023年
プレゼント本数:: 3~5本
当選リストは締め切り翌日の午後8時に動的に更新されます!当選後はブロガーからプライベートメッセージで通知 | 3日以内にご返信いただけない場合は当選とみなされます | 自動的に辞退となります

ChatGPT の技術原理を 4 次元で説明し、ChatGPT の謎に満ちた技術ブラック ボックスを明らかにします。
1. 前に書く
ChatGPT モデルが 2022 年 11 月 30 日に発表されると、すぐに世界中で大騒ぎを引き起こしました。AI 実践者も非実践者も、ChatGPT のインパクトのあるインタラクティブ エクスペリエンスと生成された素晴らしいコンテンツについて話しています。これにより、一般の人々が人工知能の可能性と価値を再認識するようになりました。AI 実践者にとって、ChatGPT モデルはアイデアの拡張となっています。大規模なモデルはもはやランキングのための単なるおもちゃではありません。誰もが高品質のデータの重要性を認識しており、「人工知能の数だけ、人工知能も存在するだろう」と固く信じています。多くの知性が存在します。」
ChatGPT モデルは優秀すぎるため、多くのタスクではサンプルがゼロまたは少数のデータでも SOTA の結果を達成できるため、多くの人が大規模モデルの研究に目を向けるようになっています。
GoogleがChatGPTのベンチマークとしてBardモデルを提案しただけでなく、Baiduの「Wen Xin Yi Yan」、Alibabaの「Tong Yi Qian Wen」、SenseTimeの「Ri Ri Xin」、Zhihuの「Zhihaitu AI」など、中国では多くの大規模な中国モデルが登場しています。 」、清華大学の「ChatGLM」、復旦大学の「MOSS」、Metaの「Llama1&Llama2」など。
Alpaca モデルの出現後、70 億のパラメータを持つモデルは ChatGPT の効果を達成することはできませんが、大規模なモデルの計算能力コストを大幅に削減し、一般のユーザーや一般の企業が大規模なモデルを使用できるようになったことが証明されました。モデル。これまで強調されてきたデータの問題は GPT-3.5 または GPT-4 インターフェイスを通じて取得でき、データ品質も非常に高いです。基本的な効果モデルのみが必要な場合、データが再度正確に校正されているかどうかはそれほど重要ではありません (もちろん、より良い効果を得るには、より正確なデータが必要です)。
2. トランスフォーマアーキテクチャモデル
事前トレーニングされた言語モデルの本質は、大量のデータから言語の普遍的な表現を学習することによって、下流のサブタスクでより良い結果を得るということです。モデル パラメーターが増加し続けるため、多くの事前トレーニング済み言語モデルは大規模言語モデル (Large Language Model、LLM) とも呼ばれます。「大きい」の定義は人によって異なります。どのくらいのパラメーター モデルが大規模な言語モデルであるかを言うのは困難です。通常、事前トレーニングされた言語モデルと大規模な言語モデルを強制的に区別することはありません。
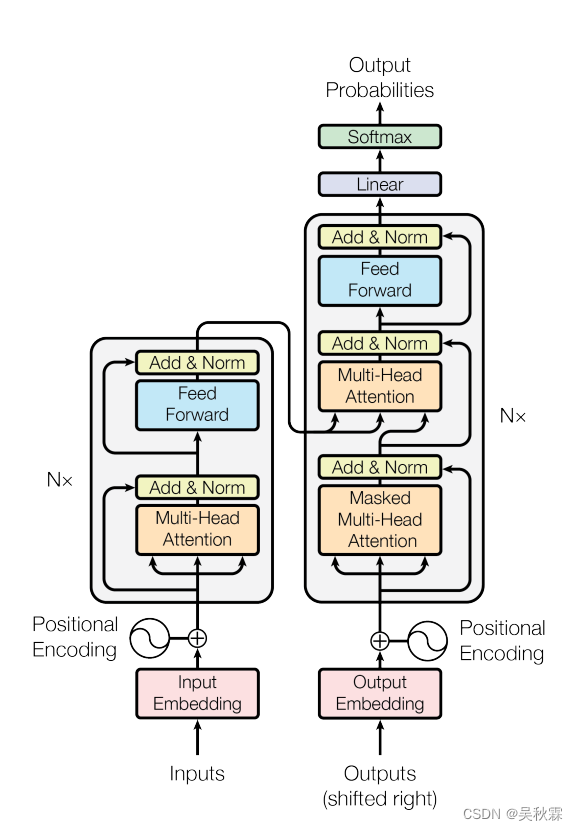
事前トレーニングされた言語モデルは、一般に、基礎となるモデルのネットワーク構造に従って、エンコーダーのみのアーキテクチャ モデル、デコーダーのみのアーキテクチャ モデル、およびエンコーダー-デコーダー アーキテクチャ モデルに分類されます。このうち、エンコーダ アーキテクチャ モデルのみに BERT、RoBerta、Ernie、SpanBert、AlBert などが含まれますが、これらに限定されません。デコーダ アーキテクチャ モデルのみに、GPT、CPM、PaLM、OPT、Bloom、Llama などが含まれますが、これらに限定されません。 ; エンコーダ/デコーダ アーキテクチャ モデルには、Mass、Bart、T5 などが含まれますが、これらに限定されません。
3.ChatGPTの原則
ChatGPT トレーニングの全体プロセスは主に、事前トレーニングと即時学習の段階、結果の評価と報酬モデリングの段階、強化学習の自己進化の段階の 3 つの段階に分かれており、3 つの段階は明確な役割分担を持ち、模倣期、規律期、自律期移行期のモデル
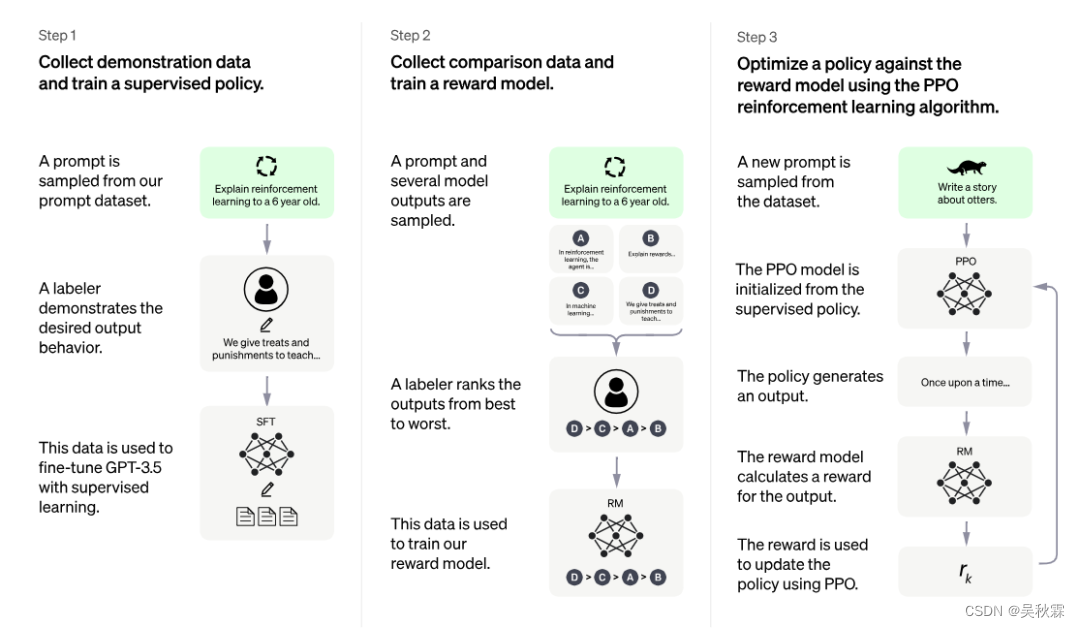
模倣の最初の段階では、モデルはさまざまなコマンドベースのタスクの学習に焦点を当てます. この段階のモデルには自己識別意識はなく、人工的な行動を模倣することに重点が置かれています. 人間のアノテーションの結果を継続的に学習することで、自分自身の行動を作ります. ある程度の知性を持っている。しかし、単なる模倣では、機械の学習動作が幼児化してしまうことがよくあります。
規律期間の第 2 フェーズでは、最適化の内容に方向性が変化し、機械の回答の内容の教育から機械の回答の品質の教育に焦点が変わりました。最初の段階では、マシンが入力 X を使用して出力 Y' を模倣および学習し、Y' を元のラベル付けされた Y と一致させるように努めることに焦点を当てます。次に、第 2 段階では、複数のモデルが X に対して複数の結果 (Y1、Y2、Y3、Y4) を出力したときに、複数の結果の是非を自分で判断できるようになることを期待します。
モデルが一定の判断能力を備えている場合、モデルは学習の第 2 段階を完了し、第 3 段階である自律期に入ることができると考えられます。自律期間では、モデルは左右の相互作用を通じて自己進化を完了する必要があります。つまり、一方では複数の出力結果を自動的に生成し、他方ではさまざまな結果の品質を判断し、評価します。異なる出力の影響に基づいてモデルの差異を把握し、それらを最適化および改善し、プロセスのモデルパラメータを自動的に生成することで、モデルの自己強化学習を完了します。
まとめると、ChatGPT の 3 段階は、人間の成長の 3 段階にたとえることもできます。模倣段階の目的は「自然の原理を知る」ことであり、規律段階の目的は「善悪の区別」です。 」、そして自律段階の目的は「すべてを理解する」ことです。
4. 迅速な学習と大規模なモデル機能の出現
ChatGPT モデルのリリース後、そのスムーズな会話表現、強力なコンテキストの保存、豊富な知識の生成、および包括的に問題を解決する能力により世界中で人気が高まり、人工知能に対する一般の理解を一新しました。プロンプトラーニング、インコンテキストラーニング、思考連鎖 (CoT) などの概念も世間の注目を集めるようになりました。市場には、指定されたタスクのプロンプト テンプレートを作成することを専門とするプロンプト エンジニアと呼ばれる職業もあります。
ほとんどの学者は、ヒント学習は、特徴量エンジニアリング、深層学習、事前トレーニング + 微調整に続く自然言語処理の 4 番目のパラダイムであると考えています。言語モデルのパラメーターが増加し続けるにつれて、コンテキスト学習や思考連鎖などの機能を備えたモデルも登場しました。言語モデルのパラメーターをトレーニングしなくても、わずか数個のパラメータを使用するだけで、多くの自然言語処理タスクでより良い結果を達成することが可能です。デモンストレーション例のスコア
4.1 学習のヒント
プロンプト学習は、追加のプロンプト情報を新しい入力として元の入力テキストに追加し、下流予測タスクを言語モデル タスクに変換し、言語モデルの予測結果を元の下流タスクの予測結果に変換します。
感情分析タスクを例にとると、本来のタスクは、「私は中国が大好きです」という与えられた入力テキストに基づいて、テキストの感情の極性を判断することです。プロンプト学習は、元の入力テキスト「I love China」に追加のプロンプト テンプレートを追加することです (例: 「この文の感情は {マスク}」)。新しい入力テキスト「I love China」が得られます。文は {mask} です。」 次に、言語モデルのマスク言語モデル タスクを使用して {mask} タグを予測し、予測されたトークンを感情極性ラベルにマッピングし、最終的に感情極性予測を達成します。
4.2 状況に応じた学習
コンテキスト学習は、プロンプト学習の特殊なケースとみなすことができます。つまり、デモンストレーション例は、プロンプト学習において手動で作成されたプロンプト テンプレート (離散プロンプト テンプレート) の一部とみなされ、モデル パラメーターは更新されません。
コンテキスト学習の核となる考え方は、類推を通じて学習することです。感情分類タスクでは、まず既存の感情分析サンプル ライブラリからいくつかの肯定的または否定的な感情テキストと対応するラベルを含むいくつかのデモンストレーション例を抽出し、次にデモンストレーション例を分析対象の感情テキストと比較します。大規模な言語モデル; 最後に、実証例への類似性を学習することでテキストの感情的な極性が得られます。
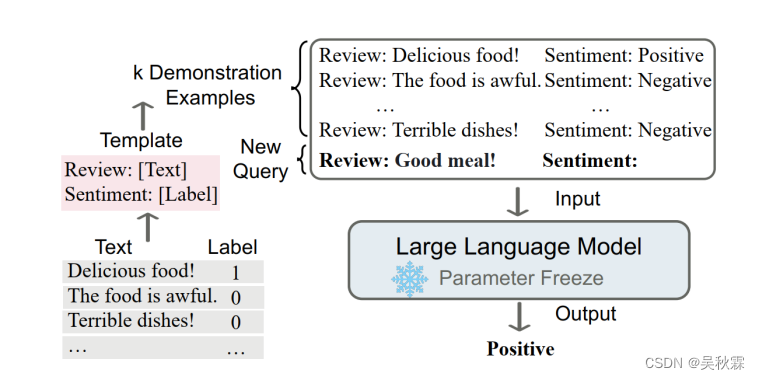
この学習方法は学習後の人間の意思決定プロセスにも近く、ある出来事に対して他の人がどのように対処するかを観察することで、同じ出来事や似たような出来事に遭遇したときに、簡単にうまく解決することができます。
4.3 思考連鎖
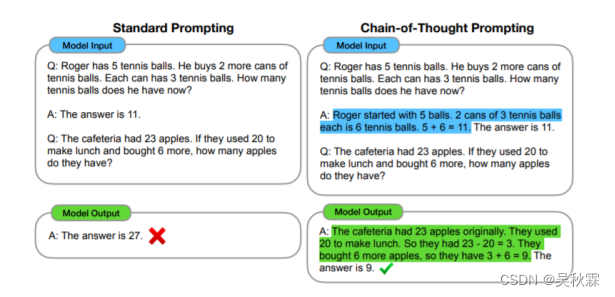
大規模な言語モデルが蔓延する時代において、自然言語処理のパラダイムは完全に変わりました。たとえば感情分析、トピック分類、その他の System-1 タスク (人間が迅速かつ直観的に完了できるタスク) など、モデル パラメーターが増加すると、サンプル数が少なくサンプルがゼロの条件下でも、より良い結果が得られるようになります。しかし、論理的推論、数学的推論、常識的推論などのシステム 2 タスク (人間が完了するためにゆっくりと思慮深く考える必要があるタスク) では、モデル パラメーターが数千億に増加した場合でも、その効果は理想的ではありません。モデルパラメータの数を単に増やすだけでは、パフォーマンスは大幅に向上しません。
Google は、大規模な言語モデルがさまざまな推論タスクを実行する能力を向上させるために、2022 年に思考連鎖 (CoT) の概念を提案しました。思考チェーンは本質的には個別のプロンプト テンプレートです。思考チェーンの主な目的は、プロンプト テンプレートを使用して、大規模な言語モデルが人間の思考プロセスを模倣し、最終的な答えを導き出すための段階的な推論の基礎を提供できるようにすることです。各ステップの推論の基礎は以下で構成されます。 文章の集合が思考連鎖の内容です。
実際、思考チェーンは、大規模な言語モデルが、マルチホップ問題全体を 1 回の順方向パスで解決するのではなく、マルチステップ問題を個別に解決できる複数の中間ステップに分解するのに役立ちます。
5. 業界の参考資料と提案
5.1 変化を受け入れる
AIGC 分野は他の分野とは異なり、現在最も急速に変化している分野の 1 つです。2023年3月13日から2023年3月19日までの1週間を例に挙げると、清華大学がChatGLM 6Bオープンソースモデルをリリースし、openAIがGPT4インターフェースをリリースし、百度文信尼燕が記者会見を開催し、マイクロソフトがOfficeを共同でリリースしたことを経験しました。 ChatGPT: 新製品 Copilot などの一連の主要イベントと組み合わせます。
これらのイベントは業界研究の方向性に影響を与え、より多くの思考を引き起こすでしょう。たとえば、次の技術的ルートはオープンソース モデルに基づくべきか、それとも新しいモデルを最初から事前トレーニングする必要がありますか? いくつのパラメーターを設計する必要がありますか? Copilot の準備は完了しましたが、オフィス プラグイン AIGC のアプリケーション開発者はどのように対応すべきでしょうか?
それでも、実務者は変化を受け入れ、戦略を迅速に調整し、最先端のリソースを使用してタスクの実現を加速することが推奨されます。
5.2 明確な位置決め
アプリケーション層を行うか基本最適化層を行うか、Cエンド市場を行うかBエンド市場を行うか、業界垂直アプリケーションを行うか一般ツールを行うかなど、トラックをセグメント化する目標を明確にする必要があります。ソフトウェア。あまり野心的になりすぎず、チャンスを掴んで「ケーキを正確にカット」しましょう。
ポジショニングを明確にするということは、壁にぶつからない、後戻りしないということではなく、自分自身の目的や意義を理解するということです。
5.3 コンプライアンスと制御性
AIGC の最大の問題点は出力の制御不能であり、この問題が解決できなければ開発が大きなネックとなり、B サイド、C サイド市場での普及が難しくなります。製品設計プロセスでは、ルール エンジンの統合、報酬と罰のメカニズムの強化、および適切な手動介入の方法に注意を払う必要があります。実務者は、AIGC が生成したコンテンツに伴う著作権、倫理的、法的リスクに焦点を当てる必要があります。
5.4 経験の蓄積
経験の蓄積の目的は、自分自身の障壁を確立することです。すべての希望を 1 つのモデルに固定しないでください。たとえば、私たちはかつて ChatGPT とシームレスに統合するためにプレーン テキスト形式で製品を設計しましたが、最新の GPT4 はすでにマルチモーダル入力をサポートしています。私たちは落胆すべきではありませんが、変化を迅速に受け入れ、これまでに蓄積された経験 (データの側面、プロンプトの側面、インタラクションデザインの側面) を活用して、新しいシナリオやインタラクション形式にうまく対応できるように製品のアップグレードを迅速に完了する必要があります。
実践者が上記の提案を参考にしていただければ幸いです。
AIGCの波の下には多くのバブルがありますが、変化を受け入れる決意を持ち、常に到達したい距離を認識し、周囲のリスクと危機に真剣に向き合い、実戦で能力を発揮し続ける限り、私は、いつか、私たちは憧れの目的地に到達できると信じています。
BAT の上級 AI 専門家と大規模モデル技術の専門家によって執筆され、MOSS システムのリーダーである Qiu Xipeng などの多くの専門家によって強く推奨されています。ChatGPTのコア技術、アルゴリズム実装、動作原理、トレーニング方法を体系的に整理、深く分析し、大量のコードとアノテーションを提供します。大規模なモデルを移行してプライベート化する方法を教えるだけでなく、基礎ゼロで独自の ChatGPT を構築する方法も段階的に教えます。

さて、ここで皆さんにお別れの時間です。作成は簡単ではありません。親指を立てて去ってください。皆様のご支援が創作の原動力となっており、より質の高い記事をお届けできればと思っております。