前回の記事のコードは正常にデバッグおよび実行できませんでした。また、前回の記事のコードは非常に高い計算能力を必要とし、間違いなく私にはあまり適していなかったので、以前に読んだ STTran の論文を探しました。コードは、まずコードの一部を解釈します。間違いがあれば批判して修正してください。学習記録のみに使用します。その後、実験結果の分析とエラー特定部分の視覚的な分析に焦点を当てます。推奨描画ツールは Graphviz です (論文の著者はその使用を推奨していますが、私はそれがどれほど効果的であるかをまだ試していません)。
この記事のデータセットは Action Genome を使用しています。まず AG データセットの構造を見てみましょう。

AG データ セット内のアノテーションは、主に次の用途に (アノテーション ファイルとして) あります。
1. 検出およびセグメンテーションタスク用に地域の注釈情報を提供します。AG データセットは、人体、車両、動物など、各画像の主要領域に注釈を付けます。これらの領域アノテーション情報は、検出モデルと画像セグメンテーション モデルをトレーニングするために使用できます。
2. 分類タスクのターゲット カテゴリ ラベルを提供します。AG データセットは、人物、車、鳥など、各画像の主要なターゲット カテゴリに注釈を付けます。これらのクラス ラベルは、画像分類モデルをトレーニングするために使用できます。
3. 姿勢推定および動作分析タスクのための重要なポイントの注釈情報を提供します。AG データセットは、頭、肩、肘、手、腰、膝、足の位置など、人体の重要なポイントに注釈を付けます。これらのキーポイントアノテーション情報は、姿勢推定モデルや人間行動分析モデルの学習に使用できます。
4. 対象オブジェクトの属性情報を記述する属性タグを付与します。AG データセットには、性別、眼鏡、年齢層などのターゲットの属性に注釈が付けられます。これらの属性ラベルを使用して、属性分類モデルをトレーニングできます。
5. ターゲット オブジェクト間の空間関係を説明する関係ラベルを提供します。AG データ セットは、人と車との間の空間的関係 (向かい合っている、近づいている、遠く離れているなど) に注釈を付けます。これらの関係ラベルは、ターゲットの関係理解モデルをトレーニングするために使用できます。
6. 方向ラベル、オクルージョン ラベル、動作ラベルなどの他の注釈は、他の視覚タスクに使用されます。

ビデオ: オリジナルビデオ
フレーム:ビデオ サンプリング フレーム
次に、データセットをロードするためのコードの一部を説明します。
import torch
from PIL import Image
from torch.utils.data import Dataset
from torchvision.transforms import Resize, Compose, ToTensor, Normalize
import random
from scipy.misc import imread
import numpy as np
import pickle
import os
from fasterRCNN.lib.model.utils.blob import prep_im_for_blob, im_list_to_blob
#AG类,用来处理数据集,方便后续加载
class AG(Dataset):
def __init__(self, mode, datasize, data_path=None, filter_nonperson_box_frame=True, filter_small_box=False):
root_path = data_path
self.frames_path = os.path.join(root_path, 'frames/')
# collect the object classes,读取annotations的注释文件,获取物体类别
self.object_classes = ['__background__']
with open(os.path.join(root_path, 'annotations/object_classes.txt'), 'r') as f:
for line in f.readlines():
line = line.strip('\n')
self.object_classes.append(line)
f.close()
#AG数据集annotations里的一些物体类名使用多个单词,如cupglassbottle
#表示一个泛类。如cupglassbottle表示一个泛类“容器”,包含杯子、玻璃杯和瓶子等。
#使用一个泛类可以在一定程度上减少类别数,使得分类任务更简单
#表示视觉上相似的类,如cupglassbottle中的杯子、玻璃杯和瓶子在视觉上具有较高的相似度,容易产生混淆,所以将它们归为一个泛类。
#这也可以看作是一种应对类间混淆的策略
self.object_classes[9] = 'closet/cabinet'
self.object_classes[11] = 'cup/glass/bottle'
self.object_classes[23] = 'paper/notebook'
self.object_classes[24] = 'phone/camera'
self.object_classes[31] = 'sofa/couch'
# collect relationship classes,同上,获取关系类别
self.relationship_classes = []
with open(os.path.join(root_path, 'annotations/relationship_classes.txt'), 'r') as f:
for line in f.readlines():
line = line.strip('\n')
self.relationship_classes.append(line)
f.close()
#此处和上面差不多,表示语义的细粒度和层次关系,其余的不赋值因为其仅由一个单词构成
self.relationship_classes[0] = 'looking_at'
self.relationship_classes[1] = 'not_looking_at'
self.relationship_classes[5] = 'in_front_of'
self.relationship_classes[7] = 'on_the_side_of'
self.relationship_classes[10] = 'covered_by'
self.relationship_classes[11] = 'drinking_from'
self.relationship_classes[13] = 'have_it_on_the_back'
self.relationship_classes[15] = 'leaning_on'
self.relationship_classes[16] = 'lying_on'
self.relationship_classes[17] = 'not_contacting'
self.relationship_classes[18] = 'other_relationship'
self.relationship_classes[19] = 'sitting_on'
self.relationship_classes[20] = 'standing_on'
self.relationship_classes[25] = 'writing_on'
#分别表示,注意力关系,描述目标的视觉注意力方向
#空间位置关系,描述目标之间的空间配置和位置关系
#表示逻辑关系,描述两个目标之间的逻辑相关性和语义连接
self.attention_relationships = self.relationship_classes[0:3]
self.spatial_relationships = self.relationship_classes[3:9]
self.contacting_relationships = self.relationship_classes[9:]
print('-------loading annotations---------slowly-----------')
#filter small box
if filter_small_box:
with open(root_path + 'annotations/person_bbox.pkl', 'rb') as f:
person_bbox = pickle.load(f)
f.close()
with open('dataloader/object_bbox_and_relationship_filtersmall.pkl', 'rb') as f:
object_bbox = pickle.load(f)
else:
with open(root_path + 'annotations/person_bbox.pkl', 'rb') as f:
person_bbox = pickle.load(f)
f.close()
with open(root_path+'annotations/object_bbox_and_relationship.pkl', 'rb') as f:
object_bbox = pickle.load(f)
f.close()
print('--------------------finish!-------------------------')
#if true:则随机选择80000个样本
if datasize == 'mini':
small_person = {}
small_object = {}
for i in list(person_bbox.keys())[:80000]:
small_person[i] = person_bbox[i]
small_object[i] = object_bbox[i]
person_bbox = small_person
object_bbox = small_object
# collect valid frames,获取有效帧
video_dict = {}
for i in person_bbox.keys():
if object_bbox[i][0]['metadata']['set'] == mode: #train or testing?
frame_valid = False
for j in object_bbox[i]: # the frame is valid if there is visible bbox
if j['visible']:
frame_valid = True
if frame_valid:
video_name, frame_num = i.split('/')
if video_name in video_dict.keys():
video_dict[video_name].append(i)
else:
video_dict[video_name] = [i]
self.video_list = []
self.video_size = [] # (w,h)
self.gt_annotations = []
self.non_gt_human_nums = 0
self.non_heatmap_nums = 0
self.non_person_video = 0
self.one_frame_video = 0
self.valid_nums = 0
'''
filter_nonperson_box_frame = True (default): according to the stanford method, remove the frames without person box both for training and testing
filter_nonperson_box_frame = False: still use the frames without person box, FasterRCNN may find the person
'''
for i in video_dict.keys():
video = []
gt_annotation_video = []
for j in video_dict[i]:
if filter_nonperson_box_frame:
if person_bbox[j]['bbox'].shape[0] == 0:
self.non_gt_human_nums += 1
continue
else:
video.append(j)
self.valid_nums += 1
#当视频或者帧中没有人或者视频只包含一帧图片时,删除对应的视频和帧
gt_annotation_frame = [{'person_bbox': person_bbox[j]['bbox']}]
# each frames's objects and human
for k in object_bbox[j]:
if k['visible']:
assert k['bbox'] != None, 'warning! The object is visible without bbox'
k['class'] = self.object_classes.index(k['class'])
k['bbox'] = np.array([k['bbox'][0], k['bbox'][1], k['bbox'][0]+k['bbox'][2], k['bbox'][1]+k['bbox'][3]]) # from xywh to xyxy
k['attention_relationship'] = torch.tensor([self.attention_relationships.index(r) for r in k['attention_relationship']], dtype=torch.long)
k['spatial_relationship'] = torch.tensor([self.spatial_relationships.index(r) for r in k['spatial_relationship']], dtype=torch.long)
k['contacting_relationship'] = torch.tensor([self.contacting_relationships.index(r) for r in k['contacting_relationship']], dtype=torch.long)
gt_annotation_frame.append(k)
gt_annotation_video.append(gt_annotation_frame)
if len(video) > 2:
self.video_list.append(video)
self.video_size.append(person_bbox[j]['bbox_size'])
self.gt_annotations.append(gt_annotation_video)
elif len(video) == 1:
self.one_frame_video += 1
else:
self.non_person_video += 1
print('x'*60)
if filter_nonperson_box_frame:
print('There are {} videos and {} valid frames'.format(len(self.video_list), self.valid_nums))
print('{} videos are invalid (no person), remove them'.format(self.non_person_video))
print('{} videos are invalid (only one frame), remove them'.format(self.one_frame_video))
print('{} frames have no human bbox in GT, remove them!'.format(self.non_gt_human_nums))
else:
print('There are {} videos and {} valid frames'.format(len(self.video_list), self.valid_nums))
print('{} frames have no human bbox in GT'.format(self.non_gt_human_nums))
print('Removed {} of them without joint heatmaps which means FasterRCNN also cannot find the human'.format(non_heatmap_nums))
print('x' * 60)
'''
实现了对视频序列数据的读取、预处理和包装,将其转换为用于训练的PyTorch数据样本,包括图像输入、图像信息、目标框和目标框数这4个部分
'''
def __getitem__(self, index):
frame_names = self.video_list[index]
processed_ims = []
im_scales = []
'''
这部分将一段视频帧图片读取为向量,返回的相关向量的维度如下:
im(单张图片)= (w,h,颜色通道)
img_tensor(一段视频) = (num of image,w,h,颜色通道)
im_info = (num of image,颜色通道)
gt_boxes(ground truth零向量) = (num of image,1,5)
num_boxes = = (num of image,)
index = num of image
'''
for idx, name in enumerate(frame_names):
im = imread(os.path.join(self.frames_path, name)) # channel h,w,3
im = im[:, :, ::-1] # rgb -> bgr
im, im_scale = prep_im_for_blob(im, [[[102.9801, 115.9465, 122.7717]]], 600, 1000) #cfg.PIXEL_MEANS, target_size, cfg.TRAIN.MAX_SIZE
im_scales.append(im_scale)
processed_ims.append(im)
blob = im_list_to_blob(processed_ims)
im_info = np.array([[blob.shape[1], blob.shape[2], im_scales[0]]],dtype=np.float32)
im_info = torch.from_numpy(im_info).repeat(blob.shape[0], 1)
img_tensor = torch.from_numpy(blob)
img_tensor = img_tensor.permute(0, 3, 1, 2)
gt_boxes = torch.zeros([img_tensor.shape[0], 1, 5])
num_boxes = torch.zeros([img_tensor.shape[0]], dtype=torch.int64)
return img_tensor, im_info, gt_boxes, num_boxes, index
def __len__(self):
return len(self.video_list)
def cuda_collate_fn(batch):
"""
don't need to zip the tensor
"""
return batch[0]前にも書きましたが、この論文のネットワーク構造はボトムアップアプローチで大きく 2 つの部分に分かれています。

具体的なネットワーク構造図を以下に示します。
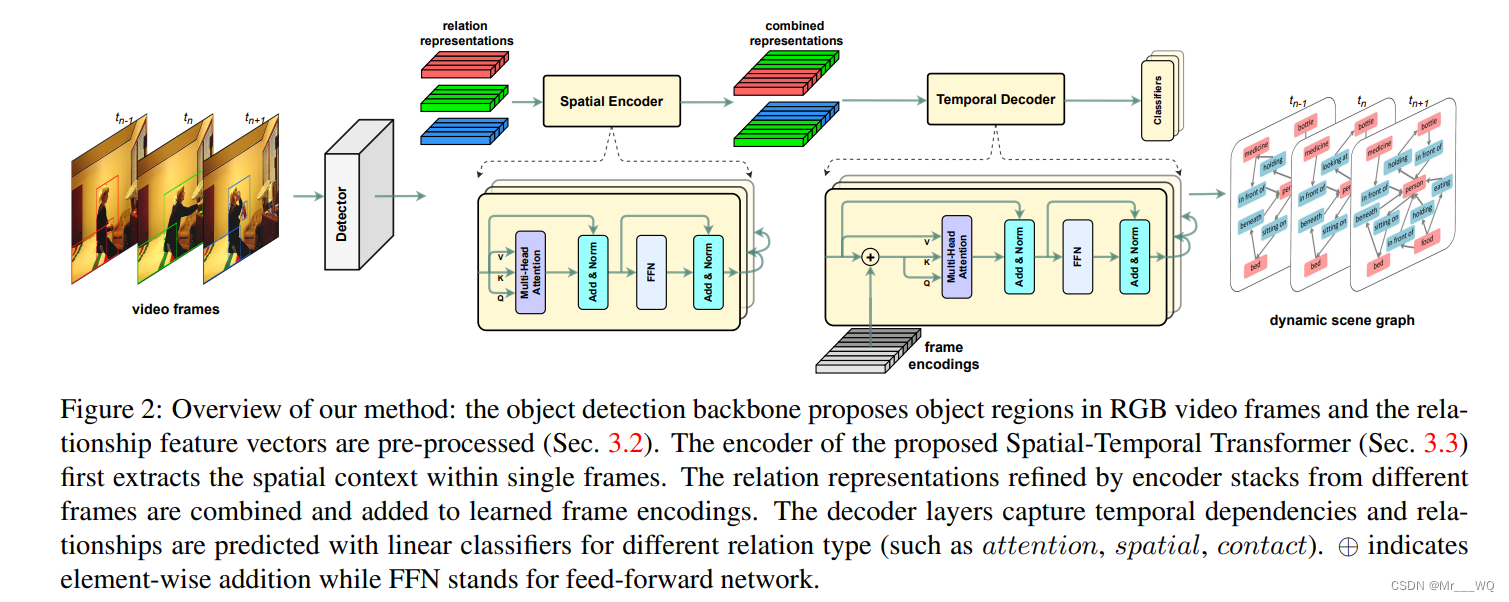
最初の部分はターゲット検出 (上の図の Detector に相当)、2 番目の部分はペアワイズ関係認識 (Detector の後ろの部分に相当) 次に、これら 2 つの部分について簡単に説明します。
1 つ目は Detector 部分です。この論文のこの部分は Fast-RCNN を使用して実装されており、コード内に Detector 用に別のクラスが記述されています。具体的な情報については、次のブログを参照してください: STTran ソース コード解釈 (2): 検出器クラス_美蘭区鄧子琦のブログ - CSDN ブログ![]() https://blog.csdn.net/qq_34108497/article/details/129049084?spm=1001.2014. 3001.5502ここでは Fast-RCNN の実装については紹介せず、ターゲット検出部分の実装のみを紹介します。具体的な導入については、以下の注意事項を参照してください。
https://blog.csdn.net/qq_34108497/article/details/129049084?spm=1001.2014. 3001.5502ここでは Fast-RCNN の実装については紹介せず、ターゲット検出部分の実装のみを紹介します。具体的な導入については、以下の注意事項を参照してください。
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
import copy
import cv2
import os
from lib.funcs import assign_relations
from lib.draw_rectangles.draw_rectangles import draw_union_boxes
from fasterRCNN.lib.model.faster_rcnn.resnet import resnet
from fasterRCNN.lib.model.rpn.bbox_transform import bbox_transform_inv, clip_boxes
from fasterRCNN.lib.model.roi_layers import nms
#bbox:bounding box
#gt:ground-truth
class detector(nn.Module):
'''first part: object detection (image/video)'''
def __init__(self, train, object_classes, use_SUPPLY, mode='predcls'):
super(detector, self).__init__()
self.is_train = train
#是否使用供应网络
self.use_SUPPLY = use_SUPPLY
self.object_classes = object_classes
self.mode = mode
#fasterRCNN定义
self.fasterRCNN = resnet(classes=self.object_classes, num_layers=101, pretrained=False, class_agnostic=False)
self.fasterRCNN.create_architecture()
#加载预训练权重
checkpoint = torch.load('fasterRCNN/models/faster_rcnn_ag.pth')
self.fasterRCNN.load_state_dict(checkpoint['model'])
#将不同特征大小的的输入区域输出相同大小输出特征
self.ROI_Align = copy.deepcopy(self.fasterRCNN.RCNN_roi_align)
self.RCNN_Head = copy.deepcopy(self.fasterRCNN._head_to_tail)
def forward(self, im_data, im_info, gt_boxes, num_boxes, gt_annotation, im_all):
'''input:
im_data(一段视频的所有向量化的图片表示)= (num of image,3,w,h)
im_info(一段视频所有图片的宽,高,缩放比例) = (num of image,3)
gt_boxes(初始化ground truth为零向量) = (num of image,1,5)
num_boxes = = (num of image,)
gt_annotation(一段视频所有图片的ground truth) = num of image
'''
#如果是场景图检测
if self.mode == 'sgdet':
##初始化变量,counter用于计数总的处理帧数,counter_image用于计数每10帧中的帧数
counter = 0
counter_image = 0
##创建用于保存最终预测结果的变量
# create saved-bbox, labels, scores, features
FINAL_BBOXES = torch.tensor([]).cuda(0)
FINAL_LABELS = torch.tensor([], dtype=torch.int64).cuda(0)
FINAL_SCORES = torch.tensor([]).cuda(0)
FINAL_FEATURES = torch.tensor([]).cuda(0)
FINAL_BASE_FEATURES = torch.tensor([]).cuda(0)
##当处理的总帧数未达到图像序列长度时,循环继续
while counter < im_data.shape[0]:
#compute 10 images in batch and collect all frames data in the video
##如果剩余帧数大于10,每次取10帧进行处理
if counter + 10 < im_data.shape[0]:
inputs_data = im_data[counter:counter + 10]
inputs_info = im_info[counter:counter + 10]
inputs_gtboxes = gt_boxes[counter:counter + 10]
inputs_numboxes = num_boxes[counter:counter + 10]
##否则取所有剩余帧进行处理
else:
inputs_data = im_data[counter:]
inputs_info = im_info[counter:]
inputs_gtboxes = gt_boxes[counter:]
inputs_numboxes = num_boxes[counter:]
#通过Faster RCNN模型得到这10帧的检测结果,包括建议框rois、分类概率cls_prob、
#框回归结果bbox_pred以及
#特征feat和roi_features
rois, cls_prob, bbox_pred, base_feat, roi_features = self.fasterRCNN(inputs_data, inputs_info,
inputs_gtboxes, inputs_numboxes)
#base_feat:[batch_size, rpn_input_dim=1024,38,67]
##得分和建议框
SCORES = cls_prob.data
boxes = rois.data[:, :, 1:5]
##对建议框进行解码,获得预测框
# bbox regression (class specific)
box_deltas = bbox_pred.data
box_deltas = box_deltas.view(-1, 4) * torch.FloatTensor([0.1, 0.1, 0.2, 0.2]).cuda(0) \
+ torch.FloatTensor([0.0, 0.0, 0.0, 0.0]).cuda(0) # the first is normalize std, the second is mean
box_deltas = box_deltas.view(-1, rois.shape[1], 4 * len(self.object_classes)) # post_NMS_NTOP: 30
##预测框还原和剪辑到图像范围内
pred_boxes = bbox_transform_inv(boxes, box_deltas, 1)
PRED_BOXES = clip_boxes(pred_boxes, im_info.data, 1)
#预测框坐标归一化到0-1范围
PRED_BOXES /= inputs_info[0, 2] # original bbox scale!!!!!!!!!!!!!!
#对这10帧中的每一帧进行处理,取出预测框和得分
#traverse frames
for i in range(rois.shape[0]):
# images in the batch
scores = SCORES[i]
pred_boxes = PRED_BOXES[i]
#对每个类别进行NMS,去除重复框,只保留置信度最高的预测框
for j in range(1, len(self.object_classes)):
# NMS according to obj categories
inds = torch.nonzero(scores[:, j] > 0.1).view(-1) #0.05 is score threshold
# if there is det
if inds.numel() > 0:
cls_scores = scores[:, j][inds]
_, order = torch.sort(cls_scores, 0, True)
cls_boxes = pred_boxes[inds][:, j * 4:(j + 1) * 4]
cls_dets = torch.cat((cls_boxes, cls_scores.unsqueeze(1)), 1)
cls_dets = cls_dets[order]
keep = nms(cls_boxes[order, :], cls_scores[order], 0.4) # NMS threshold
cls_dets = cls_dets[keep.view(-1).long()]
##对'person'类别特殊处理,只保留置信度最高的预测
if j == 1:
# for person we only keep the highest score for person!
#保存'person'类别的预测框、标签、得分和特征
final_bbox = cls_dets[0,0:4].unsqueeze(0)
final_score = cls_dets[0,4].unsqueeze(0)
final_labels = torch.tensor([j]).cuda(0)
final_features = roi_features[i, inds[order[keep][0]]].unsqueeze(0)
else:
#保存其他类别的预测框、标签、得分和特征
final_bbox = cls_dets[:, 0:4]
final_score = cls_dets[:, 4]
final_labels = torch.tensor([j]).repeat(keep.shape[0]).cuda(0)
final_features = roi_features[i, inds[order[keep]]]
#将这一帧的预测结果拼接到总结果中
final_bbox = torch.cat((torch.tensor([[counter_image]], dtype=torch.float).repeat(final_bbox.shape[0], 1).cuda(0),
final_bbox), 1)
FINAL_BBOXES = torch.cat((FINAL_BBOXES, final_bbox), 0)
FINAL_LABELS = torch.cat((FINAL_LABELS, final_labels), 0)
FINAL_SCORES = torch.cat((FINAL_SCORES, final_score), 0)
FINAL_FEATURES = torch.cat((FINAL_FEATURES, final_features), 0)
#拼接这一帧的基础特征
FINAL_BASE_FEATURES = torch.cat((FINAL_BASE_FEATURES, base_feat[i].unsqueeze(0)), 0)
counter_image += 1
#计数,进入下一批处理
counter += 10
FINAL_BBOXES = torch.clamp(FINAL_BBOXES, 0)
prediction = {'FINAL_BBOXES': FINAL_BBOXES, 'FINAL_LABELS': FINAL_LABELS, 'FINAL_SCORES': FINAL_SCORES,
'FINAL_FEATURES': FINAL_FEATURES, 'FINAL_BASE_FEATURES': FINAL_BASE_FEATURES}
##场景图生成训练阶段
if self.is_train:
#通过IOU分配gt框和预测框,获得匹配关系和未匹配的预测关系
DETECTOR_FOUND_IDX, GT_RELATIONS, SUPPLY_RELATIONS, assigned_labels = assign_relations(prediction, gt_annotation, assign_IOU_threshold=0.5)
#使用供应网络,补充未检测到的gt框,未找到的gt框的预测标签
if self.use_SUPPLY:
# supply the unfounded gt boxes by detector into the scene graph generation training
FINAL_BBOXES_X = torch.tensor([]).cuda(0)
FINAL_LABELS_X = torch.tensor([], dtype=torch.int64).cuda(0)
FINAL_SCORES_X = torch.tensor([]).cuda(0)
FINAL_FEATURES_X = torch.tensor([]).cuda(0)
#初始化变量以保存所有(包含补充的)预测框、标签、得分和特征
assigned_labels = torch.tensor(assigned_labels, dtype=torch.long).to(FINAL_BBOXES_X.device)
#如果这一帧有未检测到的gt框 ,为未检测到的gt框赋予概率1
#创建变量保存未检测到的gt框、标签和得分
for i, j in enumerate(SUPPLY_RELATIONS):
if len(j) > 0:
unfound_gt_bboxes = torch.zeros([len(j), 5]).cuda(0)
unfound_gt_classes = torch.zeros([len(j)], dtype=torch.int64).cuda(0)
one_scores = torch.ones([len(j)], dtype=torch.float32).cuda(0) # probability
for m, n in enumerate(j):
# if person box is missing or objects
#填充未找到gt框的信息,包括坐标、类别等
if 'bbox' in n.keys():
unfound_gt_bboxes[m, 1:] = torch.tensor(n['bbox']) * im_info[
i, 2] # don't forget scaling!
unfound_gt_classes[m] = n['class']
else:
# here happens always that IOU <0.5 but not unfounded
unfound_gt_bboxes[m, 1:] = torch.tensor(n['person_bbox']) * im_info[
i, 2] # don't forget scaling!
unfound_gt_classes[m] = 1 # person class index
#为补充的gt框指定匹配的检测器预测框索引
DETECTOR_FOUND_IDX[i] = list(np.concatenate((DETECTOR_FOUND_IDX[i],
np.arange(
start=int(sum(FINAL_BBOXES[:, 0] == i)),
stop=int(
sum(FINAL_BBOXES[:, 0] == i)) + len(
SUPPLY_RELATIONS[i]))), axis=0).astype(
'int64'))
#添加补充的关系到GT_RELATIONS
GT_RELATIONS[i].extend(SUPPLY_RELATIONS[i])
#计算未找到gt框的特征
# compute the features of unfound gt_boxes
pooled_feat = self.fasterRCNN.RCNN_roi_align(FINAL_BASE_FEATURES[i].unsqueeze(0),
unfound_gt_bboxes.cuda(0))
pooled_feat = self.fasterRCNN._head_to_tail(pooled_feat)
#通过roi align获得特征并通过模型头尾进行处理,得到分类概率
cls_prob = F.softmax(self.fasterRCNN.RCNN_cls_score(pooled_feat), 1)
unfound_gt_bboxes[:, 0] = i
unfound_gt_bboxes[:, 1:] = unfound_gt_bboxes[:, 1:] / im_info[i, 2]
FINAL_BBOXES_X = torch.cat(
(FINAL_BBOXES_X, FINAL_BBOXES[FINAL_BBOXES[:, 0] == i], unfound_gt_bboxes))
FINAL_LABELS_X = torch.cat((FINAL_LABELS_X, assigned_labels[FINAL_BBOXES[:, 0] == i],
unfound_gt_classes)) # final label is not gt!
FINAL_SCORES_X = torch.cat(
(FINAL_SCORES_X, FINAL_SCORES[FINAL_BBOXES[:, 0] == i], one_scores))
FINAL_FEATURES_X = torch.cat(
(FINAL_FEATURES_X, FINAL_FEATURES[FINAL_BBOXES[:, 0] == i], pooled_feat))
#如果这一帧没有未检测到的gt框,直接将检测结果拼接起来
else:
FINAL_BBOXES_X = torch.cat((FINAL_BBOXES_X, FINAL_BBOXES[FINAL_BBOXES[:, 0] == i]))
FINAL_LABELS_X = torch.cat((FINAL_LABELS_X, assigned_labels[FINAL_BBOXES[:, 0] == i]))
FINAL_SCORES_X = torch.cat((FINAL_SCORES_X, FINAL_SCORES[FINAL_BBOXES[:, 0] == i]))
FINAL_FEATURES_X = torch.cat((FINAL_FEATURES_X, FINAL_FEATURES[FINAL_BBOXES[:, 0] == i]))
#通过模型获得分类概率分布,global_idx保存所有预测框的索引
FINAL_DISTRIBUTIONS = torch.softmax(self.fasterRCNN.RCNN_cls_score(FINAL_FEATURES_X)[:, 1:], dim=1)
global_idx = torch.arange(start=0, end=FINAL_BBOXES_X.shape[0]) # all bbox indices
im_idx = [] # which frame are the relations belong to
pair = []
a_rel = []
s_rel = []
c_rel = []
for i, j in enumerate(DETECTOR_FOUND_IDX):
#找出这一帧中person类别的预测框索引
for k, kk in enumerate(GT_RELATIONS[i]):
if 'person_bbox' in kk.keys():
kkk = k
break
localhuman = int(global_idx[FINAL_BBOXES_X[:, 0] == i][kkk])
#这一关系属于哪一帧图像
for m, n in enumerate(j):
if 'class' in GT_RELATIONS[i][m].keys():
im_idx.append(i)
#这一个关系的两个实体(主语和宾语)的预测框索引
pair.append([localhuman, int(global_idx[FINAL_BBOXES_X[:, 0] == i][int(n)])])
#这一关系的三种gt关系标签:注意关系、空间关系和接触关系
a_rel.append(GT_RELATIONS[i][m]['attention_relationship'].tolist())
s_rel.append(GT_RELATIONS[i][m]['spatial_relationship'].tolist())
c_rel.append(GT_RELATIONS[i][m]['contacting_relationship'].tolist())
pair = torch.tensor(pair).cuda(0)
im_idx = torch.tensor(im_idx, dtype=torch.float).cuda(0)
#计算两个相关实体的联合框,用于获得关系特征
union_boxes = torch.cat((im_idx[:, None],
torch.min(FINAL_BBOXES_X[:, 1:3][pair[:, 0]],
FINAL_BBOXES_X[:, 1:3][pair[:, 1]]),
torch.max(FINAL_BBOXES_X[:, 3:5][pair[:, 0]],
FINAL_BBOXES_X[:, 3:5][pair[:, 1]])), 1)
union_boxes[:, 1:] = union_boxes[:, 1:] * im_info[0, 2]
#通过RoI Align获得关系特征union_feat
union_feat = self.fasterRCNN.RCNN_roi_align(FINAL_BASE_FEATURES, union_boxes)
pair_rois = torch.cat((FINAL_BBOXES_X[pair[:,0],1:],FINAL_BBOXES_X[pair[:,1],1:]), 1).data.cpu().numpy()
#获得两个相关实体的mask,用于计算相对方向
spatial_masks = torch.tensor(draw_union_boxes(pair_rois, 27) - 0.5).to(FINAL_FEATURES.device)
'''
#返回最终用于训练场景图生成的关系 triplets 相关信息,包括:
boxes:所有预测框
labels:所有预测框的预测标签
scores:所有预测框的预测得分
distribution:所有预测框的分类概率分布
im_idx:每个关系属于的图像索引
pair_idx:每个关系的两个实体(主语和宾语)的预测框索引
features:所有预测框的特征
union_feat:每个关系的特征
spatial_masks:每个关系的两个实体的mask
attention_gt:每个关系的注意力gt标签
spatial_gt:每个关系的空间gt标签
contacting_gt:每个关系的接触gt标签
'''
entry = {'boxes': FINAL_BBOXES_X,
'labels': FINAL_LABELS_X,
'scores': FINAL_SCORES_X,
'distribution': FINAL_DISTRIBUTIONS,
'im_idx': im_idx,
'pair_idx': pair,
'features': FINAL_FEATURES_X,
'union_feat': union_feat,
'spatial_masks': spatial_masks,
'attention_gt': a_rel,
'spatial_gt': s_rel,
'contacting_gt': c_rel}
return entry
##测试阶段,没有补充GT框
else:
#通过模型获得分类概率分布和预测标签
FINAL_DISTRIBUTIONS = torch.softmax(self.fasterRCNN.RCNN_cls_score(FINAL_FEATURES)[:, 1:], dim=1)
FINAL_SCORES, PRED_LABELS = torch.max(FINAL_DISTRIBUTIONS, dim=1)
PRED_LABELS = PRED_LABELS + 1
entry = {'boxes': FINAL_BBOXES,
'scores': FINAL_SCORES,
'distribution': FINAL_DISTRIBUTIONS,
'pred_labels': PRED_LABELS,
'features': FINAL_FEATURES,
'fmaps': FINAL_BASE_FEATURES,
'im_info': im_info[0, 2]}
return entry
else:
# 计算总bbox数量
# how many bboxes we have
bbox_num = 0
# 表示关系属于的帧索引
im_idx = [] # which frame are the relations belong to
# 人物对或主宾pair
pair = []
#注意关系、空间关系、联合关系
a_rel = []
s_rel = []
c_rel = []
#通过gt_annotation计算总bbox数
for i in gt_annotation:
bbox_num += len(i)
# 初始化FINAL_BBOXES,FINAL_LABELS,FINAL_SCORES,HUMAN_IDX
FINAL_BBOXES = torch.zeros([bbox_num,5], dtype=torch.float32).cuda(0)
FINAL_LABELS = torch.zeros([bbox_num], dtype=torch.int64).cuda(0)
FINAL_SCORES = torch.ones([bbox_num], dtype=torch.float32).cuda(0)
HUMAN_IDX = torch.zeros([len(gt_annotation),1], dtype=torch.int64).cuda(0)
# 填充人物bbox和非人物bbox信息
bbox_idx = 0
for i, j in enumerate(gt_annotation):
for m in j:
if 'person_bbox' in m.keys():
# 填人物bbox
FINAL_BBOXES[bbox_idx,1:] = torch.from_numpy(m['person_bbox'][0])
FINAL_BBOXES[bbox_idx, 0] = i
FINAL_LABELS[bbox_idx] = 1
HUMAN_IDX[i] = bbox_idx
bbox_idx += 1
else:
# 填非人物bbox
FINAL_BBOXES[bbox_idx,1:] = torch.from_numpy(m['bbox'])
FINAL_BBOXES[bbox_idx, 0] = i
FINAL_LABELS[bbox_idx] = m['class']
im_idx.append(i)
pair.append([int(HUMAN_IDX[i]), bbox_idx])
a_rel.append(m['attention_relationship'].tolist())
s_rel.append(m['spatial_relationship'].tolist())
c_rel.append(m['contacting_relationship'].tolist())
bbox_idx += 1
pair = torch.tensor(pair).cuda(0)
im_idx = torch.tensor(im_idx, dtype=torch.float).cuda(0)
counter = 0
FINAL_BASE_FEATURES = torch.tensor([]).cuda(0)
# 连续提取10帧,获得base_feat并拼接
while counter < im_data.shape[0]:
#compute 10 images in batch and collect all frames data in the video
if counter + 10 < im_data.shape[0]:
inputs_data = im_data[counter:counter + 10]
else:
inputs_data = im_data[counter:]
base_feat = self.fasterRCNN.RCNN_base(inputs_data)
FINAL_BASE_FEATURES = torch.cat((FINAL_BASE_FEATURES, base_feat), 0)
counter += 10
# 将bbox调整到原图尺度,获得FINAL_FEATURES
FINAL_BBOXES[:, 1:] = FINAL_BBOXES[:, 1:] * im_info[0, 2]
FINAL_FEATURES = self.fasterRCNN.RCNN_roi_align(FINAL_BASE_FEATURES, FINAL_BBOXES)
FINAL_FEATURES = self.fasterRCNN._head_to_tail(FINAL_FEATURES)
#predcls:谓词分类
if self.mode == 'predcls':
# 计算人物对的联合bbox
union_boxes = torch.cat((im_idx[:, None], torch.min(FINAL_BBOXES[:, 1:3][pair[:, 0]], FINAL_BBOXES[:, 1:3][pair[:, 1]]),
torch.max(FINAL_BBOXES[:, 3:5][pair[:, 0]], FINAL_BBOXES[:, 3:5][pair[:, 1]])), 1)
# 根据联合bbox提取特征
union_feat = self.fasterRCNN.RCNN_roi_align(FINAL_BASE_FEATURES, union_boxes)
# 调整bbox到原图尺度
FINAL_BBOXES[:, 1:] = FINAL_BBOXES[:, 1:] / im_info[0, 2]
# 获得人物对的bbox
pair_rois = torch.cat((FINAL_BBOXES[pair[:, 0], 1:], FINAL_BBOXES[pair[:, 1], 1:]),
1).data.cpu().numpy()
# 获得人物对的spatial masks
spatial_masks = torch.tensor(draw_union_boxes(pair_rois, 27) - 0.5).to(FINAL_FEATURES.device)
entry = {'boxes': FINAL_BBOXES,
'labels': FINAL_LABELS, # here is the groundtruth#这里是真实标签
'scores': FINAL_SCORES,
'im_idx': im_idx,
'pair_idx': pair,
'human_idx': HUMAN_IDX,
'features': FINAL_FEATURES,
'union_feat': union_feat,
'union_box': union_boxes,
'spatial_masks': spatial_masks,
'attention_gt': a_rel,
'spatial_gt': s_rel,
'contacting_gt': c_rel
}
return entry
'''
这段代码的主要功能是:
1. 如果self.is_train == True,则是训练阶段,返回必要的信息用于关系分类
2. 否则是验证阶段,返回必要信息用于性能评估
在训练阶段,我们需要获得预测标签(PRED_LABELS)、概率分布(FINAL_DISTRIBUTIONS)以及
人物对的信息用于关系分类。
在验证阶段,我们返回预测标签、概率分布以及其他信息用于性能评估。
返回的entry与上一段代码类似,包含真实标签、预测标签、概率分布等信息。
'''
elif self.mode == 'sgcls':
if self.is_train:
FINAL_DISTRIBUTIONS = torch.softmax(self.fasterRCNN.RCNN_cls_score(FINAL_FEATURES)[:, 1:], dim=1)
FINAL_SCORES, PRED_LABELS = torch.max(FINAL_DISTRIBUTIONS, dim=1)
PRED_LABELS = PRED_LABELS + 1
union_boxes = torch.cat(
(im_idx[:, None], torch.min(FINAL_BBOXES[:, 1:3][pair[:, 0]], FINAL_BBOXES[:, 1:3][pair[:, 1]]),
torch.max(FINAL_BBOXES[:, 3:5][pair[:, 0]], FINAL_BBOXES[:, 3:5][pair[:, 1]])), 1)
union_feat = self.fasterRCNN.RCNN_roi_align(FINAL_BASE_FEATURES, union_boxes)
FINAL_BBOXES[:, 1:] = FINAL_BBOXES[:, 1:] / im_info[0, 2]
pair_rois = torch.cat((FINAL_BBOXES[pair[:, 0], 1:], FINAL_BBOXES[pair[:, 1], 1:]),
1).data.cpu().numpy()
spatial_masks = torch.tensor(draw_union_boxes(pair_rois, 27) - 0.5).to(FINAL_FEATURES.device)
entry = {'boxes': FINAL_BBOXES,
'labels': FINAL_LABELS, # here is the groundtruth
'scores': FINAL_SCORES,
'distribution': FINAL_DISTRIBUTIONS,
'pred_labels': PRED_LABELS,
'im_idx': im_idx,
'pair_idx': pair,
'human_idx': HUMAN_IDX,
'features': FINAL_FEATURES,
'union_feat': union_feat,
'union_box': union_boxes,
'spatial_masks': spatial_masks,
'attention_gt': a_rel,
'spatial_gt': s_rel,
'contacting_gt': c_rel}
return entry
else:
FINAL_BBOXES[:, 1:] = FINAL_BBOXES[:, 1:] / im_info[0, 2]
FINAL_DISTRIBUTIONS = torch.softmax(self.fasterRCNN.RCNN_cls_score(FINAL_FEATURES)[:, 1:], dim=1)
FINAL_SCORES, PRED_LABELS = torch.max(FINAL_DISTRIBUTIONS, dim=1)
PRED_LABELS = PRED_LABELS + 1
entry = {'boxes': FINAL_BBOXES,
'labels': FINAL_LABELS, # here is the groundtruth
'scores': FINAL_SCORES,
'distribution': FINAL_DISTRIBUTIONS,
'pred_labels': PRED_LABELS,
'im_idx': im_idx,
'pair_idx': pair,
'human_idx': HUMAN_IDX,
'features': FINAL_FEATURES,
'attention_gt': a_rel,
'spatial_gt': s_rel,
'contacting_gt': c_rel,
'fmaps': FINAL_BASE_FEATURES,
'im_info': im_info[0, 2]}
return entry
ネットワーク構造図の 2 番目の部分は主に STTran クラスで実装されており、コードと関連コメントは次のとおりです。
"""
Let's get the relationships yo
"""
import numpy as np
import torch
import torch.nn as nn
from lib.word_vectors import obj_edge_vectors
from lib.transformer import transformer
from lib.fpn.box_utils import center_size
from fasterRCNN.lib.model.roi_layers import ROIAlign, nms
from lib.draw_rectangles.draw_rectangles import draw_union_boxes
class ObjectClassifier(nn.Module):
"""
Module for computing the object contexts and edge contexts
"""
def __init__(self, mode='sgdet', obj_classes=None):
super(ObjectClassifier, self).__init__()
self.classes = obj_classes # 目标类别列表
self.mode = mode # 数据集模式 (sgdet, predcls or sgcls)
#----------add nms when sgdet
self.nms_filter_duplicates = True
self.max_per_img =64
self.thresh = 0.01
# roi align
self.RCNN_roi_align = RoIAlign((7, 7), 1.0/16.0, 0) # 对目标进行ROIAlign操作 (输出7x7大小的feature map)
# 使用obj_edge_vectors函数提取obj_classes类别的词向量
# 使用torch.nn.Embedding函数将词向量作为Embedding层的权重
embed_vecs = obj_edge_vectors(obj_classes[1:], wv_type='glove.6B', wv_dir='data', wv_dim=200)
self.obj_embed = nn.Embedding(len(obj_classes)-1, 200)
self.obj_embed.weight.data = embed_vecs.clone()
# This probably doesn't help it much
# 对每个目标的位置信息进行标准化和矩阵变换
self.pos_embed = nn.Sequential(nn.BatchNorm1d(4, momentum=0.01 / 10.0),
nn.Linear(4, 128),
nn.ReLU(inplace=True),
nn.Dropout(0.1))
self.obj_dim = 2048 # 目标预测使用的特征维度大小
self.decoder_lin = nn.Sequential(nn.Linear(self.obj_dim + 200 + 128, 1024),
nn.BatchNorm1d(1024),
nn.ReLU(),
nn.Linear(1024, len(self.classes))) # 目标预测输出层
def clean_class(self, entry, b, class_idx):
# 定义四个空列表
final_boxes = [] # 装目标框
final_dists = [] # 装目标分数
final_feats = [] # 装目标特征向量
final_labels = [] # 装目标类别
for i in range(b): # 对每张图像中的目标进行遍历
# 获取每个目标框的目标预测分数、坐标、特征向量和预测的类别
scores = entry['distribution'][entry['boxes'][:, 0] == i]
pred_boxes = entry['boxes'][entry['boxes'][:, 0] == i]
feats = entry['features'][entry['boxes'][:, 0] == i]
pred_labels = entry['pred_labels'][entry['boxes'][:, 0] == i]
# 获取特定类别的目标框、特征向量和预测分数,并将其预测为0
new_box = pred_boxes[entry['pred_labels'][entry['boxes'][:, 0] == i] == class_idx]
new_feats = feats[entry['pred_labels'][entry['boxes'][:, 0] == i] == class_idx]
new_scores = scores[entry['pred_labels'][entry['boxes'][:, 0] == i] == class_idx]
new_scores[:, class_idx-1] = 0
# 如果有目标框,则将最高的分数预测为该类别,否则将预测类别置为空
if new_scores.shape[0] > 0:
new_labels = torch.argmax(new_scores, dim=1) + 1
else:
new_labels = torch.tensor([], dtype=torch.long).cuda(0)
# 将分数、框、特征向量和预测类别添加到四个列表中
final_dists.append(scores)
final_dists.append(new_scores)
final_boxes.append(pred_boxes)
final_boxes.append(new_box)
final_feats.append(feats)
final_feats.append(new_feats)
final_labels.append(pred_labels)
final_labels.append(new_labels)
# 将四个列表中的元素拼接在一起,并用拼接好的项更新entry中的值
entry['boxes'] = torch.cat(final_boxes, dim=0)
entry['distribution'] = torch.cat(final_dists, dim=0)
entry['features'] = torch.cat(final_feats, dim=0)
entry['pred_labels'] = torch.cat(final_labels, dim=0)
return entry
def forward(self, entry):
# 若self.mode的值为'predcls'
if self.mode == 'predcls':
# 将entry中'labels'的值赋给'pred_labels'字段并直接返回entry
entry['pred_labels'] = entry['labels']
return entry
# 若self.mode的值为'sgcls'
elif self.mode == 'sgcls':
# 首先,根据entry中'boxes'和'distribution'字段的值,计算出物体嵌入的obj_embed和位置嵌入的pos_embed,并将它们与'features'进行拼接得到obj_features
obj_embed = entry['distribution'] @ self.obj_embed.weight
pos_embed = self.pos_embed(center_size(entry['boxes'][:, 1:]))
obj_features = torch.cat((entry['features'], obj_embed, pos_embed), 1)
# 根据模型当前是否处于训练模式,分别进行如下操作:
# 若处于训练模式下
if self.training:
# 使用decoder_lin对obj_features进行线性变换并将结果赋给entry中的'distribution'字段,同步将'labels'赋给'pred_labels'字段
entry['distribution'] = self.decoder_lin(obj_features)
entry['pred_labels'] = entry['labels']
# 若处于非训练模式下
else:
# 使用decoder_lin对obj_features进行线性变换并将结果赋给entry中的'distribution'字段
entry['distribution'] = self.decoder_lin(obj_features)
# 根据entry['boxes']中记录的每个物体的索引,计算预测得分和标签
box_idx = entry['boxes'][:,0].long() # 获取box索引
b = int(box_idx[-1] + 1) # 获取box个数
entry['distribution'] = torch.softmax(entry['distribution'][:, 1:], dim=1) # 对后面的类别维度进行softmax归一化操作
entry['pred_scores'], entry['pred_labels'] = torch.max(entry['distribution'][:, 1:], dim=1) # 计算每个bbox中概率最大的标签和得分
entry['pred_labels'] = entry['pred_labels'] + 2 # 类别编号从2开始,因为1用来表示人体
# 找到具有最高人体得分的bbox,并将其视为人类检测结果
HUMAN_IDX = torch.zeros([b, 1], dtype=torch.int64).to(obj_features.device) # 初始化一个全0的张量
global_idx = torch.arange(0, entry['boxes'].shape[0]) # 获取每个bbox所对应的全局索引
for i in range(b):
local_human_idx = torch.argmax(entry['distribution'][box_idx == i, 0]) # 找到每个bbox信息中human类别得分的最大值
HUMAN_IDX[i] = global_idx[box_idx == i][local_human_idx] # 对于每个bbox中得分最大的human检测结果,将其索引记录在HUMAN_IDX中
entry['pred_labels'][HUMAN_IDX.squeeze()] = 1 # 将预测结果中人类检测的类别标签设为1(1是human类别标签)
entry['pred_scores'][HUMAN_IDX.squeeze()] = entry['distribution'][HUMAN_IDX.squeeze(), 0] # 将预测结果中人类检测的得分设为human类别的得分
# 去除重叠的检测结果
for i in range(b):
# 找出在同一bbox内,预测的类别相同的检测结果
duplicate_class = torch.mode(entry['pred_labels'][entry['boxes'][:, 0] == i])[0]
present = entry['boxes'][:, 0] == i # 获取属于当前bbox的所有检测结果的索引
# 若存在同类别的检测结果
if torch.sum(entry['pred_labels'][entry['boxes'][:, 0] == i] == duplicate_class) > 0:
duplicate_position = entry['pred_labels'][present] == duplicate_class
ppp = torch.argsort(entry['distribution'][present][duplicate_position][:,duplicate_class - 1])[:-1]
#找到所有类别为duplicate_class的检测结果
for j in ppp:
# # 更新标签和得分
changed_idx = global_idx[present][duplicate_position][j]
entry['distribution'][changed_idx, duplicate_class-1] = 0
entry['pred_labels'][changed_idx] = torch.argmax(entry['distribution'][changed_idx])+1
entry['pred_scores'][changed_idx] = torch.max(entry['distribution'][changed_idx])
# 去除重叠的检测结果
# 遍历HUMAN_IDX,对于每个human bbox,遍历所有剩下的object bbox,将它们和human bbox配对,形成一对一的目标ROI对,并记录下他们所在的帧im_idx和pair_idx
im_idx = [] # which frame are the relations belong to
pair = []
for j, i in enumerate(HUMAN_IDX):
for m in global_idx[box_idx==j][entry['pred_labels'][box_idx==j] != 1]: # this long term contains the objects in the frame
im_idx.append(j)
pair.append([int(i), int(m)])
# 将pair转换成Tensor格式
pair = torch.tensor(pair).to(obj_features.device)
im_idx = torch.tensor(im_idx, dtype=torch.float).to(obj_features.device)
entry['pair_idx'] = pair
entry['im_idx'] = im_idx
# 对entry中的bbox坐标进行比例缩放,得到对应的union_boxes
entry['boxes'][:, 1:] = entry['boxes'][:, 1:] * entry['im_info']
union_boxes = torch.cat((im_idx[:, None], torch.min(entry['boxes'][:, 1:3][pair[:, 0]], entry['boxes'][:, 1:3][pair[:, 1]]),
torch.max(entry['boxes'][:, 3:5][pair[:, 0]], entry['boxes'][:, 3:5][pair[:, 1]])), 1)
# 调用RCNN_roi_align方法,将所有union_boxes对应的ROI特征拼接成一个特征张量
union_feat = self.RCNN_roi_align(entry['fmaps'], union_boxes)
# 将entry的bbox还原,并将union_boxes、spatial_masks等信息也保存在entry中
#union_feat = self.RCNN_roi_align(entry['fmaps'], union_boxes)
entry['boxes'][:, 1:] = entry['boxes'][:, 1:] / entry['im_info']
pair_rois = torch.cat((entry['boxes'][pair[:, 0], 1:], entry['boxes'][pair[:, 1], 1:]),
1).data.cpu().numpy()
spatial_masks = torch.tensor(draw_union_boxes(pair_rois, 27) - 0.5).to(obj_features.device)
entry['union_feat'] = union_feat
entry['union_box'] = union_boxes
entry['spatial_masks'] = spatial_masks
return entry
else:
if self.training:
obj_embed = entry['distribution'] @ self.obj_embed.weight
pos_embed = self.pos_embed(center_size(entry['boxes'][:, 1:]))
obj_features = torch.cat((entry['features'], obj_embed, pos_embed), 1)
box_idx = entry['boxes'][:, 0][entry['pair_idx'].unique()]
l = torch.sum(box_idx == torch.mode(box_idx)[0])
b = int(box_idx[-1] + 1) # !!!
entry['distribution'] = self.decoder_lin(obj_features)
entry['pred_labels'] = entry['labels']
else:
obj_embed = entry['distribution'] @ self.obj_embed.weight
pos_embed = self.pos_embed(center_size(entry['boxes'][:, 1:]))
obj_features = torch.cat((entry['features'], obj_embed, pos_embed), 1) #use the result from FasterRCNN directly
box_idx = entry['boxes'][:, 0].long()
b = int(box_idx[-1] + 1)
entry = self.clean_class(entry, b, 5)
entry = self.clean_class(entry, b, 8)
entry = self.clean_class(entry, b, 17)
# # NMS
final_boxes = []
final_dists = []
final_feats = []
for i in range(b):
# images in the batch
scores = entry['distribution'][entry['boxes'][:, 0] == i]
pred_boxes = entry['boxes'][entry['boxes'][:, 0] == i, 1:]
feats = entry['features'][entry['boxes'][:, 0] == i]
for j in range(len(self.classes) - 1):
# NMS according to obj categories
inds = torch.nonzero(torch.argmax(scores, dim=1) == j).view(-1)
# if there is det
if inds.numel() > 0:
cls_dists = scores[inds]
cls_feats = feats[inds]
cls_scores = cls_dists[:, j]
_, order = torch.sort(cls_scores, 0, True)
cls_boxes = pred_boxes[inds]
cls_dists = cls_dists[order]
cls_feats = cls_feats[order]
keep = nms(cls_boxes[order, :], cls_scores[order], 0.6) # hyperparameter
final_dists.append(cls_dists[keep.view(-1).long()])
final_boxes.append(torch.cat((torch.tensor([[i]], dtype=torch.float).repeat(keep.shape[0],
1).cuda(0),
cls_boxes[order, :][keep.view(-1).long()]), 1))
final_feats.append(cls_feats[keep.view(-1).long()])
entry['boxes'] = torch.cat(final_boxes, dim=0)
box_idx = entry['boxes'][:, 0].long()
entry['distribution'] = torch.cat(final_dists, dim=0)
entry['features'] = torch.cat(final_feats, dim=0)
entry['pred_scores'], entry['pred_labels'] = torch.max(entry['distribution'][:, 1:], dim=1)
entry['pred_labels'] = entry['pred_labels'] + 2
# use the infered object labels for new pair idx
HUMAN_IDX = torch.zeros([b, 1], dtype=torch.int64).to(box_idx.device)
global_idx = torch.arange(0, entry['boxes'].shape[0])
for i in range(b):
local_human_idx = torch.argmax(entry['distribution'][
box_idx == i, 0]) # the local bbox index with highest human score in this frame
HUMAN_IDX[i] = global_idx[box_idx == i][local_human_idx]
entry['pred_labels'][HUMAN_IDX.squeeze()] = 1
entry['pred_scores'][HUMAN_IDX.squeeze()] = entry['distribution'][HUMAN_IDX.squeeze(), 0]
im_idx = [] # which frame are the relations belong to
pair = []
for j, i in enumerate(HUMAN_IDX):
for m in global_idx[box_idx == j][
entry['pred_labels'][box_idx == j] != 1]: # this long term contains the objects in the frame
im_idx.append(j)
pair.append([int(i), int(m)])
pair = torch.tensor(pair).to(box_idx.device)
im_idx = torch.tensor(im_idx, dtype=torch.float).to(box_idx.device)
entry['pair_idx'] = pair
entry['im_idx'] = im_idx
entry['human_idx'] = HUMAN_IDX
entry['boxes'][:, 1:] = entry['boxes'][:, 1:] * entry['im_info']
union_boxes = torch.cat(
(im_idx[:, None], torch.min(entry['boxes'][:, 1:3][pair[:, 0]], entry['boxes'][:, 1:3][pair[:, 1]]),
torch.max(entry['boxes'][:, 3:5][pair[:, 0]], entry['boxes'][:, 3:5][pair[:, 1]])), 1)
union_feat = self.RCNN_roi_align(entry['fmaps'], union_boxes)
entry['boxes'][:, 1:] = entry['boxes'][:, 1:] / entry['im_info']
entry['union_feat'] = union_feat
entry['union_box'] = union_boxes
pair_rois = torch.cat((entry['boxes'][pair[:, 0], 1:], entry['boxes'][pair[:, 1], 1:]),
1).data.cpu().numpy()
entry['spatial_masks'] = torch.tensor(draw_union_boxes(pair_rois, 27) - 0.5).to(box_idx.device)
return entry
class STTran(nn.Module):
def __init__(self, mode='sgdet', attention_class_num=None,
spatial_class_num=None, contact_class_num=None,
obj_classes=None, rel_classes=None,
enc_layer_num=None, dec_layer_num=None):
"""
Args:
- mode: 模型运行模式,可选sgdet, sgcls或predcls
- attention_class_num: 注意力得分相关的类别数
- spatial_class_num: 空间关系相关的类别数
- contact_class_num: 聚合关系相关的类别数
- obj_classes: 对象分类的类别数
- rel_classes: 关系分类的类别数,当不使用关系模式时为None
- enc_layer_num: 编码层的数量
- dec_layer_num: 解码层的数量
"""
super(STTran, self).__init__()
self.obj_classes = obj_classes
self.rel_classes = rel_classes
self.attention_class_num = attention_class_num
self.spatial_class_num = spatial_class_num
self.contact_class_num = contact_class_num
assert mode in ('sgdet', 'sgcls', 'predcls')
self.mode = mode
# 对象分类器
self.object_classifier = ObjectClassifier(mode=self.mode, obj_classes=self.obj_classes)
###################################
# 模型的卷积神经网络部分
self.union_func1 = nn.Conv2d(1024, 256, 1, 1)
self.conv = nn.Sequential(
nn.Conv2d(2, 256 //2, kernel_size=7, stride=2, padding=3, bias=True),
nn.ReLU(inplace=True),
nn.BatchNorm2d(256//2, momentum=0.01),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1),
nn.Conv2d(256 // 2, 256, kernel_size=3, stride=1, padding=1, bias=True),
nn.ReLU(inplace=True),
nn.BatchNorm2d(256, momentum=0.01),
)
# 主语,宾语和视觉特征的分类器
self.subj_fc = nn.Linear(2048, 512)
self.obj_fc = nn.Linear(2048, 512)
self.vr_fc = nn.Linear(256*7*7, 512)
# 对象的嵌入表示向量
embed_vecs = obj_edge_vectors(obj_classes, wv_type='glove.6B',
wv_dir='/home/cong/Dokumente/neural-motifs-master/data',
wv_dim=200)
self.obj_embed = nn.Embedding(len(obj_classes), 200)
self.obj_embed.weight.data = embed_vecs.clone()
self.obj_embed2 = nn.Embedding(len(obj_classes), 200)
self.obj_embed2.weight.data = embed_vecs.clone()
# 全局的transformer
self.glocal_transformer = transformer(enc_layer_num=enc_layer_num,
dec_layer_num=dec_layer_num,
embed_dim=1936, nhead=8,
dim_feedforward=2048, dropout=0.1, mode='latter')
# 注意力,空间和聚合关系的分类器
self.a_rel_compress = nn.Linear(1936, self.attention_class_num)
self.s_rel_compress = nn.Linear(1936, self.spatial_class_num)
self.c_rel_compress = nn.Linear(1936, self.contact_class_num)
def forward(self, entry):
# 使用对象分类器预测我们的输入entry
entry = self.object_classifier(entry)
# visual part,视觉部分,包括主语、宾语和视觉上匹配的union features
subj_rep = entry['features'][entry['pair_idx'][:, 0]]
subj_rep = self.subj_fc(subj_rep)
obj_rep = entry['features'][entry['pair_idx'][:, 1]]
obj_rep = self.obj_fc(obj_rep)
vr = self.union_func1(entry['union_feat'])+self.conv(entry['spatial_masks'])
vr = self.vr_fc(vr.view(-1,256*7*7))
x_visual = torch.cat((subj_rep, obj_rep, vr), 1)
# semantic part,语义部分,由主语和宾语的嵌入表示向量构成
subj_class = entry['pred_labels'][entry['pair_idx'][:, 0]]
obj_class = entry['pred_labels'][entry['pair_idx'][:, 1]]
subj_emb = self.obj_embed(subj_class)
obj_emb = self.obj_embed2(obj_class)
x_semantic = torch.cat((subj_emb, obj_emb), 1)
# 合并视觉和语义特征
rel_features = torch.cat((x_visual, x_semantic), dim=1)
# 使用ST模型对混合特征进行处理并生成全局输出,并计算注意力分布以及空间分布和聚合分布
global_output, global_attention_weights, local_attention_weights = self.glocal_transformer(features=rel_features, im_idx=entry['im_idx'])
entry["attention_distribution"] = self.a_rel_compress(global_output)
entry["spatial_distribution"] = self.s_rel_compress(global_output)
entry["contacting_distribution"] = self.c_rel_compress(global_output)
# 非线性变换,并将空间分布和聚合分布通过sigmoid变换映射到[0, 1]之间
entry["spatial_distribution"] = torch.sigmoid(entry["spatial_distribution"])
entry["contacting_distribution"] = torch.sigmoid(entry["contacting_distribution"])
# 返回预测结果
return entryエネルギーに限りがあるため、すべてのコードを 1 つずつコメントすることはできませんが、誤解がある場合はご了承ください。個人的な学習記録にのみ使用されます。