導入
今回の事例では、収集した電力データをもとに各電力設備の電流、電圧、電力を深く掘り下げ、実際の各電力設備の消費電力を分析することで、電力会社が電力エネルギー戦略を立てる際の一定の参考資料となります。詳細については、書籍 **『Python データ マイニング: 高度で実践的な事例分析入門』** を参照してください。

1 案例背景
電気機器のエネルギー消費をより適切に監視するために、電力サブメーター技術が誕生しました。電力サブメーターは、電力会社にとって、電力負荷を正確に予測し、送電網の配電計画を科学的に策定し、電力システムの安定性と信頼性を向上させるために非常に重要です。ユーザーにとって、電力サブメーターは、電気機器の使用状況を把握し、ユーザーの省エネ意識を向上させ、電気の科学的かつ合理的な使用を促進するのに役立ちます。
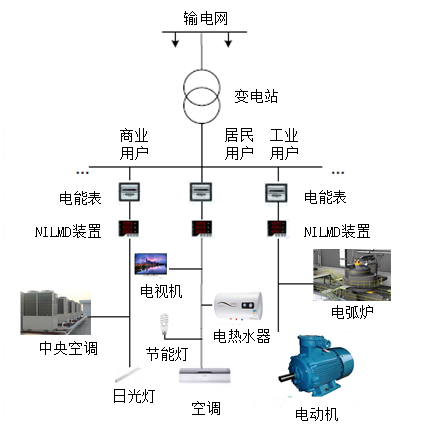
2 分析目标
非侵入型負荷検出および分解のための電力データ マイニングの背景とビジネス要件に基づいて、この場合に達成すべき目標は次のとおりです。
Ø各電気機器の動作属性を分析します。
Øデバイス識別属性ライブラリを構築します。
ØK最近傍モデルを使用して、ライン全体から各電気機器の独立した電力消費データを「分解」します。
3 分析过程
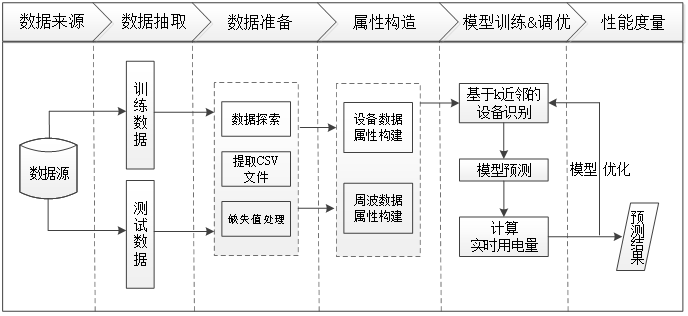
4 数据准备
1. データ探索
今回の電力データマイニングの解析には、稼働記録データは関与しません。したがって、主に機器データ、サイクルデータ、高調波データがここで取得されます。データを取得した後、データテーブルが多数あり、各テーブルに多くの属性があるため、データのデータ探索と分析を実行する必要があります。データ探索のプロセスでは、主に元のデータの特徴に基づいて、各デバイスのさまざまな属性に対応するデータが可視化され、得られた結果の一部が図 1 ~ 3 に示されています。
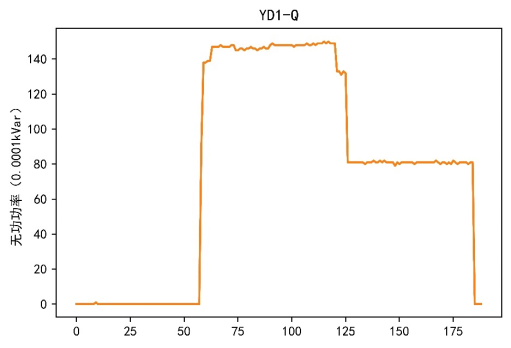
図1 無効電力と総無効電力
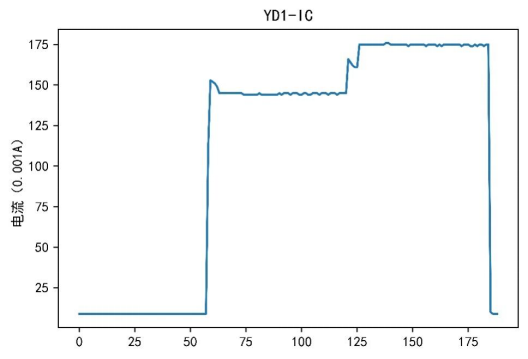
図 2 電流トレース
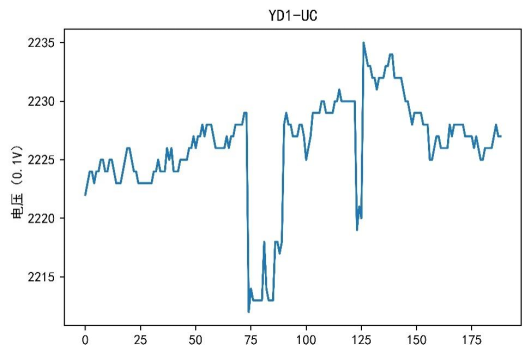
図 3 電圧トレース
視覚化の結果に基づいて、電流、電圧、電力の特性がデバイスごとに異なることがわかります。
データ属性の視覚化をコード リスト 1 に示します。
コード リスト 1 データ属性の視覚化
パンダをPDとしてインポートする matplotlib.pyplotをpltとしてインポート 私たちを輸入してください
filename = os.listdir('../data/attachment 1') # フォルダー内のすべてのファイルの名前を取得します n_ファイル名 = len(ファイル名) # 各機器のデータに動作情報を追加し、各属性の軌跡図を描画して保存 デフォルトの楽しみ(a): save_name = ['YD1', 'YD10', 'YD11', 'YD2', 'YD3', � 39;YD4'、 「YD5」、「YD6」、「YD7」、「YD8」、「YD9」] plt.rcParams['font.sans-serif'] = ['SimHei'] # 中国語ラベルを通常に表示するために使用されます plt.rcParams['axes.unicode_minus'] = False # 負の符号を通常どおり表示するために使用されます 範囲(a)のiの場合: Sb = pd.read_excel('../data/attachment1/' + ファイル名[i], 'デバイスデータ',index_col = None)
Zb = pd.read_excel('../data/attachment1/' + ファイル名[i], 'サイクルデータ',index_col = None) # 電流トレース図 plt.plot(Sb['IC']) plt.title(save_name[i] + '-IC') plt.ylabel('電流 (0.001A)') plt.show() # 電圧トレース図 lt.plot(Sb['UC']) plt.title(save_name[i] + '-UC') plt.ylabel('電圧 (0.1V)') plt.show() # 有効電力と合計有効電力 plt.plot(Sb[['PC', 'P']]) plt.title(save_name[i] + '-P') plt.ylabel('有効電力 (0.0001kW)') plt.show() #無効電力と合計無効電力 plt.plot(Sb[['QC', 'Q']]) plt.title(save_name[i] + '-Q') plt.ylabel('無効電力 (0.0001kVar)') plt.show() # 力率と総力率 plt.plot(Sb[['PFC', 'PF']]) plt.title(save_name[i] + '-PF') plt.ylabel('力率 (%)') plt.show() # 高調波電圧 plt.plot(Xb.loc[:, 'UC02':].T) plt.title(save_name[i] + '-高調波電圧') plt.show() # 週次データ plt.plot(Zb.loc[:, 'IC001':].T) plt.title(save_name[i] + '-サイクルデータ') plt.show()
楽しい(n_ファイル名) |
2. 欠損値の処理
データ探索を通じて、データ内の一部の「時間」属性に欠損値があることが判明し、これらの欠損値を処理する必要があります。各データの「時刻」属性の欠落期間が異なるため、異なる処理が必要となる。各デバイスデータのうち欠損時間が大きいデータは削除され、欠損時間が小さいデータは以前の値を使用して補完されます。
欠損値を処理する前に、学習データの全設備データに設備データテーブル、サイクルデータテーブル、高調波データテーブル、稼働記録テーブルを追加するとともに、全設備データに設備データテーブル、サイクルデータテーブルを追加する必要があります。テスト データ内のデータ テーブルと高調波データ テーブルが独立したデータ ファイルとして抽出され、生成されたファイルの一部が図 4 に示されています。
図 4 データ ファイルの抽出結果の一部
コード リスト 2 に示すように、データ ファイルを抽出します。
コード リスト 2 データ ファイルの抽出
#xlsxファイルをCSVファイルに変換 グロブをインポートする パンダをPDとしてインポートする 数学をインポート
def file_transform(xls): Print('合計 %s xlsx ファイルが見つかりました' % len(glob.glob(xls))) print('正在处理............') for file in glob.glob(xls): # 循环读取同文件夹下的xlsx文件 combine1 = pd.read_excel(file, index_col=0, sheet_name=None) for key in combine1: combine1[key].to_csv('../tmp/' + file[8: -5] + key + '.csv', encoding='utf-8') print('处理完成')
xls_list = ['../data/附件1/*.xlsx', '../data/附件2/*.xlsx'] file_transform(xls_list[0]) # 处理训练数据 file_transform(xls_list[1]) # 处理测试数据 |
提取数据文件完成后,对提取的数据文件进行缺失值处理,处理后生成的部分文件如图5所示。
图5 缺失值处理后的部分结果
缺失值处理如代码清单3所示。
代码清单3 缺失值处理
# 对每个数据文件中较大缺失时间点数据进行删除处理,较小缺失时间点数据进行前值替补 def missing_data(evi): print('共发现%s个CSV文件' % len(glob.glob(evi))) for j in glob.glob(evi): fr = pd.read_csv(j, header=0, encoding='gbk') fr['time'] = pd.to_datetime(fr['time']) helper = pd.DataFrame({'time': pd.date_range(fr['time'].min(), fr['time'].max(), freq='S')}) fr = pd.merge(fr, helper, on='time', how='outer').sort_values('time') fr = fr.reset_index(drop=True)
frame = pd.DataFrame() for g in range(0, len(list(fr['time'])) - 1): if math.isnan(fr.iloc[:, 1][g + 1]) and math.isnan(fr.iloc[:, 1][g]): continue else: scop = pd.Series(fr.loc[g]) frame = pd.concat([frame, scop], axis=1) frame = pd.DataFrame(frame.values.T, index=frame.columns, columns=frame.index) frames = frame.fillna(method='ffill') frames.to_csv(j[:-4] + '1.csv', index=False, encoding='utf-8') print('处理完成')
evi_list = ['../tmp/附件1/*数据.csv', '../tmp/附件2/*数据.csv'] missing_data(evi_list[0]) # 处理训练数据 missing_data(evi_list[1]) # 处理测试数据 |
5 属性构造
虽然在数据准备过程中对属性进行了初步处理,但是引入的属性太多,而且这些属性之间存在重复的信息。为了保留重要的属性,建立精确、简单的模型,需要对原始属性进一步筛选与构造。
- 设备数据
在数据探索过程中发现,不同设备的无功功率、总无功功率、有功功率、总有功功率、功率因数和总功率因数差别很大,具有较高的区分度,故本案例选择无功功率、总无功功率、有功功率、总有功功率、功率因数和总功率因数作为设备数据的属性构建判别属性库。
处理好缺失值后,每个设备的数据都由一张表变为了多张表,所以需要将相同类型的数据表合并到一张表中,如将所有设备的设备数据表合并到一张表当中。同时,因为缺失值处理的其中一种方式是使用前一个值进行插补,所以产生了相同的记录,需要对重复出现的记录进行处理,处理后生成的数据表如表1所示。
表1 合并且去重后的设备数据
time |
IC |
UC |
PC |
QC |
PFC |
P |
Q |
PF |
label |
2018/1/27 17:11 |
33 |
2212 |
10 |
65 |
137 |
10 |
65 |
137 |
0 |
2018/1/27 17:11 |
33 |
2212 |
10 |
66 |
143 |
10 |
66 |
143 |
0 |
2018/1/27 17:11 |
33 |
2213 |
10 |
65 |
143 |
10 |
65 |
143 |
0 |
2018/1/27 17:11 |
33 |
2211 |
10 |
66 |
135 |
10 |
66 |
135 |
0 |
2018/1/27 17:11 |
33 |
2211 |
10 |
66 |
141 |
10 |
66 |
141 |
0 |
…… |
…… |
…… |
…… |
…… |
…… |
…… |
…… |
…… |
…… |
合并且去重设备数据如代码清单4所示。
代码清单4 合并且去重设备数据
import glob import pandas as pd import os
# 合并11个设备数据及处理合并中重复的数据 def combined_equipment(csv_name): # 合并 print('共发现%s个CSV文件' % len(glob.glob(csv_name))) print('正在处理............') for i in glob.glob(csv_name): # 循环读取同文件夹下的CSV文件 fr = open(i, 'rb').read() file_path = os.path.split(i) with open(file_path[0] + '/device_combine.csv', 'ab') as f: f.write(fr) print('合并完毕!') # 去重 df = pd.read_csv(file_path[0] + '/device_combine.csv', header=None, encoding='utf-8') datalist = df.drop_duplicates() datalist.to_csv(file_path[0] + '/device_combine.csv', index=False, header=0) print('去重完成')
csv_list = ['../tmp/附件1/*设备数据1.csv', '../tmp/附件2/*设备数据1.csv'] combined_equipment(csv_list[0]) # 处理训练数据 combined_equipment(csv_list[1]) # 处理测试数据 |
- 周波数据
在数据探索过程中发现,周波数据中的电流随着时间的变化有较大的起伏,不同设备的周波数据中的电流绘制出来的折线图的起伏不尽相同,具有明显的差异,故本案例选择波峰和波谷作为周波数据的属性构建判别属性库。
由于原始的周波数据中并未存在电流的波峰和波谷两个属性,所以需要进行属性构建,构建生成的数据表如表2所示。
表2 构建周波数据中的属性生成的数据
波谷 |
波峰 |
344 |
1666365 |
362 |
1666324 |
301 |
1666325 |
314 |
1666392 |
254 |
1666435 |
…… |
…… |
构建周波数据中的属性代码如代码清单5所示。
代码清单5 构建周波数据中的属性
# 求取周波数据中电流的波峰和波谷作为属性参数 import glob import pandas as pd from sklearn.cluster import KMeans import os
def cycle(cycle_file): for file in glob.glob(cycle_file): cycle_YD = pd.read_csv(file, header=0, encoding='utf-8') cycle_YD1 = cycle_YD.iloc[:, 0:128] models = [] for types in range(0, len(cycle_YD1)): model = KMeans(n_clusters=2, random_state=10) model.fit(pd.DataFrame(cycle_YD1.iloc[types, 1:])) # 除时间以外的所有列 models.append(model)
# 相同状态间平稳求均值 mean = pd.DataFrame() for model in models: r = pd.DataFrame(model.cluster_centers_, ) # 找出聚类中心 r = r.sort_values(axis=0, ascending=True, by=[0]) mean = pd.concat([mean, r.reset_index(drop=True)], axis=1) mean = pd.DataFrame(mean.values.T, index=mean.columns, columns=mean.index) mean.columns = ['波谷', '波峰'] mean.index = list(cycle_YD['time']) mean.to_csv(file[:-9] + '波谷波峰.csv', index=False, encoding='gbk ')
cycle_file = ['../tmp/附件1/*周波数据1.csv', '../tmp/附件2/*周波数据1.csv'] cycle(cycle_file[0]) # 处理训练数据 cycle(cycle_file[1]) # 处理测试数据
# 合并周波的波峰波谷文件 def merge_cycle(cycles_file): means = pd.DataFrame() for files in glob.glob(cycles_file): mean0 = pd.read_csv(files, header=0, encoding='gbk') means = pd.concat([means, mean0]) file_path = os.path.split(glob.glob(cycles_file)[0]) means.to_csv(file_path[0] + '/zuhe.csv', index=False, encoding='gbk') print('合并完成')
cycles_file = ['../tmp/附件1/*波谷波峰.csv', '../tmp/附件2/*波谷波峰.csv'] merge_cycle(cycles_file[0]) # 训练数据 merge_cycle(cycles_file[1]) # 测试数据 |
6 模型训练
在判别设备种类时,选择K最近邻模型进行判别,利用属性构建而成的属性库训练模型,然后利用训练好的模型对设备1和设备2进行判别。构建判别模型并对设备种类进行判别,如代码清单6所示。
代码清单6 建立判别模型并对设备种类进行判别
import glob import pandas as pd from sklearn import neighbors import pickle import os
# 模型训练 def model(test_files, test_devices): # 训练集 zuhe = pd.read_csv('../tmp/附件1/zuhe.csv', header=0, encoding='gbk') device_combine = pd.read_csv('../tmp/附件1/device_combine.csv', header=0, encoding='gbk') train = pd.concat([zuhe, device_combine], axis=1) train.index = train['time'].tolist() # 把“time”列设为索引 train = train.drop(['PC', 'QC', 'PFC', 'time'], axis=1) train.to_csv('../tmp/' + 'train.csv', index=False, encoding='gbk') # 测试集 for test_file, test_device in zip(test_files, test_devices): test_bofeng = pd.read_csv(test_file, header=0, encoding='gbk') test_device = pd.read_csv(test_device, ヘッダー=0, エンコーディング='gbk') test = pd.concat([test_bofeng, test_devi], axis=1) test.index = test['time'].tolist() # 「time」列をインデックスとして設定します test = test.drop(['PC', 'QC', 'PFC', 'time'], axis=1)
# K最近邻 clf = neighbors.KNeighborsClassifier(n_neighbors=6, アルゴリズム='auto') clf.fit(train.drop(['label'], axis=1), train['label']) 予測 = clf.predict(test.drop(['label'], axis=1)) 予測 = pd.DataFrame(予測) ファイルパス = os.path.split(テストファイル)[1] test.to_csv('../tmp/' + file_path[:3] + 'test.csv'、エンコーディング='gbk') predicted.to_csv('../tmp/' + file_path[:3] + 'predicted.csv'、index=False、エンコーディング='gbk') open('../tmp/' + file_path[:3] + 'model.pkl', 'ab') を pickle_file として使用します: pickle.dump(clf, pickle_file) 印刷(clf)
model(glob.glob('../tmp/attachment 2/*谷とピーク.csv'), glob.glob('../tmp/attachment2/*devicedata1.csv')) |
7 性能度量
コードリスト 6 のデバイス識別結果に基づいてモデルを評価した結果は、混同行列を図 7 に、ROC 曲線を図 8 に示します。
模型分类准确度: 0.7951219512195122
模型评估报告:
precision recall f1-score support
0.0 1.00 0.84 0.92 64
21.0 0.00 0.00 0.00 0
61.0 0.00 0.00 0.00 0
91.0 0.78 0.84 0.81 77
92.0 0.00 0.00 0.00 5
93.0 0.76 0.75 0.75 59
111.0 0.00 0.00 0.00 0
accuracy 0.80 205
macro avg 0.36 0.35 0.35 205
weighted avg 0.82 0.80 0.81 205
计算auc:0.8682926829268293
注: ここでの結果の一部は省略されています。
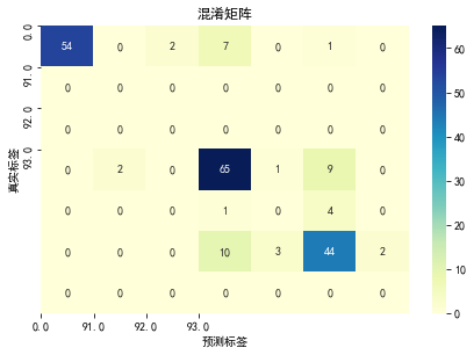
図 7 混同マトリックス
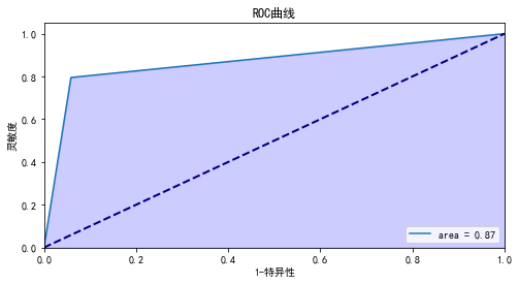
図8 ROC曲線
モデルの評価をコード リスト 7 に示します。
コード リスト 7 モデルの評価
import glob
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn import metrics
from sklearn.preprocessing import label_binarize
import os
import pickle
# 模型评估
def model_evaluation(model_file, test_csv, predicted_csv):
for clf, test, predicted in zip(model_file, test_csv, predicted_csv):
with open(clf, 'rb') as pickle_file:
clf = pickle.load(pickle_file)
test = pd.read_csv(test, header=0, encoding='gbk')
predicted = pd.read_csv(predicted, header=0, encoding='gbk')
test.columns = ['time', '波谷', '波峰', 'IC', 'UC', 'P', 'Q', 'PF', 'label']
print('模型分类准确度:', clf.score(test.drop(['label', 'time'], axis=1), test['label']))
print('模型评估报告:\n', metrics.classification_report(test['label'], predicted))
confusion_matrix0 = metrics.confusion_matrix(test['label'], predicted)
confusion_matrix = pd.DataFrame(confusion_matrix0)
class_names = list(set(test['label']))
tick_marks = range(len(class_names))
sns.heatmap(confusion_matrix, annot=True, cmap='YlGnBu', fmt='g')
plt.xticks(tick_marks, class_names)
plt.yticks(tick_marks, class_names)
plt.tight_layout()
plt.title('混淆矩阵')
plt.ylabel('真实标签')
plt.xlabel('预测标签')
plt.show()
y_binarize = label_binarize(test['label'], classes=class_names)
predicted = label_binarize(predicted, classes=class_names)
fpr, tpr, thresholds = metrics.roc_curve(y_binarize.ravel(), predicted.ravel())
auc = metrics.auc(fpr, tpr)
print('计算auc:', auc)
# 绘图
plt.figure(figsize=(8, 4))
lw = 2
plt.plot(fpr, tpr, label='area = %0.2f' % auc)
plt.plot([0, 1], [0, 1], color='navy', lw=lw, linestyle='--')
plt.fill_between(fpr, tpr, alpha=0.2, color='b')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('1-特异性')
plt.ylabel('灵敏度')
plt.title('ROC曲线')
plt.legend(loc='lower right')
plt.show()
model_evaluation(glob.glob('../tmp/*model.pkl'),
glob.glob('../tmp/*test.csv'),
glob.glob('../tmp/*predicted.csv'))
分析目的に応じて、リアルタイムの消費電力を計算する必要があります。リアルタイム消費電力は、瞬時電流、電圧、時間の積として計算され、計算式は次のようになります。
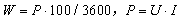
このうちリアルタイム消費電力は0.001kWhです。は電力、単位は W です。
リアルタイム消費電力を計算し、得られたリアルタイム消費電力を表 3 に示します。
表 3 リアルタイム消費電力

コード リスト 8 に示すように、リアルタイムの消費電力を計算します。
コード リスト 8 リアルタイムの消費電力を計算する
# 计算实时用电量并输出状态表
def cw(test_csv, predicted_csv, test_devices):
for test, predicted, test_device in zip(test_csv, predicted_csv, test_devices):
# 划分预测出的时刻表
test = pd.read_csv(test, header=0, encoding='gbk')
test.columns = ['time', '波谷', '波峰', 'IC', 'UC', 'P', 'Q', 'PF', 'label']
test['time'] = pd.to_datetime(test['time'])
test.index = test['time']
predicteds = pd.read_csv(predicted, header=0, encoding='gbk')
predicteds.columns = ['label']
indexes = []
class_names = list(set(test['label']))
for j in class_names:
index = list(predicteds.index[predicteds['label'] == j])
indexes.append(index)
# 取出首位序号及时间点
from itertools import groupby # 连续数字
dif_indexs = []
time_indexes = []
info_lists = pd.DataFrame()
for y, z in zip(indexes, class_names):
dif_index = []
fun = lambda x: x[1] - x[0]
for k, g in groupby(enumerate(y), fun):
dif_list = [j for i, j in g] # 连续数字的列表
if len(dif_list) > 1:
scop = min(dif_list) # 选取连续数字范围中的第一个
else:
scop = dif_list[0 ]
dif_index.append(scop)
time_index = list(test.iloc[dif_index, :].index)
time_indexes.append(time_index)
info_list = pd.DataFrame({
'时间': time_index, 'model_设备状态': [z] * len(time_index)})
dif_indexs.append(dif_index)
info_lists = pd.concat([info_lists, info_list])
# 计算实时用电量并保存状态表
test_devi = pd.read_csv(test_device, header=0, encoding='gbk')
test_devi['time'] = pd.to_datetime(test_devi['time'])
test_devi['实时用电量'] = test_devi['P'] * 100 / 3600
info_lists = info_lists.merge(test_devi[['time', '实时用电量']],
how='inner', left_on='时间', right_on='time')
info_lists = info_lists.sort_values(by=['时间'], ascending=True)
info_lists = info_lists.drop(['time'], axis=1)
file_path = os.path.split(test_device)[1]
info_lists.to_csv('../tmp/' + file_path[:3] + '状态表.csv', index=False, encoding='gbk')
print(info_lists)
cw(glob.glob('../tmp/*test.csv'),
glob.glob('../tmp/*predicted.csv'),
glob.glob('../tmp/附件2/*设备数据1.csv'))
8 推荐阅读

本物のリンク: https://item.jd.com/13814157.html
**「Python データ マイニング: 入門、高度で実践的なケース分析」** は、実際のプロジェクトの事例を基にしたデータ マイニングの本で、Python プログラミングの基礎やデータ マイニングの基礎を持たない読者が Python データを迅速にマスターするのに役立ちます。 、プロセスと方法。文体としては、従来の「理論と実践を組み合わせた」入門書とは異なり、データマイニング分野で有名なイベント「テディカップ」データマイニングチャレンジ(2018年から開催されている)を取り上げています。 10年以上)と「テディカップ」のデータ分析により、これまで5回開催された技能競技大会(1,500以上の大学から10万人以上の教員・学生が参加)をもとに、古典競技問題11問を厳選し、 Python プログラミングの知識、データ マイニングの知識、業界の知識を統合し、読者が電子商取引、教育、運輸、メディア、電力、観光、製造を含む 7 つの主要業界のデータ マイニング手法を実際に素早く習得できるようにします。
この本は、基礎知識がゼロの読者による自習だけでなく、教師による指導にも適しています。読者がこの本の内容をより効率的に習得できるように、この本では次の 10 の追加事項が提供されています。値:
(1) モデリング プラットフォーム: 構成が不要で、多数のケース プロジェクトが含まれるワンストップのビッグ データ マイニング モデリング プラットフォームを提供します。練習しながら学習でき、紙で話す必要はありません< a i=3>(2) ビデオ説明: 600 分以上の Python プログラミングとデータ マイニング関連の教育ビデオを提供します。 、見ながら学び、すぐに経験値を獲得できます(3) 選択された演習: 60 以上のデータ マイニング演習を慎重に選択し、詳細な回答を提供します。知識の盲点を確認しながら練習(4) 著者 Q&A: 学習プロセス中に質問がある場合は、「Tree Hole」アプレットを使用して、紙の本の写真を撮り、ワンクリックで著者に送信します。質問しながら学習でき、半分の労力で 2 倍の結果が得られます。 a> **(5) データ ファイル: **各ケースにデータ ファイルを提供し、エンジニアリングの実践と組み合わせて、すぐに使用できるようにして実用性を高めます。 ** (6) プログラム コード: ** 書籍内のコードの電子ファイルを提供します。および関連ツールのインストール パッケージ。コードはプラットフォームにインポートして実行でき、学習効果はすぐに現れます。 ** (7) コースウェアの指導:* *サポートする PPT コースウェアを提供します。この本を教材として使用すると、レッスンの準備時間を節約できます。 **(8) モデル サービス: **10 個以上のデータ マイニング モデル、モデルを提供します。完全なケース実装プロセスを提供します。データ マイニングの実践能力の向上に役立ちます **(9) 教育プラットフォーム: **Teddy Technology は、本書で提供される追加リソースに対して、詳細な操作ガイドを備えたワンストップのデータベースの教育プラットフォームを提供します。 、見ながら学び、練習し、 時間を節約します **(10) 就職推薦: **多数の就職推薦の機会を提供し、ファーウェイ、有名企業を含む 1500 以上の企業と協力します。 JD.com や美的など
この本を学ぶことで、読者はデータ マイニングの原理を理解し、ビッグ データ テクノロジの関連操作を迅速に習得し、その後のデータ分析、データ マイニング、ディープ ラーニングの実践と競技のための優れた技術的基盤を築くことができます。

9 参加方法
- 今回は2冊プレゼントします
- 活動期間:2023-11-2まで
- 参加方法: ブロガーをフォローし、好きなように「いいね!」を集め、コメントを集めます。
追記: 20 単語を超えるコメントは、コメント内の「いいね!」の数に基づいて選択されます< /span> - 読書量が2,000冊を超えた場合は1冊追加(読書量に応じて最後の1冊を配布します。読書量が基準に満たない場合は実際の量に応じて配布します)< /span>
追記: 勝者リストイベント終了後のファンベースとコメントエリア発表